视频版:https://www.youtube.com/watch?v=ZjAeOe3UZuw
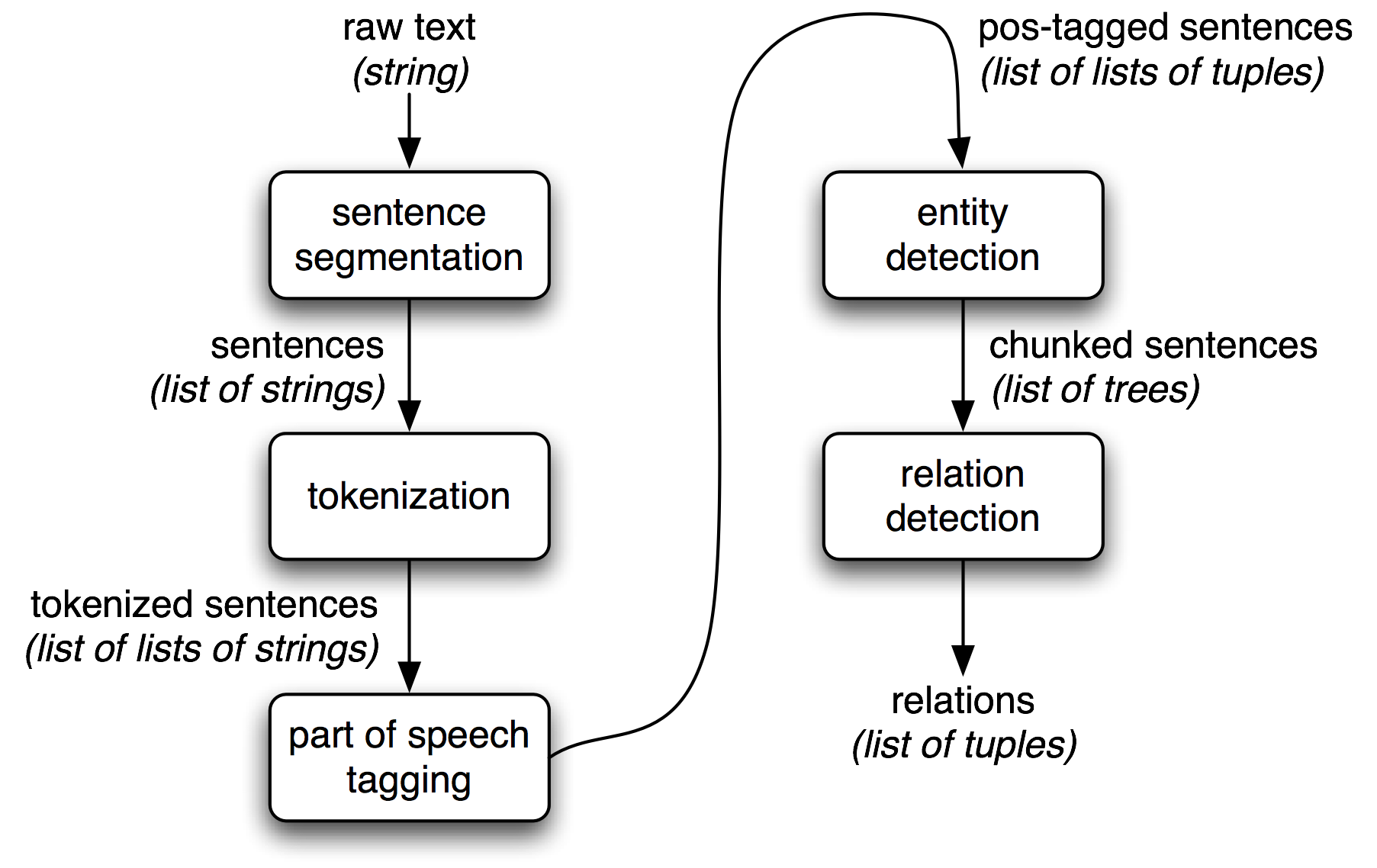
图1:信息抽取系统架构图 – 从原始文本到结构化知识的完整流程
在斯坦福大学计算机科学系的实验室里,研究生李明正盯着屏幕上密密麻麻的医学文献,思考着一个令人头疼的问题:如何从这些浩如烟海的文本中自动提取出有价值的医学知识。这不是科幻小说的情节,而是当今人工智能领域最激动人心的挑战之一——信息抽取技术。
当机器开始阅读:信息抽取的奇妙世界

