想象一下,如果你能教会计算机像人类一样理解和预测语言,那会是什么样子?这个看似简单的问题,实际上开启了现代自然语言处理最精彩的技术革命之旅。今天,让我们一起踏上这段从朴素的统计计数到强大神经网络的探索之路。
网页版:https://reftdprs.gensparkspace.com/
视频版:https://www.youtube.com/watch?v=wp1FLENPrkM
第一章:N-gram模型——语言建模的统计学起源
什么是N-gram?一个简单却深刻的想法

在1940年代,当计算机还是庞大的机械怪物时,一位名叫Claude Shannon的天才工程师就在思考:能否用数学方法来描述人类语言的规律?他的想法简单得令人惊讶——通过统计前面出现的词来预测下一个词。
这就是N-gram模型的核心思想。想象你正在读一本小说,看到"The cat sat on the"这句话,你的大脑会自动预期下一个词可能是"mat"、"floor"或"chair",而不太可能是"elephant"。N-gram模型就是要教会计算机这种直觉。
Unigram(1-gram):只考虑单个词的频率
Bigram(2-gram):考虑前一个词的影响
Trigram(3-gram):考虑前两个词的影响
N-gram的数学魅力

让我们看一个实际的例子。假设我们有一个关于"Jack建造房子"的小语料库:
<s> This is the house that Jack built </s>
<s> This is the malt that lay in the house that Jack built </s>
<s> This is the rat that ate the malt that lay in the house </s>
要计算P(house|the)的概率,我们需要:
- 统计"the house"出现的次数:3次
- 统计"the"出现的总次数:8次
- 概率 = 3/8 = 0.375
这种基于**最大似然估计(MLE)**的方法看起来简单,但它蕴含着深刻的统计学原理。正如斯坦福大学的Dan Jurafsky教授在其经典教材中所写:"N-gram模型的美妙之处在于,它用最简单的假设捕捉了语言中最基本的统计规律"斯坦福大学N-gram教程。
