想象一下,你站在一座巨大的图书馆里,面前有数千本书籍,每本书都代表着一个特征维度。你需要从这个复杂的高维空间中找到最重要的信息,就像是在浓雾中寻找灯塔一样。这正是数据科学家们在处理高维数据时面临的挑战。
网页版:https://lijoktlz.gensparkspace.com
视频版:https://www.youtube.com/watch?v=1IOw0u4xQoU
音频版:https://notebooklm.google.com/notebook/1970e9be-3515-4c5f-8f0f-0acee585bc0f/audio
今天,我们将踏上一场奇妙的降维技术探索之旅,从经典的主成分分析(PCA)到现代的UMAP,看看这些技术如何帮助我们从数据的迷雾中找到清晰的洞察。
维度灾难:高维世界的困扰

在我们开始技术探索之前,先聊聊为什么降维如此重要。在高维空间中,数据会表现出一些违反直觉的特性,这就是所谓的"维度灾难"。
想象一个简单的例子:在一维空间(一条线)上,两个随机点之间的平均距离相对较小。但随着维度增加,奇怪的事情发生了。在高维空间中,几乎所有点都会变得等距离,这意味着传统的距离度量失去了意义。
研究表明,当维度超过20时,欧几里得距离的区分能力会急剧下降。在某些情况下,最近邻和最远邻之间的距离差异可能小于5%。这直接影响了聚类算法、最近邻搜索和许多机器学习模型的性能,正如维度灾难研究所指出的。
PCA:寻找最大方差的方向
