
RAG (检索增强生成) 技术架构图 – AWS官方示意
想象一下这样的场景:你正坐在办公室里,面对着成千上万页的技术文档、研究报告和知识库,而你只是想找到一个简单问题的答案。传统的搜索方式让你在文档的海洋中迷失方向,关键词匹配总是给出不相关的结果,而你真正需要的答案却深埋在某个段落的深处。
视频版:https://www.youtube.com/watch?v=GQmt6UcevzI
这种痛苦的体验,直到RAG(检索增强生成)技术的出现才得以改变。这项技术就像是给大语言模型装上了一副"智能眼镜",让它不仅能够理解你的问题,还能准确地从海量文档中找到最相关的信息,然后生成准确、有依据的回答。
为什么需要RAG:LLM的"知识困境"
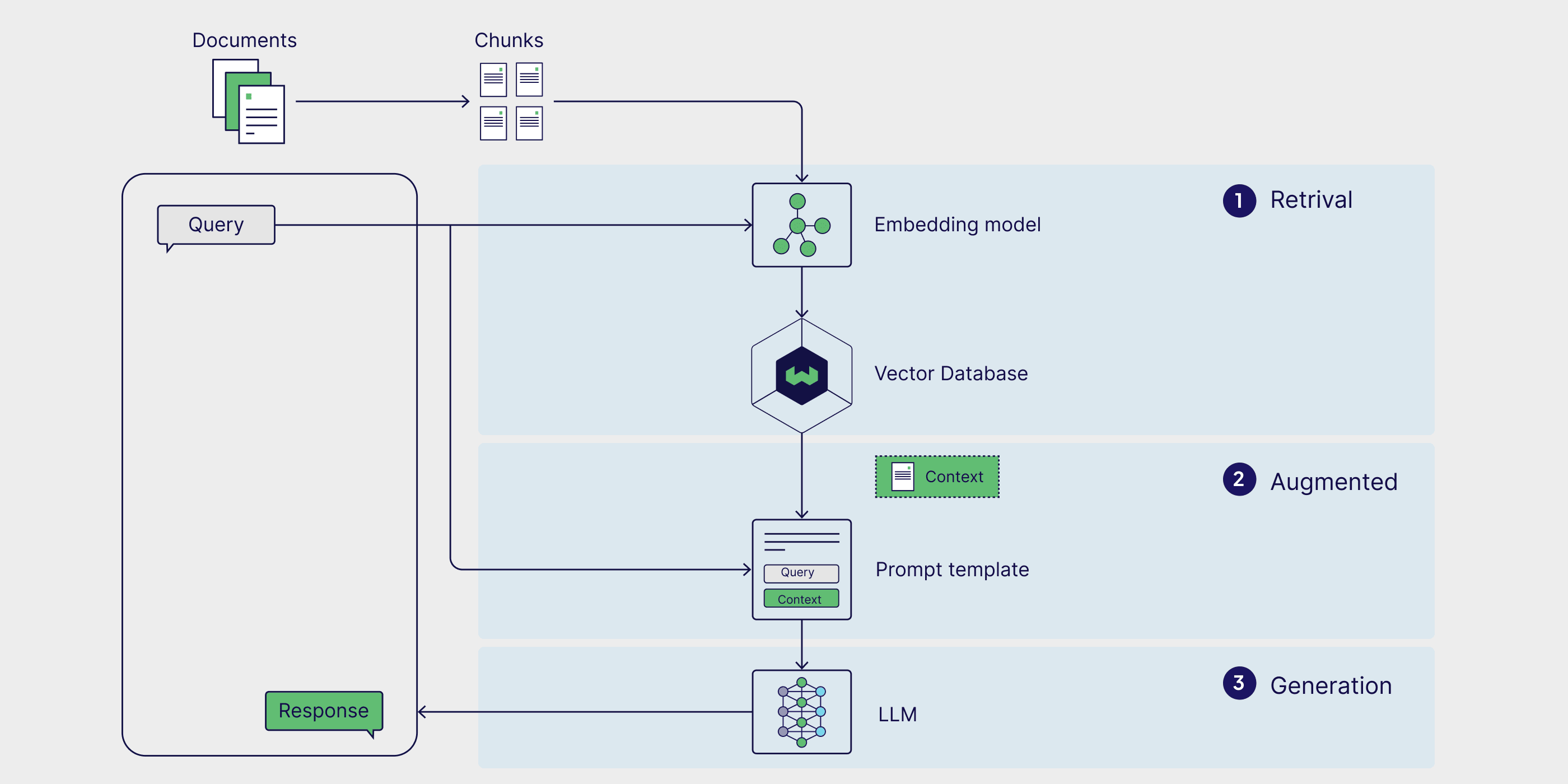
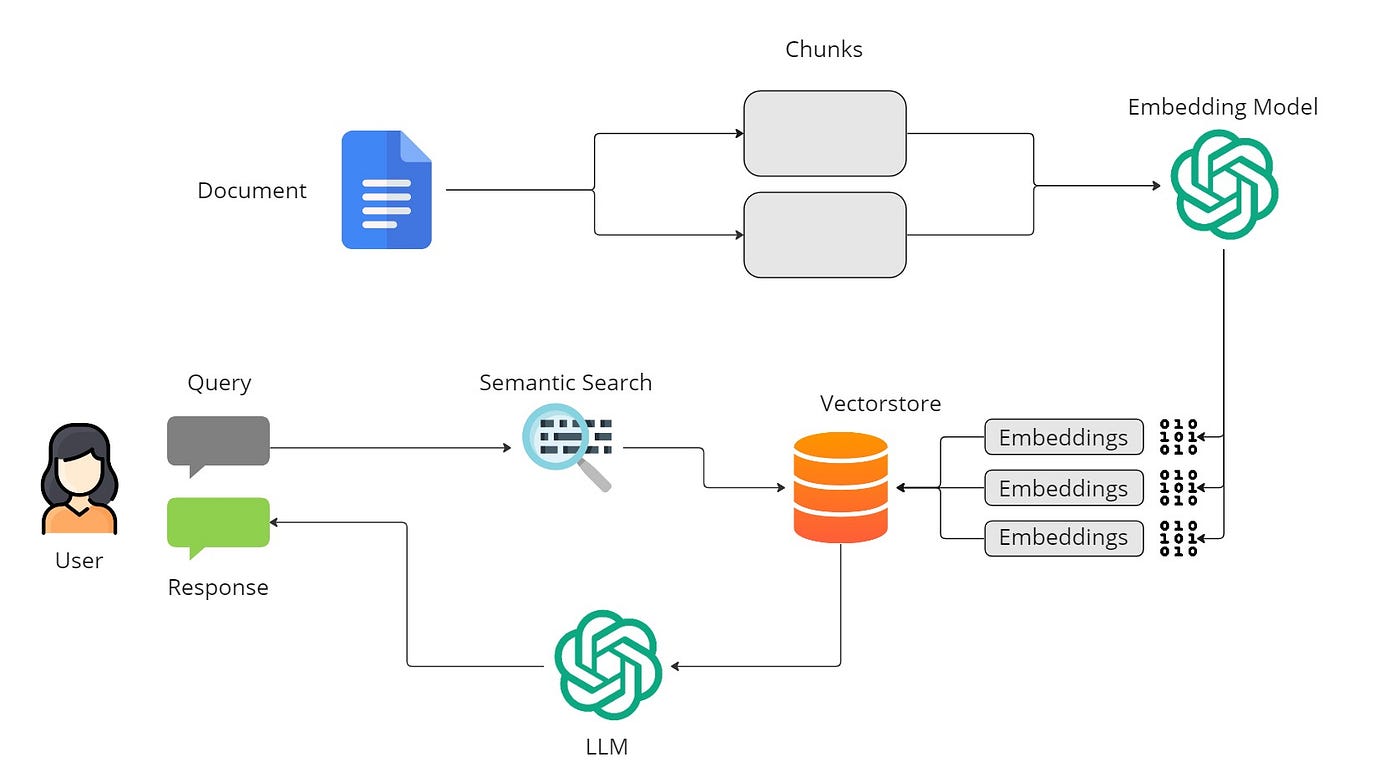
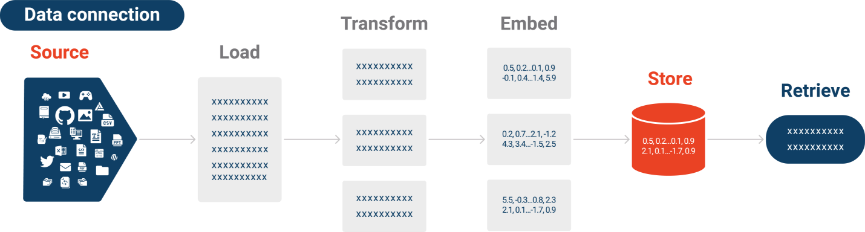
完整的RAG工作流程:从文档到答案的全过程 – Weaviate
