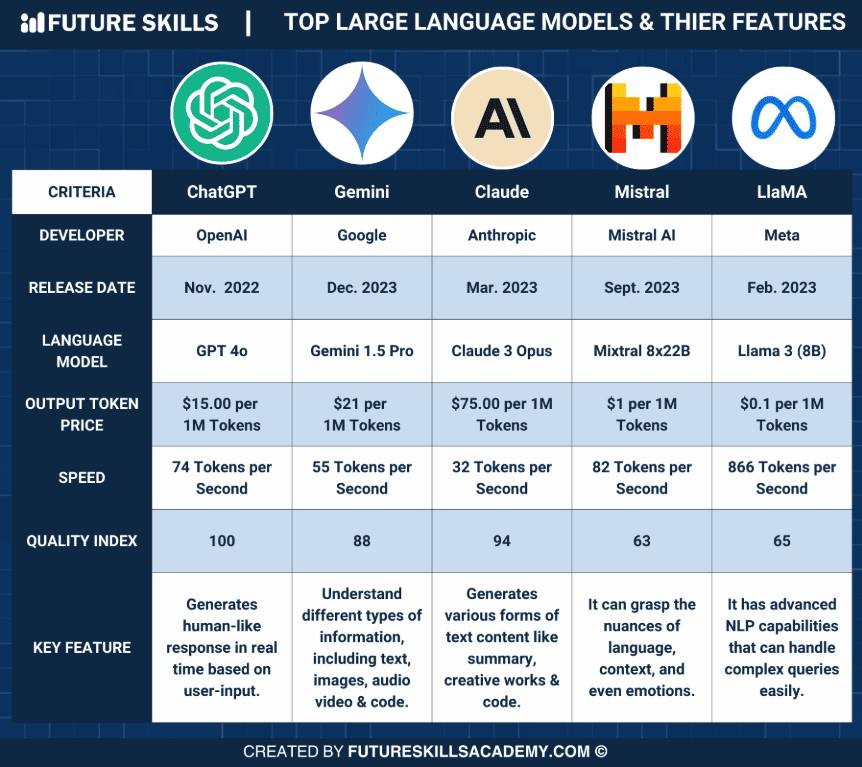
在人工智能飞速发展的2025年,大型语言模型(LLM)已经从单纯的文本生成工具演变为强大的多模态智能体。顶级科技公司和研究机构在这个战场上激烈角逐,推出了一系列具有里程碑意义的模型。今天,我们深入剖析六大顶尖AI模型:GPT-4o、Claude 3.7、Deepseek R1、Gemini 2.5、Qwen2.5-Max和GPT-4.1,揭秘它们的核心优势、技术架构和性能边界。
大模型格局:谁是真正的王者?
当今的AI格局已不再是单一维度的竞争,而是在多模态理解、推理思考、跨语言能力和专业任务等多个方面的全面对决。同时,模型架构也从传统的密集架构向混合专家(MoE)架构演进,寻求在性能与计算成本间的最佳平衡。
OpenAI的GPT-4o:全能实时交互之王

GPT-4o是OpenAI的旗舰多模态模型,"o"代表"omni"(全能),体现了其通用设计理念。这款模型彻底改变了用户与AI交互的体验,实现了约320毫秒的超低延迟响应,使对话体验更接近人类交流。
核心优势:
- 多模态无缝集成,原生处理文本、图像和音频
- 超低延迟响应,实现类似人类的对话体验
- 高品质语音合成与识别,包括情感和语调捕捉
- 增强的视觉处理能力,可理解复杂图像和图表
GPT-4o采用优化的Transformer架构,将不同模态的输入统一处理,大幅降低了多模态推理的延迟。它在实时会议助手、多语言翻译和多媒体内容创作等场景表现尤为出色。
Anthropic的Claude 3.7:思考深度的代码专家
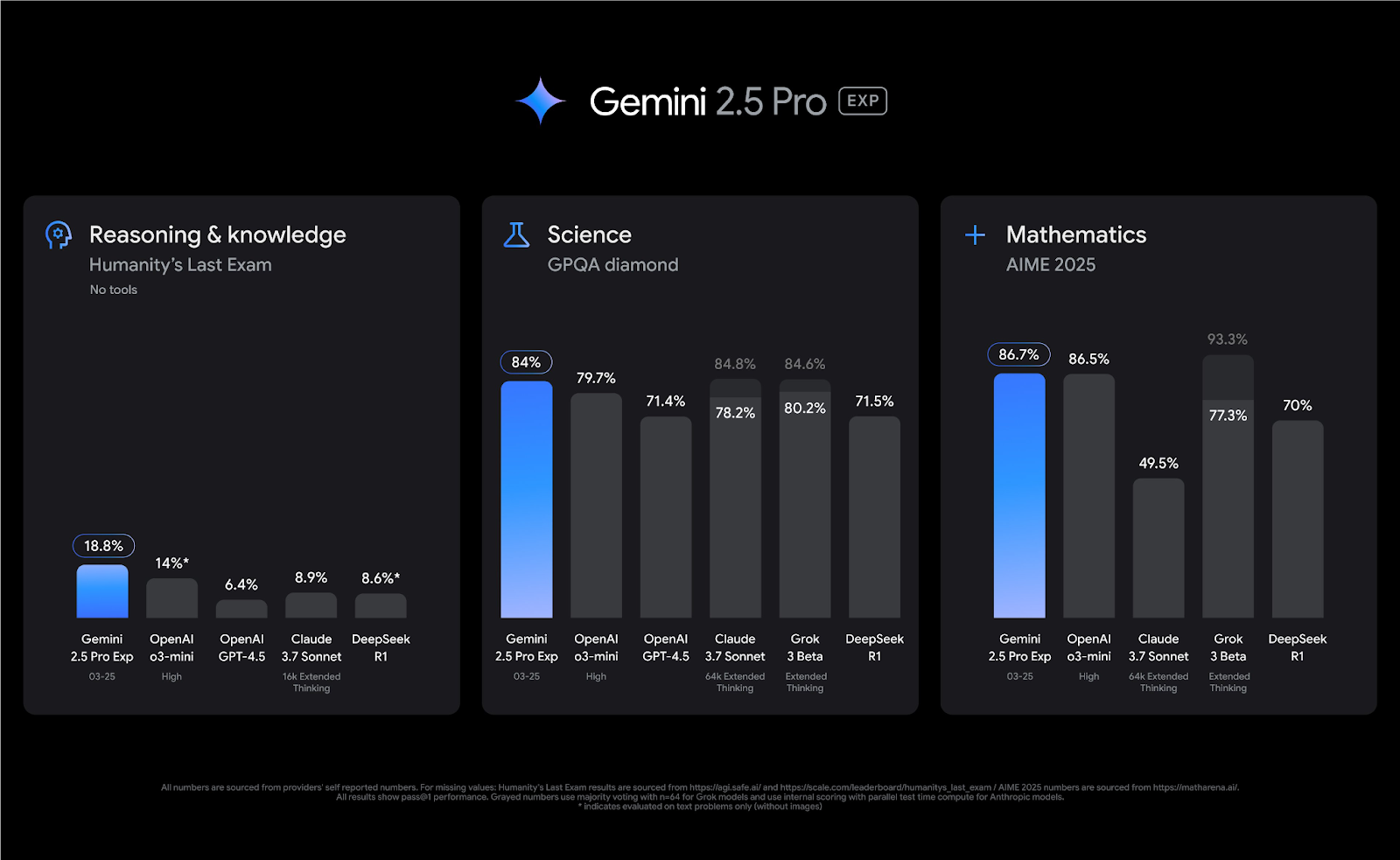
Claude 3.7以其卓越的推理深度和编程能力脱颖而出,引入了革命性的"扩展思考"模式,让模型能进行更深入的思考过程,提升复杂问题的解决能力。
核心优势:
- 扩展思考(Extended Thinking)模式,提升复杂问题解决准确率8-10%
- SWE-bench验证达62.3%,与配合Claude Code可达70.3%的顶级编程性能
- 128K输出token支持,能生成超长详细回复
- 90.8%-93.2%的指令遵循精度,业界领先
- 卓越的代码库架构分析和优化能力
