在人工智能快速发展的今天,多模态理解与跨模态融合正成为推动AI技术进步的关键动力。这些技术不仅拓展了AI的感知与理解能力,还实现了跨不同数据形式的信息整合与创新表达。本文将深入探讨多模态理解的核心技术、最新进展及其在虚拟现实等场景下的创新应用,揭示这一前沿领域如何重塑人工智能的未来。
网页版:https://cvspzejr.gensparkspace.com
视频版:https://www.youtube.com/watch?v=YkQd0joZnUk
音频版:https://notebooklm.google.com/notebook/d85724f7-398b-4618-b5a9-c50f40c844e0/audio
多模态理解:打破单一感知的局限
多模态AI的基础概念
多模态AI(Multimodal AI)是指能够同时处理和整合多种不同类型数据(如文本、图像、音频、视频等)的人工智能系统。与传统的单模态AI系统不同,多模态AI通过模拟人类感知和决策过程,实现更全面、更准确的理解与表达。
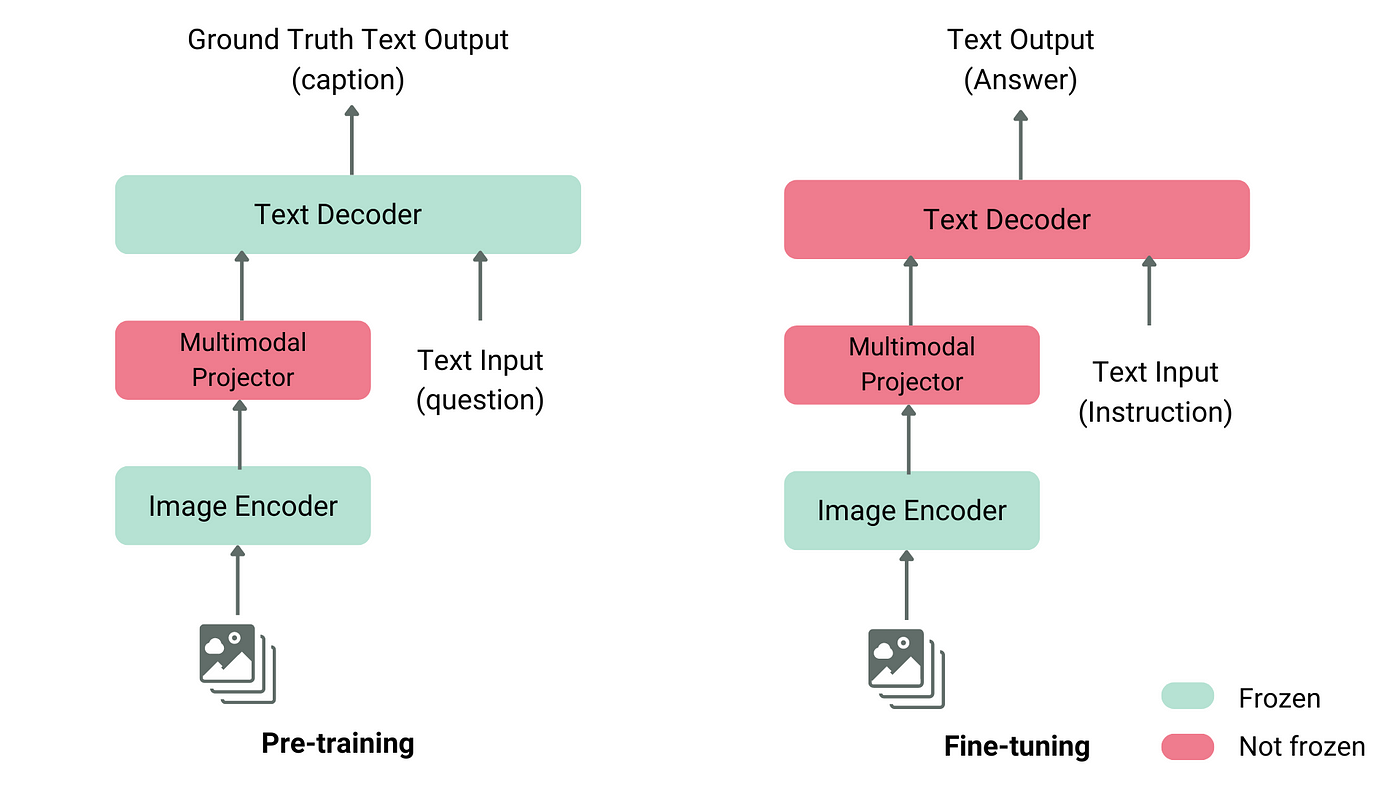
多模态AI系统的核心在于其能够:
- 整合多源数据:从不同来源获取信息,形成全面的理解
- 跨模态推理:在不同类型的数据之间建立联系,实现更深入的推理
- 模态转换:将一种模态的信息转换为另一种模态,如文本到图像的生成
- 增强鲁棒性:通过多模态信息的互补性,提高系统的稳定性和抗干扰能力
多模态推理:超越单一思维路径
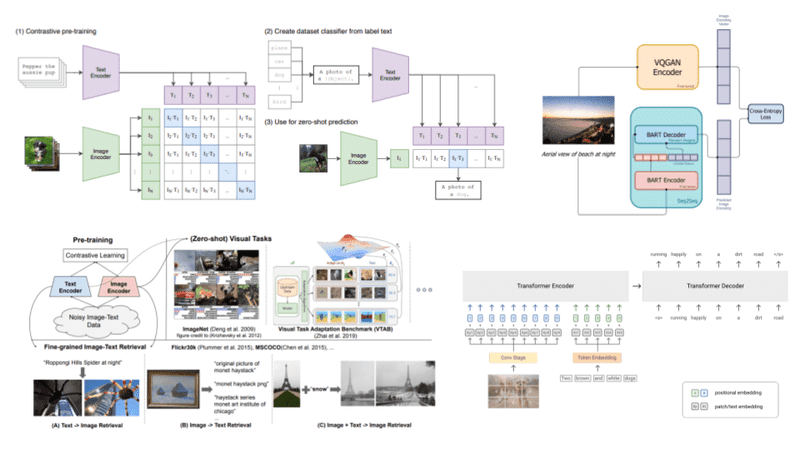
多模态推理是多模态AI的关键能力之一,它允许AI系统基于多种模态的输入进行复杂的推理和决策。例如,在视觉问答(Visual Question Answering, VQA)任务中,模型需要理解图像内容并结合文本问题给出准确答案。
