实现长期记忆与实时响应的平衡艺术
网页版:https://mzfgnzpy.genspark.space
视频版:https://www.youtube.com/watch?v=NAIXf-PMQE8
音频版:https://notebooklm.google.com/notebook/2b6cb868-83a5-4089-8124-4e42862e0895/audio
在人工智能快速发展的今天,智能体(Agent)已经成为AI领域的热点话题。然而,一个真正高效的智能体不仅需要强大的推理能力,更需要一套完善的记忆系统来存储、管理和检索信息。正如人类依靠记忆来学习和成长,AI智能体也需要"记忆"来保持连贯性、积累经验并提供上下文感知的服务。
本文将深入探讨智能体记忆系统的构建,聚焦于向量记忆、知识图谱和分层记忆等混合架构,以及如何在长期记忆存储和实时响应之间取得平衡,为下一代智能体系统打造坚实的记忆基础。
智能体记忆系统概述
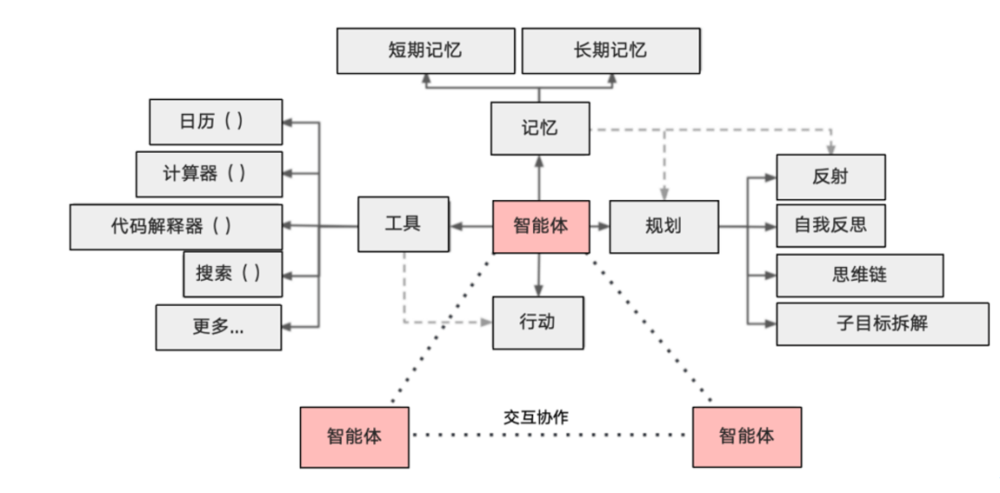
智能体记忆系统是AI智能体的核心组件,它不仅是简单的数据存储,更是一个动态、复杂的系统,能够与智能体的其他功能深度融合,支持智能体"记住"过去的经验和知识,保持交互的连贯性和连续性。
记忆系统的重要性
- 维持对话连贯性 – 让智能体能够理解当前对话的上下文
- 累积经验知识 – 从过去交互中学习,逐渐提升能力
- 个性化交互 – 根据用户历史进行定制化回应
- 提供知识支撑 – 为复杂任务提供必要的知识基础
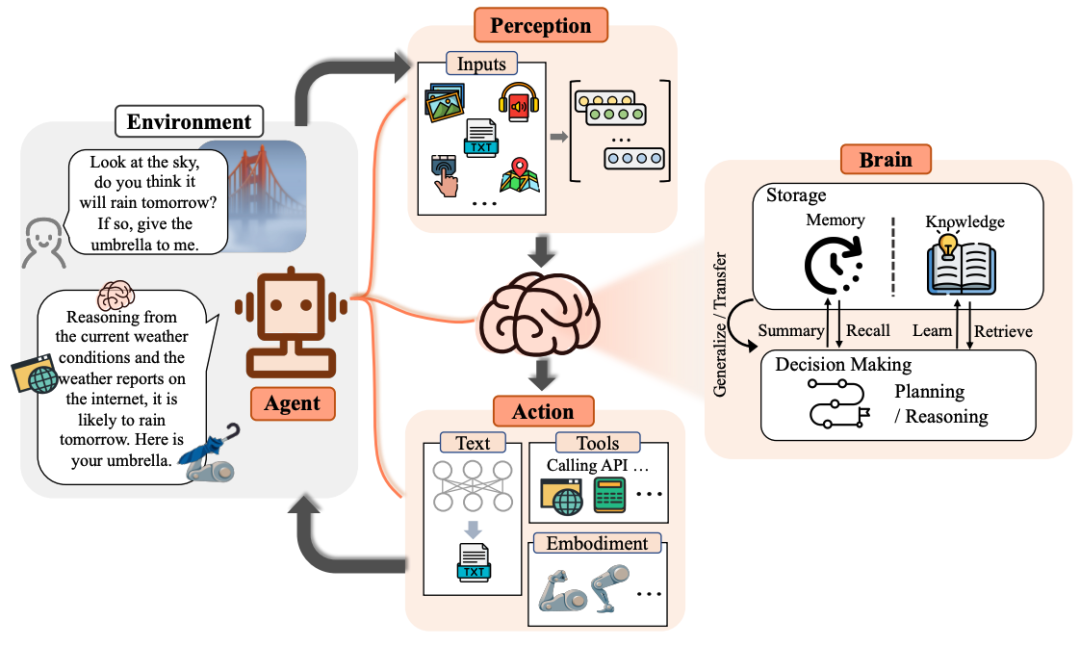
图1:典型智能体架构中的记忆模块位置与作用
记忆系统的基础类型
智能体的记忆系统通常分为两种基本类型:短期记忆和长期记忆。这种分类方式借鉴了人类记忆系统的组织方式,每种类型都有其特定的功能和特点。
短期记忆 (Short-Term Memory)
短期记忆主要负责存储当前会话或最近交互的信息,这些信息对于维持对话的连贯性和即时响应至关重要。