Claude 3.7采用增强型Transformer架构,集成了128个先进的注意力层,通过"Constitutional AI"训练方法增强了安全性和减少了幻觉。它在软件开发、复杂推理问题和需要精确指令遵循的任务中表现最为出色。
DeepSeek的R1:开源推理的MoE力量

DeepSeek R1是第一个开源的大型推理模型,采用混合专家(MoE)架构,通过纯强化学习激励推理能力,在数学和逻辑推理等领域表现突出。
核心优势:
- 671B参数MoE架构,高效激活37B参数,平衡性能与计算成本
- 纯强化学习(RL)驱动的推理能力,自动生成高质量思维链
- 128K长上下文窗口,支持复杂文档处理
- 开源可定制,提供1.5B和7B参数的轻量级蒸馏版本
- 在数学和科学推理领域表现优异
DeepSeek R1包含61个Transformer层,使用分组查询注意力(GQA)机制,配备40个查询头和8个键值头。模型通过基于规则的奖励系统训练,包括准确性奖励和推理奖励,是复杂数学问题、科学研究和需要详细推理过程的应用的理想选择。
Google的Gemini 2.5:"思考型"模型的百万token王者

Gemini 2.5是Google DeepMind推出的"思考型"旗舰模型,能够在响应前先进行内部推理,拥有惊人的100万token上下文窗口,多模态能力全面而深入。
核心优势:
- 业界最大的100万token上下文窗口,可处理超长文档和知识库
- 内置推理过程("thinking"能力),提升复杂问题准确性
- 视频分析和内容提取能力领先业界
- 全面的多语言支持,特别在低资源语言上相对表现更好
- 强大的工具调用能力和Web交互能力
Gemini 2.5采用创新的"思考架构",实现了原生多模态处理,支持文本、图像、音频和视频输入。通过TPU v5超级计算机训练,优化了并行计算和内存使用效率,特别适合超长文档分析、视频处理和需要思考过程可视化的应用。
阿里巴巴的Qwen2.5-Max:中国MoE架构的挑战者

Qwen2.5-Max是阿里云推出的大规模MoE模型,预训练超过20万亿tokens,在Arena-Hard等基准测试中击败多个顶级模型,展现了中国AI技术的实力。
核心优势:
- 325B参数MoE架构,在Arena-Hard上得分89.4,领先各大模型
- 中英双语优化,同时覆盖29+种语言
- 超大规模预训练(20万亿tokens),知识丰富全面
