还记得第一次打开Jupyter Notebook的那个瞬间吗?屏幕上出现的不再是冰冷的黑色终端,而是一个温暖的、可以交互的工作空间。那种"哇,原来代码还可以这样写"的震撼感,就像是推开了一扇通往新世界的门。
网页版:https://jmoflqyo.gensparkspace.com/
视频版:https://www.youtube.com/watch?v=T0lDOlEuCt8
音频版:https://notebooklm.google.com/notebook/1513eb10-2dbd-4eca-b41a-27690dbf9a47/audio

今天,我想和你分享这个被无数数据科学家奉为圭臬的工具背后的故事,以及它是如何从一个简单的想法演变成改变整个行业的平台。
从三个字母开始的传奇
Jupyter这个名字其实隐藏着一个有趣的秘密。它是Julia、Python和R三种编程语言名字的混合体,就像是三个好朋友决定一起开创一番事业。2014年,当Project Jupyter从IPython项目中独立出来时,没有人能预料到它会成为今天这样一个庞大的生态系统。
想象一下,如果你是一位探险家,传统的代码编辑器就像是一张空白的地图,你需要在脑海中想象整个探索过程。而Jupyter则是一本图文并茂的探险日志,你不仅可以记录每一步的发现,还能实时看到结果,甚至可以在旁边画个小插图来解释你的思路。
Notebook与Lab:一对神奇的双胞胎
当我们谈到Jupyter生态系统时,很多人会困惑于Jupyter Notebook和JupyterLab的区别。让我用一个简单的比喻来解释:如果Jupyter Notebook是一间温馨的工作室,那么JupyterLab就是一座现代化的办公大楼。
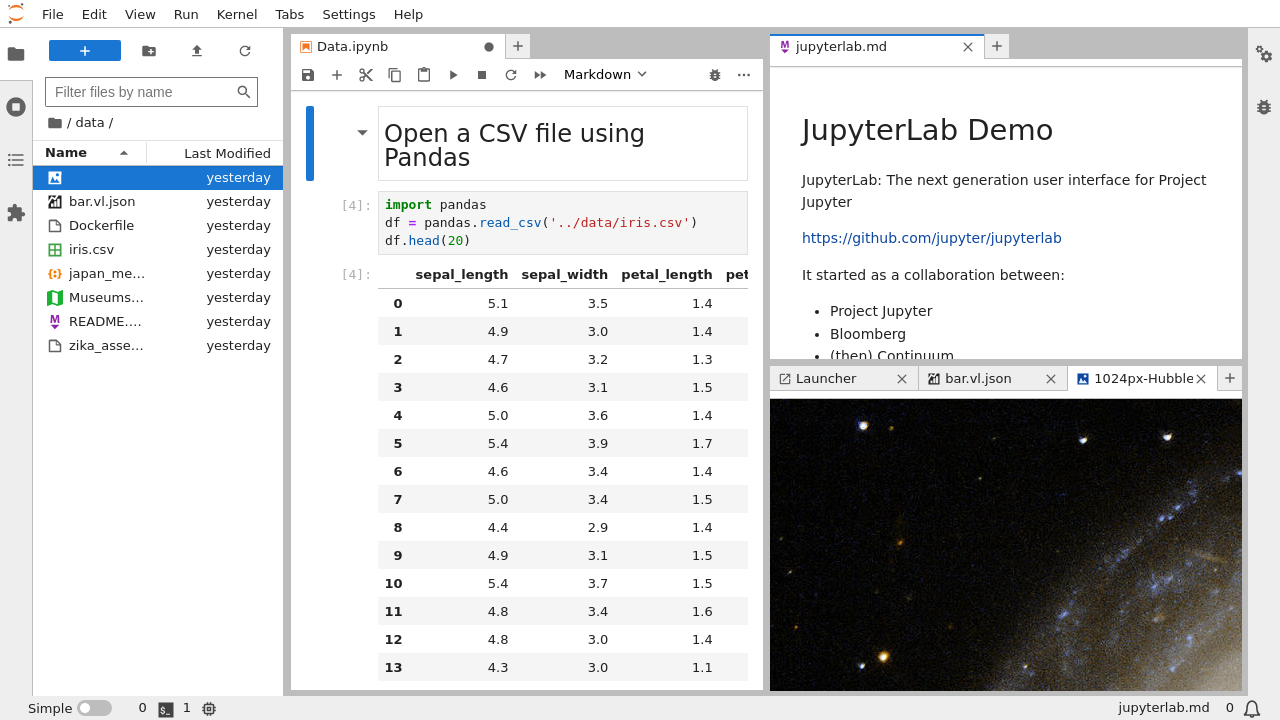
Jupyter Notebook:简约而不简单
Jupyter Notebook就像是一张永不结束的纸,你可以在上面交替写代码和文字。它的界面简洁明了,专注于单一文档的编辑。每个notebook都是一个独立的故事,有着自己的开头、发展和结尾。
最让人惊喜的是它的单元格(Cell)系统。代码单元格让你可以逐步执行代码,就像是在和计算机进行对话。比如当你输入这样的代码时:
# 你说:请帮我计算这个
population = [3_029_000_000, 3_631_000_000, 4_449_000_000, 5_292_000_000]
decades = ['1960', '1970', '1980', '1990']
# 计算机回应:好的,已经记住了
print(f"从{decades[0]}年到{decades[-1]}年,世界人口增长了{population[-1] - population[0]:,}人")