马尔可夫假设:化繁为简的智慧
N-gram模型基于一个关键假设——马尔可夫假设:未来只依赖于当前状态,而不依赖于过去的历史。在语言建模中,这意味着:
P(wₙ|w₁,w₂,…,wₙ₋₁) ≈ P(wₙ|wₙ₋ₖ₊₁,…,wₙ₋₁)
这个假设虽然简化了现实,但让计算变得可行。就像物理学中的"完全弹性碰撞"假设一样,它不完全符合现实,但提供了有用的近似。
第二章:困惑度——语言模型的"体检报告"
什么是困惑度?
困惑度(Perplexity)是评估语言模型性能的金标准指标。它的定义看起来有些复杂,但概念很直观:
Perplexity(W) = P(w₁w₂…wₙ)^(-1/N)
困惑度越低,模型越好。这就像考试成绩——分数越高越好,但困惑度是"越低越好"的指标。
困惑度的直观理解
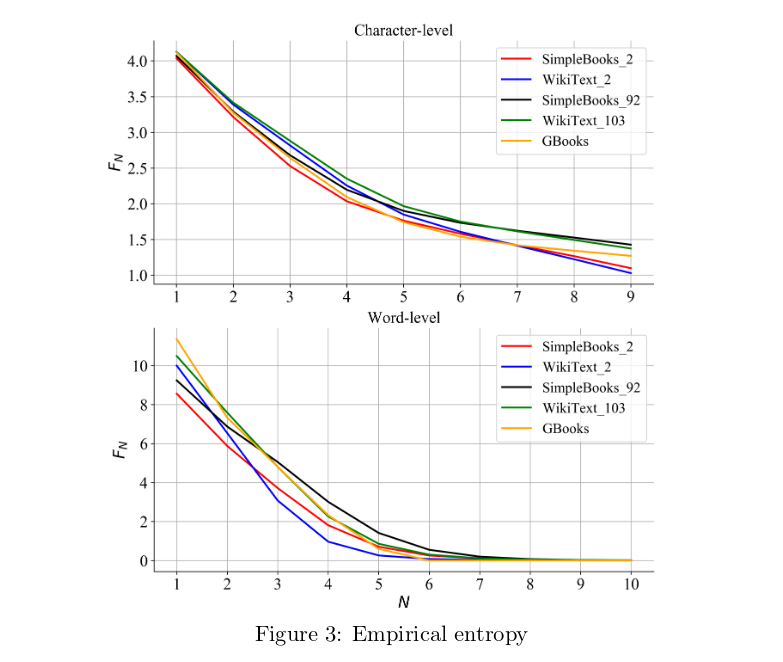
想象一个只有三种颜色的简单语言:红、蓝、绿。如果每种颜色出现的概率相等(1/3),那么困惑度就是3。但如果红色出现80%的时间,蓝色和绿色各10%,困惑度就会降到约1.89。
这告诉我们一个重要道理:预测性越好的模型,困惑度越低。正如Hugging Face团队在其技术博客中指出的:"困惑度是语言模型质量的温度计——它能准确反映模型对语言规律的掌握程度"Hugging Face困惑度指南。
第三章:平滑技术——处理未知的艺术
零概率问题:N-gram的阿喀琉斯之踵
N-gram模型有一个致命弱点:数据稀疏性。当遇到训练数据中从未出现过的词组合时,模型会给出零概率,这显然不合理。
拉普拉斯平滑:给每个可能一次机会
**加一平滑(Add-1 Smoothing)**是最简单的解决方案:
P(wᵢ|wᵢ₋₁) = (C(wᵢ₋₁wᵢ) + 1) / (C(wᵢ₋₁) + V)
其中V是词汇表大小。这就像给每个可能的词组合都"预付"了一次出现机会。
更高级的平滑技术
现代NLP系统通常使用更复杂的平滑方法:
- Good-Turing平滑:基于概率质量重分配
