想象一下,你正站在一个巨大的图书馆里,面前堆积着无数本书籍,每本书都用不同的语言、不同的字体、甚至不同的书写方向编写。作为一个想要理解这些书籍内容的人,你会从何下手呢?这正是现代自然语言处理系统面临的挑战。
网页版:https://jrjlckrd.gensparkspace.com/
视频版:https://www.youtube.com/watch?v=XAJk-JZo2yk
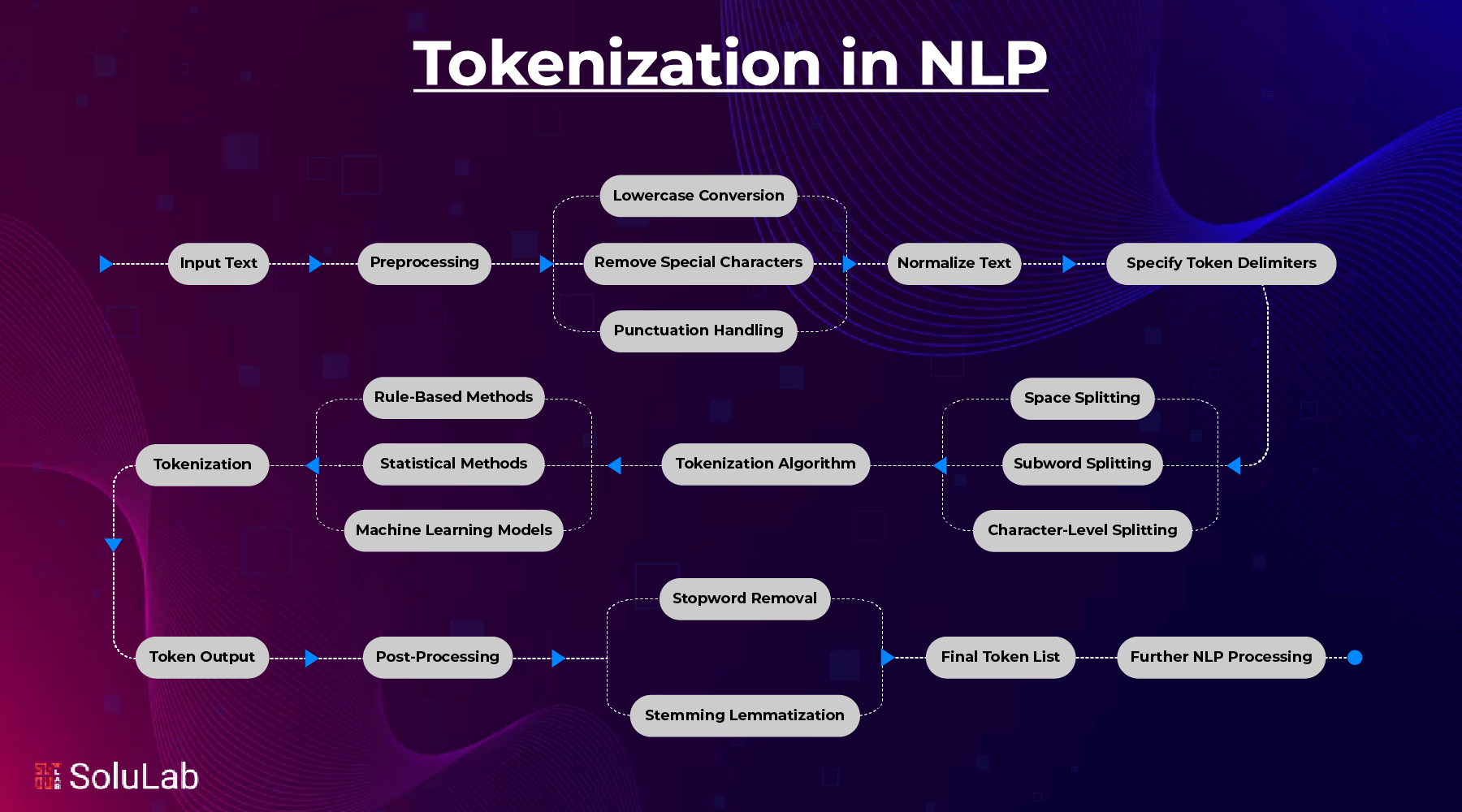
在数字世界中,机器需要一套精密的工具来理解人类的语言,而文本预处理技术就是这套工具的基石。从上图可以看出,文本预处理是一个多步骤的复杂过程,每个环节都至关重要。
分词:将语言的巨石劈成可见的砖块
当你看到"Hello world"这个简单的句子时,你的大脑几乎瞬间就能识别出这是两个单词。但对于计算机来说,这只是一串连续的字符。分词技术就像是一位经验丰富的雕刻师,需要将原始的语言材料精确地切分成一个个有意义的单元。
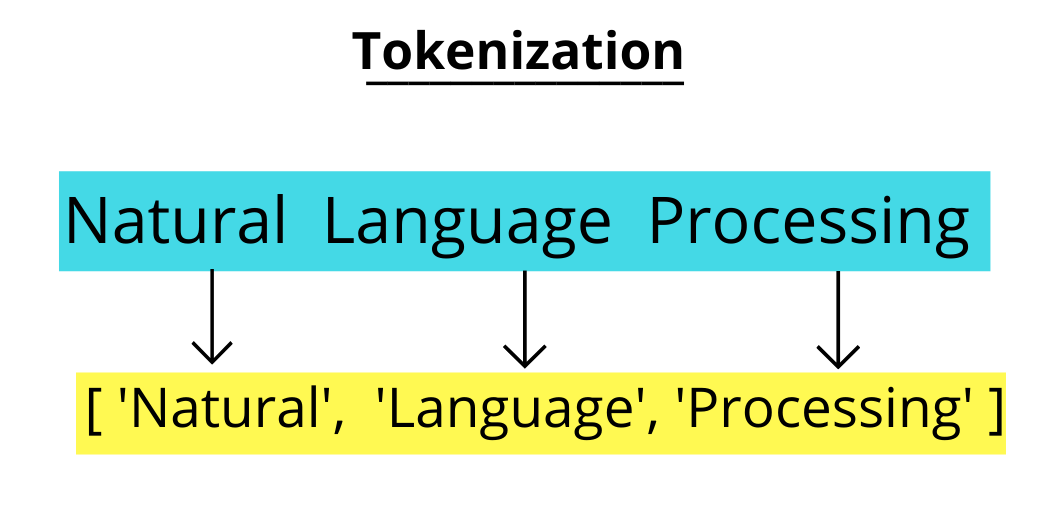
在传统的分词方法中,词袋模型(Bag of Words)是最直观的方式。就像将所有的单词扔进一个大袋子里,不考虑它们的顺序,只关心它们的存在与否。这种方法虽然简单,但在处理复杂语言现象时显得力不从心。
随着技术的进步,N-grams模型横空出世。它不再满足于单个词汇,而是考虑词汇之间的局部关系。比如当我们看到"neural network"时,bigram模型会将"neural"和"network"作为一个整体来理解,这样的组合往往比单独的词汇更有意义。