这种即时反馈的体验让编程变得如此直观和有趣。
JupyterLab:数据科学的指挥中心
如果说Notebook是一把精巧的瑞士军刀,那么JupyterLab就是一整套专业工具箱。它不仅包含了Notebook的所有功能,还增加了文件管理器、终端、文本编辑器等工具。
想象一下你正在进行一个复杂的数据分析项目:
- 左边的面板显示着项目文件结构
- 中间同时打开着三个notebook,分别负责数据清洗、模型训练和结果可视化
- 右边还开着一个终端窗口,随时准备安装新的包或运行脚本
- 底部的debugger正在帮你追踪一个棘手的bug
这就是JupyterLab的魅力所在——让你可以像指挥家一样,优雅地协调多个工具协同工作。
魔法命令:Jupyter的超能力
每个Jupyter用户都应该知道的秘密武器就是魔法命令(Magic Commands)。这些以百分号开头的特殊命令,就像是哈利波特世界里的咒语,能够让你的notebook拥有超乎想象的能力。

时间魔法:%timeit
还在为代码运行速度发愁吗?%timeit就像是一个精准的秒表。这个魔法命令会自动运行你的代码多次,然后给出准确的性能统计。它比你手动计时准确得多,还会自动处理各种干扰因素。
%timeit sum(range(1000))
# 输出:26.4 µs ± 494 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
可视化魔法:%matplotlib inline
记得第一次使用这个命令时的惊喜吗?一行神奇的代码,让所有的图表都直接显示在notebook中,不再需要在多个窗口间切换。
%matplotlib inline
import matplotlib.pyplot as plt
plt.plot([1, 2, 3, 4], [1, 4, 9, 16])
plt.title('我的第一个图表')
plt.show()
这种即时反馈的体验,让数据可视化变得如此直观和有趣。

系统集成魔法:!command
最令人印象深刻的是,Jupyter让你可以在代码中直接运行系统命令:
# 直接在notebook中安装新包
!pip install pandas numpy
# 查看当前目录
!ls -la
# 甚至可以运行Python脚本
!python my_script.py
这种无缝集成让notebook不再是一个孤立的环境,而是与整个系统融为一体的工作平台。
Markdown:让代码会说话的艺术
如果说代码是逻辑的体现,那么Markdown就是情感的表达。在Jupyter中,Markdown单元格让你可以创建真正的"文学编程"。
想象一下你正在写一份数据分析报告:
# 🚀 销售数据深度分析
## 背景介绍
在这个**数字化转型**的关键时期,我们需要深入了解客户行为模式...