主成分分析(PCA)就像是一位经验丰富的摄影师,知道从哪个角度拍摄才能捕捉到最多的信息。PCA的核心思想是找到数据中方差最大的方向,因为方差大的方向通常包含更多的信息。
PCA的数学原理
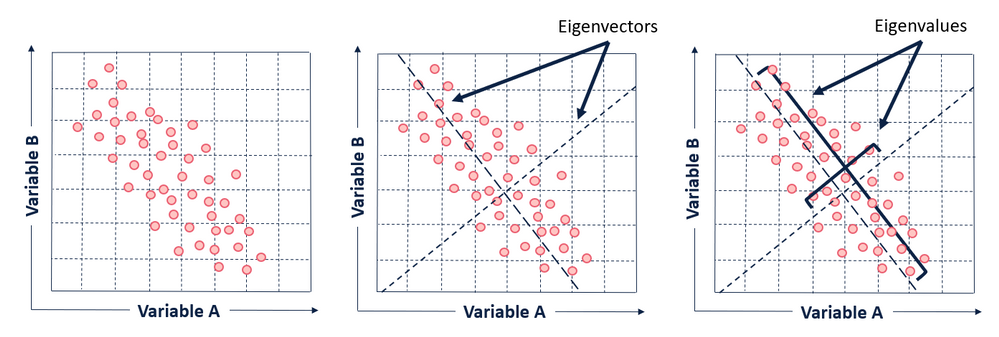
PCA的工作原理基于线性代数中的特征值分解。整个过程可以分为几个关键步骤:
首先,我们需要对数据进行标准化处理。这一步至关重要,因为PCA对特征的尺度非常敏感。假设我们有身高(以厘米为单位)和体重(以千克为单位)两个特征,如果不进行标准化,身高的数值范围(150-200)会远大于体重除以1000后的范围,导致PCA主要关注身高这个特征。
接下来是计算协方差矩阵。协方差矩阵揭示了特征之间的相关性。对于n维数据,协方差矩阵是一个n×n的对称矩阵,其中对角线元素表示各特征的方差,非对角线元素表示特征间的协方差。
最关键的步骤是对协方差矩阵进行特征值分解。特征向量指示了主成分的方向,而特征值则表示了在该方向上的方差大小。根据特征值的大小对特征向量进行排序,特征值最大的特征向量就是第一主成分,依此类推。
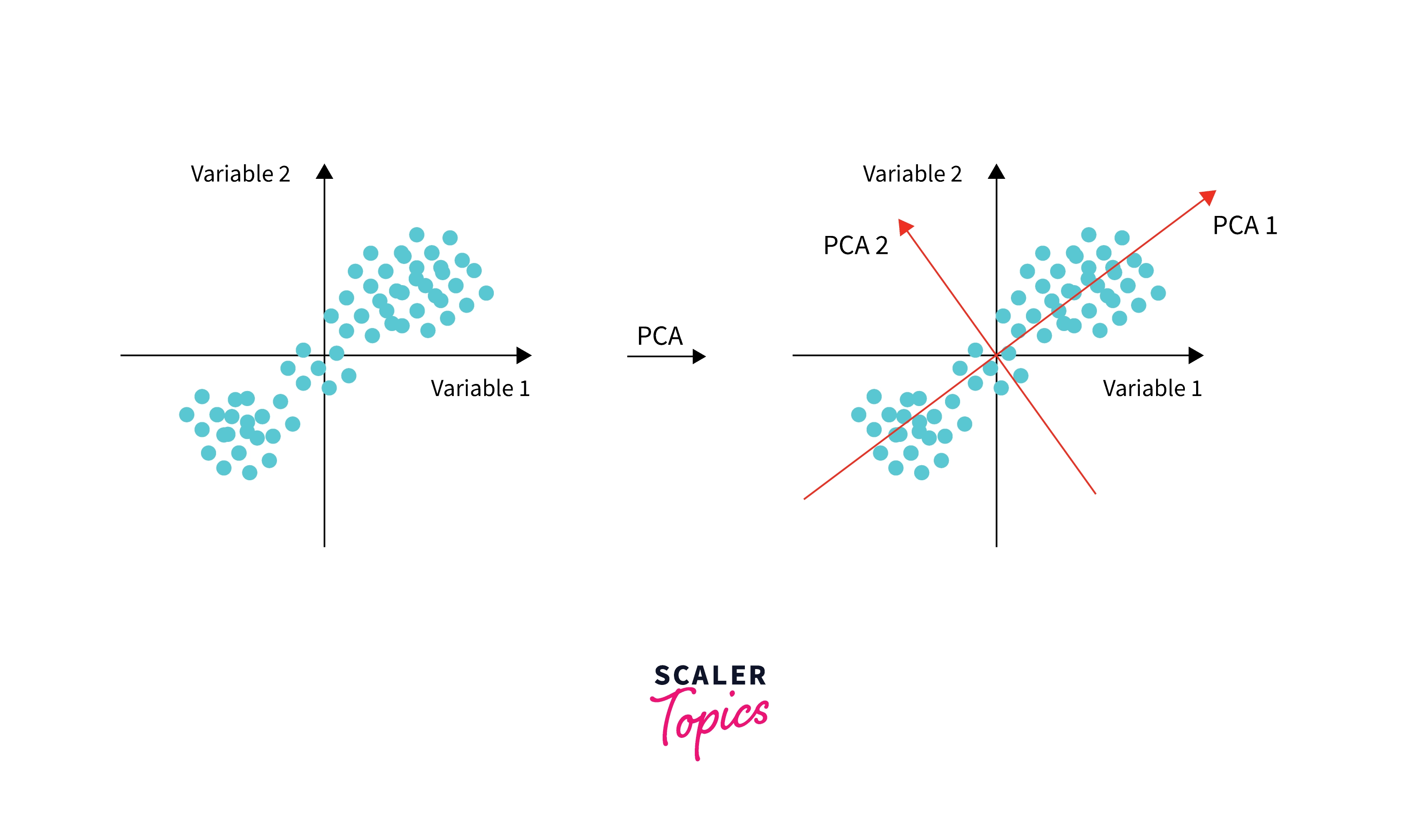
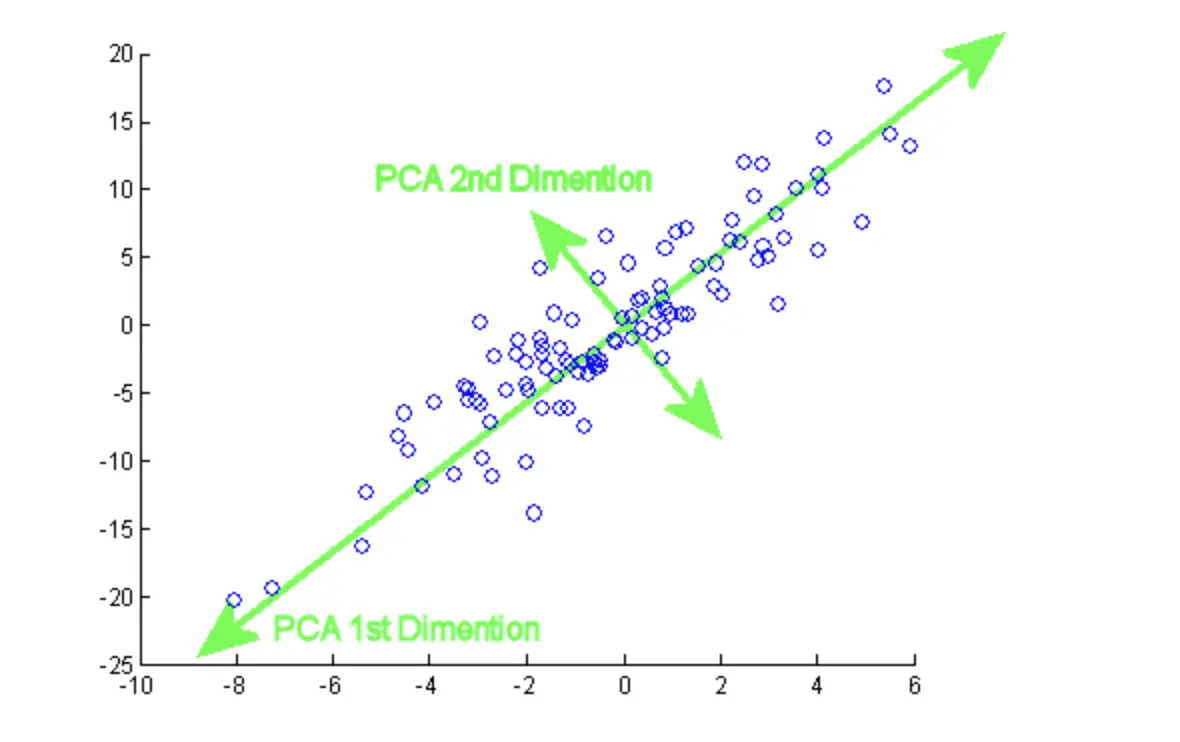
PCA的几何直观

从几何角度来看,PCA寻找的是一组新的坐标轴,使得数据在这些轴上的投影具有最大的方差。这些新的坐标轴是原始特征的线性组合,且彼此正交(垂直)。