特点:
- 容量有限,通常基于上下文窗口实现
- 访问速度快,支持实时交互
- 信息临时性强,旧信息容易被覆盖
- 主要用于维持对话连贯性和即时响应
在实践中,短期记忆通常通过保留最近N轮对话或设定上下文窗口来实现,例如GPT模型的对话上下文窗口。
长期记忆 (Long-Term Memory)
长期记忆用于存储持久化的知识和历史信息,是智能体积累经验和知识的关键。
特点:
- 容量大,可保存大量历史信息
- 需要通过检索机制访问
- 信息持久性强,可长期保存
- 主要用于累积知识和经验学习
长期记忆通常需要借助外部存储系统实现,如向量数据库、关系数据库或知识图谱等。
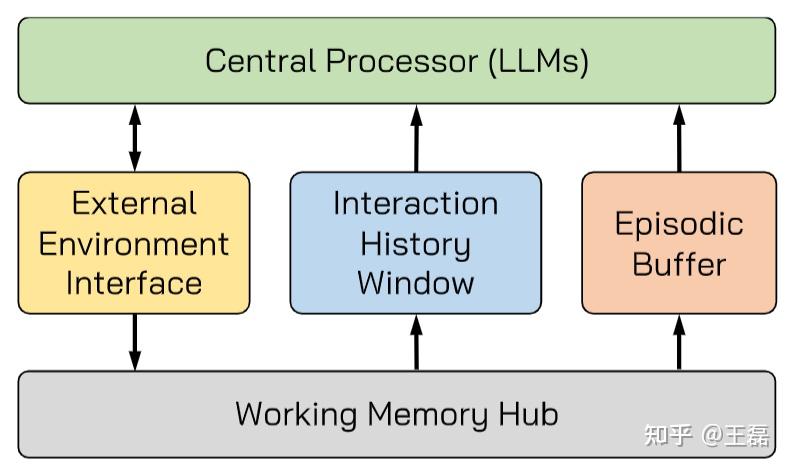
图2:短期记忆与长期记忆的结构对比
向量记忆架构
向量记忆是目前智能体记忆系统中应用最为广泛的架构之一,它基于向量嵌入(embeddings)技术,将文本或其他形式的信息转换为高维向量表示,通过计算向量相似度进行信息检索。
工作原理
向量记忆系统的核心思想是将语义信息编码为高维向量,使得语义相似的内容在向量空间中的距离更近。当需要检索信息时,系统将查询同样转换为向量,然后找到最相似的已存储向量及其对应的信息。
图3:向量数据库在智能体记忆系统中的应用
核心技术组件
- 嵌入模型:将文本等信息转换为密集向量表示的神经网络模型
- 向量数据库:专门存储和检索向量数据的数据库系统,如Pinecone、Milvus、FAISS
- 相似度计算:通常使用余弦相似度或欧氏距离等度量方法
- 索引技术:如HNSW、ANN等高效近似最近邻搜索算法
优势与局限
优势:
- 高效处理非结构化数据
- 支持语义搜索和相似度匹配
- 查询速度快,适合实时应用
- 易于集成到现有智能体系统
- 扩展性好,可处理海量数据
局限:
- 无法表示实体间的复杂关系
- 较难处理时序和因果关系
- 缺乏逻辑推理能力
- 维度灾难问题可能降低效率