## 核心发现
1. **季节性趋势**:第四季度销售额增长了 *25%*
2. **客户分层**:高价值客户占比仅 *8%*,但贡献了 *40%* 的营收
> 💡 **关键洞察**:我们发现了一个有趣的现象...
---
### 数据来源
- [内部销售系统](https://company.com/sales)
- [客户反馈平台](https://company.com/feedback)
这样的文档不仅包含了分析过程,还讲述了一个完整的故事。读者不需要具备编程背景,也能理解你的分析思路和结论。
LaTeX:数学公式的优雅表达
当你需要表达复杂的数学概念时,LaTeX就派上用场了。在Jupyter中,你可以轻松地插入美观的数学公式:

均值回归系数的计算公式:
$$\beta = \frac{\sum_{i=1}^{n} (x_i - \bar{x})(y_i - \bar{y})}{\sum_{i=1}^{n} (x_i - \bar{x})^2}$$
标准差的定义:
$$\sigma = \sqrt{\frac{1}{n}\sum_{i=1}^{n} (x_i - \mu)^2}$$
这些公式在notebook中会渲染成优美的数学表达式,让你的分析报告看起来如同学术论文一般专业。
插件与扩展:无限可能的生态系统
Jupyter的真正强大之处在于其开放的插件生态系统。JupyterLab的扩展机制让开发者可以创造出令人惊叹的功能。
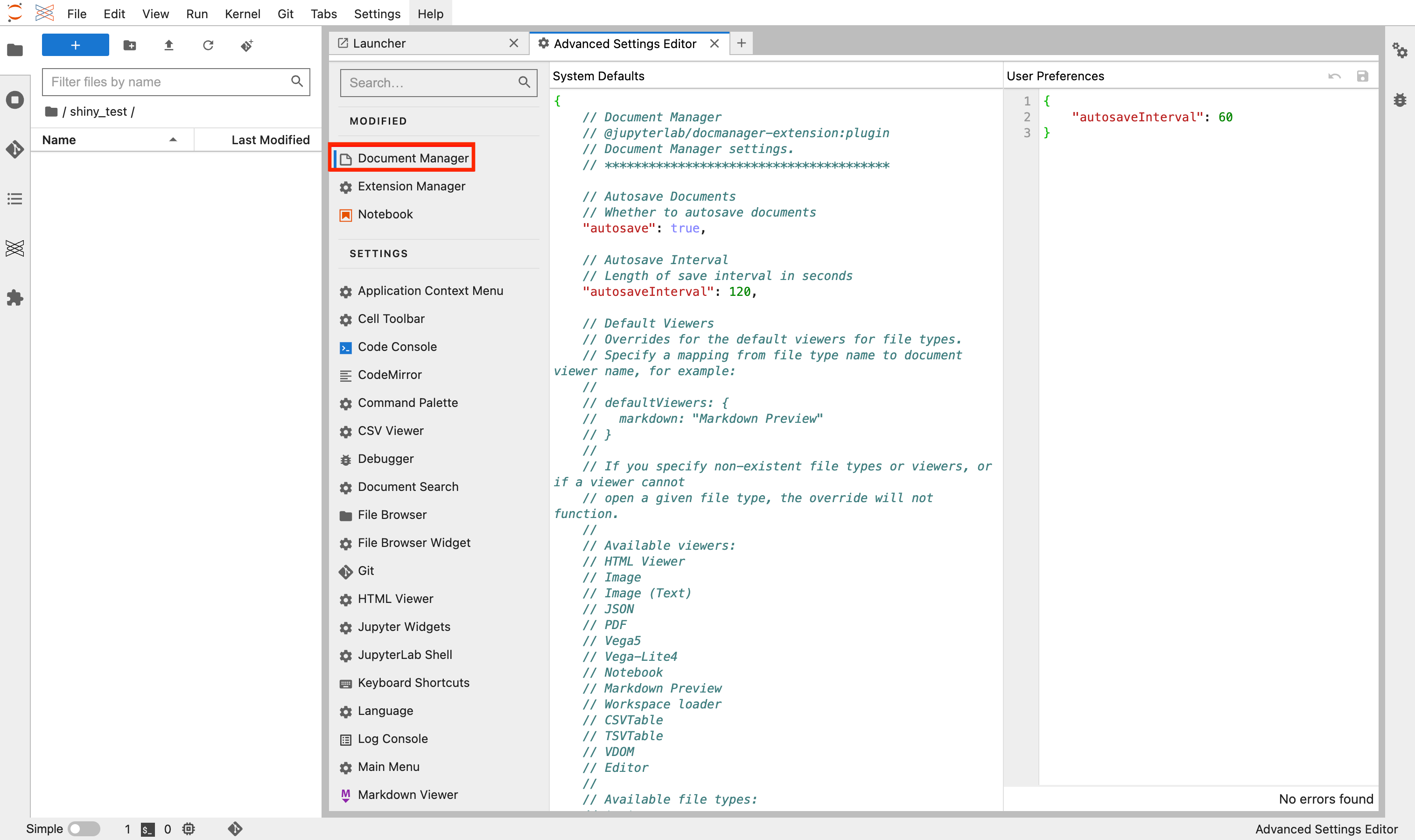