Microsoft Research开发的METRE框架展示了多模态推理的先进方法,它采用了多种子架构,包括视觉编码器、解码器模块、文本编码器和多模态融合模块,增强了模型解释和回答视觉查询的能力。

视觉-文本联合表征:构建跨模态理解的桥梁
联合表征学习方法
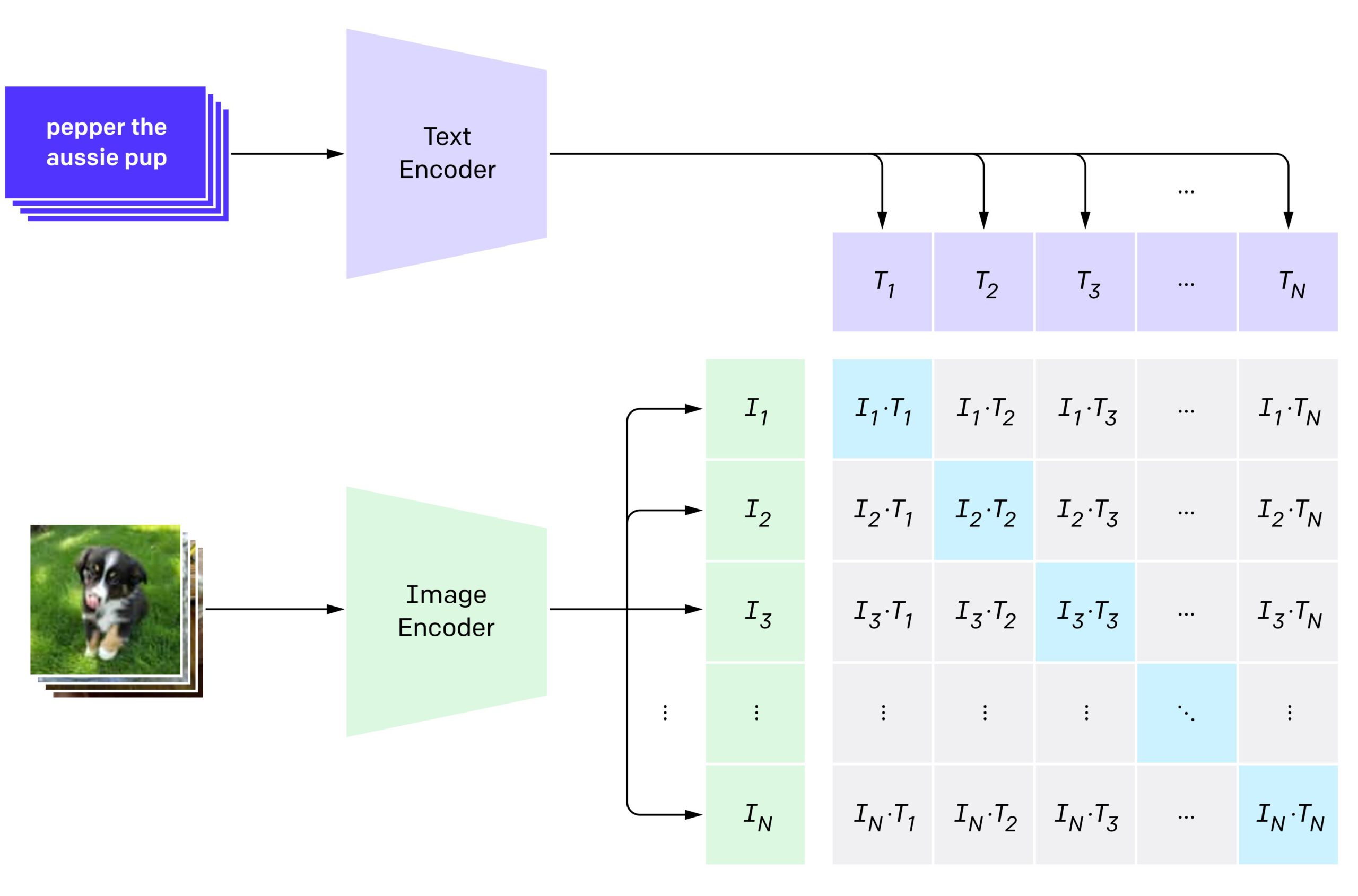
视觉-文本联合表征(Visual-Text Joint Representation)是实现多模态理解的核心技术,它使AI系统能够在共享的特征空间中理解和处理视觉与文本信息。主要的联合表征学习方法包括:
-
对比学习:如OpenAI的CLIP模型,通过训练模型区分相关和不相关的图像-文本对,学习有效的表征,无需大量标记数据即可进行训练。
-
跨模态注意力机制:使用跨注意力层实现视觉和文本信息的整合,允许模型在处理相关文本时聚焦于特定的图像部分。
-
早期融合与晚期融合:早期融合在模型架构的早期阶段就结合图像和文本嵌入,而晚期融合则先单独处理视觉和文本信息,仅在后期层中合并它们。
主流视觉-文本模型介绍
当前的主流视觉-文本联合表征模型主要包括:
-
CLIP (Contrastive Language–Image Pretraining):由OpenAI开发,使用双编码器架构将图像和文本对齐到共享特征空间。它通过对比学习方法在大规模图像-文本对数据集上训练,擅长零样本学习。
-
ViLBERT (Vision-and-Language BERT):BERT架构的扩展,采用两个并行模型分别处理视觉区域和文本段落,并使用共注意力变换器层融合这些模态,在视觉问答等多模态任务中表现出色。