- 信息更新可能导致向量漂移
# 向量记忆系统的简单实现示例
from sentence_transformers import SentenceTransformer
import numpy as np
# 1. 初始化嵌入模型
model = SentenceTransformer('all-MiniLM-L6-v2')
# 2. 创建简单的向量存储
memory_texts = ["用户喜欢看科幻电影", "用户居住在北京", "用户是一名软件工程师"]
memory_embeddings = model.encode(memory_texts)
# 3. 查询记忆
query = "用户的工作是什么?"
query_embedding = model.encode([query])[0]
# 4. 计算相似度并检索最相关记忆
similarities = np.dot(memory_embeddings, query_embedding) / (
np.linalg.norm(memory_embeddings, axis=1) * np.linalg.norm(query_embedding)
)
most_similar_idx = np.argmax(similarities)
print(f"查询: {query}")
print(f"检索到的记忆: {memory_texts[most_similar_idx]}")
print(f"相似度得分: {similarities[most_similar_idx]:.4f}")
知识图谱架构
知识图谱是一种结构化的知识表示方法,以图形结构存储实体和实体间的关系,为智能体提供更加丰富的语义理解能力。相比向量记忆,知识图谱能够更好地表示复杂的关系网络和支持逻辑推理。
工作原理
知识图谱以节点(实体)和边(关系)的形式构建信息网络。节点代表实体(如人、地点、概念等),边表示实体之间的关系(如"是"、"属于"、"创建"等)。通过这种结构化表示,智能体可以追踪实体之间的复杂关系,进行多跳推理,并理解信息的上下文。