必装扩展推荐
想象一下这些场景:
- Variable Inspector:就像X光一样,让你随时查看内存中所有变量的状态
- Table of Contents:为长文档自动生成导航目录,就像书籍的章节索引
- Code Formatter:一键美化代码,让乱糟糟的代码瞬间变得整洁优雅
- Git集成:直接在界面中进行版本控制,告别命令行的繁琐
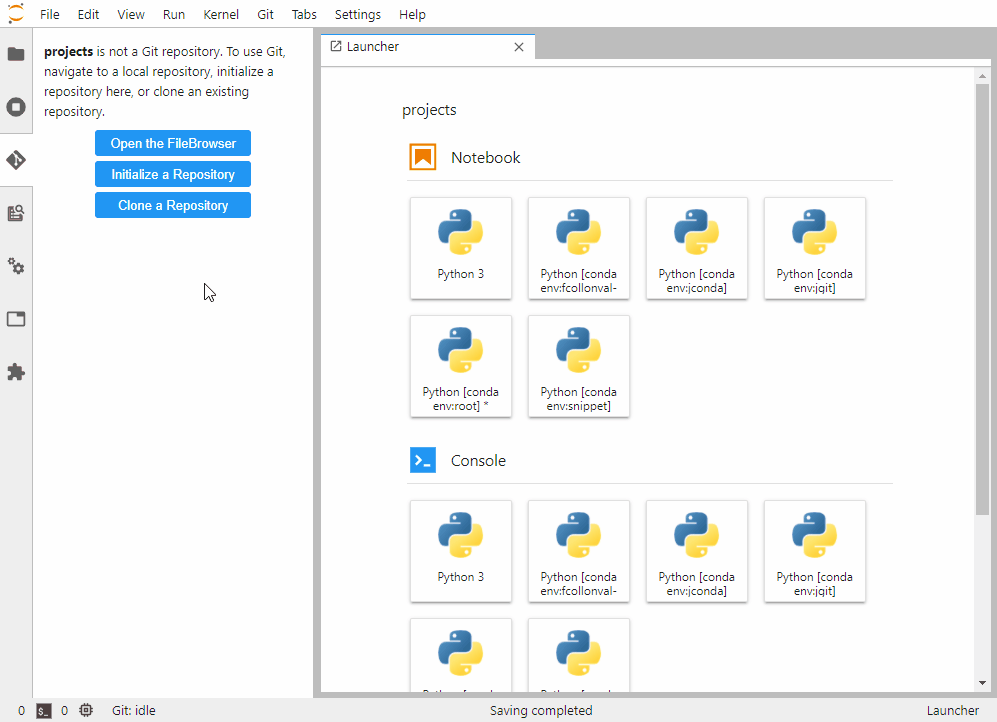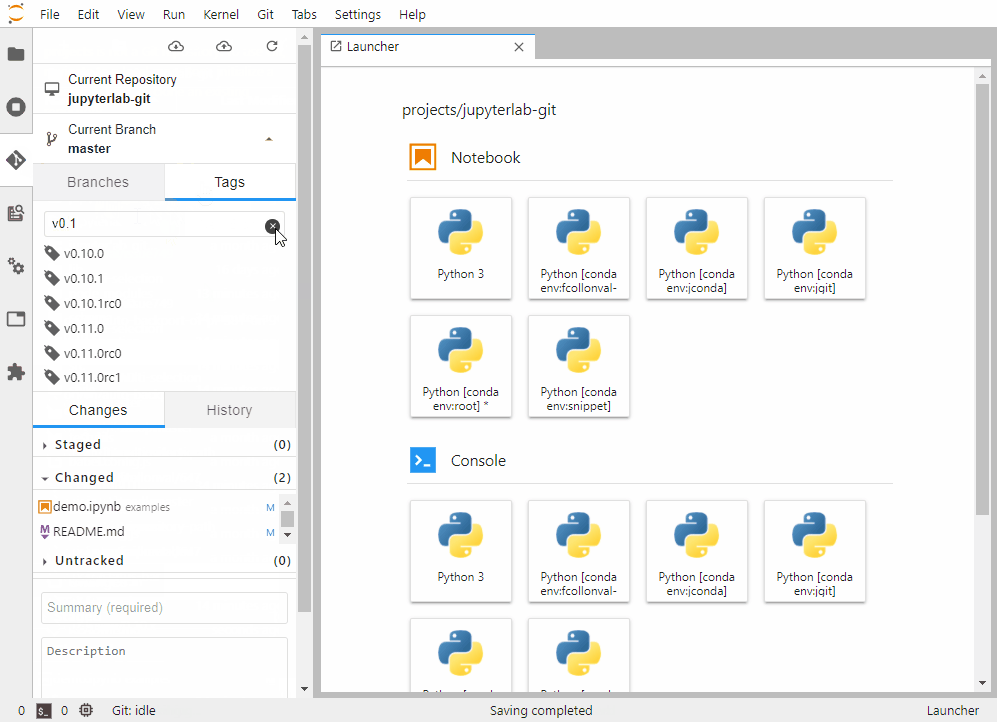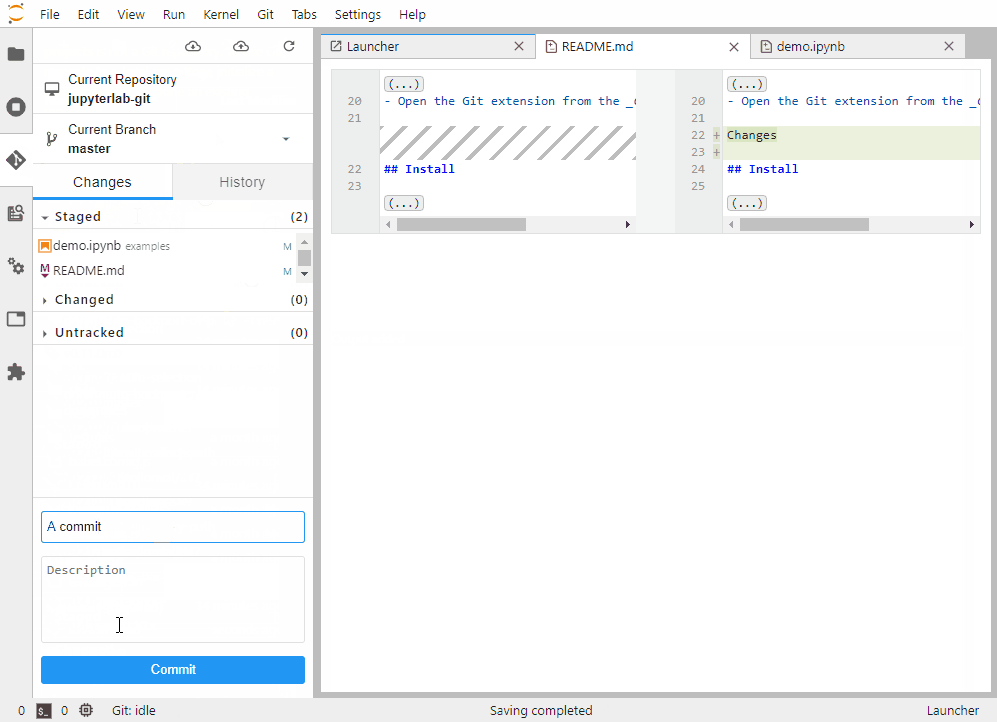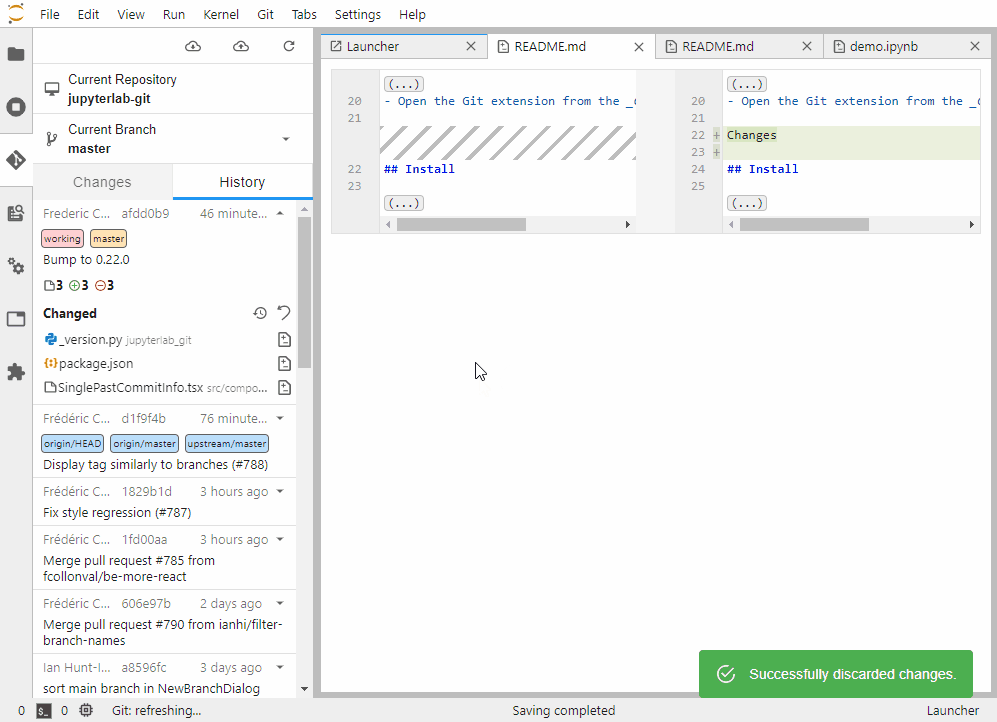
安装这些扩展就像是给你的Jupyter装上了各种专业工具:
# 使用pip安装扩展
pip install jupyterlab-git
pip install jupyterlab-toc
# 或者使用conda
conda install -c conda-forge jupyterlab-git
数据分析的艺术:从探索到报告
真正让Jupyter闪耀的是它对可重现研究的支持。想象一下你正在进行一项重要的商业分析:
第一步:数据探索
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 数据加载与初步探索
data = pd.read_csv('sales_data.csv')
