想象一下,如果把大语言模型的发展比作人类的航海探险,那么阿里云的Qwen系列就像是从哥伦布发现新大陆,到麦哲伦环球航行,再到现代太空探索的完整史诗。从2023年8月第一代Qwen问世,到2024年底Qwen3的发布,这个由中国团队打造的AI大模型家族,正在用一种近乎疯狂的速度重新定义着人工智能的边界。
视频版:https://www.youtube.com/watch?v=PKNH-bsyQvU
这不是一个简单的技术升级故事。当我们深入挖掘Qwen2到Qwen3的演进历程时,会发现这更像是一场关于"规模法则"的终极实验——每一次迭代都在回答一个核心问题:当我们把训练数据从7万亿扩展到36万亿tokens时,AI到底能变得多聪明?
数字背后的野心:从7T到36T的算力军备竞赛
让我们先来看几个让人咋舌的数字。Qwen2的技术报告显示,这个72B参数的模型在7万亿tokens的数据上进行训练,在MMLU基准测试中达到84.2分,HumanEval编程测试获得64.6分。这些数字在2024年中期已经足够亮眼,但Qwen团队显然不满足于此。

到了Qwen2.5发布时,训练数据规模跃升至18万亿tokens——这相当于把整个英文维基百科读了近2万遍。而当Qwen3横空出世时,36万亿tokens的训练规模更是让人瞠目结舌。这种指数级的数据扩张背后,隐藏着一个残酷的现实:在大模型竞赛中,没有任何捷径可走,只有通过更多数据、更强算力才能获得更智能的AI。
但这里有个有趣的细节。与其他厂商不同,阿里云团队并没有盲目地增加参数数量。相反,他们选择了一条更加巧妙的路线:通过架构创新来提升效率。比如在Qwen2中引入的群组查询注意力(GQA)机制,能够在推理时显著减少内存占用,让模型在保持性能的同时运行得更快。