想象一个椭圆形的数据分布。PCA会找到椭圆的长轴作为第一主成分,因为数据在这个方向上的变化最大。短轴则成为第二主成分。通过这种方式,我们可以用较少的维度(比如只保留长轴方向)来近似表示原始数据,同时保留大部分信息。
根据Principal Component Analysis的详细分析,在实际应用中,通常保留能够解释80-95%方差的主成分。这个选择涉及信息保留和维度减少之间的权衡。
t-SNE:保持局部结构的艺术

如果说PCA是一位理性的数学家,那么t-SNE就像是一位敏感的艺术家,它不仅关心整体的结构,更在意局部的细节。t-SNE(t-distributed Stochastic Neighbor Embedding)是一种非线性降维技术,特别擅长保持数据的局部结构。
t-SNE的工作原理
t-SNE的核心思想是在高维空间中,相似的数据点应该在低维空间中也保持相似。它通过两个步骤来实现这一目标:
第一步是在高维空间中计算点之间的相似性。t-SNE使用高斯分布来定义相似性,相近的点具有较高的相似性概率,远离的点相似性概率接近零。这个过程中有一个重要的参数叫做"perplexity"(困惑度),它控制着每个点考虑多少个邻居。
第二步是在低维空间中寻找一个布局,使得点之间的相似性概率尽可能接近高维空间中的相似性。这里使用的是t分布而不是高斯分布,t分布的重尾特性使得在低维空间中相对远离的点不会被过度吸引到一起。
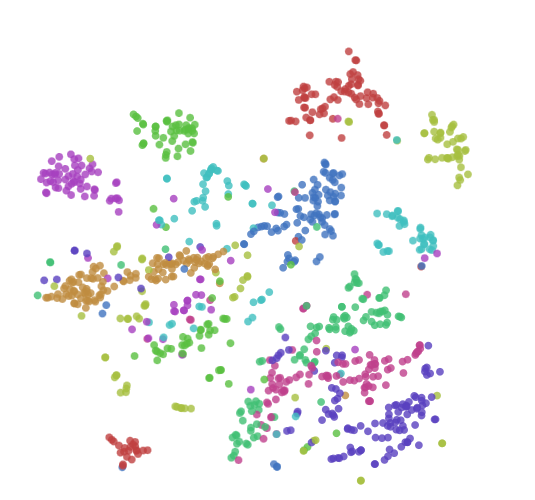
t-SNE的可视化魅力