图4:知识图谱与向量数据库比较示意图
核心技术组件
- 实体识别与关系提取:从文本中识别实体和它们之间的关系
- 图数据库:如Neo4j、ArangoDB等专门存储图结构的数据库
- 图查询语言:如Cypher、SPARQL等用于查询图结构的语言
- 知识融合:将不同来源的知识整合到统一的图谱中
- 推理引擎:基于图结构进行逻辑和路径推理
优势与局限
优势:
- 可表示复杂的实体关系网络
- 支持多跳推理和路径查询
- 能清晰表示因果和层次关系
- 信息结构化程度高,易于理解
- 便于可视化和人机交互
局限:
- 构建成本高,需要专业知识
- 难以处理大量非结构化信息
- 更新维护复杂度高
- 对模糊概念的表达能力有限
- 规模扩大时查询性能可能下降
下面是一个简单的知识图谱在智能体记忆中的应用例子:
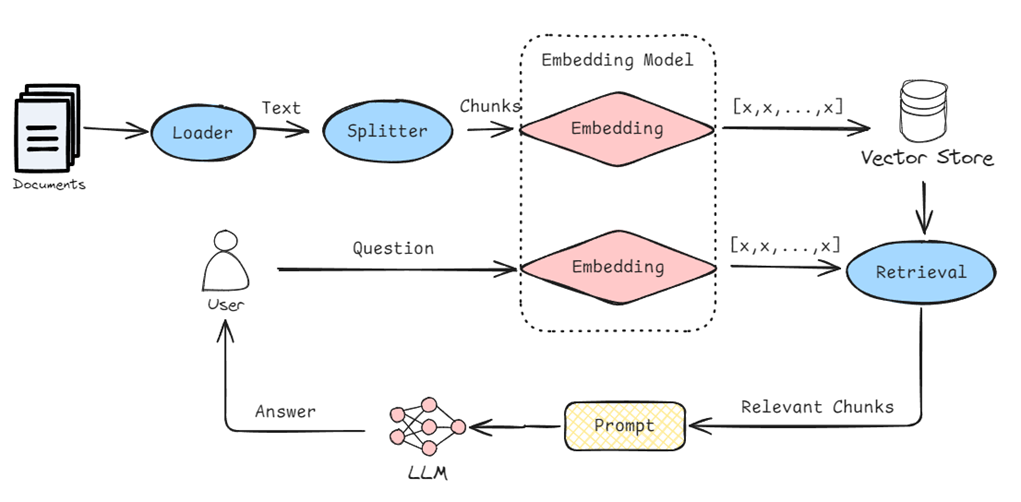
图5:结合向量数据库与知识图谱的记忆系统
分层记忆架构
分层记忆架构借鉴了人类记忆系统的组织方式,将记忆按照不同的层次和时间跨度进行分类和管理,使智能体能够更自然地使用不同类型的记忆。
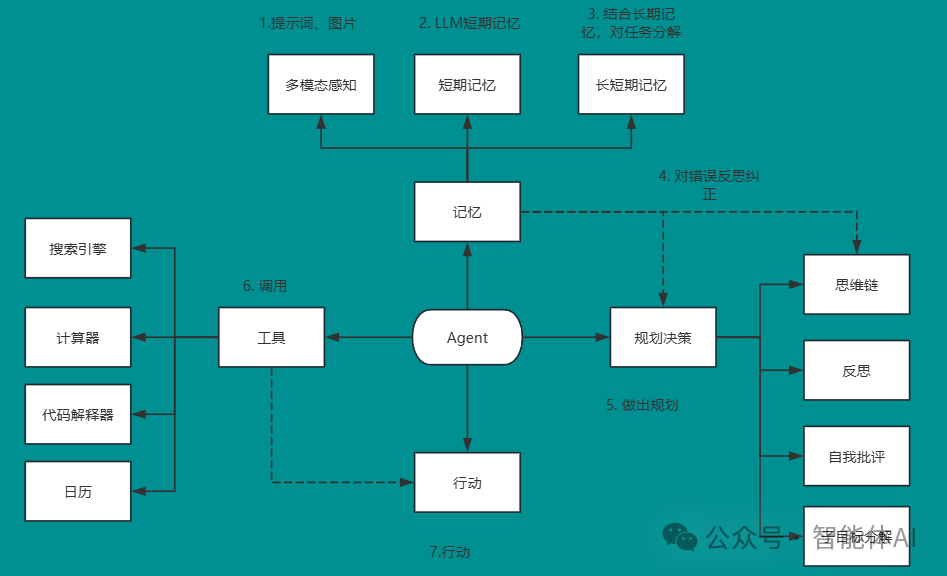
图6:智能体的分层记忆架构
典型层次结构
分层记忆架构通常包含以下几个层次:
| 记忆层次 | 时间跨度 | 存储内容 | 访问机制 | 实现技术 |
|---|---|---|---|---|
| 工作记忆 | 秒到分钟 | 当前任务相关信息 | 直接访问 | 上下文窗口 |
| 情节记忆 | 小时到天 | 近期交互和经历 | 检索 | 向量存储 |
| 语义记忆 | 长期 | 概念知识和事实 | 检索+推理 | 知识图谱 |
| 程序记忆 | 长期 | 技能和解决方案 | 联想 | FSM/检索增强生成 |
记忆转换机制
分层记忆架构的核心是不同层次之间的记忆转换机制,这使得智能体可以根据需要在不同记忆层次间进行信息流转:
- 记忆固化:将短期记忆中的重要信息转移到长期记忆
- 记忆提取:从长期记忆中检索相关信息到工作记忆
- 记忆更新:基于新信息更新已存在的记忆
- 记忆遗忘:根据重要性和时效性清理过期记忆
案例:SecondMe的三层混合记忆架构
SecondMe利用LLM自身能力,构建了一个AI原生的、分层的、个性化的记忆系统,包含三个层次:
- 短期记忆:存储最近的对话内容,维持对话连贯性
- 长期事实记忆:存储用户的个人信息和偏好
- 隐式人格记忆:捕捉用户的隐式价值观和行为模式
这种架构不仅能处理信息,更能深度理解和利用与特定用户相关的长期、隐式知识。
图7:分层记忆架构的实际应用示例
混合记忆架构
混合记忆架构整合了向量记忆、知识图谱和分层记忆的优势,构建一个多模态、多功能的智能体记忆系统,既能高效检索相关信息,又能理解复杂的实体关系网络。
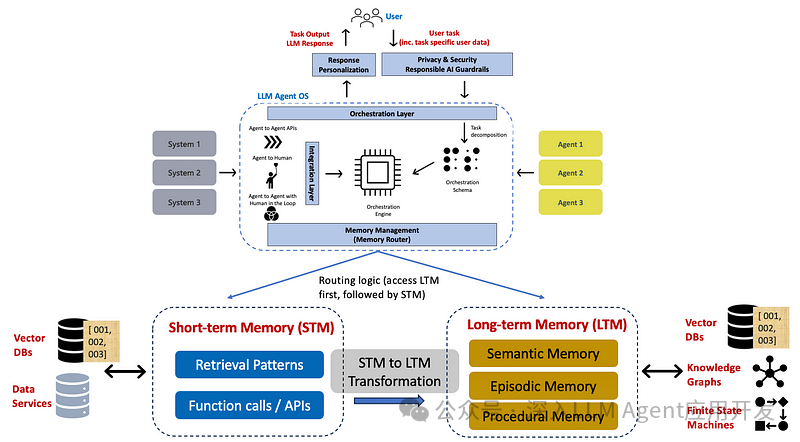
图8:智能体混合记忆管理系统架构示意图
架构组成
一个典型的混合记忆架构通常包含以下关键组件:
向量存储层
用于高效存储和检索非结构化数据,支持相似度搜索和语义匹配。
知识图谱层
表示实体和关系网络,支持结构化查询和逻辑推理。
记忆管理层
协调不同记忆类型,处理记忆的固化、提取和遗忘等过程。
记忆路由器
在STM(短期记忆)和LTM(长期记忆)模块之间路由请求,决定信息的流向。
STM到LTM转换器
负责将短期记忆中的重要信息抽象和存储到长期记忆系统中。
混合架构优势
- 全面记忆表示:同时支持非结构化(向量)和结构化(图谱)记忆表示
- 多维度推理能力:结合语义相似性搜索和关系网络推理
- 适应性记忆管理:根据记忆类型和任务需求灵活调整记忆策略
- 记忆性能均衡:在访问速度和表示丰富度之间取得平衡
- 多模态信息处理:能处理文本、结构化数据、关系等多种形式的信息
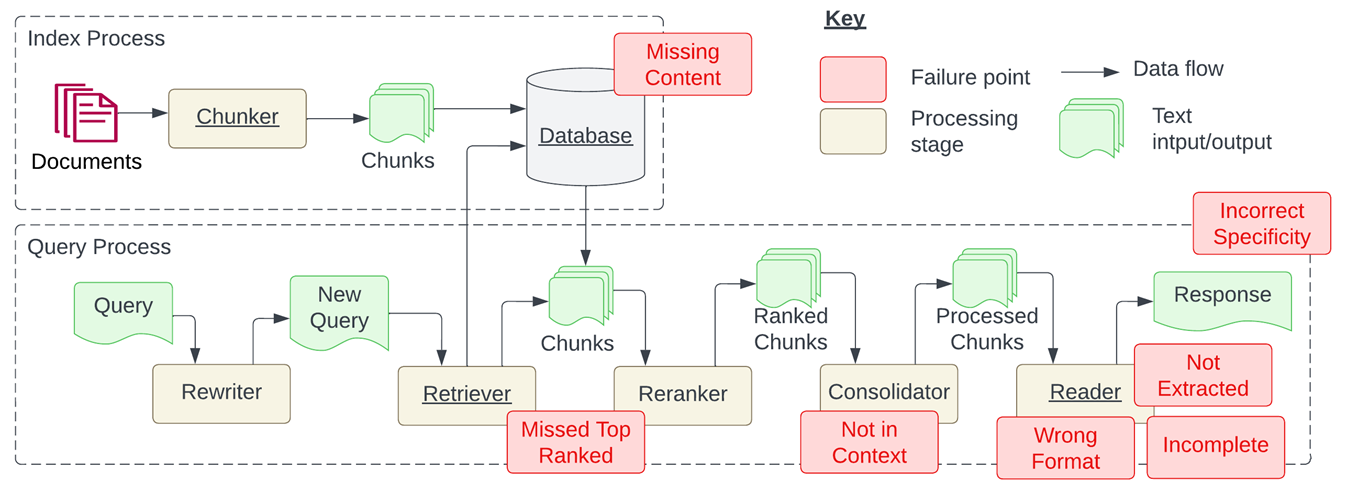