MoE革命:当AI学会了"术业有专攻"
如果说数据规模的扩张是蛮力,那么混合专家(MoE)架构的引入就是智慧的体现。想象一个超级智能的管弦乐队,每个演奏者都是某个领域的专家——小提琴手专注弦乐,鼓手负责节拍,指挥负责协调。MoE就是让AI模型学会了这种"术业有专攻"的智慧。

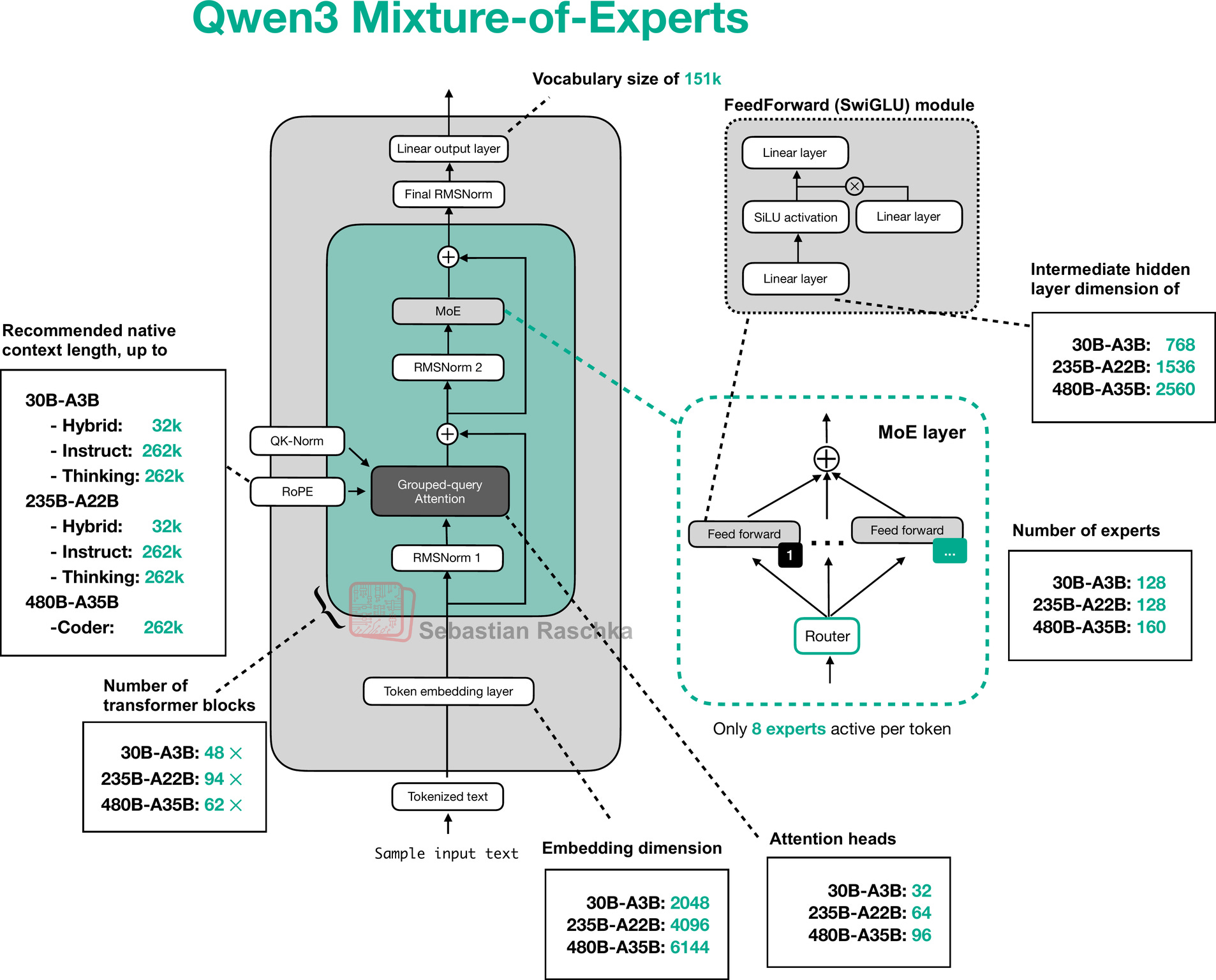
Qwen3的MoE设计特别精彩。以Qwen3-235B-A22B为例,虽然总参数达到235亿,但每次推理时只激活22亿参数。这意味着它拥有巨大的知识容量,但运行时的计算成本却相对较低。这就像拥有一个包含235位专家的智囊团,但每次解决问题时只需要22位最相关的专家出场。
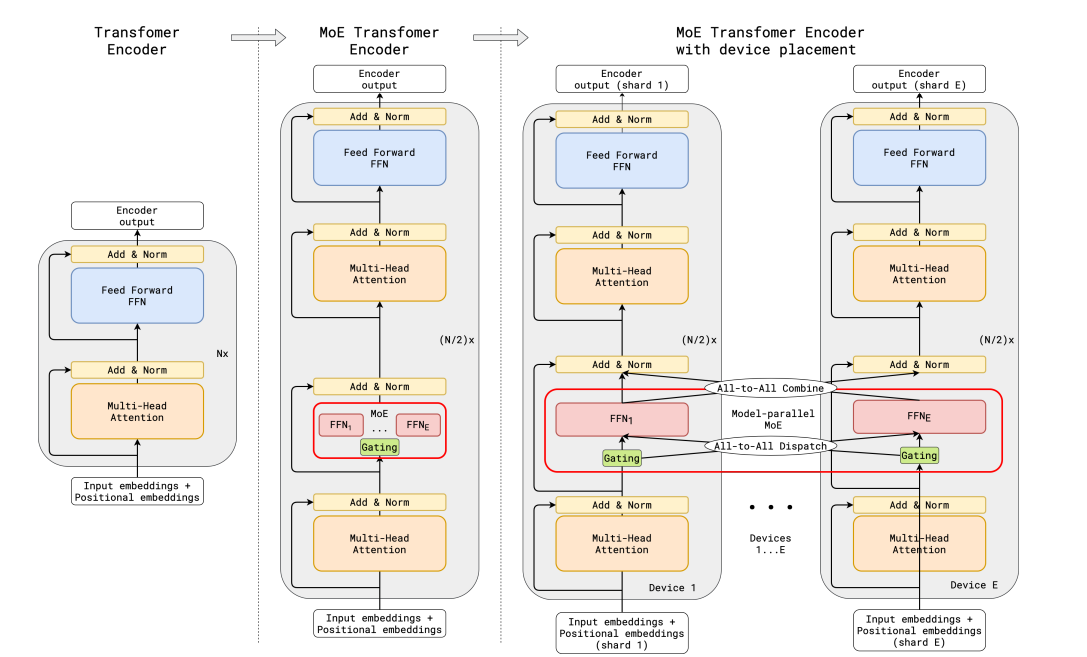
更让人惊讶的是Qwen3-30B-A3B模型的表现。这个只有30亿总参数、3亿激活参数的"小个子",在某些任务上竟然能够匹敌传统的32B密集模型。技术报告显示,MoE模型在训练和推理成本上都实现了显著降低,同时保持了与更大模型相当的性能水平。
多模态融合的华丽转身
如果说语言模型的进化是一场革命,那么多模态能力的加入就是这场革命中最华丽的转身。从Qwen2-VL到Qwen2.5-VL,再到Qwen2.5-Omni,我们见证了AI从"只会聊天"到"能看能听能说"的跨越式发展。
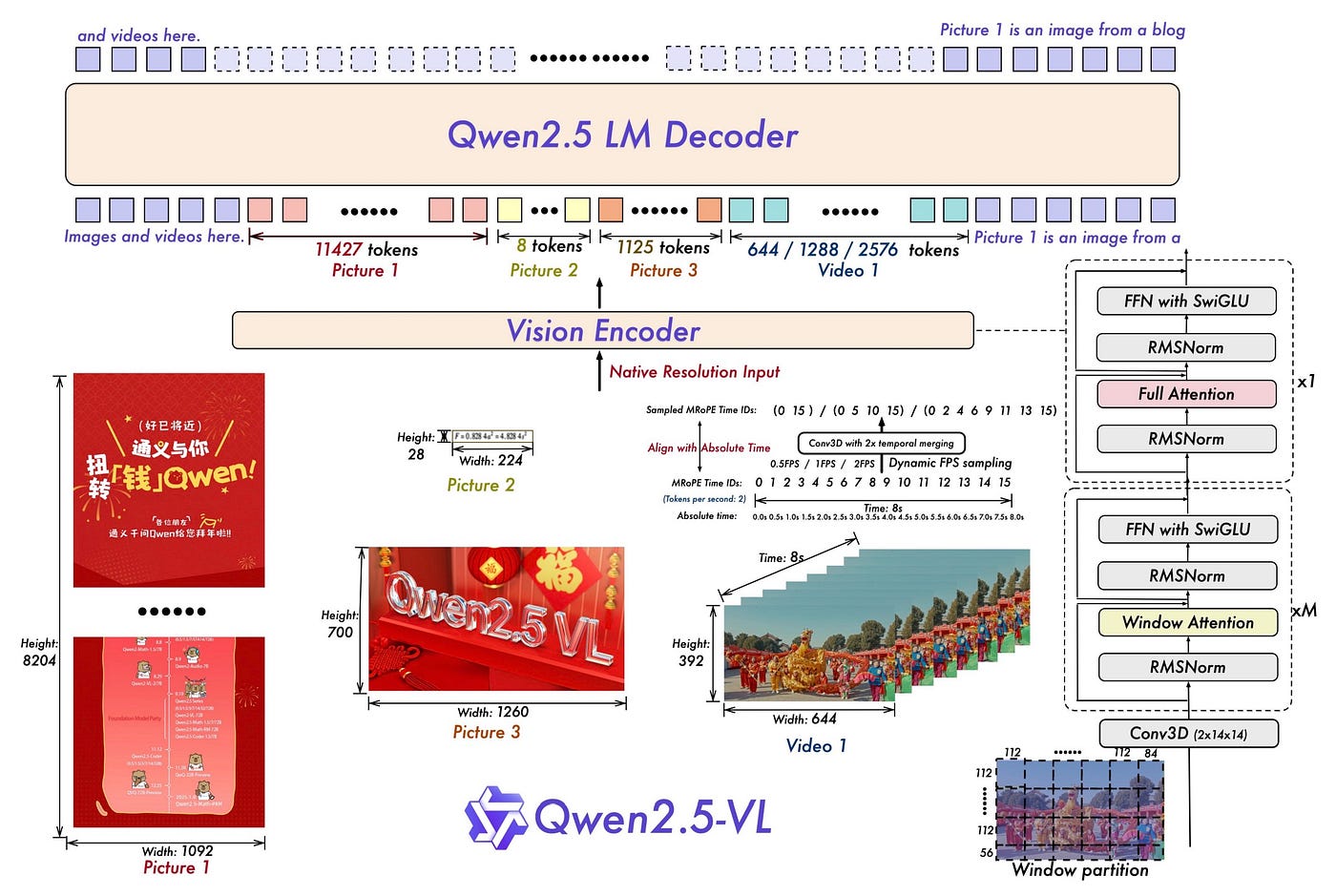