BPE:字节对编码的智慧之路
但真正的革命来自于子词切分技术。BPE(Byte Pair Encoding)的出现改变了游戏规则。

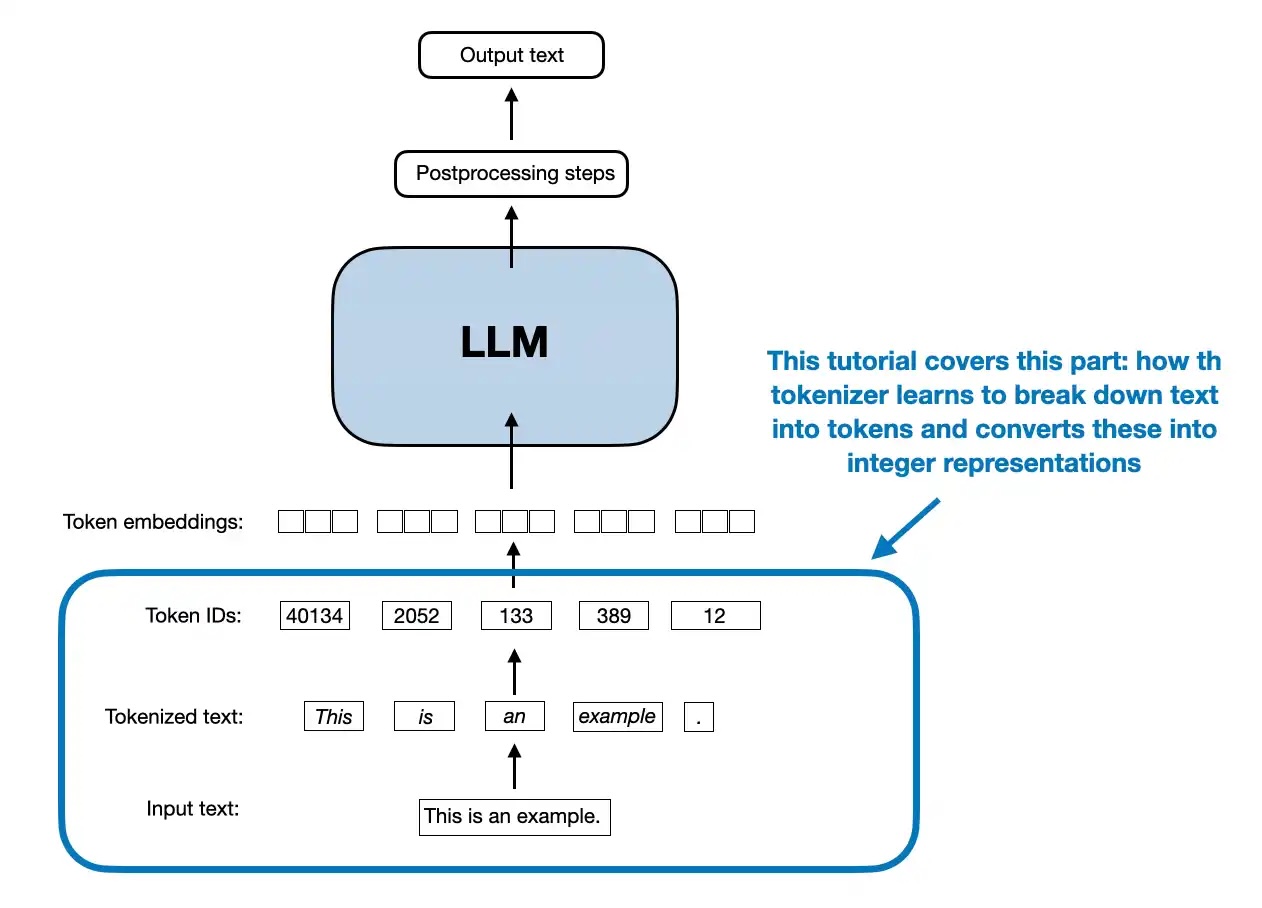
这种技术就像是一个智能的语言学家,它能够从大量文本中学习出最佳的切分策略。当遇到"unhappiness"这样的复杂词汇时,BPE可能会将其切分为"un-", "happi", "-ness",每个部分都携带着语义信息。从上图可以清楚地看到BPE算法如何通过迭代合并最频繁的字符对来构建词汇表。
更加精妙的是WordPiece算法。它不仅仅考虑频率,还会计算每个切分方案的概率。当WordPiece面对一个新词时,它会选择能够最大化训练数据似然度的切分方式,这种基于概率的方法让分词结果更加合理。
而SentencePiece则更进一步,它将空格也视为普通字符来处理,这样就能够处理中文、日文等没有明显词边界的语言。它使用特殊符号"_"来表示空格,使得整个过程可以完全可逆,这对于机器翻译等任务来说至关重要。
词性标注:为每个词汇贴上身份标签
如果说分词是将句子切分成词汇,那么词性标注(Part-of-Speech Tagging)就是为每个词汇贴上身份标签。这就像是在一场大型聚会上,每个人都佩戴着标明自己职业的名牌一样。

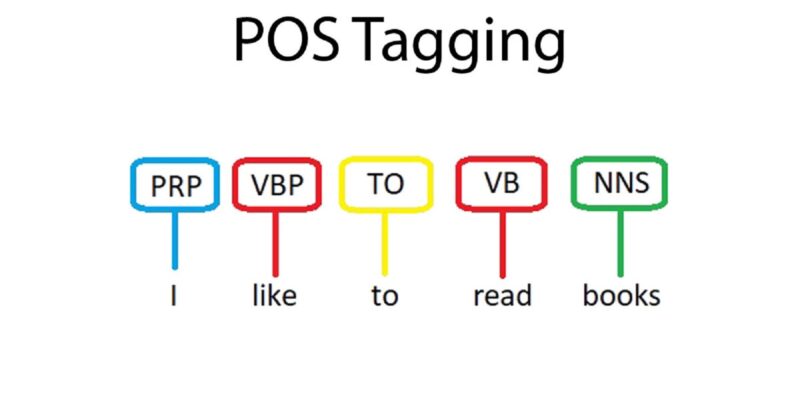