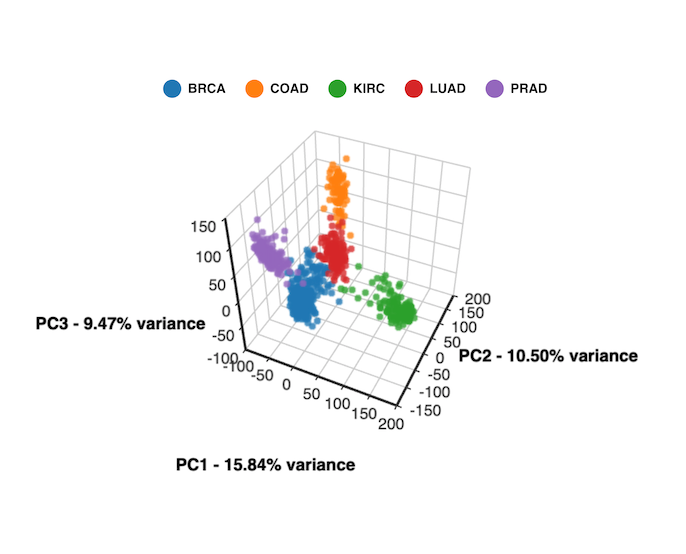
t-SNE最著名的应用之一是对MNIST手写数字数据集的可视化。在这个案例中,原本784维的图像数据(28×28像素)被映射到2维平面上,不同的数字自然地聚集成不同的群组,展现出令人惊叹的聚类效果。
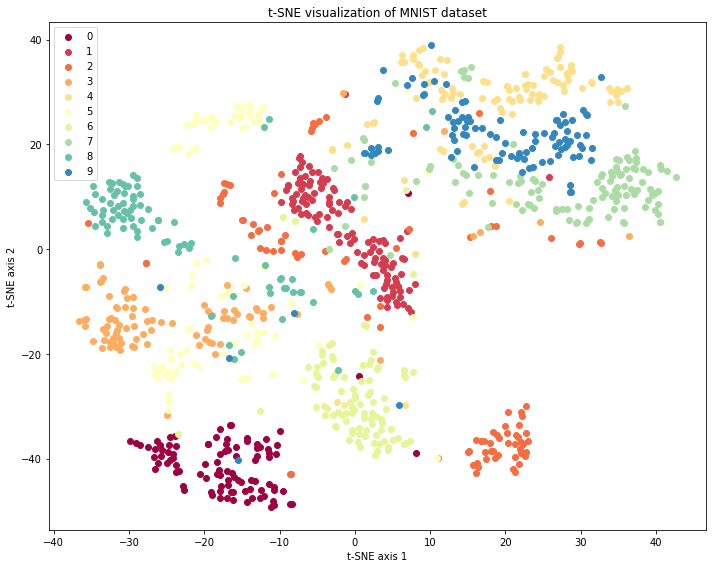
与PCA相比,t-SNE能够揭示数据中的非线性结构。例如,在处理人脸数据时,PCA可能只能捕捉到光照变化等线性因素,而t-SNE能够发现更复杂的模式,如表情变化、头部角度等非线性特征。
但t-SNE也有其局限性。它的计算复杂度较高,对于大数据集可能需要很长时间。此外,t-SNE的结果对参数设置敏感,不同的perplexity值可能产生截然不同的可视化结果。
UMAP:流形学习的新星
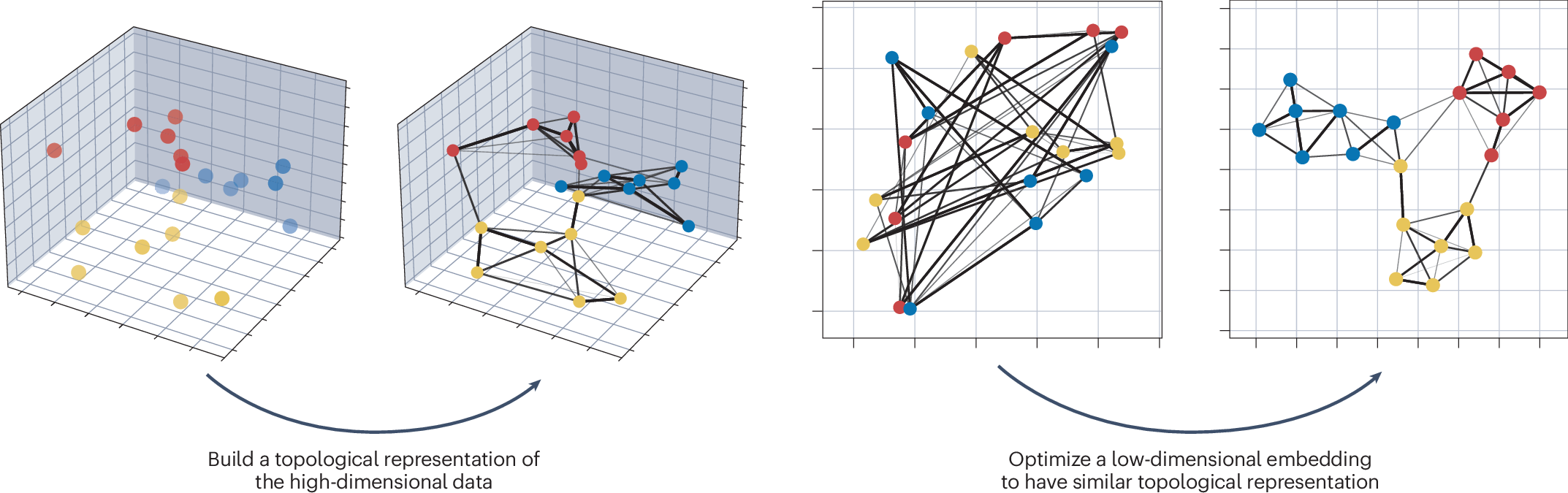
UMAP(Uniform Manifold Approximation and Projection)是降维技术中的新星,它结合了数学的严谨性和实用性的考量。如果把降维技术比作交通工具,PCA就像是直升机,能够快速到达目的地但路径相对简单;t-SNE像是一位细心的导游,会带你走过每一个有趣的角落但速度较慢;而UMAP则像是一辆智能汽车,既快速又能适应复杂的道路。
UMAP的理论基础
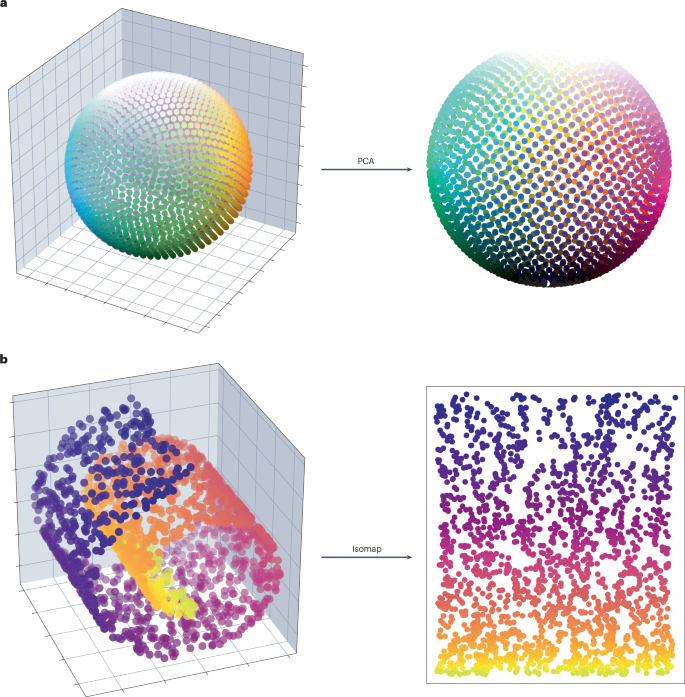