- Kneser-Ney平滑:考虑词汇的多样性
- Interpolation平滑:结合不同阶的N-gram
第四章:神经语言模型的革命
从统计到学习:神经网络的登场
2003年,Bengio等人发表了里程碑式的论文,首次将神经网络应用于语言建模。这标志着语言建模从统计时代进入学习时代。
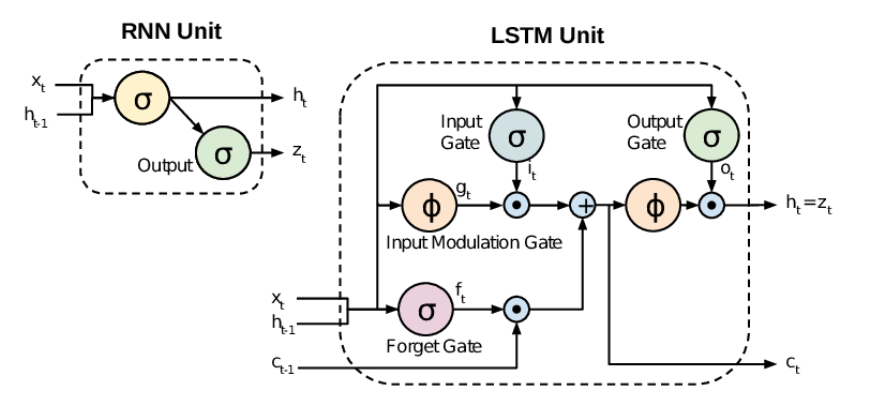
RNN:会"记忆"的神经网络

循环神经网络(RNN)的革命性在于:它不再受固定窗口大小限制,理论上可以处理任意长度的序列。RNN的核心思想是隐藏状态的循环更新:
hₜ = tanh(Wₕₕhₜ₋₁ + Wₓₕxₜ + bₕ)
这个简单的公式蕴含着深刻的思想:每个时刻的状态都承载着之前所有信息的"记忆"。
LSTM:解决长期依赖的英雄

长短期记忆网络(LSTM)是RNN的改进版本,通过引入门控机制解决了梯度消失问题:
- 遗忘门:决定丢弃哪些信息
- 输入门:决定存储哪些新信息
- 输出门:决定输出哪些信息
正如深度学习之父Yoshua Bengio所说:"LSTM的门控机制让神经网络第一次真正学会了’选择性记忆’,这是智能的重要特征"Bengio LSTM论文。
第五章:Transformer时代——注意力就是一切
自注意力机制:并行的力量
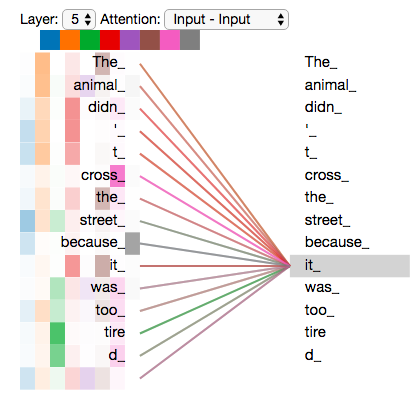
2017年,Google团队发表了震撼业界的论文《Attention Is All You Need》,提出了Transformer架构。它的核心创新是自注意力机制:
Attention(Q,K,V) = softmax(QK^T/√dₖ)V
多头注意力:从多个角度理解语言
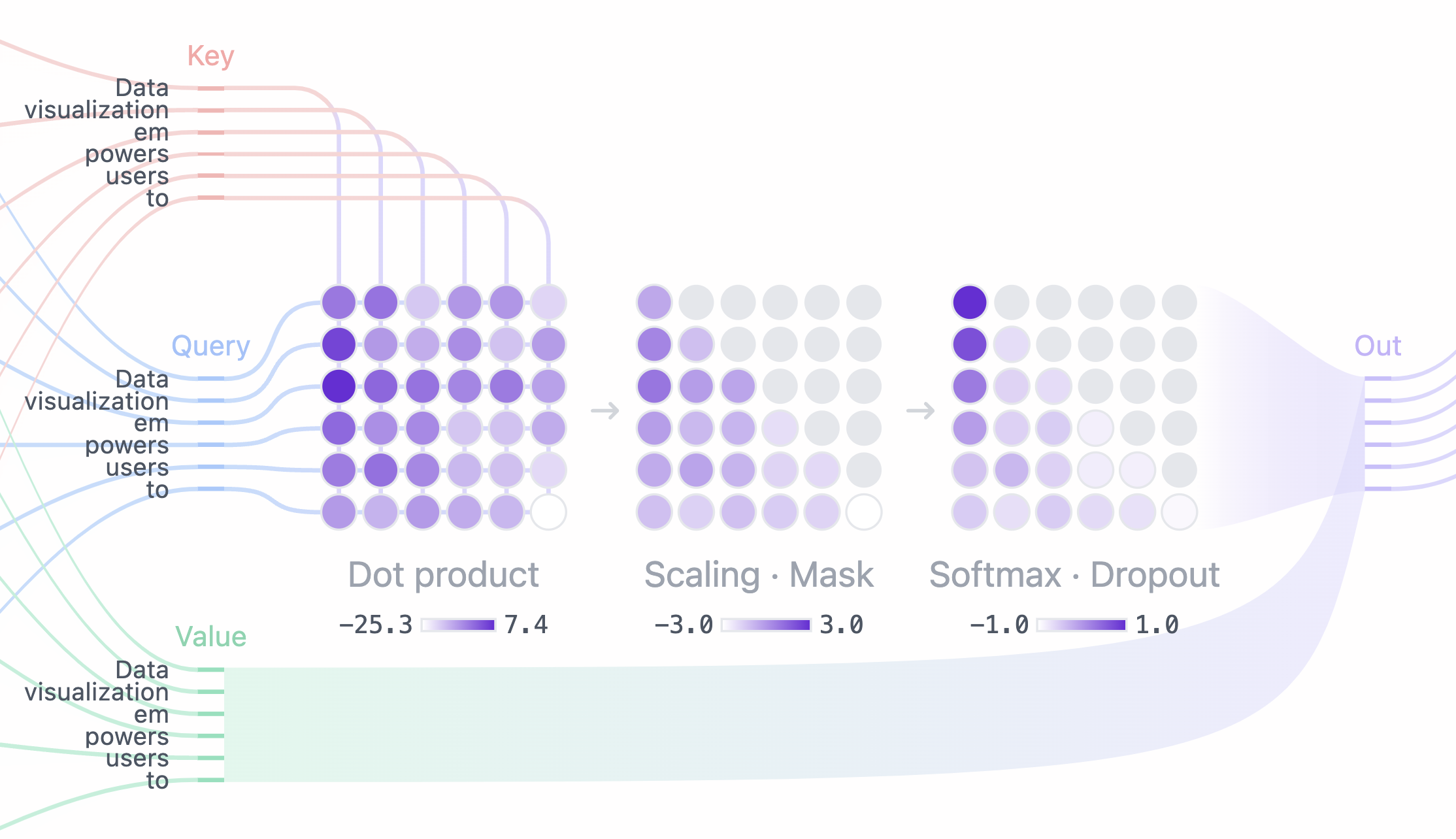
Transformer使用多头注意力,就像拥有多双眼睛,每一双都从不同角度观察语言:
- 有些关注句法结构
- 有些关注语义关系
- 有些关注长距离依赖
这种设计让Transformer能够捕捉到语言中更复杂、更微妙的模式。
Transformer的优势:为什么它改变了一切