print(f"数据集包含 {data.shape[0]} 行,{data.shape[1]} 列")
# 快速统计摘要
data.describe()
第二步:可视化洞察
# 创建一个优美的可视化
plt.figure(figsize=(12, 8))
sns.heatmap(data.corr(), annot=True, cmap='viridis')
plt.title('变量相关性热力图', fontsize=16)
plt.show()
第三步:建模与预测
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
# 数据分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 模型训练
model = RandomForestRegressor(random_state=42)
model.fit(X_train, y_train)
# 性能评估
score = model.score(X_test, y_test)
print(f"模型准确率: {score:.3f}")
第四步:结果呈现
## 📊 分析结论
基于我们的随机森林模型,我们发现:
1. **特征重要性排序**:
- 客户年龄:0.35
- 购买历史:0.28
- 季节因素:0.22
2. **预测准确率**:在测试集上达到了 **89.5%** 的准确率
3. **商业建议**:
- 重点关注25-45岁客户群体
- 在第四季度加大营销投入
- 建立客户忠诚度计划
这样的notebook不仅包含了完整的分析过程,还能够轻松地与团队成员分享,甚至可以直接转换为PDF报告或网页演示。
高效技巧:让你成为Jupyter忍者
经过多年的使用,我总结出了一些让Jupyter使用体验飞跃提升的技巧:
快捷键的魔力
掌握快捷键就像学会了瞬移术:
Shift + Enter:运行当前单元格并跳到下一个Ctrl + Enter:运行当前单元格但停留在原地Alt + Enter:运行当前单元格并在下方插入新单元格A:在上方插入单元格B:在下方插入单元格DD:删除当前单元格M:转换为Markdown单元格Y:转换为代码单元格
自动补全与文档查看
# 输入对象名后按Tab键,查看所有可用方法
data. # 然后按Tab
# 使用?查看函数文档
pd.read_csv?
# 使用??查看源代码
pd.read_csv??
这些功能让你在编程时如虎添翼,不再需要频繁查阅文档。
变量监控与调试
# 使用%who查看所有变量
%who
# 查看变量详细信息
%whos
# 查看变量内容
%pprint data.head()
当你的notebook变得复杂时,这些命令就像是探照灯,帮你照亮代码的每个角落。
版本控制:让协作变得简单
可能很多人不知道,Jupyter notebook其实可以很好地与Git集成。虽然.ipynb文件的JSON格式在版本控制中有些挑战,但现在有了很好的解决方案:
# 安装nbstripout,自动清除输出
pip install nbstripout
# 在项目中启用
nbstripout --install