UMAP基于三个核心假设:数据均匀分布在黎曼流形上;黎曼度量局部恒定;流形局部连通。这些假设使得UMAP能够用模糊拓扑结构来建模流形,然后寻找在低维空间中具有最相似拓扑结构的嵌入。
这听起来可能很抽象,让我们用一个比喻来理解。想象你有一张皱巴巴的纸(高维数据),你想把它平铺在桌面上(低维映射)。UMAP的方法是首先理解纸张的局部连接关系(哪些部分原本是相邻的),然后在平铺时尽量保持这些局部关系不变。
UMAP的优势

相比于t-SNE,UMAP有几个显著优势。首先是速度,UMAP的计算效率远高于t-SNE,对于包含数百万个数据点的大数据集,UMAP仍能在合理时间内完成计算。

其次是全局结构的保持。t-SNE主要关注局部结构,可能会丢失数据的全局组织信息。而UMAP在保持局部结构的同时,也较好地保持了全局结构。这意味着在UMAP的可视化结果中,不同群组之间的相对距离更有意义。
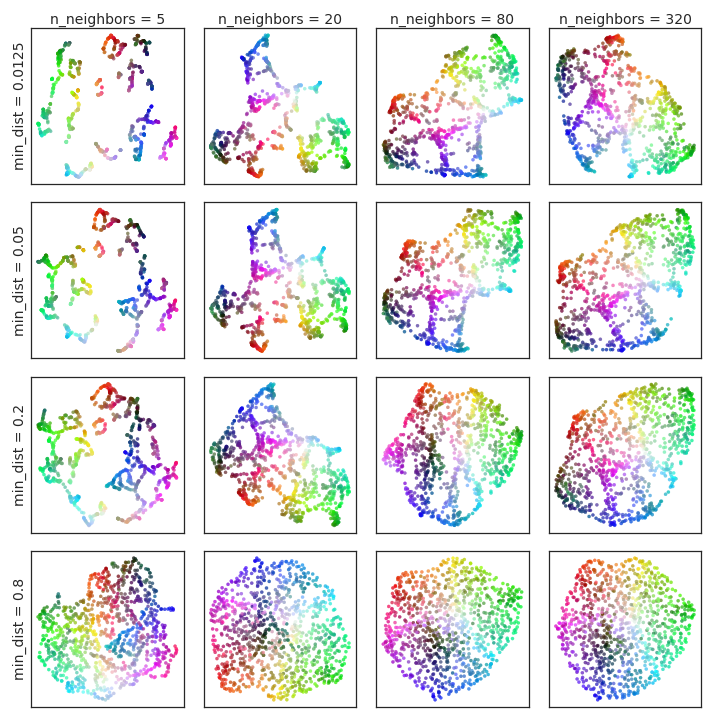
根据UMAP的官方文档,UMAP还支持有监督和半监督的降维,这使得它能够利用标签信息来改进降维效果。
LDA:有监督的降维智慧

线性判别分析(LDA)是降维技术中的"智者",它不仅要降低维度,还要确保降维后的数据更有利于分类任务。与PCA专注于最大化方差不同,LDA的目标是最大化类间差异的同时最小化类内差异。
LDA的核心思想