当我们看到句子"The quick brown fox jumps over the lazy dog"时,词性标注器会告诉我们:"The"是限定词(DT),"quick"是形容词(JJ),"brown"也是形容词(JJ),"fox"是名词(NN),"jumps"是动词(VBZ),以此类推。从上图可以看到,每个词都被准确地标注了其语法角色。
这些标签看似简单,但它们为后续的语言理解提供了至关重要的结构信息。现代的词性标注系统,特别是基于spaCy的实现,已经能够达到97%以上的准确率。这些系统不仅考虑词汇本身,还会考虑上下文信息。比如"book"这个词,在"I read a book"中是名词,而在"I book a flight"中则是动词。
命名实体识别:找出句子中的关键角色
在浩瀚的文本海洋中,某些词汇承载着特殊的意义。它们可能是人名、地名、组织名、时间表达式等。命名实体识别(Named Entity Recognition, NER)就像是一个敏锐的侦探,能够从文本中识别出这些关键信息。

当NER系统分析"Apple Inc. is headquartered in Cupertino, California"这句话时,它会识别出"Apple Inc."是一个组织(ORG),"Cupertino"和"California"是地点(LOC)。从上图可以看到,不同类型的实体被用不同颜色标注出来,这种可视化方式让复杂的识别结果变得一目了然。

