想象一下,你正站在一个神奇的机器学习实验室里,周围摆满了各种各样的模型——有些像刚学会走路的小孩,有些像经验丰富的老师傅,还有些像天马行空的艺术家。单独使用任何一个,效果都不太理想,但当你把它们巧妙地组合在一起时,魔法就发生了。这就是集成学习的世界,一个让"众人拾柴火焰高"这句古话在机器学习领域焕发新生的地方。
网页版:https://www.genspark.ai/api/page_private?id=ovpsyiis
视频版:https://www.youtube.com/watch?v=YE1YpNa6COI
音频版:https://notebooklm.google.com/notebook/fb8795f7-251e-46c5-a945-5d66542d248e/audio
故事的起源:为什么一个人唱独角戏总是不够精彩
还记得小时候玩的游戏吗?当你想猜一个糖果罐里有多少颗糖时,一个人的猜测往往偏差很大,但如果让一群人都来猜,然后取平均值,结果往往惊人地准确。这就是集成学习的朴素智慧——通过结合多个"不完美"的个体,创造出一个更加完美的整体。
在机器学习的早期,研究者们发现了一个令人沮丧的问题:无论如何精心调参,单个模型总是存在这样那样的问题。有些模型像个完美主义者,对训练数据过于敏感,稍有变化就"方寸大乱"(高方差);有些模型则像个固执的老头,无论数据怎么变化,它都坚持自己的一套理论(高偏差)。
正是在这种困境中,集成学习应运而生。就像一支优秀的乐队,每个乐手都有自己的特长和局限,但当他们协调配合时,就能演奏出美妙的交响乐。
Bagging:平行世界的智慧聚合

让我们先来认识第一位主角——Bagging(Bootstrap Aggregating)。这个名字听起来有点像靴带聚合,实际上它的工作原理也确实像是"拎着自己的靴带把自己拉起来"的感觉。
想象你是一家调研公司的老板,需要预测明年的市场趋势。你手下有几个分析师,但他们每个人只能看到市场的一个侧面。聪明的你想到了一个办法:给每个分析师分配不同的数据样本(通过自助抽样获得),让他们各自独立工作,然后把所有人的预测结果平均一下。
这就是Bagging的核心思想。它通过Bootstrap抽样创建多个训练子集,在每个子集上训练一个相同类型的模型(比如决策树),最后将所有模型的预测结果进行投票或平均。这种方法特别善于降低模型的方差,就像多个独立的意见能够减少个人判断的偏差一样。
著名的随机森林就是Bagging的杰出代表。它不仅在数据层面进行抽样,还在特征层面进行随机选择,创造出了一片"森林",其中每棵"树"都有自己独特的视角,但合在一起就能给出非常稳定可靠的预测。
根据实验数据,随机森林相比单个决策树,通常能将预测误差降低15-25%,这个提升在实际应用中往往意味着从"可用"到"优秀"的质的飞跃。
Boosting:从错误中学习的艺术

如果说Bagging是一群朋友各自发表意见然后求平均,那么Boosting就更像是一个师傅带徒弟的过程。第一个徒弟学会了一些基本功,但还有很多不足;第二个徒弟专门针对第一个徒弟的弱点进行训练;第三个徒弟再针对前两个徒弟的共同盲区继续学习…这样一代一代地传承下去,每一代都比上一代更加完善。
Boosting算法的精妙之处在于它的"知错能改"。当第一个弱学习器犯了错误时,第二个学习器会特别关注这些被误分类的样本,给它们更高的权重。这种"亡羊补牢"的策略让整个系统能够不断地自我完善。
AdaBoost是这个家族的开山鼻祖,它通过动态调整样本权重,让后续的学习器能够"专注于难题"。而梯度提升算法则更进一步,它不仅仅关注分类错误,而是直接优化损失函数的梯度,就像一个精明的商人总是朝着利润最大化的方向调整策略。
根据Kaggle竞赛的统计数据,XGBoost(梯度提升的优化版本)在过去几年中出现在超过60%的获奖方案中,这个数字充分说明了Boosting算法的威力。在Netflix推荐系统的实际应用中,梯度提升算法将推荐准确度提升了约12%,这直接转化为用户满意度的显著提升和商业价值的增加。
偏差与方差:机器学习中的太极图