- 在数学和编程领域表现尤为出色
- 高效计算架构,适合资源敏感型部署场景
Qwen2.5-Max采用大规模MoE架构,将模型参数分散到多个"专家"模块中,每次处理仅激活部分参数。模型经过监督微调(SFT)和人类反馈强化学习(RLHF)进一步优化,特别适合中英文环境、困难推理任务和对计算效率敏感的应用场景。
OpenAI的GPT-4.1:编程强化的多规格系列

GPT-4.1是OpenAI最新推出的模型系列,专注于编程和指令遵循能力,知识库更新至2024年6月,包含标准、Mini和Nano三种变体,满足不同场景需求。
核心优势:
- SWE-bench达54.6%,比GPT-4o提升21.4%,编程能力大幅增强
- 100万token上下文窗口,适合大型代码库分析
- 最新知识库(更新至2024年6月),信息更新更全面
- 多样化模型系列(标准/Mini/Nano)满足不同场景和设备需求
- 指令遵循能力大幅提升,增强21%
GPT-4.1系列架构优化专注于代码生成和指令遵循,引入了改进的注意力机制和更高效的推理算法。Nano变体是OpenAI首个轻量级模型,针对移动和边缘设备优化,为全面部署AI提供了更多可能性。
性能对决:多维度的能力比拼
大模型的竞争不再是单一性能指标的比拼,而是多维度能力的综合较量。从多模态处理到跨语言能力,从推理深度到专业任务表现,每个模型都有其独特优势。
多模态能力对比
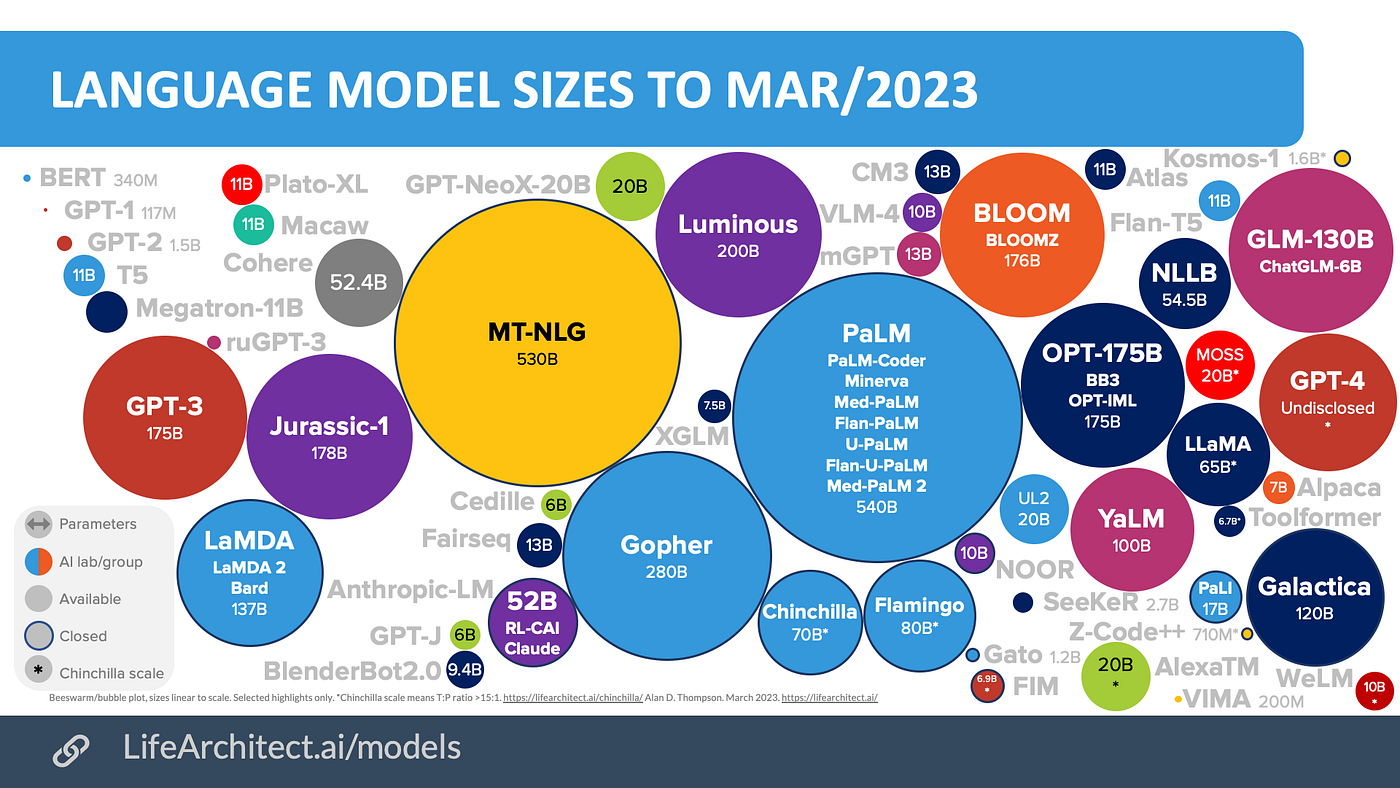
在多模态处理方面,GPT-4o和Gemini 2.5表现最为出色,尤其是在实时交互和视频理解方面。Claude 3.7在图表和文档分析上有特殊优势,而Qwen2.5-Max在中文多模态内容理解上领先。
值得注意的是,多模态能力已经从简单的多形式输入支持,进化为深度的跨模态理解和推理。这种进步代表着AI正从单一信息处理向类人感知方式迈进。
推理能力与思考深度
在推理能力方面,Claude 3.7、DeepSeek R1和Gemini 2.5各具特色。Claude 3.7的扩展思考模式、DeepSeek R1的强化学习驱动推理和Gemini 2.5的内置思考过程,代表了增强模型推理能力的不同技术路线。
特别是在编程领域,GPT-4.1和Claude 3.7表现最为突出。GPT-4.1在SWE-bench上达到54.6%的成绩,比GPT-4o提升了21.4%,而Claude 3.7配合Claude Code可达70.3%的顶级编程性能。