这种识别能力对于信息抽取、知识图谱构建等任务来说是不可或缺的。现代的NER系统采用了深度学习技术,特别是基于Transformer的模型,能够处理更加复杂的实体类型和嵌套实体。比如在"Former Microsoft CEO Bill Gates"中,系统需要同时识别出"Microsoft"(组织)、"Bill Gates"(人名)以及"CEO"(职位)之间的复杂关系。
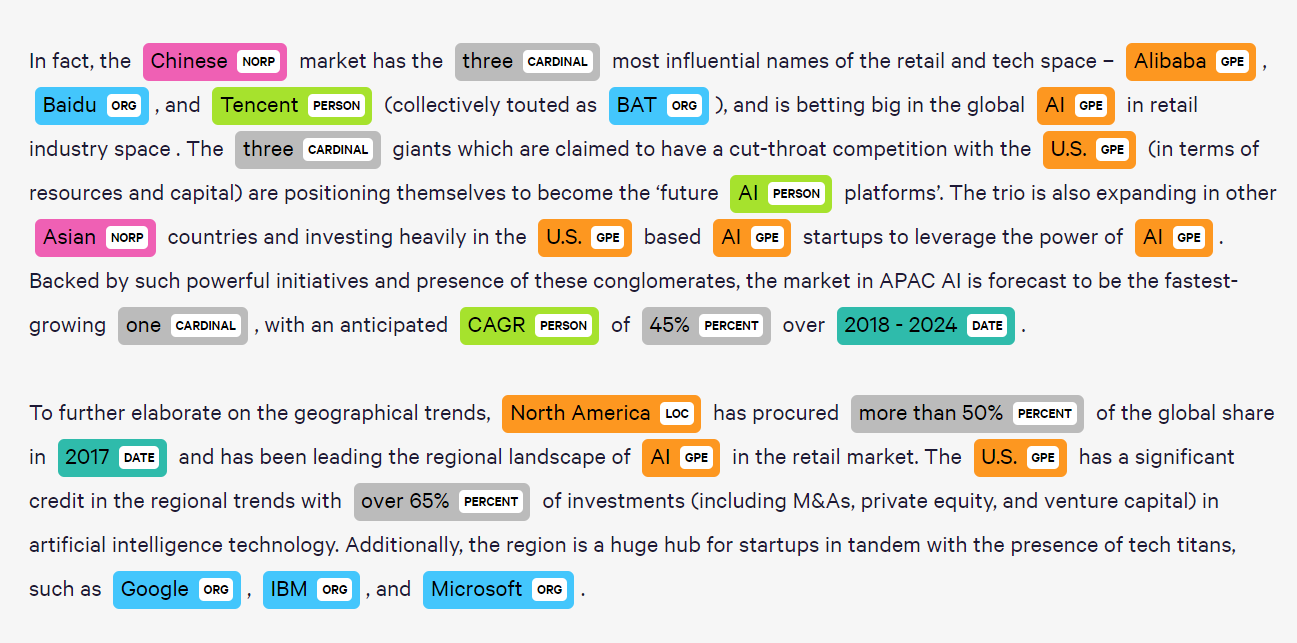
依存句法分析:解码语言的内在结构
如果把句子比作一棵树,那么依存句法分析(Dependency Parsing)就是描绘这棵树的精确蓝图。它不仅告诉我们每个词的位置,更重要的是揭示了词与词之间的依存关系。

在句子"The cat sat on the mat"中,依存句法分析会建立起这样的关系网络:"sat"是整个句子的根节点,"cat"是"sat"的主语(subject),"mat"是介词"on"的宾语(object),而"on the mat"整体作为"sat"的状语(adverbial modifier)。从上图的spaCy可视化结果可以看到,每条弧线都代表一种语法关系,这种树状结构让计算机能够理解句子的语法层次。
对于更复杂的句子,依存句法分析能够揭示出更加精细的语法结构。Stanford的依存句法分析器能够处理多种语言,并且提供了丰富的可视化功能。当你看到依存句法树的可视化结果时,句子的语法结构变得一目了然,就像看到了语言的X光片一样。

工具的选择:NLTK、spaCy还是Hugging Face?
