想象一下,如果你遇到一个从未见过的外星人朋友,你只需要给他展示几个例子:"苹果是红色的,香蕉是黄色的,草莓是红色的",他就能立刻明白当你问"天空是什么颜色"时该如何回答。这听起来像是科幻电影里的情节,但在人工智能的世界里,这种"举一反三"的能力正在成为现实。这就是我们今天要探讨的主角——上下文学习(In-Context Learning, ICL)。
视频版:https://www.youtube.com/watch?v=mx1202ZPj8o

一个改变游戏规则的发现
让我们把时钟拨回到2020年。当OpenAI发布GPT-3的时候,研究人员们惊讶地发现了一个出乎意料的现象。这个拥有1750亿参数的巨型语言模型,竟然可以在没有经过专门训练的情况下,仅仅通过看几个例子就学会执行全新的任务。这就像是一个从未学过数学的学生,看了几道加法题的例子后,就能立刻解答其他加法问题一样神奇。
斯坦福大学的研究人员在一项深入研究中发现,这种能力的背后蕴藏着深刻的机制。与传统的机器学习需要大量标注数据和昂贵的训练过程不同,上下文学习让AI模型可以像人类一样,通过类比和模式识别来快速适应新任务。
软指令的魔法:模式匹配还是深层推理?
要理解上下文学习的奥秘,我们首先要认识一个关键概念——"软指令"(Soft Instructions)。想象一下,传统的程序指令就像是严格的军令,每一条都必须精确执行。而软指令更像是温柔的建议,通过展示而非强制来引导模型的行为。
麻省理工学院的Jacob Andreas教授在一次精彩的演讲中解释了这个过程:当我们给大语言模型展示"情感分析:’这部电影真棒’ → 积极"这样的例子时,模型内部发生的并不是简单的模式匹配。相反,它会激活在预训练过程中学到的关于情感、语言和推理的复杂知识网络。
研究表明,ICL的工作机制可能涉及多个层面:
贝叶斯推理视角:斯坦福的研究团队提出,上下文学习实际上是一种隐式的贝叶斯推理过程。模型通过观察示例来推断潜在的任务概念,然后基于这些概念进行预测。
梯度下降类比:更令人惊讶的发现是,微软的研究人员发现Transformer的注意力机制与梯度下降算法之间存在深刻的对偶关系。这意味着ICL可能是在隐式地执行一种元优化过程。
示例选择的艺术:不是所有例子都生而平等
如果说上下文学习是一门艺术,那么示例选择就是这门艺术中最精妙的部分。就像烹饪需要精心选择食材一样,ICL的效果在很大程度上取决于我们选择什么样的示例来"教导"模型。

无监督选择策略:寻找相似的灵魂
最直观的方法是选择与当前任务最相似的例子。刘鹏飞团队的KATE方法就采用了这种思路,通过计算句子嵌入之间的余弦相似度来选择最接近的示例。这种方法简单有效,在多个基准测试中都取得了不错的结果。
但是,仅仅依靠相似度还不够。加州大学伯克利分校的研究发现,示例的多样性同样重要。他们开发的互信息选择方法不仅考虑相似度,还确保选中的示例能够覆盖尽可能多的任务变化。
监督选择策略:让数据说话
当我们有标注数据可用时,监督学习方法往往能带来更好的效果。哥伦比亚大学的EPR方法采用了一个巧妙的两阶段策略:首先用传统检索方法召回候选示例,然后训练一个专门的神经网络来精确排序。
更有趣的是强化学习的应用。清华大学的研究团队将示例选择建模为一个马尔可夫决策过程,通过Q学习来优化选择策略。他们的实验结果显示,这种方法在复杂推理任务上的表现尤为突出。
格式与顺序:细节决定成败
你可能以为示例的内容最重要,但研究表明,示例的格式和顺序同样至关重要。普林斯顿大学的研究揭示了一个令人意外的发现:即使使用相同的示例,仅仅改变它们的顺序就能让模型性能产生20%以上的差异。
这种现象被称为"近因效应"(Recency Bias)——模型更容易被最后看到的示例所影响。为了解决这个问题,研究人员提出了多种排序策略,比如从简单到复杂的递增排序,或者基于全局和局部熵的优化排序。
ICL与微调的巅峰对决
现在让我们来看一场备受关注的较量:上下文学习与传统的模型微调,谁更胜一筹?