图2:自然语言处理与信息抽取的完整处理链条
想象一下,如果计算机能够像人类一样阅读和理解文本,从新闻报道中识别出人物关系,从医学论文中提取疾病与症状的关联,从法律文件中梳理出复杂的法律关系——这就是信息抽取技术的使命。
Stanford CS224U Natural Language Understanding课程的Bill MacCartney教授曾经生动地描述过这个领域的愿景:通过机器阅读,我们要构建一个包含地球上80%事实内容的结构化知识库。这个看似疯狂的目标,正在通过关系抽取、事件抽取和知识图谱构建等技术逐步变为现实。
从规则到智慧:技术演进的三个里程碑

图3:现代信息抽取模型的设计架构 – 融合深度学习与传统方法
信息抽取技术的发展历程就像是一部精彩的科技进化史。在上世纪80-90年代,研究者们主要依靠手工编写的模式匹配规则。比如,要识别"创始人"关系,他们会写下"X是Y的创始人"或"X,Y的创始人"这样的模板。
然而,语言的复杂性很快暴露了这种方法的局限性。Explosion AI的博客中提到的一个例子很好地说明了这个问题:同样表达"埃隆·马斯克创立了SpaceX"这个事实,可能会有无数种不同的表达方式,许多表达方式是我们无法预先设计模板的。
2000年前后,机器学习革命席卷了自然语言处理领域。研究者们开始用监督学习的方法训练分类器,让机器从标注数据中学习识别关系和事件的模式。这种方法的效果显著提升,但标注数据的获取成本极其昂贵。
直到2010年,距离监督(Distant Supervision)的出现才真正改变了游戏规则。这个天才的想法是:利用现有的知识库作为"老师",自动为大量文本生成训练标签。虽然会引入一些噪声,但海量数据带来的收益远超过噪声造成的损失。
关系抽取:连接实体的智慧纽带

图4:关系抽取任务示意图 – 识别实体间的语义关系
关系抽取技术就像是文本世界的"红线仙",专门负责发现和标注实体之间的关系。在生物医学领域,这意味着要找出"GATA3抑制FOXP3表达"这样的基因调控关系。在商业分析中,则要识别"苹果公司收购了Siri"这样的并购关系。
BERT模型:关系抽取的超级英雄

