那是2017年的一个平常的夏日,Google的研究团队在论文中写下了六个改变AI世界的单词:"Attention Is All You Need"。当时的研究者们可能没有想到,这篇论文会成为现代人工智能的基石,就像是为机器装上了一颗会思考的大脑。
网页版:https://www.genspark.ai/api/page_private?id=borvzdfl
视频版:https://www.youtube.com/watch?v=A7Hw6e4rHOk
一个革命性的开始
想象一下,你正在翻译一本厚厚的书。传统的方法是逐字逐句地翻译,就像早期的RNN和LSTM模型一样,需要按顺序处理每个单词。但Transformer就像是拥有了透视眼的翻译专家,能够同时看到整篇文章的所有内容,理解每个词汇之间的复杂关系。
这种"透视能力"来自于一个叫做"注意力机制"的创新技术。Jay Alammar在他的经典教程中用生动的可视化展示了这个过程:当模型处理句子"The animal didn’t cross the street because it was too tired"中的"it"时,注意力机制能够聪明地将"it"与"animal"建立联系,而不是与"street"混淆。
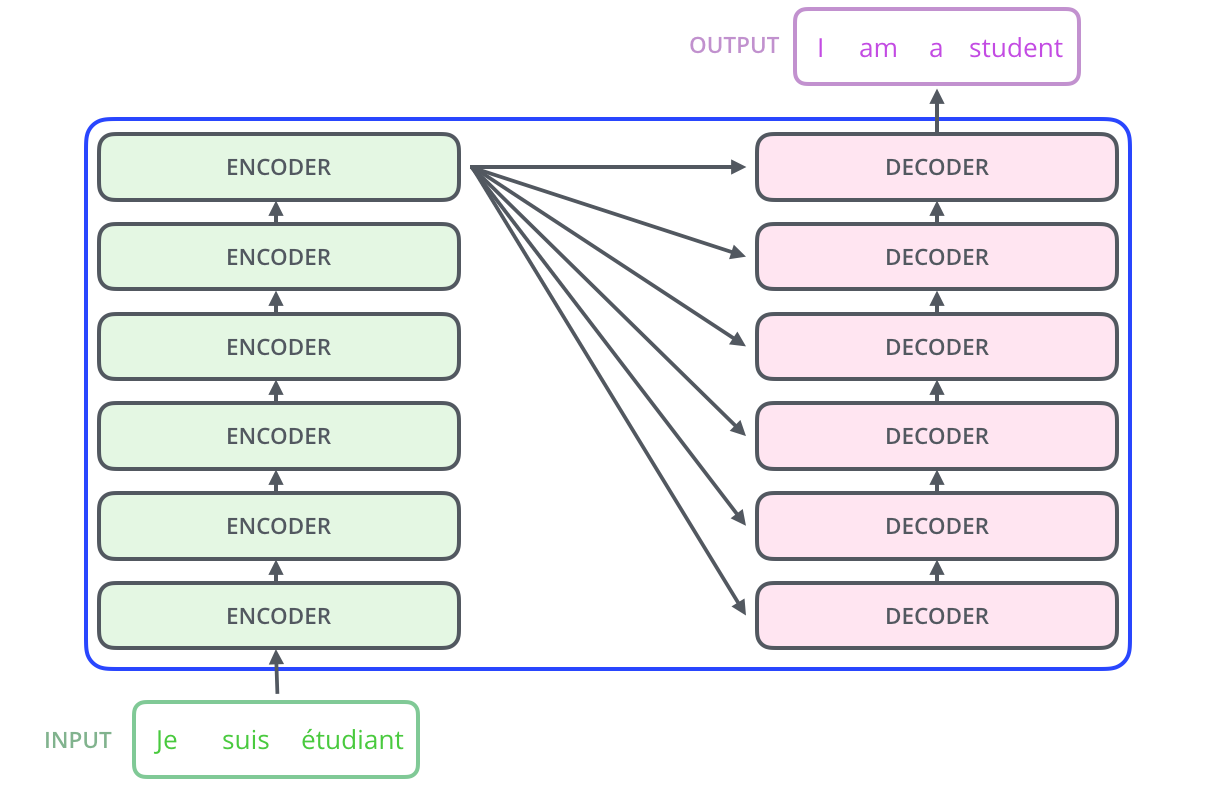
编码器:理解世界的眼睛
Transformer的编码器就像是一个细致入微的观察者。它由6个相同的层堆叠而成,每一层都在做着两件重要的事情:通过多头自注意力机制观察,通过前馈神经网络思考。
多头自注意力:八面玲珑的观察家
多头注意力机制可能是Transformer最精妙的设计。想象你正在参加一个鸡尾酒会,周围有很多人在同时说话。人类大脑有一种神奇的能力,叫做"鸡尾酒会效应",能够从嘈杂的环境中专注于特定的声音。多头注意力机制就是这种能力的数字化版本。
根据Towards Data Science的详细分析,GPT-2模型使用了12个注意力头,每个头都关注不同的语言特征。一个头可能专门识别主谓关系,另一个头可能擅长捕捉形容词和名词的搭配,第三个头则可能专注于时态的一致性。
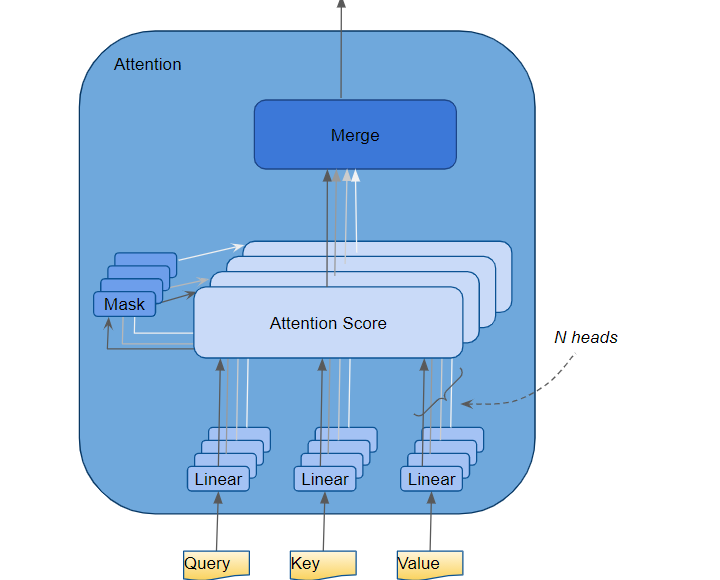
数学上,注意力机制的计算公式看起来很简洁:
Attention(Q,K,V) = softmax(QK^T/√d_k)V