在文本预处理的工具选择上,就像选择合适的画笔来创作艺术品一样重要。每种工具都有其独特的优势和适用场景。

NLTK就像是一个历史悠久的工匠铺,提供了丰富的传统NLP工具。它的教育价值很高,适合学习和研究,但在处理大规模数据时可能显得有些笨重。
spaCy则像是一个现代化的工厂,专注于工业级的性能和易用性。它的处理速度快,预训练模型质量高,特别适合生产环境中的应用。当你需要处理大量文本时,spaCy往往是更好的选择。
而Hugging Face Transformers则代表了最前沿的技术。它提供了各种预训练的Transformer模型,能够在各种NLP任务上达到最先进的性能。如果你追求最高的准确率,并且有足够的计算资源,Hugging Face的工具是不二之选。
实际应用中的挑战与机遇
在真实世界的应用中,文本预处理面临着各种挑战。社交媒体上的非正规文本、多语言混合的内容、含有表情符号和特殊字符的文本,都对传统的预处理方法提出了挑战。

比如当处理推特数据时,"I luv this movie 😍 #amazing"这样的文本包含了非标准拼写、表情符号和话题标签。现代的预处理系统需要能够理解这些元素的含义,而不是简单地将它们忽略或删除。
另一个挑战来自于领域特定的语言。医学文本、法律文档、科技论文都有其独特的词汇和表达方式。通用的预处理工具可能无法很好地处理这些专业领域的文本,需要进行特殊的调整和优化。
然而,这些挑战也带来了机遇。随着大规模预训练语言模型的兴起,我们看到了更加智能的文本预处理方法。这些模型能够从上下文中学习词汇的含义,即使面对从未见过的词汇或表达方式,也能够给出合理的处理结果。
未来的展望:走向更智能的预处理
文本预处理技术正在经历一场深刻的变革。传统的基于规则和统计的方法正在被基于深度学习的方法所补充甚至替代。
多模态预处理是一个令人兴奋的发展方向。当文本与图像、音频等其他模态的信息结合时,预处理系统需要能够理解跨模态的关联。比如在分析一篇包含图片的社交媒体帖子时,系统需要同时理解文字内容和图片内容,以及它们之间的关系。
实时预处理也变得越来越重要。随着对话式AI和实时翻译需求的增长,预处理系统需要能够在毫秒级的时间内完成复杂的语言分析任务。这要求算法不仅要准确,还要足够高效。
跨语言预处理是另一个重要趋势。随着全球化的深入,我们经常需要处理多语言混合的文本。未来的预处理系统需要能够无缝地处理语言切换,理解不同语言之间的语法和语义差异。

文本预处理技术的发展历程就像是人类理解语言能力的一面镜子。从最初简单的分词和词性标注,到现在复杂的语义理解和跨模态分析,每一步进展都让我们更接近真正理解人类语言的奥秘。在这个AI时代,文本预处理技术不仅是NLP系统的基础,更是连接人类智慧与机器智能的重要桥梁。
随着技术的不断进步,我们有理由相信,未来的文本预处理系统将变得更加智能、更加高效,能够更好地理解和处理人类语言的复杂性和多样性。这不仅会推动NLP技术的发展,也会为人机交互开启新的可能性。从混沌到有序:文本预处理技术的奇妙之旅
想象一下,你正站在一个巨大的图书馆里,面前堆积着无数本书籍,每本书都用不同的语言、不同的字体、甚至不同的书写方向编写。作为一个想要理解这些书籍内容的人,你会从何下手呢?这正是现代自然语言处理系统面临的挑战。
网页版:https://jrjlckrd.gensparkspace.com/
视频版:
音频版:
在数字世界中,机器需要一套精密的工具来理解人类的语言,而文本预处理技术就是这套工具的基石。从上图可以看出,文本预处理是一个多步骤的复杂过程,每个环节都至关重要。
分词:将语言的巨石劈成可见的砖块
当你看到"Hello world"这个简单的句子时,你的大脑几乎瞬间就能识别出这是两个单词。但对于计算机来说,这只是一串连续的字符。分词技术就像是一位经验丰富的雕刻师,需要将原始的语言材料精确地切分成一个个有意义的单元。
在传统的分词方法中,词袋模型(Bag of Words)是最直观的方式。就像将所有的单词扔进一个大袋子里,不考虑它们的顺序,只关心它们的存在与否。这种方法虽然简单,但在处理复杂语言现象时显得力不从心。
随着技术的进步,N-grams模型横空出世。它不再满足于单个词汇,而是考虑词汇之间的局部关系。比如当我们看到"neural network"时,bigram模型会将"neural"和"network"作为一个整体来理解,这样的组合往往比单独的词汇更有意义。