图5:BERT模型在关系抽取任务中的架构设计
TowardsDataScience的详细教程展示了BERT模型在关系抽取中的强大能力。在一个职位描述的分析案例中,BERT模型能够准确识别出"3年以上Python开发经验"中年限与技能的关系,准确率高达95%以上。
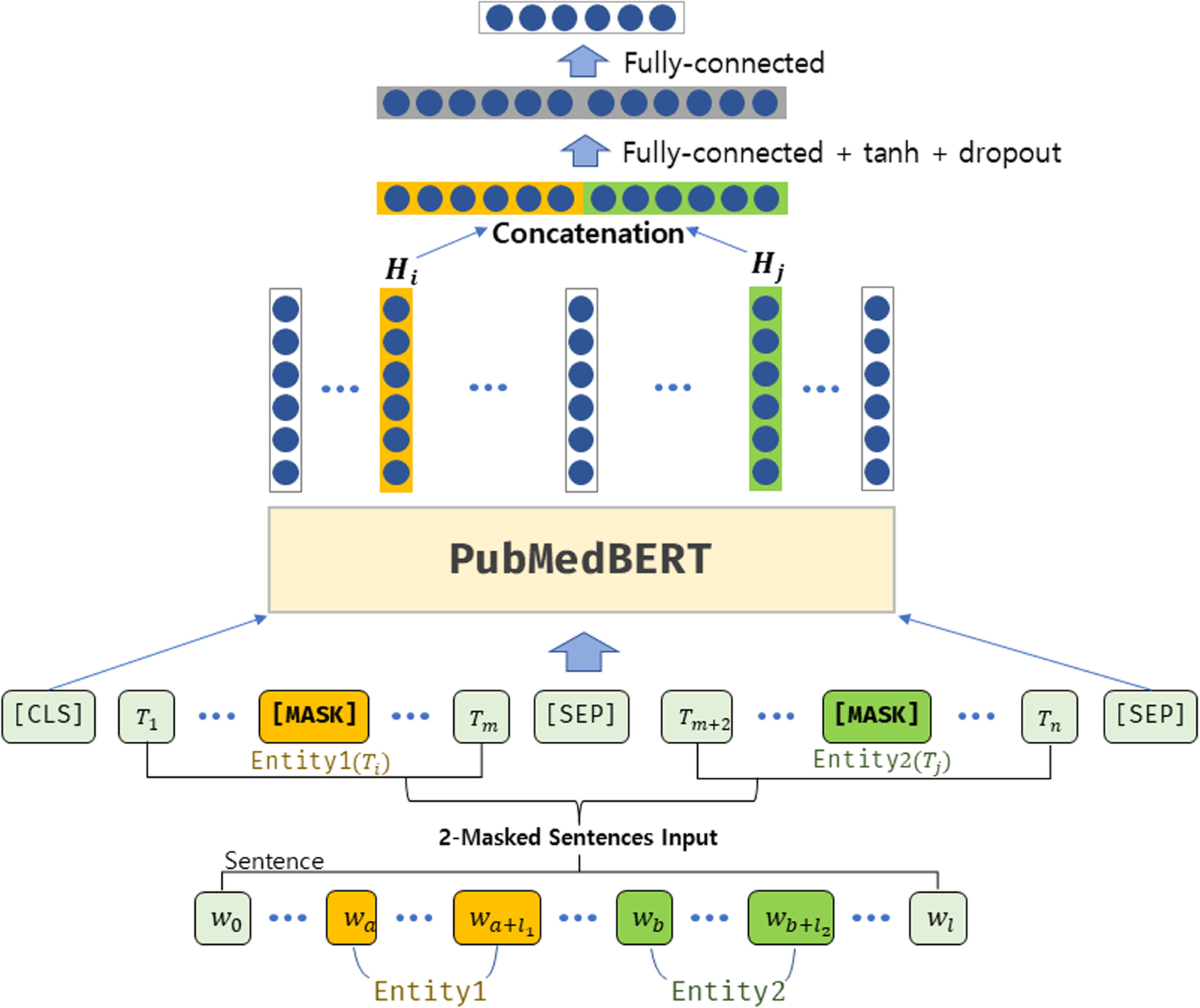
图6:BERT微调用于医学关系抽取的详细架构
更令人惊奇的是,研究者发现仅用100个标注样本训练的BERT关系抽取模型,其表现就能显著超越传统的基于特征工程的方法。这种"少样本学习"能力让信息抽取技术在实际应用中变得更加实用。
SpaCy:让关系抽取变得触手可及

图7:SpaCy的处理流水线架构 – 模块化的NLP处理框架
对于想要动手实践的开发者来说,SpaCy提供了一个绝佳的起点。正如Explosion AI的实战指南所展示的,通过SpaCy 3.0的新架构,开发者可以轻松构建自定义的关系抽取组件。

图8:SpaCy的整体架构设计 – 从文本输入到结构化输出
# 一个简单而强大的关系抽取示例
nlp = spacy.load("en_core_web_trf")
doc = nlp("苹果公司的CEO蒂姆·库克宣布了新产品发布计划")
for rel in doc._.rel:
print(f"关系: {rel}")
事件抽取:捕捉时间流中的关键瞬间

图9:事件检测与事件抽取的核心概念图
如果说关系抽取关注的是静态的连接,那么事件抽取则专注于动态的过程。它要识别的不仅仅是"谁"和"什么",更要回答"何时"、"何地"、"为何"、"如何"等关键问题。