-
VisualBERT:通过统一架构整合视觉和文本信息,结合BERT与视觉嵌入。它在COCO等数据集上训练,适用于图像描述和VQA等任务。
-
GPT-4V:OpenAI的多模态大语言模型,增强了处理和生成来自文本和图像的信息的能力,"V"表示其视觉能力,使其成为处理需要同时理解书面语言和视觉数据的任务的强大工具。
跨模态创作:从理解到生成的飞跃
跨模态内容生成技术
跨模态内容生成是指AI系统能够基于一种模态的输入,生成另一种模态的内容。这种技术打破了传统内容创作的边界,开创了全新的创作可能性。主要技术包括:
-
文本到图像生成:如DALL-E 3,能够根据文本描述生成详细的图像,增强了对用户意图的理解。
-
图像到文本生成:例如图像描述模型,能够根据图像生成详细的文本描述。
-
多模态到多模态生成:如微软研究院的CoDi(Composable Diffusion),能够接收任何模态的输入(文本、图像、音频、视频)并生成任何模态的输出,实现了真正的"any-to-any"生成能力。

跨模态创作的应用案例
跨模态创作技术已经在多个领域展示出了巨大的潜力:
-
电子商务:使用VLM增强视觉搜索功能,允许顾客拍摄物品照片来查找类似产品或获取建议。
-
制造业:辅助视觉质量检查,在生产线上识别产品和零件的缺陷,提高质量控制效率。
-
医疗诊断:帮助医疗专业人员通过分析医疗图像结合患者数据进行疾病诊断。
-
内容创作:为创意专业人士提供新的工具,如根据文本描述生成图像,或基于参考图像创建变体。
-
教育:创建个性化学习材料,将复杂概念可视化,增强学习体验。
虚拟现实场景下的认知融合
虚拟现实中的多模态交互
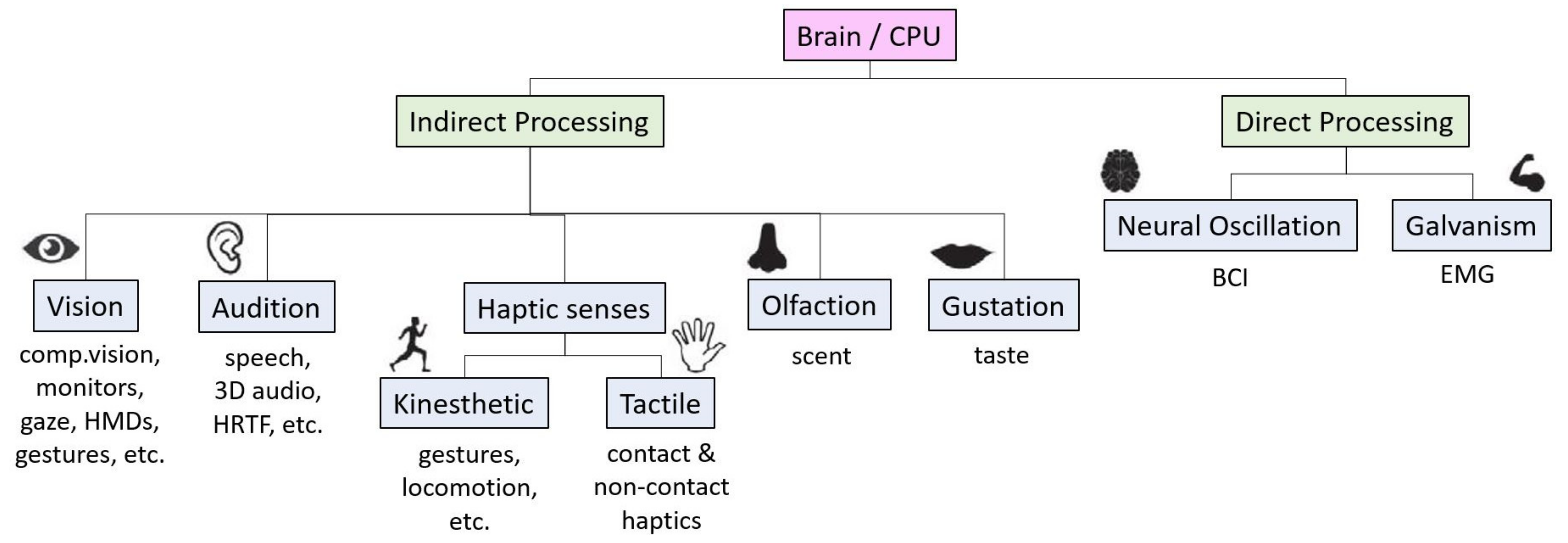