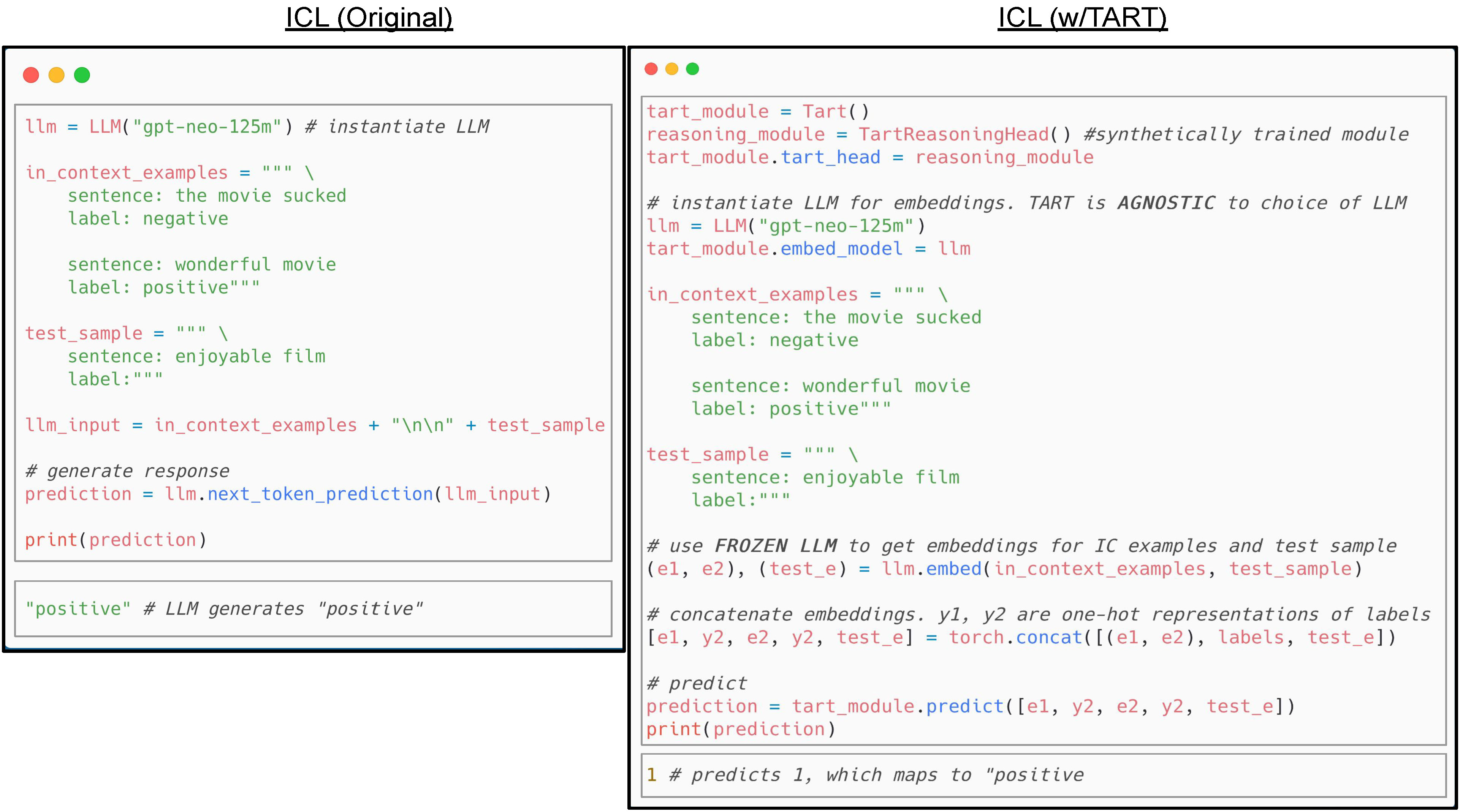
各有千秋的较量
斯坦福大学Hazy Research团队的研究发现了一个有趣的现象:虽然ICL在灵活性上无与伦比,但在性能上通常还是略逊于专门的微调模型。他们的实验显示,在相同的示例数量下,微调模型的准确率平均比ICL高出15.8%。
但这个差距并非不可逾越。研究人员发现,这主要是因为大语言模型缺乏抽象的推理能力。为了验证这个假设,他们提出了TART(Task-Agnostic Reasoning Transformer)方法,通过在合成的逻辑回归任务上训练模型来增强其推理能力。
效率的权衡
从效率角度来看,ICL有着明显的优势。OpenAI的研究表明,使用ICL可以在几秒钟内适应新任务,而微调即使是最小的模型也需要几小时到几天的时间。
但ICL也有自己的瓶颈。随着示例数量的增加,推理成本会线性上升,而且受限于模型的上下文长度。谷歌的研究显示,当示例超过64个时,大多数模型的性能不仅不会提升,反而可能下降。
泛化能力的较量
在泛化能力上,ICL展现出了独特的优势。MIT的研究发现,对于隐含模式的任务,ICL的泛化能力显著优于微调。这是因为ICL迫使模型在推理时动态地识别和应用模式,而不是简单地记忆训练数据中的特定关联。
实践应用:从实验室到现实世界
理论研究固然重要,但上下文学习真正的价值体现在它的实际应用中。让我们看看这项技术是如何在现实世界中发挥作用的。
情感分析:理解人类的情绪密码
在社交媒体监控和客户反馈分析中,ICL展现出了惊人的适应性。传统方法需要为每个新领域收集大量标注数据,但ICL只需要几个领域相关的例子就能快速上手。