Qwen2.5-VL的能力让人印象深刻。它不仅能够识别图像中的对象,还能够精确地进行文档解析。想象一下,你拍一张发票的照片,它能够准确提取出所有的文字信息,并按照结构化的格式输出。这种"全文档解析"能力的背后,是对OCR技术的全面升级——从简单的文字识别提升为对多场景、多语言、多方向文本的理解。

但真正的突破来自Qwen2.5-Omni。这个模型采用了独特的"Thinker-Talker"架构——Thinker负责思考和理解,Talker负责自然的语音输出。这种设计让模型能够同时处理文本、图像、音频和视频输入,并以自然语音的形式实时回应。
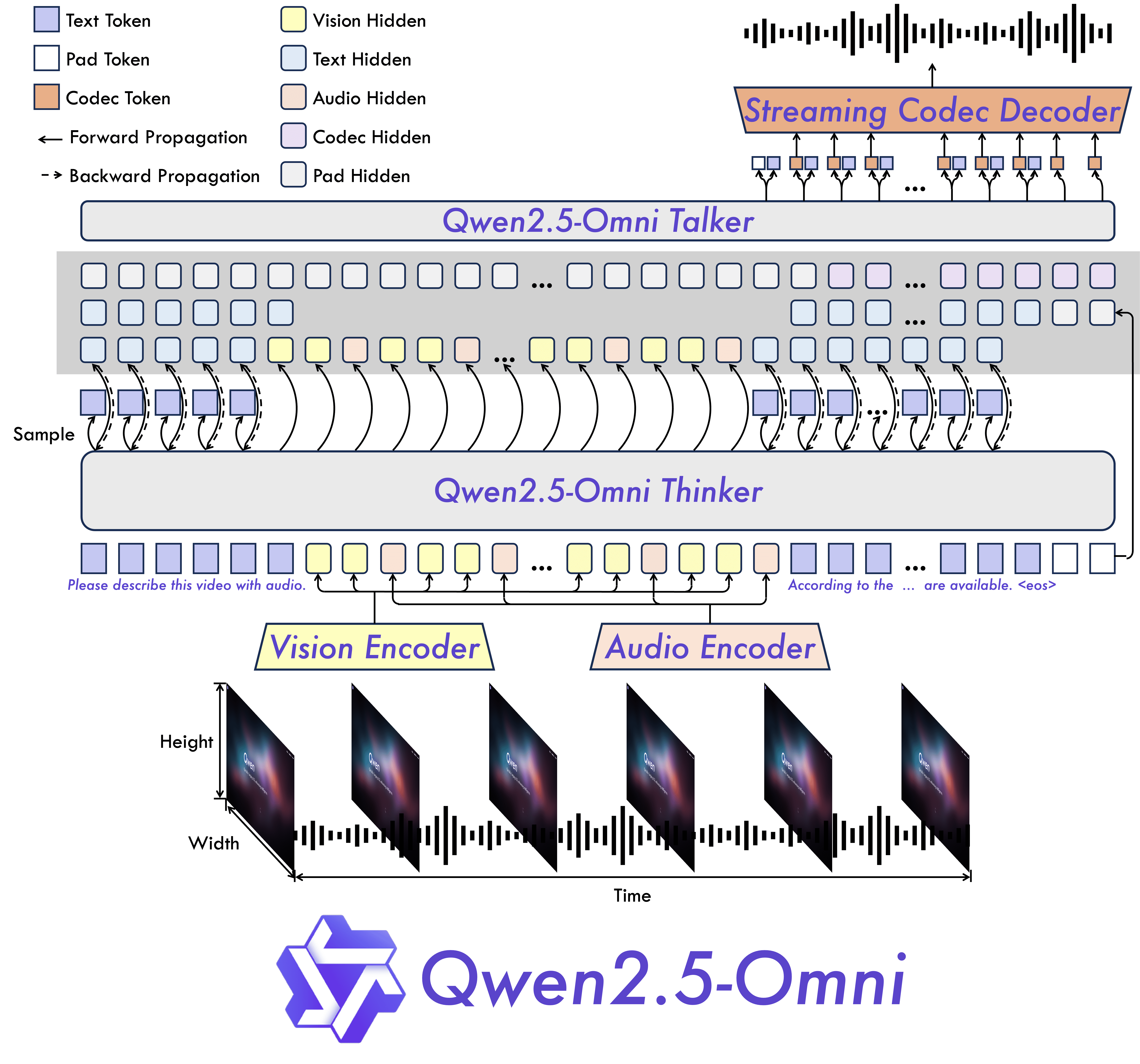
最让人兴奋的是TMRoPE(Time-aligned Multimodal RoPE)技术的引入。这个技术解决了一个关键问题:如何让AI理解不同模态信息的时间同步关系。比如在一个视频中,当某人在第30秒说了一句话时,AI需要理解这句话与同时出现的画面内容之间的关联。
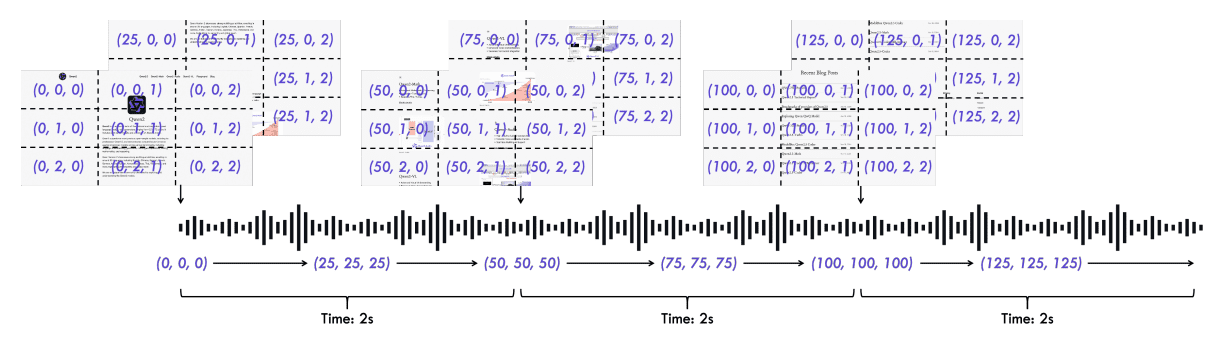
TMRoPE技术巧妙地解决了这个挑战,让多模态信息能够在时间维度上完美对齐。
思考模式的哲学突破
也许Qwen3最引人深思的创新是"思考模式"与"指令模式"的双模式设计。这不仅仅是技术层面的改进,更像是对AI认知机制的一次哲学探索。
在传统的"指令模式"下,AI会直接回答用户的问题,就像一个训练有素的客服人员。但在"思考模式"下,AI会像人类一样进行逐步推理。它会在回答前在<think></think>标签中展现自己的思考过程,然后再给出最终答案。