跨语言能力比较
在跨语言能力方面,Qwen2.5-Max和Gemini 2.5表现最为全面。Qwen2.5-Max在中英文处理上有明显优势,同时支持29+种语言;而Gemini 2.5的多语言支持最为广泛,特别在低资源语言上相对表现更好。
值得注意的是,尽管大模型在跨语言能力上取得了显著进步,但低资源语言支持仍然有限,非英语内容的推理深度通常较浅,这是未来需要改进的方向。
上下文窗口与响应速度
在上下文窗口方面,Gemini 2.5和GPT-4.1以100万token的容量领先,而GPT-4o以约320毫秒的响应速度成为最快的模型。长上下文窗口为处理大型文档和代码库提供了基础,而低延迟响应则使实时对话更加自然流畅。
模型架构的演进:密集VS混合专家

2025年的大模型架构呈现两条主要发展路线:
-
密集型架构:如GPT-4o、Claude 3.7和部分Gemini模型采用的传统Transformer架构,每个输入都激活全部参数,多模态集成表现更佳。
-
混合专家(MoE)架构:如DeepSeek R1和Qwen2.5-Max采用的新型架构,将参数分散到多个"专家"模块,每次处理仅激活部分参数,在计算效率上具有显著优势。
MoE架构允许模型在不显著增加计算成本的情况下扩展到数千亿参数,代表了大模型发展的重要方向。同时,推理机制创新也成为新趋势,各大模型都在探索如何增强推理能力和思考深度。
适用场景与选择建议
不同的大模型由于其设计理念和优化重点不同,在各类应用场景中表现各异。以下是六大模型最适合的应用场景:
GPT-4o:实时多模态交互的首选
适用场景:
- 实时多模态应用,如视频会议助手
- 多语言实时翻译与对话
- 需要低延迟的用户交互场景
- 音视频内容创作和编辑
Claude 3.7:深度推理与编程的专家
适用场景:
- 高级软件开发与代码分析
- 需要深度推理的复杂问题解决
- 超长输出内容生成,如研究报告
- 代码库架构分析和优化
DeepSeek R1:数学推理与开源定制
适用场景:
- 复杂数学和逻辑问题求解
- 需要详细推理过程展示的应用
- 科学研究和学术分析
- 开源定制化开发需求
Gemini 2.5:超长文档与视频分析
适用场景:
- 超长文档和知识库分析