图10:事件抽取的重要性与应用价值
生物医学领域的突破性应用
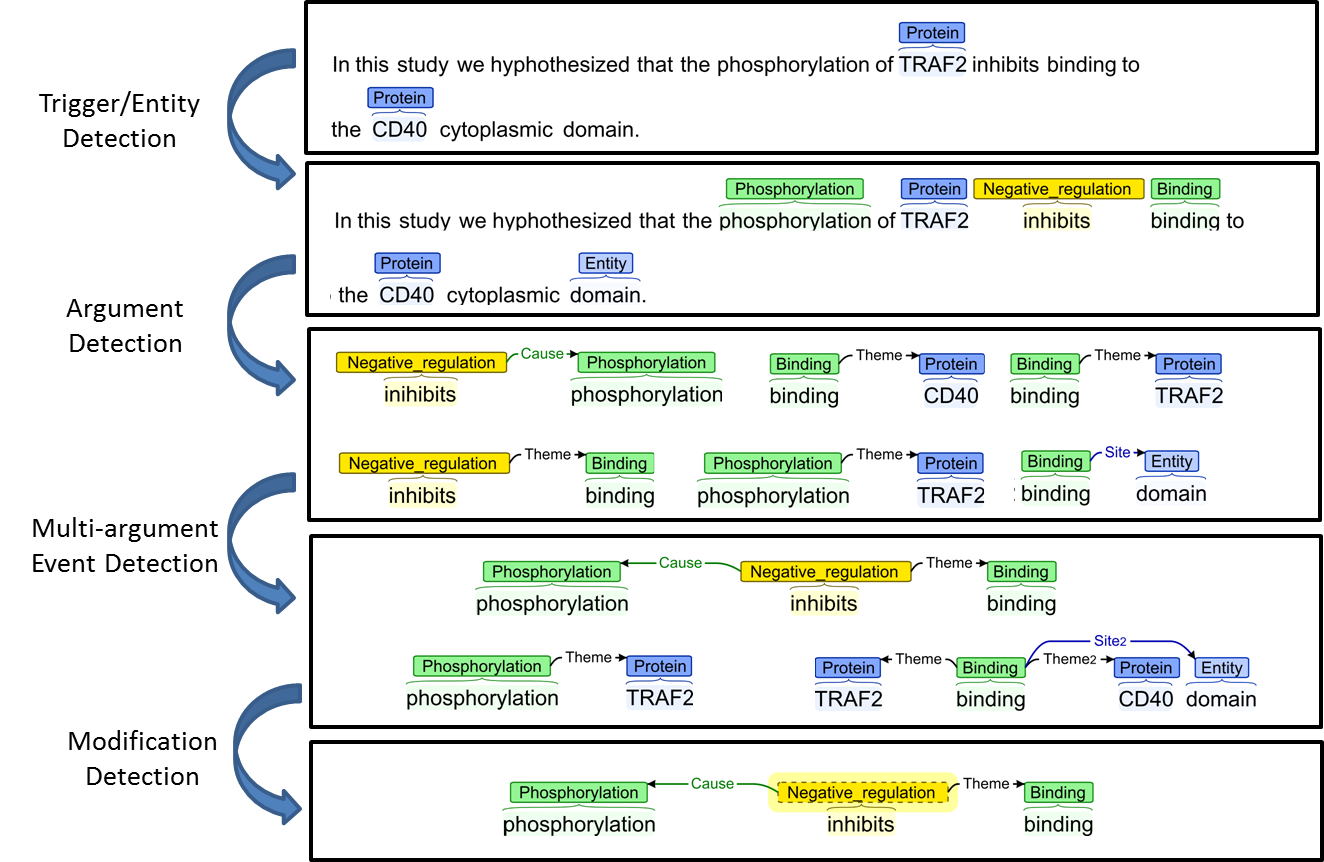
图11:EventMine系统的生物医学事件抽取流程
在新冠疫情期间,事件抽取技术发挥了关键作用。研究者们利用这项技术从数百万篇医学文献中快速提取疫情相关的事件信息:病毒变异、疫苗研发、临床试验结果等。Nature文章提到的一个案例显示,自动化事件抽取系统在3个月内处理了超过120万篇COVID-19相关论文,提取出的关键信息为疫情应对决策提供了重要支持。
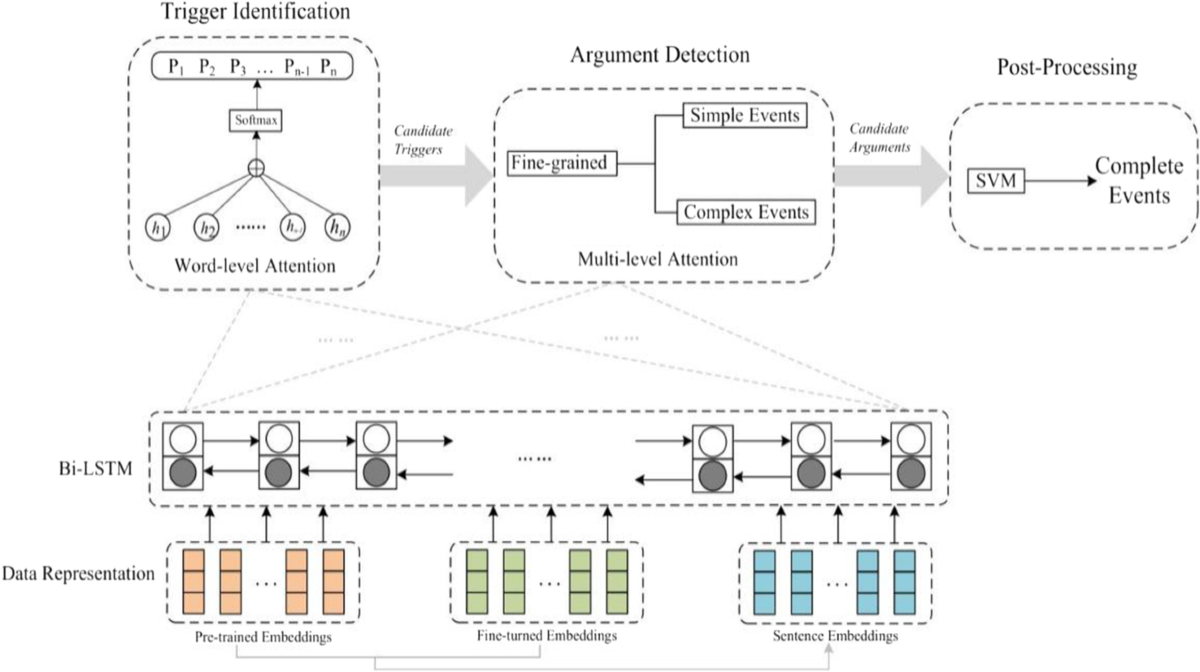
图12:基于深度学习的生物医学事件抽取模型架构
挑战与解决方案