LDA试图找到一个投影方向,使得不同类别的数据在这个方向上尽可能分离,而同一类别的数据尽可能聚集。这就像是在拍摄一张集体照时,摄影师会选择一个角度,让不同组的人尽可能分开,而同组的人尽可能靠近。
数学上,LDA寻找的是使得Fisher判别准则最大的投影方向。Fisher准则定义为类间散布矩阵与类内散布矩阵的比值。类间散布矩阵衡量不同类别重心之间的距离,类内散布矩阵衡量每个类别内部数据的分散程度。
LDA vs PCA
LDA和PCA的区别可以通过一个简单的例子来说明。假设我们有两类数据,一类是红色点,一类是蓝色点。如果这两类数据在某个方向上重叠较多,但在垂直方向上分离较好,PCA可能会选择方差最大的方向(可能是重叠的方向),而LDA会选择能够更好分离两类数据的方向。
根据Linear Discriminant Analysis的研究,LDA在有监督学习任务中通常比PCA表现更好,特别是当数据的最大方差方向不利于分类时。
实战案例:人脸识别中的降维应用
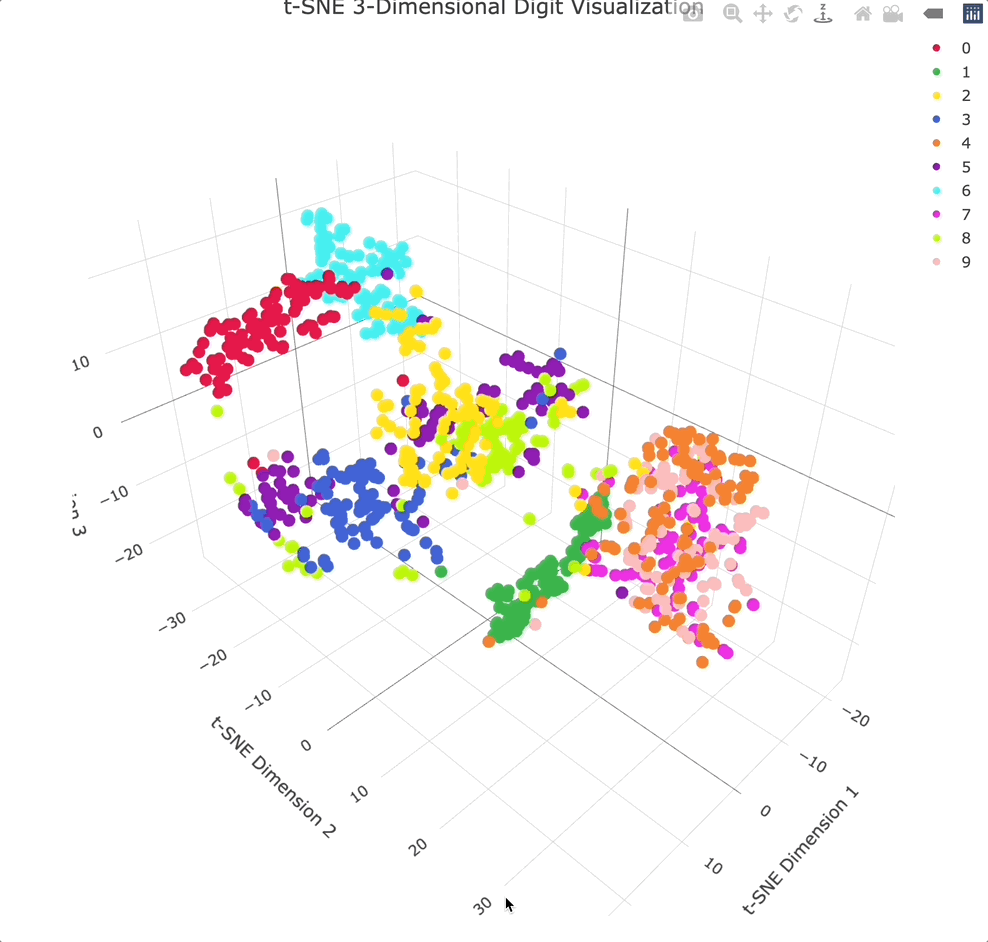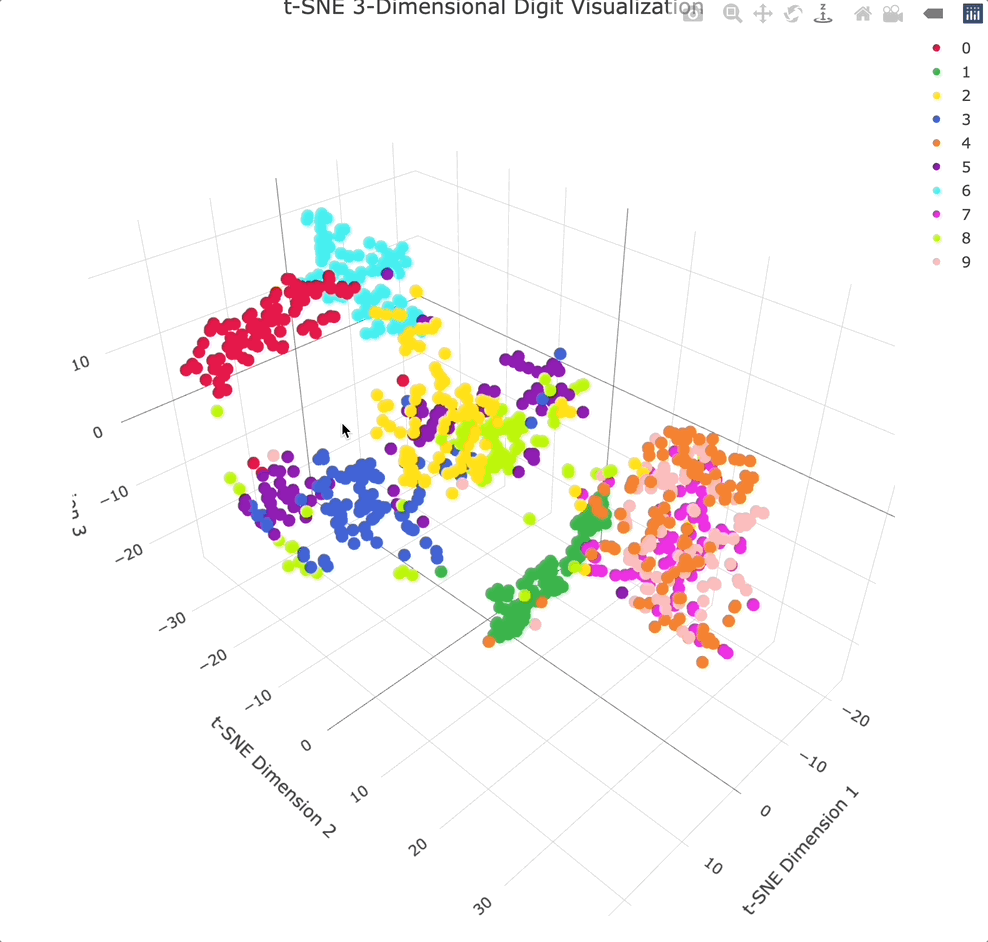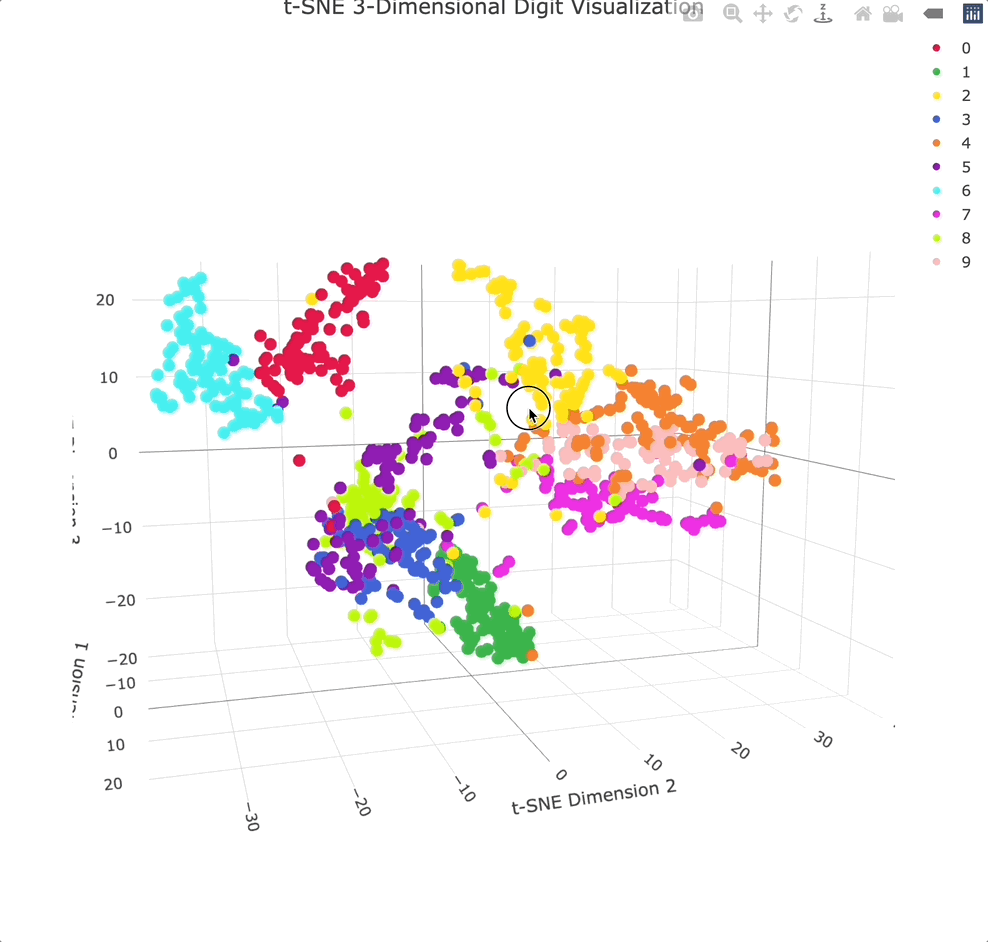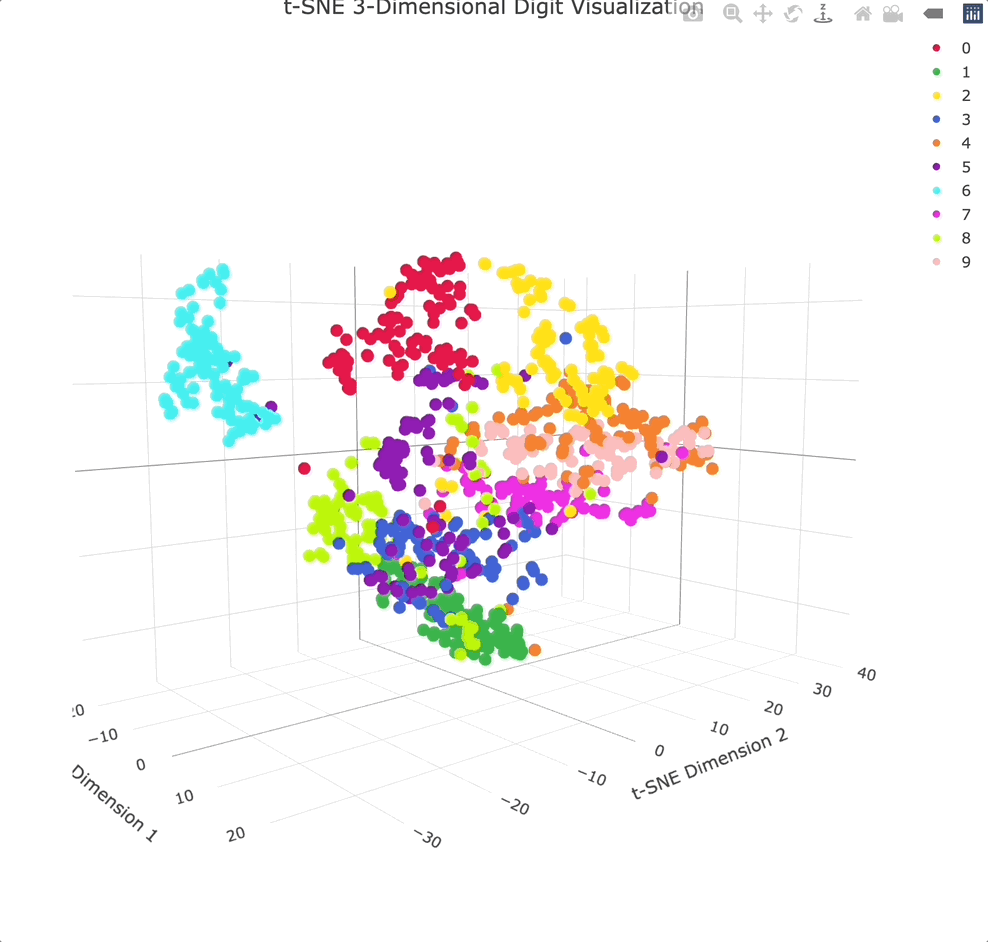
让我们通过Olivetti人脸数据集来看看这些降维技术的实际效果。这个数据集包含40个人的400张人脸图像,每张图像是64×64像素,即4096维的向量。
PCA在人脸识别中的应用