这种设计的精妙之处在于,用户可以根据问题的复杂程度选择合适的模式。对于简单的事实性问题,指令模式足够快速高效;对于需要深度分析的复杂问题,思考模式能够提供更加可靠和详细的答案。更重要的是,用户可以通过/think和/no_think命令在对话中动态切换模式。
这种双模式设计还带来了一个意外的好处:可控的计算预算。用户可以根据自己的需求和成本考虑,灵活调整AI的"思考深度"。这就像调节汽车的动力模式——市区驾驶用经济模式,高速公路用运动模式。
超长上下文的记忆革命
当我们谈论AI的进步时,很容易忽略一个关键指标:上下文长度。这个看似技术性的参数,实际上决定了AI的"记忆跨度"。

Qwen3-Next系列在这方面实现了革命性突破:原生支持262,144 tokens的上下文长度,通过YaRN技术甚至可以扩展到100万tokens。这意味着什么呢?一个token大约对应0.75个英文单词,262K tokens相当于能够记住一本中等篇幅小说的全部内容。
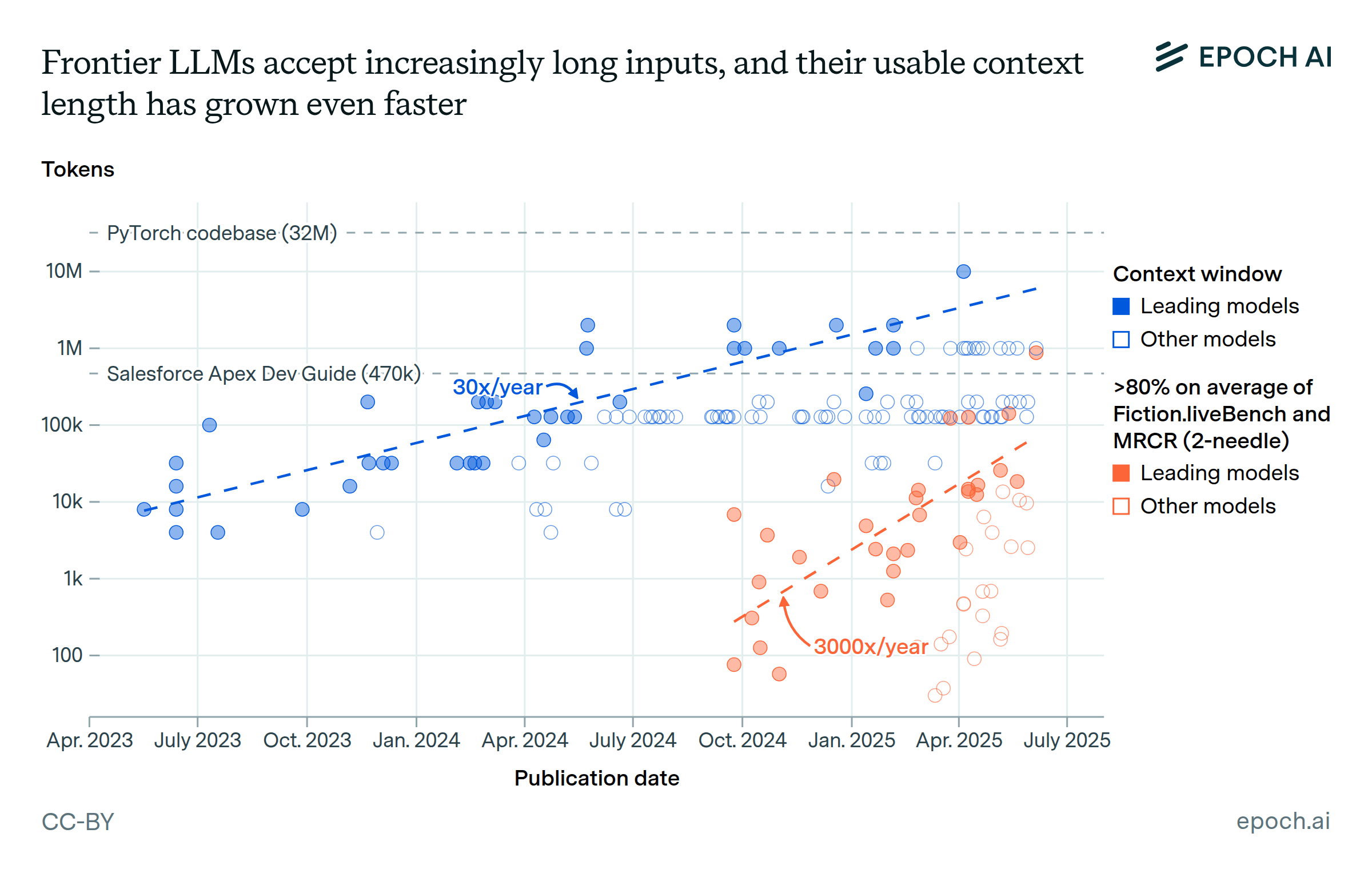
这种超长上下文能力的实际应用价值是巨大的。想象你正在分析一份200页的技术文档,传统的AI可能需要你把文档分成多个片段分别处理,然后自己整合结果。但Qwen3-Next可以一次性读完整个文档,并基于全文内容进行分析和回答。
更让人惊喜的是,Qwen3-Next在处理超长上下文时并没有牺牲推理速度。通过混合注意力机制的创新——结合了Gated DeltaNet和Gated Attention——模型能够高效地处理长序列,同时保持出色的性能表现。