BPE:字节对编码的智慧之路
但真正的革命来自于子词切分技术。BPE(Byte Pair Encoding)的出现改变了游戏规则。
这种技术就像是一个智能的语言学家,它能够从大量文本中学习出最佳的切分策略。当遇到"unhappiness"这样的复杂词汇时,BPE可能会将其切分为"un-", "happi", "-ness",每个部分都携带着语义信息。从上图可以清楚地看到BPE算法如何通过迭代合并最频繁的字符对来构建词汇表。
更加精妙的是WordPiece算法。它不仅仅考虑频率,还会计算每个切分方案的概率。当WordPiece面对一个新词时,它会选择能够最大化训练数据似然度的切分方式,这种基于概率的方法让分词结果更加合理。
而SentencePiece则更进一步,它将空格也视为普通字符来处理,这样就能够处理中文、日文等没有明显词边界的语言。它使用特殊符号"_"来表示空格,使得整个过程可以完全可逆,这对于机器翻译等任务来说至关重要。
词性标注:为每个词汇贴上身份标签
如果说分词是将句子切分成词汇,那么词性标注(Part-of-Speech Tagging)就是为每个词汇贴上身份标签。这就像是在一场大型聚会上,每个人都佩戴着标明自己职业的名牌一样。
当我们看到句子"The quick brown fox jumps over the lazy dog"时,词性标注器会告诉我们:"The"是限定词(DT),"quick"是形容词(JJ),"brown"也是形容词(JJ),"fox"是名词(NN),"jumps"是动词(VBZ),以此类推。从上图可以看到,每个词都被准确地标注了其语法角色。
这些标签看似简单,但它们为后续的语言理解提供了至关重要的结构信息。现代的词性标注系统,特别是基于spaCy的实现,已经能够达到97%以上的准确率。这些系统不仅考虑词汇本身,还会考虑上下文信息。比如"book"这个词,在"I read a book"中是名词,而在"I book a flight"中则是动词。
命名实体识别:找出句子中的关键角色
在浩瀚的文本海洋中,某些词汇承载着特殊的意义。它们可能是人名、地名、组织名、时间表达式等。命名实体识别(Named Entity Recognition, NER)就像是一个敏锐的侦探,能够从文本中识别出这些关键信息。
当NER系统分析"Apple Inc. is headquartered in Cupertino, California"这句话时,它会识别出"Apple Inc."是一个组织(ORG),"Cupertino"和"California"是地点(LOC)。从上图可以看到,不同类型的实体被用不同颜色标注出来,这种可视化方式让复杂的识别结果变得一目了然。
这种识别能力对于信息抽取、知识图谱构建等任务来说是不可或缺的。现代的NER系统采用了深度学习技术,特别是基于Transformer的模型,能够处理更加复杂的实体类型和嵌套实体。比如在"Former Microsoft CEO Bill Gates"中,系统需要同时识别出"Microsoft"(组织)、"Bill Gates"(人名)以及"CEO"(职位)之间的复杂关系。
依存句法分析:解码语言的内在结构
如果把句子比作一棵树,那么依存句法分析(Dependency Parsing)就是描绘这棵树的精确蓝图。它不仅告诉我们每个词的位置,更重要的是揭示了词与词之间的依存关系。
在句子"The cat sat on the mat"中,依存句法分析会建立起这样的关系网络:"sat"是整个句子的根节点,"cat"是"sat"的主语(subject),"mat"是介词"on"的宾语(object),而"on the mat"整体作为"sat"的状语(adverbial modifier)。从上图的spaCy可视化结果可以看到,每条弧线都代表一种语法关系,这种树状结构让计算机能够理解句子的语法层次。
对于更复杂的句子,依存句法分析能够揭示出更加精细的语法结构。Stanford的依存句法分析器能够处理多种语言,并且提供了丰富的可视化功能。当你看到依存句法树的可视化结果时,句子的语法结构变得一目了然,就像看到了语言的X光片一样。
工具的选择:NLTK、spaCy还是Hugging Face?