图9:结合向量存储和知识图谱的混合记忆架构实现
长期记忆与实时响应平衡
实现长期记忆与实时响应的平衡是智能体记忆系统最关键的挑战之一。这需要在记忆的完整性和系统响应速度之间找到最佳折衷点。
平衡策略
分级缓存机制
类似计算机的多级缓存系统,智能体记忆可以构建多级缓存架构:
- L1缓存:当前对话上下文(超快速访问)
- L2缓存:近期相关记忆(快速访问)
- L3缓存:常用知识和经验(较快访问)
- 主存储:完整长期记忆(较慢访问)
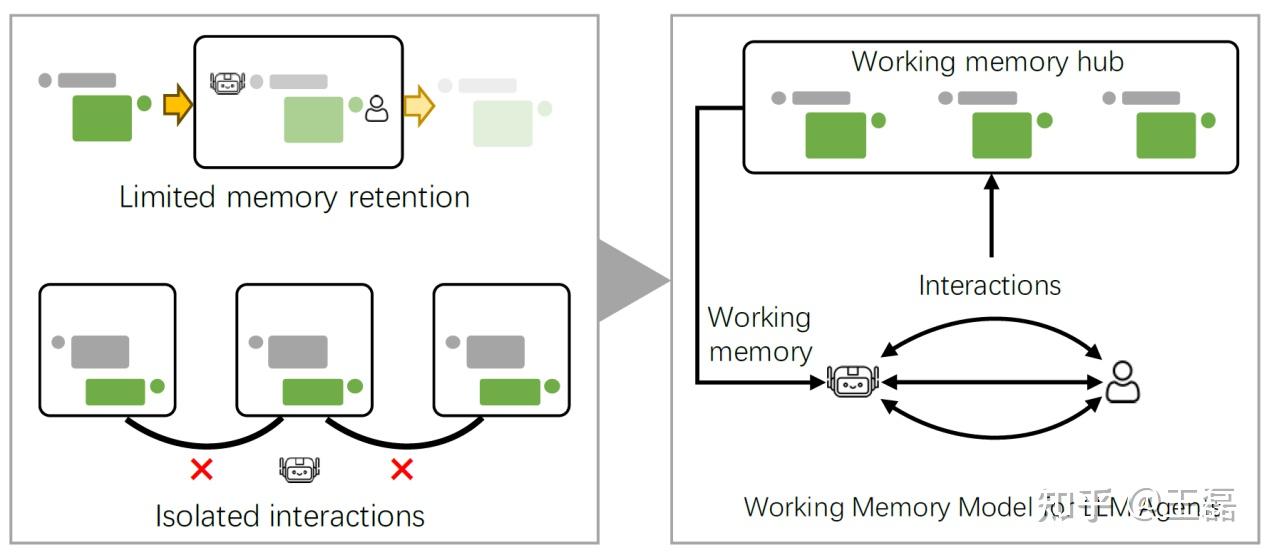
图10:大语言模型记忆缓存机制
预测性记忆加载
系统预测可能需要的记忆,提前加载到快速访问层:
- 基于当前对话主题预加载相关记忆
- 根据用户历史偏好预加载个性化信息
- 识别对话意图,预加载相应任务知识
- 使用记忆访问模式进行智能预取
异步记忆管理
将记忆操作与对话流程解耦,提高响应速度:
- 响应生成与记忆检索并行进行
- 后台异步索引和整理记忆
- 增量更新记忆结构
- 使用工作队列管理记忆任务
自适应记忆压缩
根据重要性和使用频率压缩和概括记忆:
- 将详细记忆压缩为概括摘要
- 保留关键信息点,舍弃次要细节
- 根据使用频率动态调整压缩率
- 层次化存储不同粒度的记忆
实现案例
许多前沿的智能体记忆系统已经在实际应用中取得了显著成果,以下是几个典型案例:
MemO系统
MemO(Memory Organization)是一个为AI智能体打造的可扩展长时记忆系统,通过基于自然语言的MemO和基于知识图谱的MemOᴳ两种架构实现类似人类的记忆能力。
关键特点:
- 自动组织和结构化记忆
- 多层次记忆整合
- 知识图谱与向量存储结合
应用效果: 在LOCOMO基准测试中,MemO系统以26%的优势超越现有技术,展示了显著性能提升。
Zep AI记忆层
Zep AI推出的记忆层插件能将智能体记忆组织成情节并存储于知识图谱,实现长期记忆管理。
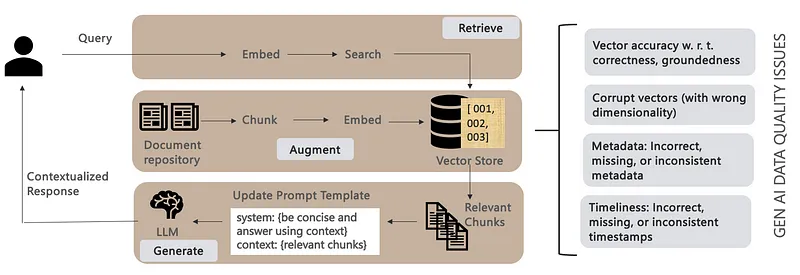