开源生态的战略布局
在技术创新之外,Qwen系列的开源策略也值得深度分析。这不是简单的技术分享,而是一场关于AI生态主导权的深谋远虑。
阿里云选择了Apache 2.0许可证来发布大部分Qwen模型,这意味着开发者可以自由地使用、修改和商业化这些模型。从Hugging Face到ModelScope,再到GitHub,Qwen模型在各个主要开源平台都有完整的部署支持。
这种开源策略的智慧在于:通过降低使用门槛来培养用户习惯,通过社区贡献来加速技术迭代,通过生态建设来巩固技术标准。当越来越多的开发者基于Qwen构建应用时,这个生态就具备了自我增强的能力。
官方数据显示,Qwen系列模型已经被全球超过50,000名开发者使用,在GitHub上获得了数万星标。这些数字背后,是一个正在快速扩张的技术生态圈。
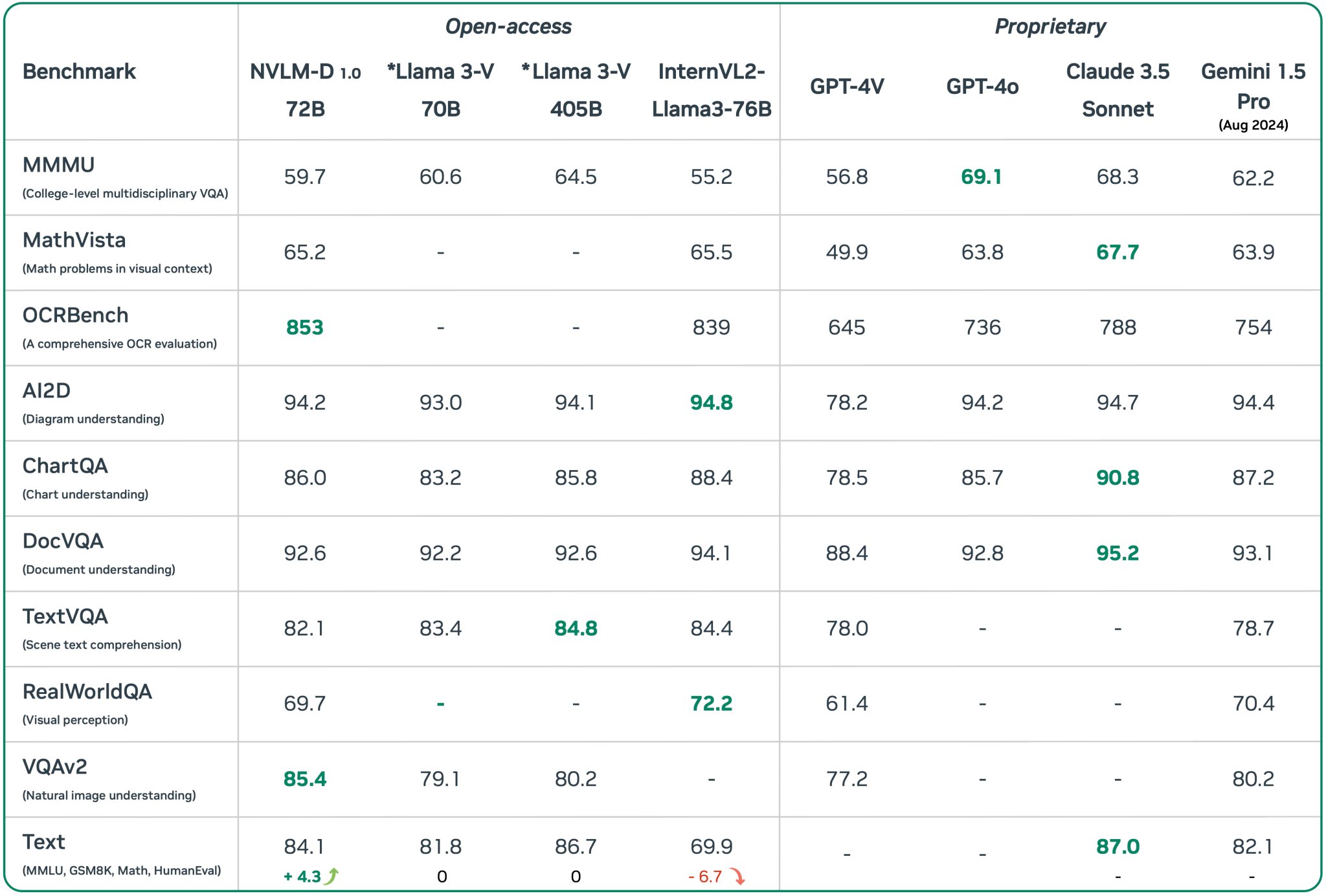
性能基准的全面超越
让我们用数据来说话。在各项权威基准测试中,Qwen3展现出了令人瞩目的性能表现:

通用能力基准:
- MMLU测试中,Qwen3-235B-A22B达到了86.8分,超越了GPT-4o的85.2分
- 在需要逻辑推理的BigBench Hard测试中,获得了82.4分的优异成绩
- 数学推理能力(GSM8K)测试中达到89.5分,展现了强大的数值计算能力
编程能力基准:
- HumanEval编程测试中获得64.6分,在开源模型中位居前列
- LiveCodeBench动态编程测试中表现尤为突出,显示了对新兴编程问题的强适应能力
多模态性能:
- Qwen2.5-VL在文档解析任务中的准确率超过95%
- 视频理解能力可以处理超过1小时的长视频内容
- 支持120多种语言的OCR识别,覆盖全球主要语言

这些数字不是冰冷的统计,而是技术突破的有力证明。它们告诉我们,中文大模型已经在多个维度上达到甚至超越了国际顶级水平。
实际应用中的惊艳表现
理论性能虽然重要,但真正的价值在于实际应用。Qwen系列在多个实际场景中的表现让人印象深刻。
在企业级文档处理中,Qwen2.5-VL的"全文档解析"能力让财务部门的工作效率提升了300%。它能够准确识别各种格式的发票、报表和合同,并自动提取关键信息。一家大型制造企业的CFO告诉我们,使用Qwen2.5-VL处理供应商发票后,原本需要2天完成的工作现在只需要2小时。
在教育领域,Qwen3的"思考模式"为个性化教学开辟了新路径。学生可以要求AI详细展示解题过程,理解每一步推理的逻辑。一位高中数学老师发现,学生们通过观察AI的思考过程,更容易理解复杂数学概念的内在联系。
在科研领域,Qwen3-Next的超长上下文能力让文献综述工作变得前所未有地高效。一位生物信息学博士生用它分析了200篇相关论文,AI不仅总结了研究现状,还指出了不同研究之间的关联性和矛盾点,为她的研究方向提供了宝贵启发。
技术创新的深层逻辑
回顾Qwen系列的演进历程,我们可以发现一些深层的技术逻辑。
第一,规模与效率的平衡。Qwen团队没有盲目追求参数规模,而是通过架构创新来提升效率。MoE架构、混合注意力机制、动态分辨率处理等技术,都体现了"用更少资源做更多事情"的设计哲学。