- 视频分析和内容提取
- 需要思考过程可视化的应用
- 多语言全球化应用
Qwen2.5-Max:中文环境与效率优先
适用场景:
- 中英文双语环境最优化
- 高级数学和算法研究
- 计算效率敏感的应用
- 困难推理任务场景
GPT-4.1:多规格编程专家
适用场景:
- 专业软件开发与代码重构
- 大型代码库分析与问题解决
- 需要最新知识的应用
- 多规模部署需求(标准/Mini/Nano)
行业趋势与未来展望

2025年AI大模型呈现几个明显的发展趋势:
-
架构多元化:密集型和MoE架构并行发展,各有所长,MoE架构在计算效率上具有优势,密集架构在多模态集成上表现更佳。
-
推理机制创新:各大模型都在探索增强推理能力的方法,从Claude的扩展思考到Gemini的内置思考过程,代表着不同技术路线。
-
上下文窗口扩展:上下文窗口从十万扩展到百万级别,大大提升了处理长文档和复杂场景的能力。
-
多模态深度集成:从简单的多模态输入支持到深度的跨模态理解和推理,AI正从单一信息处理向类人感知迈进。
-
专业化与通用化并行:一方面是通用模型,另一方面是专业模型,市场正进入细分阶段。
结语:智能时代的多元竞争
2025年的AI大模型已经不再是简单的参数规模竞赛,而是在多个维度上的全面较量。每个模型都有其独特的优势和适用场景,选择时应基于具体需求而非简单的排名。
GPT-4o以其卓越的多模态实时交互能力领先;Claude 3.7凭借深度思考和编程能力脱颖而出;DeepSeek R1通过MoE架构和强化学习实现高效推理;Gemini 2.5以百万token窗口和内置思考能力开创新标准;Qwen2.5-Max在中文处理和MoE效率上独树一帜;GPT-4.1则通过多规格系列满足不同场景需求。
在这个快速迭代的领域,今天的顶级模型很可能在明年就会被新一代技术超越。持续关注技术发展,根据实际需求选择合适的模型,将是我们应对这一变化的最佳策略。
人工智能的未来不再由单一模型定义,而是由多元化的技术路线共同推动,正如人类智能本身也是多维度、多层次的。在这场技术革命中,我们不仅是观察者,更是参与者和塑造者。
网页版:https://page.genspark.site/page/toolu_01XU8wJZAQTWuaTPCdGZC7P4/ai_llm_comparison_2025.html