# 现在Git只会跟踪代码和Markdown,忽略输出结果
这样,你的notebook历史就会变得清晰简洁,团队协作也变得轻松愉快。
从学院到工业:Jupyter的无限应用
Jupyter的影响力早已超越了数据科学的边界。在教育领域,它让编程教学变得生动有趣;在科研领域,它促进了可重现研究的发展;在工业界,它成为了从原型开发到生产部署的重要工具。
Netflix使用Jupyter进行推荐算法的研究,NASA用它来分析火星探测数据,金融机构用它来进行风险模型建模。这个最初只是为了改善Python交互体验的工具,现在已经成为了连接思维与代码的桥梁。
未来展望:智能化的笔记本
随着人工智能技术的发展,Jupyter生态系统也在不断演进。想象一下未来的notebook:它可能会根据你的代码自动生成解释文档,智能推荐最佳的可视化方案,甚至能够理解你的分析意图并提供优化建议。
这不再是科幻小说,而是正在发生的现实。每一次打开Jupyter,你都在参与这场改变世界的技术革命。
代码不仅仅是指令,它是思想的载体;数据不仅仅是数字,它是现实的映射。而Jupyter,就是连接这一切的神奇纽带。在这个数据驱动的时代,掌握Jupyter不仅是一种技能,更是一种思维方式——用科学的方法探索未知,用优雅的形式表达发现。
从简单的代码执行到复杂的数据故事讲述,从个人的探索实验到团队的协作研究,Jupyter始终在那里,默默地支撑着无数数据科学家的梦想和创新。它不仅仅是一个工具,更是一种哲学——让计算变得人性化,让复杂变得简单,让孤立的代码变成连贯的故事。