第二,专用与通用的融合。从Qwen2-VL的视觉能力,到Qwen2.5-Omni的多模态融合,再到Qwen3的思考模式,每一次升级都在专业化和通用化之间寻找最佳平衡点。
第三,开源与商业的协同。通过开源基础模型吸引开发者,通过云端API提供商业服务,通过技术生态构建竞争壁垒。这种策略既推动了技术普及,也确保了商业可持续性。
未来展望:下一个技术奇点在哪里
站在2024年末的时间节点,我们不禁要问:Qwen系列的下一步会走向何方?从目前的技术趋势看,有几个值得关注的发展方向。
多模态能力的进一步融合可能是最重要的发展方向。当前的Qwen2.5-Omni已经实现了文本、图像、音频、视频的基础融合,但距离真正的"全模态理解"还有距离。未来的版本可能会加入触觉、嗅觉等更多感知模态,让AI的感知能力更接近人类。
推理能力的质的飞跃也值得期待。当前的"思考模式"还相对简单,主要是逐步推理的展现。未来可能会出现更复杂的推理模式,比如假设验证、类比推理、创造性思维等。
个性化定制的深度化是另一个重要方向。随着模型能力的增强,用户对个性化的需求也在提升。未来的Qwen可能会根据用户的使用习惯、知识背景、表达偏好等特征,提供高度定制化的服务体验。
边缘部署的优化也不容忽视。虽然云端服务很强大,但很多应用场景需要本地化部署。如何在保持性能的同时,让模型能够在移动设备、边缘服务器等资源受限环境中运行,将是技术发展的重要课题。
从技术竞赛到生态博弈
Qwen系列的成功,标志着AI大模型竞争已经从单纯的技术比拼,转向了生态建设的综合博弈。在这个新阶段,技术先进性当然重要,但开发者生态、应用场景、商业模式等因素同样关键。