但这个简单公式背后蕴含着深刻的智慧。Query(查询)矩阵就像是搜索引擎中输入的关键词,Key(键)矩阵像是所有可能的搜索结果标题,而Value(值)矩阵则是实际的内容。通过计算Query和Key的相似度,模型能够决定应该从哪些Value中提取信息。
前馈网络:深度思考的大脑
每个编码器层的第二个组件是前馈神经网络。如果说注意力机制是在收集信息,那么前馈网络就是在加工这些信息。它将输入的维度从512扩展到2048,然后再压缩回512维,就像是一个思考的过程:展开思维,深入分析,然后得出结论。
解码器:创造语言的艺术家
解码器的设计更加巧妙,它不仅要理解已经生成的文本,还要与编码器的输出进行交互,创造出新的语言。
掩码注意力:防止"剧透"的智慧
解码器中最关键的创新是掩码自注意力机制。想象你正在写一部悬疑小说,你不能让读者提前知道结局,否则就失去了悬念。掩码注意力机制就是这样一个"防剧透"装置,它确保模型在生成第i个词时,只能看到前面的i-1个词,而不能偷看后面的内容。
哈佛大学的注释版Transformer实现详细解释了这个过程:掩码通过将未来位置的注意力分数设置为负无穷大,然后通过softmax函数将其转换为接近零的概率,从而实现了信息的屏蔽。
层归一化和残差连接:稳定训练的秘密武器
层归一化:保持内心平衡的修炼
层归一化就像是给神经网络做心理辅导。在深度学习中,内部协变量偏移是一个常见问题,就像一个人情绪不稳定一样,会影响整个系统的表现。层归一化通过标准化每一层的输入,确保网络在训练过程中保持稳定的状态。
残差连接:记忆的桥梁
残差连接的灵感来自于人类的记忆机制。我们在学习新知识时,不会丢弃已有的知识,而是在原有基础上进行累积。ResNet论文首次提出了这个概念,Transformer巧妙地将其融入到每个子层中,使得信息能够更好地在深层网络中流动。
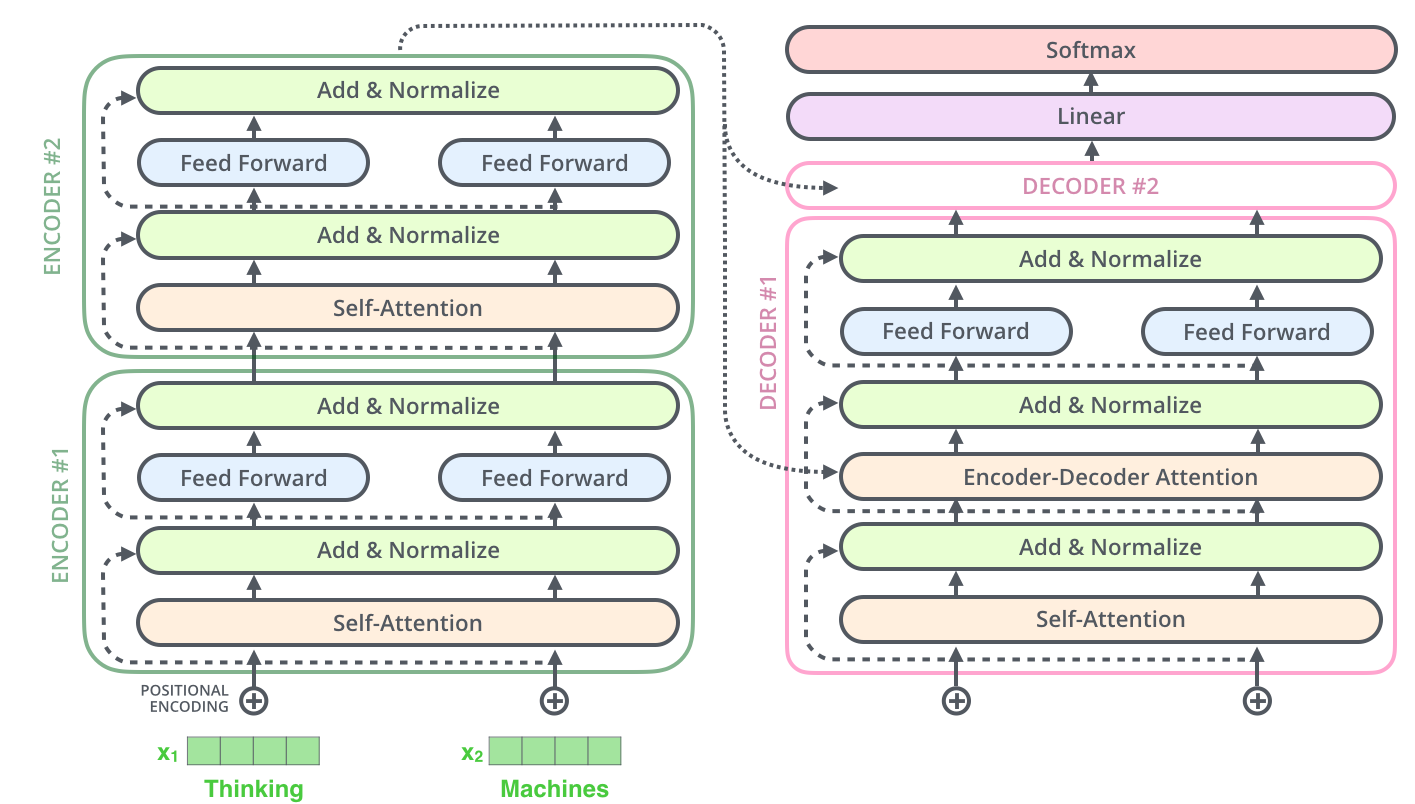
位置编码:给词汇安排座位号
Transformer面临一个独特的挑战:由于注意力机制天生没有顺序概念,模型需要额外的方式来理解词汇的位置关系。位置编码就像是给每个词汇分配一个独特的"座位号",使用正弦和余弦函数生成的编码既能表示绝对位置,又能捕捉相对位置关系。
数学表达式为:
- PE(pos,2i) = sin(pos/10000^(2i/d_model))
- PE(pos,2i+1) = cos(pos/10000^(2i/d_model))
这种设计的巧妙之处在于,它能够处理训练时未见过的长度的句子,就像是一套可以无限扩展的座位编号系统。
从理论到实践:构建你自己的Transformer