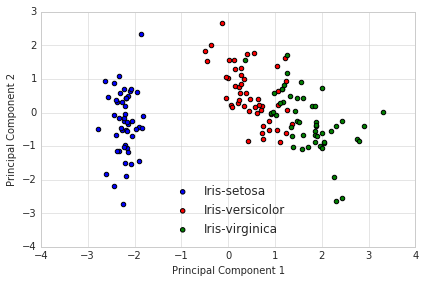
在人脸识别任务中,PCA被称为"特征脸"(Eigenfaces)方法。通过PCA,我们可以找到最能解释人脸变化的主要方向。通常,前50-100个主成分就能捕捉到人脸的主要特征,包括光照变化、姿态变化等。
使用PCA进行降维后,人脸识别的准确率通常能达到85-90%。更重要的是,存储和计算需求大大减少。原本需要4096个数字来表示一张人脸,现在只需要50-100个数字。
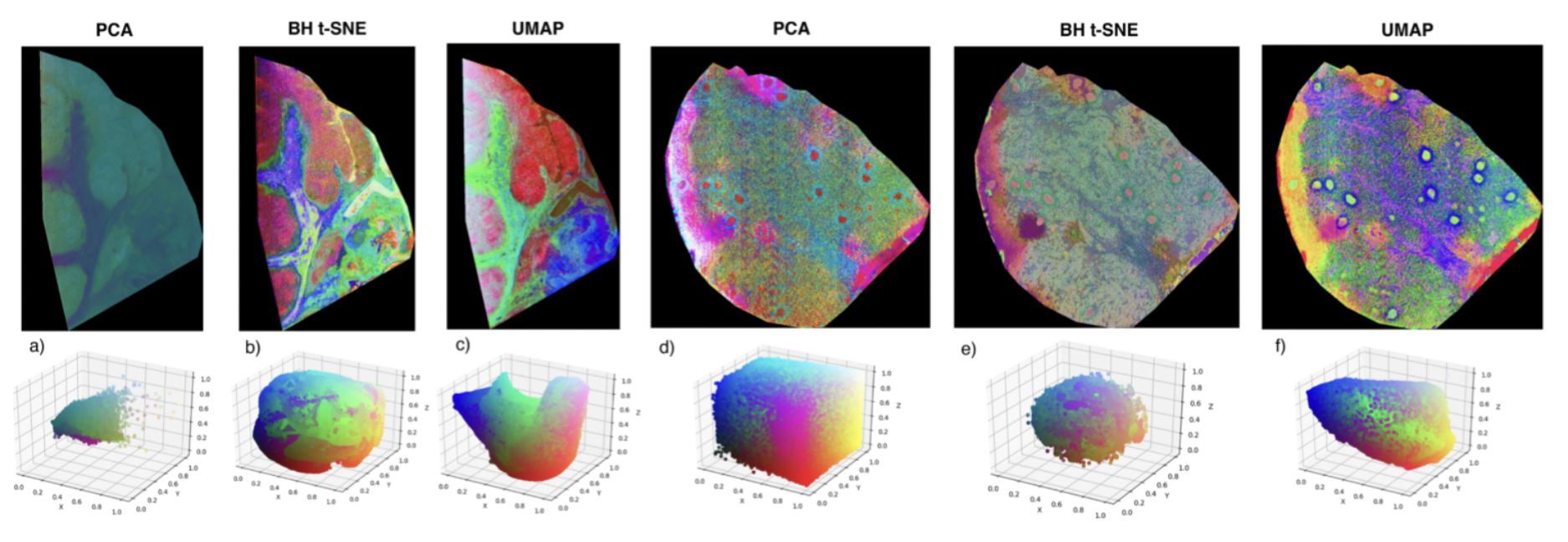
t-SNE和UMAP的比较
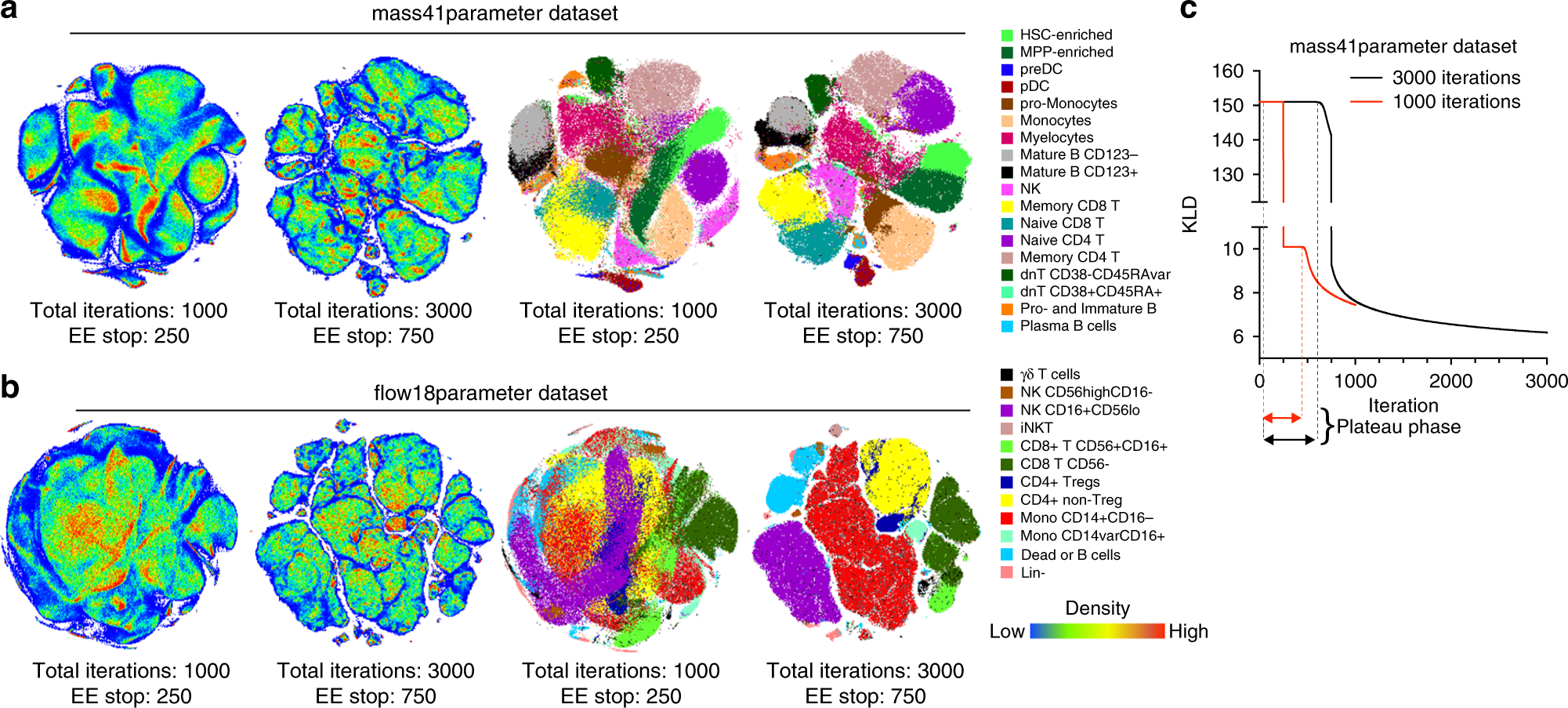
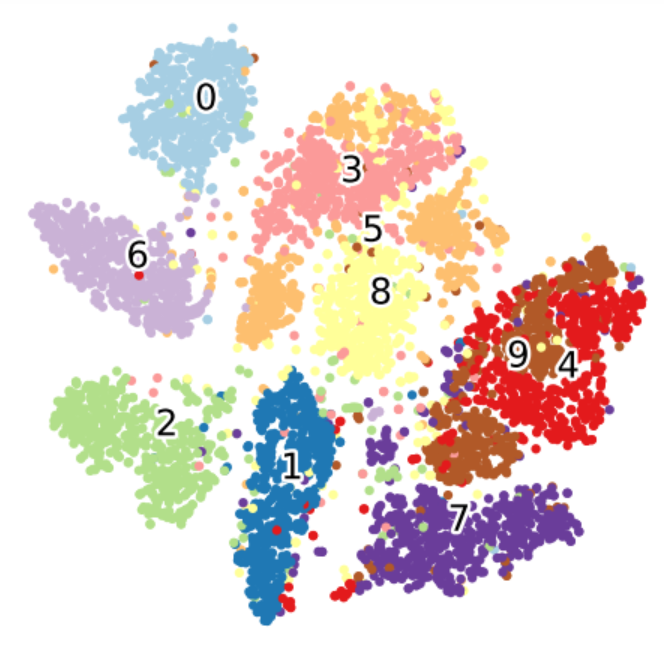
当我们用t-SNE和UMAP对同样的人脸数据进行可视化时,会发现有趣的差异。t-SNE倾向于形成紧密的聚类,同一人的不同照片会聚集在一起,但不同人之间的相对位置可能不具有全局意义。
UMAP的可视化结果则更加平衡,既保持了局部的聚类结构,又保留了一定的全局组织。这使得我们能够观察到人脸数据的层次结构,比如相似外貌的人可能会分布在相邻的区域。
降维技术的选择指南
.jpg)
选择合适的降维技术就像选择合适的工具一样,需要根据具体的任务需求来决定。
对于数据探索和可视化,如果数据规模较小(少于10,000个样本),t-SNE是很好的选择,它能够提供美观且富含信息的可视化结果。对于大规模数据,UMAP是更好的选择,它速度快且能处理数百万个数据点。