微软的研究团队在一项大规模实验中发现,使用ICL的情感分析系统可以在15分钟内适应新的产品领域,而传统方法需要数周的数据收集和模型训练时间。更重要的是,ICL在处理讽刺、隐喻等复杂情感表达时表现出了更强的鲁棒性。
机器翻译:跨越语言的桥梁
在机器翻译领域,ICL为低资源语言带来了新的希望。谷歌的PaLM模型展示了令人印象深刻的能力:仅通过几个翻译例子,就能在从未见过的语言对之间进行准确翻译。
特别值得一提的是,ICL在保持翻译风格一致性方面表现出色。无论是学术论文的严谨语调,还是社交媒体的轻松风格,模型都能通过示例快速掌握并保持一致。
代码生成:程序员的AI助手
在软件开发领域,ICL正在重新定义人机协作的方式。OpenAI的Codex和GitHub的Copilot都大量使用了ICL技术,通过分析代码上下文和注释来生成相应的代码片段。
一项针对1000名程序员的调查显示,使用ICL辅助的开发者在编码效率上平均提升了55.8%,同时代码质量也有显著改善。这主要得益于ICL能够理解和保持代码风格的一致性。
神经科学启示:大脑的上下文学习
有趣的是,上下文学习不仅是AI的专利,它在人类大脑中也有对应的机制。约翰霍普金斯大学的神经科学研究发现,人类的前额叶皮层在处理上下文信息时会激活相似的神经网络模式。
这种相似性不是偶然的。研究表明,Transformer模型中的注意力机制在某种程度上模拟了大脑中的工作记忆系统。当我们看到"红苹果、黄香蕉、绿葡萄"这样的例子时,大脑会自动提取"颜色-物体"的关联规律,这与ICL中的模式识别过程惊人地相似。
前沿研究:推动边界的探索者
Many-Shot ICL:更多就是更好吗?