理解了Transformer的原理后,用PyTorch实现一个简化版本的编码器块并不困难:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.w_o = nn.Linear(d_model, d_model)
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
# 计算Q, K, V
Q = self.w_q(query).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
K = self.w_k(key).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
V = self.w_v(value).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
# 计算注意力分数
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attention = F.softmax(scores, dim=-1)
context = torch.matmul(attention, V)
# 合并多头输出
context = context.transpose(1, 2).contiguous().view(
batch_size, -1, self.d_model
)
return self.w_o(context)
class TransformerEncoderBlock(nn.Module):
def __init__(self, d_model, n_heads, d_ff, dropout=0.1):
super().__init__()
self.attention = MultiHeadAttention(d_model, n_heads)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.feed_forward = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Linear(d_ff, d_model)
)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
# 多头自注意力 + 残差连接 + 层归一化
attn_output = self.attention(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
# 前馈网络 + 残差连接 + 层归一化
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return x
这个实现展示了Transformer编码器块的核心结构。Andrej Karpathy的nanoGPT项目提供了一个更完整的实现,是学习Transformer的绝佳资源。
性能的魔法:为什么Transformer如此强大
Transformer的成功不是偶然的。根据谷歌团队的分析,它在机器翻译任务上的BLEU分数达到了28.4,超过了当时最好的循环神经网络模型。
更重要的是并行化能力的提升。传统的RNN需要按顺序处理每个词,就像单线程程序一样慢。而Transformer可以同时处理整个序列,就像多线程程序一样高效。这使得训练时间从数周缩短到数天,为大规模语言模型的发展奠定了基础。
现实世界的影响:从GPT到ChatGPT的进化之路
Transformer架构催生了一系列革命性的模型。GPT系列模型仅使用解码器部分,专注于文本生成;BERT使用编码器部分,专精于理解任务。OpenAI的研究显示,通过增加模型规模和训练数据,这些模型展现出了惊人的能力。
从GPT-1的1.17亿参数到GPT-3的1750亿参数,再到ChatGPT的出现,我们见证了一个从学术研究到改变世界的完整历程。每一次参数规模的增长,都带来了质的飞跃,就像是给机器装上了更加聪明的大脑。
未来的无限可能
Transformer的故事还远未结束。研究者们正在探索更高效的注意力机制,如Linformer和Performer,试图解决注意力机制的二次复杂度问题。同时,Vision Transformer将这一架构成功应用到计算机视觉领域,Perceiver更是展示了处理多模态数据的可能性。
当你下次使用搜索引擎、翻译软件或者AI助手时,请记住这个奇妙的架构。它就像是一个数字化的大脑,正在默默地理解你的意图,处理你的请求,为你提供智能化的服务。Transformer不仅仅是一个技术创新,它是人类向通用人工智能迈出的重要一步,是连接现在与未来的桥梁。
在这个AI飞速发展的时代,理解Transformer的工作原理不仅仅是技术人员的需求,也是每个现代人理解这个数字世界的关键。正如Transformer论文的标题所言,"注意力就是一切",而我们对这项技术的理解和掌握,将决定我们如何更好地与AI共同创造更美好的未来。