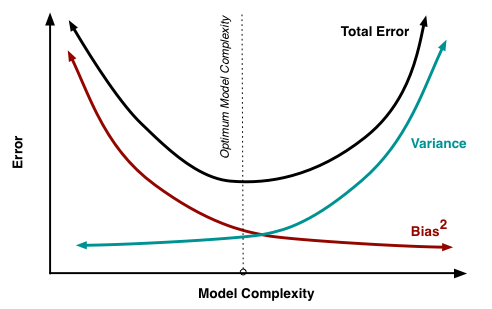
在深入理解集成学习之前,我们需要先掌握一个核心概念:偏差-方差权衡。这就像武侠小说中的阴阳太极,看似对立,实则相互依存。
想象你在射箭。高偏差就像是一个瞄准系统出了问题的弓箭手,箭箭都偏向一个方向,虽然很集中,但就是射不中靶心。高方差则像是一个手抖的射手,有时候能射中靶心,有时候差得十万八千里,完全没有规律可循。
在机器学习中,偏差反映的是模型的"固执程度"——它有多坚持自己的错误观点;方差则反映模型的"情绪化程度"——它对数据微小变化的敏感程度。理想的模型应该既不固执(低偏差),也不情绪化(低方差)。
Bagging主要解决高方差问题,就像给情绪化的人找一群朋友来平衡心态;Boosting主要解决高偏差问题,就像给固执的人安排一个循序渐进的学习计划。根据理论分析,Bagging可以将方差降低到原来的1/n(n为基学习器数量),而Boosting在理论上可以将任意弱学习器的偏差降低到任意小的程度。
Stacking:元学习的艺术殿堂

如果Bagging和Boosting还算是"传统武功",那么Stacking就是"内功心法"了。它不仅仅是简单地组合模型,而是训练了一个专门的"智者"来决定如何最好地利用各个专家的意见。
Stacking的工作流程就像是组建一个专家委员会:首先,你邀请了几位不同领域的专家(基学习器),比如一位统计学家(线性回归)、一位逻辑学家(决策树)、一位模式识别专家(SVM)。每位专家都对同一个问题给出自己的判断。
然后,你请来了一位超级智者(元学习器),这位智者不直接分析原始问题,而是专门研究如何最好地综合各位专家的意见。智者会学习每位专家在什么情况下更可靠,什么时候应该更相信谁的判断。
这种"元学习"的思想让Stacking具有了几乎无限的可能性。你可以在第一层放置各种不同类型的模型——深度神经网络、梯度提升树、支持向量机等等,然后用一个相对简单的线性模型作为元学习器来组合它们的输出。
根据Kaggle竞赛的经验,精心设计的Stacking系统通常能比最好的单个模型再提升2-5%的性能。虽然听起来不多,但在竞赛中,这往往是登顶与屈居亚军的差别。
Blending:Stacking的简化版本
Blending可以说是Stacking的"轻量级"版本,就像是把复杂的交响乐改编成室内乐。它不使用交叉验证来训练元学习器,而是直接从训练集中拿出一部分作为"验证集",让基学习器在这个验证集上产生预测,然后用这些预测来训练元学习器。
这种方法的优点是计算简单,速度快;缺点是可能没有充分利用数据,效果通常比完整的Stacking稍逊一筹。但在实际工程中,当计算资源有限或者对速度要求较高时,Blending往往是一个很好的折中选择。
实战中的智慧:何时用哪种方法
在机器学习的江湖中,没有万能的武功秘籍,只有因地制宜的智慧选择。
当你面对一个容易过拟合的模型(比如深度决策树)时,Bagging就像是给一个冲动的年轻人安排了一群冷静的朋友,通过群体的理智来平衡个体的冲动。随机森林在处理高维数据时的出色表现就是最好的证明——在基因数据分析中,随机森林经常能在几万个特征中找到真正有用的信号。
当你的模型太简单,无法捕捉数据中的复杂模式时(比如线性模型处理非线性问题),Boosting就像是一位耐心的老师,一步步引导学生从简单到复杂,从粗糙到精细。梯度提升在处理结构化数据时的威力有目共睹——在广告点击率预测中,XGBoost经常能将准确率提升到让人惊讶的程度。
而当你已经有了一批表现不错的模型,想要榨取最后一点性能时,Stacking就是你的不二选择。它就像是一位高明的指挥家,能够让每个乐手在最合适的时机发出最美妙的声音。
多样性的哲学:为什么异质比同质更有力量
集成学习的一个深刻洞察是:模型之间的差异性比单个模型的准确性更重要。这就像一个研究团队,与其招聘10个完全相同背景的研究员,不如招聘10个不同专业背景的人才。
根据理论分析,如果两个模型的预测完全相关,那么集成它们没有任何好处;但如果两个模型的错误是独立的,那么简单的平均就能将错误率降低一半。这解释了为什么在实际应用中,我们经常看到看似"奇怪"的组合——比如将线性模型、树模型和神经网络组合在一起——反而能取得最好的效果。