Transformer相比RNN的优势是全方位的:
- 并行计算:不再需要逐步处理,大大提高训练效率
- 长距离建模:注意力机制让任意位置的词都能直接交互
- 可解释性:注意力权重提供了模型决策的可视化窗口
正如OpenAI的研究科学家Alec Radford所言:"Transformer不仅仅是一个更好的模型架构,它重新定义了我们对语言理解的认知边界"GPT论文。
第六章:实践应用与未来展望
从理论到应用:语言模型的实际价值
现代语言模型的应用已经渗透到我们生活的方方面面:
- 智能搜索:Google搜索的背后就有强大的语言模型
- 机器翻译:Google翻译、DeepL等工具
- 智能写作:ChatGPT、Claude等对话系统
- 代码生成:GitHub Copilot等编程助手
技术演进的启示
回顾语言模型70多年的发展历程,我们看到了几个重要的技术演进规律:
- 从规则到统计到学习:体现了人工智能发展的整体趋势
- 从局部到全局:模型能够处理的上下文越来越长
- 从单任务到多任务:现代大模型展现出惊人的通用性
挑战与机遇并存
当前语言模型仍面临诸多挑战:
- 计算资源需求:训练大模型需要海量计算资源
- 数据质量:模型性能高度依赖训练数据质量
- 可解释性:模型决策过程仍有待深入理解
- 公平性与偏见:如何确保模型的公平性
但同时,新的机遇也在不断涌现:
- 多模态融合:结合文本、图像、语音的统一模型
- 少样本学习:通过更好的预训练减少对标注数据的依赖
- 个性化模型:针对特定用户或场景的定制化模型
结语:技术的诗意与未来的召唤
从Shannon的信息论到Transformer的注意力机制,语言模型的发展史就是一部人类智慧的结晶史。每一次技术突破,都让我们离真正的人工智能更近一步。
正如著名计算机科学家Alan Kay所说:"预测未来的最好方法就是创造未来。"在这个人工智能蓬勃发展的时代,理解语言模型的基础原理不仅是技术学习的需要,更是参与创造未来的必备素养。
无论你是刚入门的初学者,还是经验丰富的研究者,希望这段从N-gram到Transformer的技术之旅能够为你提供有价值的洞察。记住,每一个伟大的技术突破,都始于对基础原理的深刻理解。