图13:生物医学文本挖掘中的事件抽取应用
事件抽取面临的最大挑战是事件的复杂性和多样性。一个简单的新闻报道可能包含多个相互重叠的事件,每个事件又可能有多个参与者和时间节点。为了解决这个问题,研究者们开发了基于图神经网络的方法,将句子建模为图结构,更好地捕捉事件之间的复杂关系。
知识图谱构建:编织智慧的蛛网
图14:知识图谱的可视化展示 – 复杂关系网络的直观呈现
知识图谱是信息抽取技术的终极目标——将从文本中提取的实体、关系和事件组织成一个巨大的结构化知识网络。Google的知识图谱包含超过500亿个事实,覆盖数十亿个实体,这个规模足以让人感到震撼。
图15:复杂知识网络的分析与可视化
从GPT-4到知识图谱:新时代的到来
图16:大规模知识图谱的网络结构可视化
Thu Vu的精彩演示展示了大语言模型如何彻底改变知识图谱构建的范式。传统方法需要复杂的规则设计和大量的手工标注,而GPT-4等模型可以直接从文本中一步生成结构化的知识图谱。
在一个实际案例中,研究者使用GPT-4分析《权力的游戏》相关文本,自动构建了包含数百个角色和数千个关系的复杂知识图谱。整个过程只需要几分钟,而传统方法可能需要数月的人工工作。
Neo4j:知识图谱的可视化魔法