虚拟现实(VR)技术与多模态AI的结合,正在创造全新的人机交互范式。在VR环境中,多模态交互允许用户通过多种感官通道(视觉、听觉、触觉等)与系统进行自然、直观的互动。

VR中的多模态交互主要包括:
-
视觉-语言整合:用户可以通过语音指令与所看到的虚拟对象进行交互。
-
手势识别与语音控制:结合手势和语音命令进行复杂操作,提高交互自然性。
-
多感官反馈:通过视觉、听觉、触觉等多种感官通道提供综合反馈。
-
情感感知与响应:捕捉用户的情感状态,并相应地调整VR体验。
认知融合的理论与实践
认知融合是指在虚拟环境中,将不同模态的信息整合成统一的认知体验,使用户能够自然地理解和交互。这种融合超越了简单的多模态交互,旨在创造一种无缝、直觉的体验。
在实践中,认知融合通过以下方式实现:
-
跨模态映射:建立不同模态之间的对应关系,如将视觉信息与相关的文本描述或声音关联起来。
-
情境感知:系统能够理解当前的环境和用户状态,提供相应的响应和支持。
-
自适应界面:根据用户的行为和偏好动态调整交互方式和内容展示。
-
共享表征学习:在神经网络层面,学习不同模态数据的共享表征,实现更深层次的融合。
多模态系统的挑战与未来趋势
当前面临的挑战
尽管多模态AI取得了显著进展,但仍面临诸多挑战:
-
模型复杂性:多模态AI系统的集成导致模型复杂性增加,需要大量计算资源进行训练,包括强大的硬件和大型数据集。随着模型的增长和复杂化,部署难度增加,特别是在资源受限的设备上。
-
数据集偏见:多模态AI容易受到训练数据集中存在的偏见影响,可能导致输出偏斜或不准确。当模型在从互联网精选的数据集上训练时,它们可能会记忆特定模式而不是学习可推广的概念。
-