图11:Zep AI记忆层架构
关键特点:
- 时间感知的动态知识图谱
- 从对话中提取"情节"信息
- 将信息组织成层次结构
- 自动生成摘要和相关信息
Memary开源项目
Memary是一个赋予Agent智能体长期记忆能力的开源项目,通过多种存储技术实现记忆功能。
关键特点:
- 自动建立记忆,无需人工介入
- 仿人记忆架构,模仿人类记忆系统
- 利用Neo4j构建知识图谱
- 支持向量数据库存储和检索
实现代码片段:
# Memary开源项目记忆存储示例
from memary import MemorySystem
from memary.providers import VectorStoreProvider, KnowledgeGraphProvider
# 初始化混合记忆系统
memory_system = MemorySystem()
# 添加向量存储提供者
vector_provider = VectorStoreProvider(embedding_model="all-MiniLM-L6-v2")
memory_system.add_provider(vector_provider)
# 添加知识图谱提供者
graph_provider = KnowledgeGraphProvider(connection_uri="bolt://localhost:7687")
memory_system.add_provider(graph_provider)
# 存储记忆
memory_system.store(
content="用户王先生喜欢阅读科幻小说,特别是刘慈欣的作品",
metadata={"source": "conversation", "timestamp": "2025-05-07T10:30:00Z"}
)
# 检索记忆
relevant_memories = memory_system.retrieve("用户的阅读偏好是什么?")