图17:Neo4j平台上的知识图谱实例
现代知识图谱不仅要存储知识,更要以直观的方式展示知识。Neo4j等图数据库平台提供了强大的可视化工具,让复杂的知识网络变成了可以交互探索的"知识地图"。在这个地图上,用户可以像游览真实世界一样,从一个概念"旅行"到另一个概念,发现意想不到的知识连接。
图18:高级知识图谱可视化工具界面
实战案例:从理论走向应用

图19:信息抽取技术在各个领域的应用场景
让我们看一个具体的应用场景:智能招聘系统。传统的招聘系统只能进行简单的关键词匹配,而基于信息抽取技术的智能系统能够:
- 关系抽取: 识别"5年Java开发经验"中经验年限与技术技能的关系
- 事件抽取: 提取候选人的工作经历、项目经验、成就获得等关键事件
- 知识图谱: 构建包含技能、公司、项目、成就等多维度的候选人知识档案
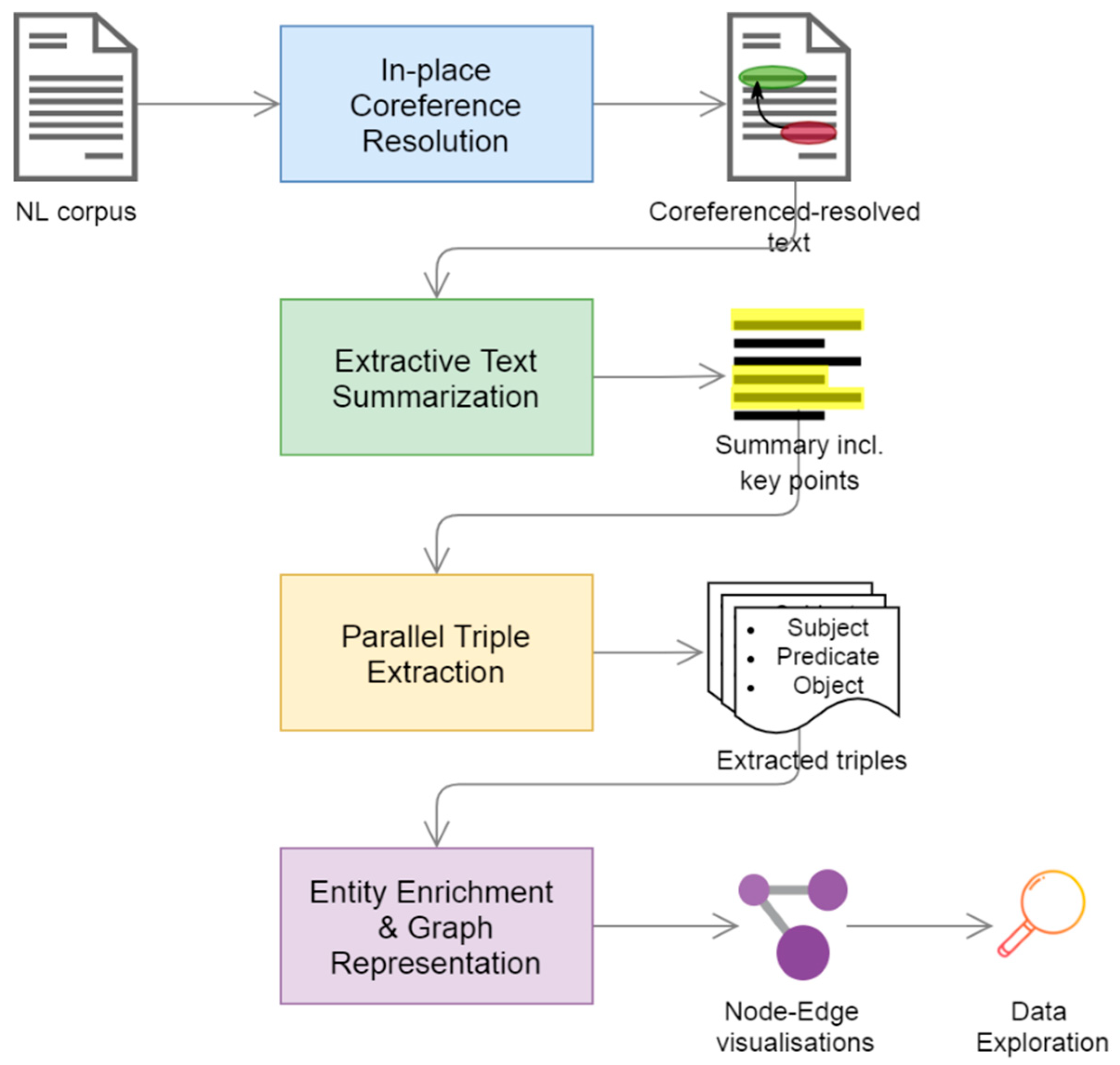
图20:开放域信息抽取的综合方法论
这样的系统不仅能提高匹配精度,还能发现传统方法无法捕捉的潜在适配性。
技术挑战与未来展望