评估困难:由于视觉解释的主观性和语言描述的多样性,评估多模态AI系统面临独特挑战。传统评估指标通常依赖单一参考句进行比较,可能无法捕捉给定图像的全部有效描述范围。
-
可解释性问题:多模态AI系统的黑盒性质使我们难以理解它们如何得出结论。这种缺乏可解释性的问题阻碍了对其输出的信任,尤其是在医疗或自动驾驶等关键应用领域。
未来发展趋势
随着技术的不断进步,多模态理解与跨模态融合领域的未来发展趋势主要包括:
-
认知融合的深化:未来的多模态系统将更加注重认知层面的融合,实现更接近人类感知和理解方式的AI系统。
-
自监督学习的突破:减少对标注数据的依赖,通过自监督学习方法提高模型在少量数据情况下的表现。
-
知识蒸馏技术:通过知识蒸馏简化多模态AI,将知识从较大的教师模型转移到较小的学生模型。这一过程使学生能够以更少的参数实现高性能,使部署更快、更少资源密集。
-
多模态基础模型:像FUSION这样的完全视觉-语言对齐和集成范式的多模态大语言模型将成为未来发展方向,它们能够在整个处理流程中实现深度、动态的集成。
-
跨行业应用深化:多模态技术将在医疗健康、自动驾驶、教育、零售、制造等更多领域得到深入应用,创造新的价值和机会。

结论:融合的力量,无限的可能
多模态理解与跨模态融合代表了人工智能发展的重要方向,它不仅扩展了AI系统的感知和理解能力,还开创了全新的内容创作和人机交互方式。从视觉-文本联合表征到虚拟现实中的认知融合,这些技术正在重塑我们与人工智能系统交互的方式。
尽管面临诸多挑战,但随着技术的不断进步和创新,多模态AI将继续突破边界,创造更智能、更自然、更有创造力的系统,为各行各业带来变革性的影响。在这个多模态AI蓬勃发展的时代,我们正见证着技术的融合如何创造出前所未有的可能性,引领我们迈向更加智能化的未来。