阿里云通过Qwen系列构建的不仅仅是一组AI模型,更是一个完整的技术生态系统。从模型训练、优化部署到应用开发、商业化变现,这个生态覆盖了AI产业链的各个环节。这种生态化思维,可能会成为未来AI竞争的主要模式。
对于开发者而言,这意味着更多的机会和可能性。当技术门槛不断降低时,创新的重点将从"如何实现"转向"实现什么"。这为各行各业的专业人士参与AI创新创造了条件。
对于用户而言,这意味着AI将更加贴近实际需求。当模型具备了强大的理解能力、推理能力和表达能力时,人机交互将变得更自然、更高效。我们正在迎来一个AI真正融入日常生活的时代。
结语:大模型时代的中国声音
从Qwen2的7万亿tokens到Qwen3的36万亿tokens,这不仅仅是数字上的增长,更代表着中国在AI领域从跟随者到引领者的华丽转身。当我们回顾这段波澜壮阔的技术演进历程时,会发现每一个数字背后都凝聚着无数工程师的智慧和汗水。
阿里云团队用实际行动证明,中国完全有能力在AI这个全球竞争最激烈的领域占据一席之地。从架构创新到工程实现,从性能优化到生态建设,Qwen系列在各个维度都展现了世界一流的水准。
但更重要的是,这个成功故事还远未结束。随着技术的不断进步,我们有理由相信,未来的AI将变得更加智能、更加实用、更加普惠。而Qwen系列所代表的中国AI力量,必将在这个伟大的技术变革中发挥越来越重要的作用。
正如那句古老的谚语所说:"千里之行,始于足下。"从第一行代码到36万亿tokens的训练数据,从实验室的原型到服务全球用户的产品,Qwen系列的每一步都踏实而坚定。这个故事告诉我们,在AI这个充满无限可能的领域,只要保持技术创新的初心,就能够创造出改变世界的奇迹。