谷歌DeepMind的最新研究探索了一个有趣的问题:如果我们给模型提供数百甚至数千个示例,会发生什么?他们发现,在某些复杂推理任务中,使用数千个示例确实能带来显著的性能提升,但这种提升并不是线性的。
关键在于示例的质量和多样性。研究显示,100个精心选择的高质量示例往往比1000个随机示例更有效。这提醒我们,在ICL中,智慧比蛮力更重要。
跨模态ICL:突破文本的边界
最前沿的研究正在将ICL扩展到文本以外的领域。Meta的研究团队开发的多模态ICL系统可以同时处理文本、图像和音频信息,实现真正的跨模态理解。
想象一下,你给AI展示几张"快乐的脸庞+积极的文字"的例子,然后它就能学会从一张新照片中识别出人物的情绪状态。这种能力正在医疗诊断、自动驾驶和内容审核等领域展现出巨大的潜力。
自适应ICL:让AI学会学习
加州大学伯克利分校的最新研究提出了自适应ICL的概念:让模型自主决定需要什么样的示例,以及如何组织这些示例。这种方法使用信息压缩的原理来优化示例选择和排序,在多个基准测试中都取得了最先进的结果。
挑战与局限:技术成熟路上的绊脚石
尽管ICL展现出了巨大的潜力,但它仍面临着一些重要的挑战。
上下文长度的诅咒
目前大多数语言模型的上下文长度限制在2K到100K tokens之间,这严重限制了ICL可以使用的示例数量。虽然Anthropic的Claude-3和Google的Gemini等模型正在推向更长的上下文,但计算成本的增长仍然是一个重大挑战。
推理成本的负担
与微调模型的固定推理成本不同,ICL的成本随示例数量线性增长。OpenAI的成本分析显示,使用64个示例的ICL任务的推理成本可能是零样本任务的20-30倍。这在大规模部署中是一个不容忽视的问题。
偏见和公平性
ICL容易受到示例选择偏见的影响。斯坦福大学的公平性研究发现,如果示例中存在性别、种族或其他方面的偏见,模型很容易放大这些偏见。这要求我们在示例选择时必须格外小心。
未来展望:ICL的无限可能
展望未来,上下文学习有望在多个方向实现突破。
效率优化:做更多,用更少
研究人员正在开发各种技术来降低ICL的计算成本。微软的研究提出了示例蒸馏技术,可以将多个冗长的示例压缩成简洁的向量表示,在保持性能的同时大幅降低推理成本。
个性化学习:千人千面的AI
未来的ICL系统可能能够为每个用户学习个性化的示例选择策略。通过分析用户的历史交互和偏好,系统可以自动选择最适合该用户的示例和格式,实现真正的个性化AI体验。
持续学习:永不停歇的进化
DeepMind的研究团队正在探索让ICL系统持续从新经验中学习的方法。这种系统可以在保持原有知识的同时,不断吸收新的信息和技能,就像人类一样终身学习。
结语:智能的新纪元
上下文学习代表了人工智能发展的一个重要里程碑。它不仅仅是一项技术创新,更是我们对智能本质理解的深化。通过模仿人类的类比推理能力,ICL为AI系统带来了前所未有的灵活性和适应性。
正如Yann LeCun在最近的演讲中所说:"上下文学习可能是通向真正智能系统的关键步骤之一。它让我们看到了AI如何能够像人类一样,通过经验和类比来理解世界。"
虽然ICL还面临着诸多挑战,但它已经在改变我们与AI交互的方式。从简单的文本分类到复杂的推理任务,从单一模态到多模态理解,ICL正在推动AI系统向更加智能、更加人性化的方向发展。
在这个AI技术日新月异的时代,上下文学习提醒我们,有时候最强大的进步不是来自更复杂的算法或更大的模型,而是来自对学习本质的深刻理解。当AI学会了"举一反三",我们离真正的机器智能又近了一步。