未来发展趋势
随着人工智能技术的不断进步,智能体记忆系统将朝着更加智能、高效和灵活的方向发展。以下是几个值得关注的发展趋势:
自适应记忆架构
未来的智能体记忆系统将能够根据任务需求和资源限制,自动调整记忆结构和访问策略,实现资源与性能的最优平衡。
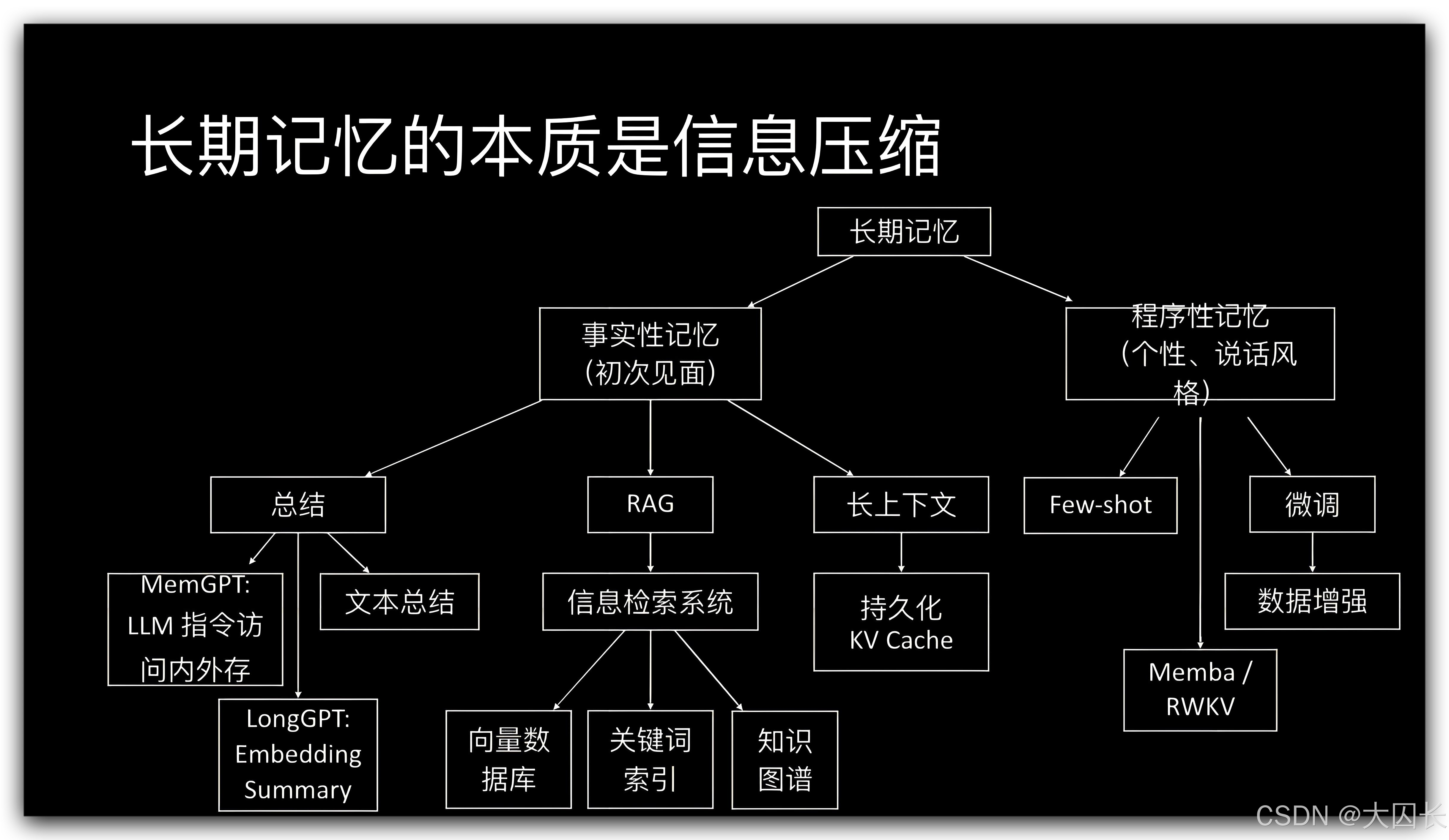
图12:AI与人类记忆比较及未来发展方向
多模态记忆整合
记忆系统将支持文本、图像、音频等多种模态信息的存储和检索,实现更全面的知识表示和理解能力。
分布式协作记忆
多个智能体将能够共享和交换记忆,形成集体智慧,同时保持个体特性,类似于人类社会的知识传播和积累。
智能体记忆系统的终极目标
构建智能体记忆系统的终极目标是创造一个能够像人类一样灵活、高效地管理记忆的AI系统,它应当:
- 理解记忆的情境和重要性
- 自动组织和关联不同的记忆片段
- 根据需要进行记忆的固化、提取和遗忘
- 在记忆的完整性和系统响应性之间取得动态平衡
- 支持从记忆中学习和推理的能力
- 在保护隐私的同时实现记忆共享