对于特征提取和数据压缩,PCA通常是首选,它简单、快速且效果稳定。如果数据中存在显著的非线性结构,可以考虑核PCA或自编码器等非线性方法。
对于有监督学习的预处理,LDA是理想选择,特别是当特征数量远大于样本数量时。LDA能够找到最有利于分类的低维表示。
技术前沿与发展趋势
降维技术仍在不断发展。最近的研究集中在几个方向:
深度学习的降维方法正在兴起,如变分自编码器(VAE)和生成对抗网络(GAN)。这些方法能够学习数据的非线性表示,且能够生成新的数据样本。
可解释性降维成为热点,研究者们开发了能够提供更好解释性的降维方法,帮助我们理解降维后的维度代表什么意义。
动态和时序数据的降维也受到关注,传统的降维方法主要针对静态数据,而现实中很多数据是随时间变化的。
超大规模数据的降维仍是挑战,虽然UMAP已经能处理数百万数据点,但对于十亿级别的数据,仍需要更高效的算法。
降维技术就像是数据科学家手中的魔法工具,它们帮助我们从高维数据的迷雾中找到清晰的洞察。无论是PCA的数学优雅、t-SNE的可视化魅力,还是UMAP的速度与效果平衡,每种技术都有其独特的价值。掌握这些技术,就像获得了从不同角度观察数据世界的能力,让我们能够发现隐藏在复杂数据背后的美丽模式和深刻规律。
在这个数据驱动的时代,降维技术不仅仅是技术工具,更是我们理解复杂世界的重要桥梁。通过合理运用这些技术,我们能够从海量数据中提取有价值的信息,为决策提供支持,为创新提供灵感。