在人工智能飞速发展的今天,我们面临着一个有趣的悖论:机器学习模型变得越来越强大,但同时也变得越来越神秘。就像那些深藏在云端的算法巨兽,它们能准确预测你的喜好,却无法告诉你为什么。这种"黑盒"现象让人既惊叹又不安——我们能相信一个连自己都解释不清楚的系统吗?
网页版:https://gvnsrpsh.gensparkspace.com/
视频版:https://www.youtube.com/watch?v=IHnmdxOqREY
音频版:https://notebooklm.google.com/notebook/0e837da5-919b-43f2-8827-16288722c49b/audio
透明度:AI时代的新货币
想象一下,你正在申请一笔重要的贷款,银行的AI系统拒绝了你的申请,但没有给出任何解释。或者,医院的智能诊断系统建议你进行某项治疗,但医生也不知道系统为什么会这样建议。这种情况下,你会怎么想?
可解释AI(XAI)的出现,正是为了解决这个问题。它不仅仅是一个技术概念,更是一种哲学思考:我们如何让人工智能既聪明又透明?
在金融、医疗、司法等高风险领域,模型的可解释性已经成为法律要求。欧盟的GDPR法规明确规定,个人有权了解自动化决策的逻辑。这意味着,一个无法解释的AI系统,可能根本无法在这些领域使用。
LIME:局部解释的魔法师
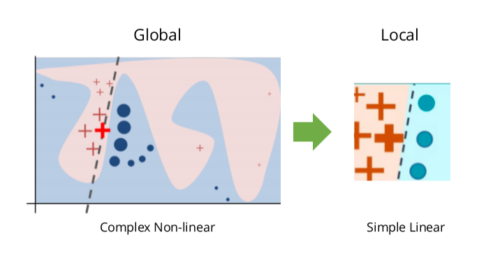
LIME(Local Interpretable Model-agnostic Explanations)就像是一位善于察言观色的侦探。它不试图理解整个模型的工作原理,而是专注于解释单个预测结果。这种方法的巧妙之处在于,它可以应用于任何类型的机器学习模型,无论是随机森林、神经网络还是支持向量机。
LIME的工作原理相当有趣:它首先围绕要解释的样本生成一些"邻居"数据点,然后在这个局部区域内训练一个简单的线性模型。这个线性模型就像是原始复杂模型的"局部替身",通过它我们可以理解原模型在特定区域的行为。
比如,当LIME解释一个图像分类结果时,它会高亮显示对预测结果最重要的像素区域。当解释文本分类时,它会标出关键词汇的重要性。这种直观的解释方式,让普通用户也能理解AI的决策过程。
SHAP:博弈论的智慧结晶
如果说LIME是局部解释的专家,那么SHAP(SHapley Additive exPlanations)就是一位拥有深厚数学功底的全能型选手。SHAP基于博弈论中的Shapley值,这个概念最初用于公平分配合作游戏中的收益。
在机器学习的语境下,SHAP将每个特征视为一个"玩家",将预测结果视为"收益"。它试图回答一个根本问题:每个特征对最终预测贡献了多少?这种方法不仅提供了局部解释,还能给出全局的特征重要性排名。
SHAP的数学基础保证了解释的一致性和公平性。无论你如何组合特征,每个特征获得的贡献值都是公平的。这种理论保证让SHAP在学术界和工业界都获得了广泛认可。
实战案例:从波士顿房价到金融风控
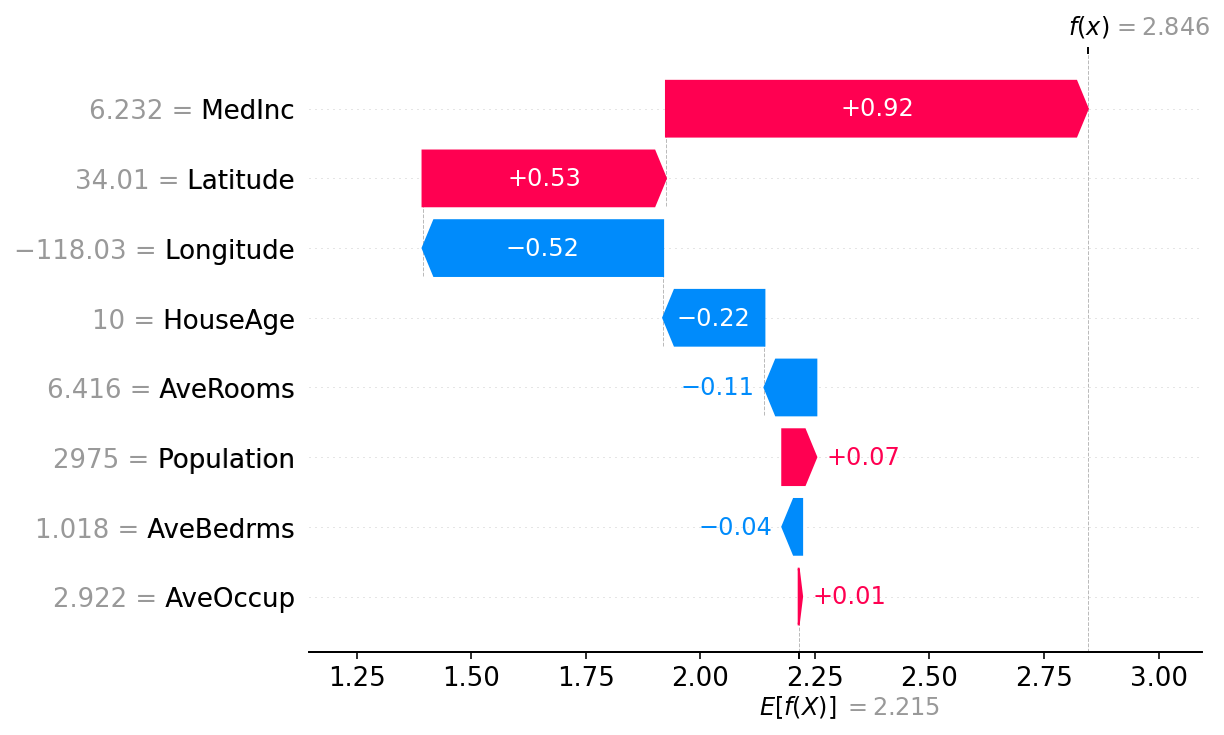
让我们看一个具体的例子。假设我们有一个用于预测房价的XGBoost模型。传统的方法可能只会告诉我们"这套房子预计售价50万美元",但通过SHAP,我们可以看到:
- 地理位置贡献了+15万美元