图21:自然语言处理技术的整体发展图景
尽管信息抽取技术已经取得了显著进展,但仍面临诸多挑战:
多语言处理的复杂性
不同语言在表达关系和事件时有着截然不同的语法结构和文化背景。中文的"是"字句、英文的被动语态、阿拉伯语的右到左书写——这些语言特性都需要专门的技术方案。
隐含知识的推理
人类在理解文本时会运用大量的背景知识和常识推理。"苹果发布了新iPhone"这个简单的句子,人类能够推断出苹果公司、产品发布、技术创新等多层含义,而让机器达到这种理解水平仍然是巨大的挑战。
实时性与准确性的平衡
在新闻事件分析、股市监控等实时应用场景中,系统需要在保证准确性的同时实现毫秒级的响应速度。这要求算法设计者在模型复杂度和计算效率之间找到最佳平衡点。
走向未来:下一代信息抽取技术

图22:SpaCy中可训练组件的生命周期管理
随着大语言模型技术的不断进步,信息抽取正在迎来新的革命。GPT-4、Claude等模型展现出了强大的零样本和少样本学习能力,可以在没有特定训练数据的情况下完成复杂的信息抽取任务。
多模态融合的新前沿

图23:多模态信息抽取的人机协作平台
未来的信息抽取系统将不再局限于文本,而是能够同时处理图像、视频、音频等多种模态的信息。想象一下,系统能够从一段新闻视频中同时提取解说员的语音信息、画面中的视觉线索、屏幕上的文字内容,并将这些信息融合成完整的事件描述。
个性化知识发现
基于用户兴趣和需求的个性化信息抽取将成为新的热点。系统能够根据用户的专业背景、研究方向、工作需求等因素,有针对性地从海量信息中提取最相关的知识,真正实现"千人千面"的智能信息服务。

图24:SpaCy项目管理系统 – 端到端的NLP工作流
结语:智慧的新纪元
图25:完整的自然语言处理流程图
从斯坦福实验室的研究突破到硅谷公司的商业应用,从学术论文的理论探讨到开源工具的普及推广,信息抽取技术正在重塑我们处理和理解信息的方式。它不仅是人工智能领域的技术创新,更是人类认知能力的延伸和放大。
在这个信息爆炸的时代,信息抽取技术就像是一把智慧的钥匙,帮助我们打开知识宝库的大门。无论是医生诊断疾病、律师分析案例、记者调查真相,还是学者探索未知,这项技术都将成为不可或缺的智能助手。
正如李明在斯坦福实验室中的感慨:"当机器学会阅读和理解的那一刻,人类的知识边界就会被无限扩展。"这不仅仅是技术的胜利,更是人类智慧与机器智能完美结合的美好未来。