在文本预处理的工具选择上,就像选择合适的画笔来创作艺术品一样重要。每种工具都有其独特的优势和适用场景。
NLTK就像是一个历史悠久的工匠铺,提供了丰富的传统NLP工具。它的教育价值很高,适合学习和研究,但在处理大规模数据时可能显得有些笨重。
spaCy则像是一个现代化的工厂,专注于工业级的性能和易用性。它的处理速度快,预训练模型质量高,特别适合生产环境中的应用。当你需要处理大量文本时,spaCy往往是更好的选择。
而Hugging Face Transformers则代表了最前沿的技术。它提供了各种预训练的Transformer模型,能够在各种NLP任务上达到最先进的性能。如果你追求最高的准确率,并且有足够的计算资源,Hugging Face的工具是不二之选。
实际应用中的挑战与机遇
在真实世界的应用中,文本预处理面临着各种挑战。社交媒体上的非正规文本、多语言混合的内容、含有表情符号和特殊字符的文本,都对传统的预处理方法提出了挑战。
比如当处理推特数据时,"I luv this movie 😍 #amazing"这样的文本包含了非标准拼写、表情符号和话题标签。现代的预处理系统需要能够理解这些元素的含义,而不是简单地将它们忽略或删除。
另一个挑战来自于领域特定的语言。医学文本、法律文档、科技论文都有其独特的词汇和表达方式。通用的预处理工具可能无法很好地处理这些专业领域的文本,需要进行特殊的调整和优化。
然而,这些挑战也带来了机遇。随着大规模预训练语言模型的兴起,我们看到了更加智能的文本预处理方法。这些模型能够从上下文中学习词汇的含义,即使面对从未见过的词汇或表达方式,也能够给出合理的处理结果。
未来的展望:走向更智能的预处理
文本预处理技术正在经历一场深刻的变革。传统的基于规则和统计的方法正在被基于深度学习的方法所补充甚至替代。
多模态预处理是一个令人兴奋的发展方向。当文本与图像、音频等其他模态的信息结合时,预处理系统需要能够理解跨模态的关联。比如在分析一篇包含图片的社交媒体帖子时,系统需要同时理解文字内容和图片内容,以及它们之间的关系。
实时预处理也变得越来越重要。随着对话式AI和实时翻译需求的增长,预处理系统需要能够在毫秒级的时间内完成复杂的语言分析任务。这要求算法不仅要准确,还要足够高效。
跨语言预处理是另一个重要趋势。随着全球化的深入,我们经常需要处理多语言混合的文本。未来的预处理系统需要能够无缝地处理语言切换,理解不同语言之间的语法和语义差异。
文本预处理技术的发展历程就像是人类理解语言能力的一面镜子。从最初简单的分词和词性标注,到现在复杂的语义理解和跨模态分析,每一步进展都让我们更接近真正理解人类语言的奥秘。在这个AI时代,文本预处理技术不仅是NLP系统的基础,更是连接人类智慧与机器智能的重要桥梁。
随着技术的不断进步,我们有理由相信,未来的文本预处理系统将变得更加智能、更加高效,能够更好地理解和处理人类语言的复杂性和多样性。这不仅会推动NLP技术的发展,也会为人机交互开启新的可能性。