- 房屋面积贡献了+8万美元
- 建筑年代贡献了-3万美元
- 周边环境贡献了+5万美元
这种分解让我们不仅知道结果,还知道每个因素的具体影响。
在金融风控领域,SHAP和LIME的应用更是具有革命性意义。银行可以向客户解释为什么贷款申请被拒绝,监管机构可以审查模型是否存在歧视性偏见,风险管理人员可以理解模型的决策逻辑。
可视化:让数据说话的艺术
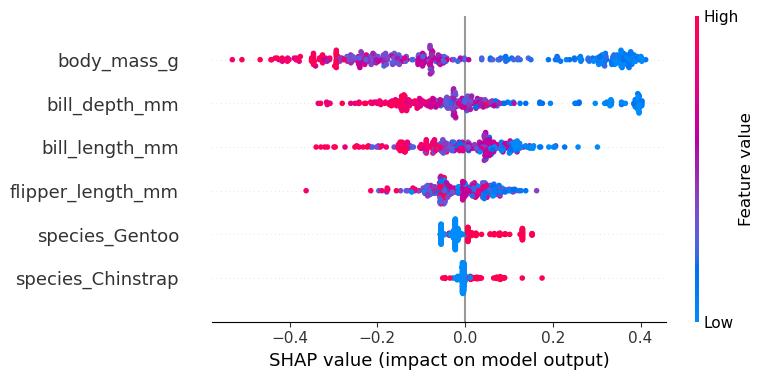
现代可解释AI的一个重要特点是丰富的可视化工具。SHAP提供了多种图表类型:
特征重要性图展示了全局范围内各个特征的重要性排名。这就像是一个"影响力排行榜",告诉我们哪些因素最重要。
依赖图则显示了特征值与其对预测的影响之间的关系。比如,我们可能发现房屋面积和房价呈正相关,但当面积超过某个阈值时,影响开始减弱。
力图(Force Plot)是最直观的可视化方式之一。它将预测过程可视化为一场"推拉"游戏:某些特征将预测结果推向一个方向,而其他特征则推向相反方向。最终的预测结果就是这些力量的平衡点。
技术挑战:完美解释的代价
尽管LIME和SHAP都很强大,但它们也面临一些挑战。LIME的局部解释可能不够稳定,同一个样本在不同时间的解释可能会有所不同。而SHAP虽然理论基础扎实,但计算成本较高,特别是对于大型数据集。
另一个有趣的发现是,LIME和SHAP有时会给出不同的解释。这并不意味着其中一个是错误的,而是反映了它们不同的设计理念和适用场景。就像两个医生可能对同一个病例给出不同但都合理的诊断。
未来展望:智能与透明的平衡
随着AI技术的不断发展,可解释性的重要性只会越来越高。我们正在见证一个有趣的趋势:企业开始将模型的可解释性作为一个重要的竞争优势。
监管机构也在加强对AI可解释性的要求。未来,一个无法解释的AI系统可能无法通过监管审查,更不用说获得用户的信任。
同时,我们也看到了新的解释方法的出现。反事实解释(Counterfactual Explanations)告诉我们"如果改变某个特征,结果会如何变化"。注意力机制(Attention Mechanisms)让我们看到深度学习模型"关注"的重点。这些方法正在丰富我们理解AI的工具箱。
实用建议:选择合适的解释工具
对于实际应用,选择合适的解释方法至关重要:
如果你需要解释个别预测结果,LIME是个不错的选择。它速度快,易于理解,特别适合需要向非技术用户解释的场景。
如果你需要深入分析模型的全局行为,或者在严格的监管环境中工作,SHAP可能更合适。它的理论基础更加坚实,提供的解释也更加全面。
对于基于树的模型(如随机森林、XGBoost),SHAP的TreeExplainer提供了快速准确的解释。而对于深度学习模型,DeepExplainer或GradientExplainer可能更适合。
结语:信任的桥梁
可解释AI不仅仅是一个技术问题,更是一个关于信任的社会问题。在一个算法影响着我们生活方方面面的时代,我们有权知道这些算法是如何工作的。
LIME和SHAP为我们提供了打开黑盒的钥匙,让我们能够审视、理解和改进AI系统。它们不是万能的,也不是完美的,但它们代表了我们在追求智能与透明平衡道路上的重要一步。
正如一位数据科学家所说:"最好的模型不是最准确的模型,而是最值得信赖的模型。"在这个AI无处不在的时代,可解释性正成为这种信任的基石。