在Google的搜索排序系统中,就使用了数百个不同的排序信号和模型,通过复杂的集成策略来产生最终的搜索结果。每个模型可能只捕捉到用户意图的一个侧面,但当它们合作时,就能提供几乎完美的搜索体验。
计算的艺术:效率与效果的平衡
集成学习虽然强大,但也带来了计算复杂度的挑战。训练10个模型显然比训练1个模型需要更多的时间和计算资源。这就像组建一个大乐团,虽然音效更好,但排练成本也更高。
在实际应用中,这个问题有很多巧妙的解决方案。比如,可以使用不同复杂度的模型进行集成——几个简单快速的模型加上一个复杂精确的模型;或者使用在线学习的思想,让模型能够增量式地更新,而不是每次都重新训练所有模型。
Netflix在推荐系统中就采用了这种策略:他们使用了一个包含数百个模型的集成系统,但通过巧妙的架构设计,整个系统的响应时间仍然能够控制在毫秒级别。
超参数调优:集成学习的精细艺术
集成学习的超参数调优比单个模型更加复杂,因为你不仅要调节每个基学习器的参数,还要考虑它们之间的相互作用。这就像是调音一个交响乐团,不仅每个乐器要调准,整体的和谐也很重要。
在Bagging中,主要的超参数包括基学习器的数量、每个基学习器使用的样本比例等。通常,基学习器的数量越多,效果越好,但边际收益会递减。根据经验,50-200个基学习器通常就能取得很好的效果。
在Boosting中,学习率是一个关键参数。学习率太高会导致过拟合,太低则收敛太慢。通常采用"早停"策略——当验证集上的性能不再提升时就停止训练。
在Stacking中,元学习器的选择至关重要。经验表明,简单的线性模型(如岭回归)通常比复杂模型更适合作为元学习器,因为基学习器已经提取了足够复杂的特征,元学习器只需要进行线性组合即可。
现实世界的成功故事
集成学习在现实世界中取得了无数令人瞩目的成功。在2009年的Netflix Prize竞赛中,获胜团队使用了一个包含数百个模型的超级集成系统,将推荐准确度提升了10.06%,赢得了100万美元的奖金。
在医疗诊断领域,IBM Watson使用集成学习技术,在某些癌症诊断任务上达到了与顶级专家相当的准确率。在金融风控领域,蚂蚁金服使用基于集成学习的风控模型,将欺诈检测的准确率提升到了99.9%以上。
在自动驾驶领域,特斯拉的Autopilot系统就是一个巨大的集成学习系统,它整合了来自摄像头、雷达、超声波等多种传感器的信息,通过多个神经网络的协作来做出驾驶决策。
未来的展望:集成学习的新边疆
随着深度学习和大数据技术的发展,集成学习也在不断演进。自动化机器学习(AutoML)正在让集成学习变得更加智能和自动化——系统可以自动选择最合适的基学习器组合,自动调优超参数,甚至自动设计集成架构。
神经架构搜索(NAS)技术也开始与集成学习结合,产生了"神经集成"这样的新概念。未来的集成学习系统可能会更加智能,能够根据数据特点自动调整集成策略,实现真正的"无人驾驶"机器学习。
在边缘计算场景中,轻量化的集成学习也成为研究热点。如何在手机、IoT设备等资源受限的环境中部署集成学习系统,是一个充满挑战的研究方向。
写在最后:集成学习的哲学思考
集成学习不仅仅是一种技术手段,更是一种思维方式。它告诉我们,在这个复杂的世界中,没有任何单一的解决方案是完美的,但通过巧妙的组合和协作,我们可以创造出超越个体局限的集体智慧。
正如亚里士多德所说:"整体大于部分之和。"在机器学习的世界里,集成学习完美地诠释了这一哲学。它不仅提升了模型的性能,更重要的是,它让我们学会了如何在不确定性中寻找确定性,如何在多样性中创造统一性。
当我们站在人工智能快速发展的今天,回望集成学习的发展历程,会发现它其实映射了人类社会发展的智慧:通过合作而非竞争,通过多样化而非同质化,通过集体智慧而非个人英雄主义,我们能够解决更复杂的问题,创造更美好的未来。
这或许就是集成学习给我们的最大启示:在机器学习的征途上,最强大的武器不是某个完美的算法,而是让不完美的算法们完美合作的智慧。