大语言模型的训练方式决定了它们只能掌握训练时的知识,面对实时更新的信息或者私有数据时就显得力不从心。更严重的是,当LLM不知道答案时,它们往往会"自信地胡说",这种现象被称为幻觉问题。
RAG技术的核心思想很简单却很巧妙:既然LLM的内在知识有限,那就给它一个能够实时查阅资料的能力。就像一个学识渊博的图书管理员,它不仅知道如何理解你的问题,还知道去哪里找到最准确的答案。
这种组合产生了1+1>2的效果。根据最新的研究数据,RAG系统的准确率可以达到92%以上,相比纯LLM系统提升了接近30%。
文档分块:RAG的第一道门槛

11种主要的文档分块策略可视化对比 – Medium技术博客
在RAG系统中,文档分块(Chunking)是最关键却也是最容易被忽视的环节。这个过程决定了后续所有步骤的质量上限。
分块的艺术与科学
想象你正在整理一本厚厚的科学教科书。如果你把整本书当作一个整体来理解,重要的细节会被淹没在大量信息中;如果你把每个句子都单独拿出来,又会失去上下文的连贯性。正如Weaviate的研究指出,最佳的分块策略需要在检索精度和语义完整性之间找到平衡点。

Chroma研究团队对不同分块方法的评估结果
现实中的挑战往往比理论更复杂。一份企业的技术文档可能同时包含概述性的介绍、详细的API说明、代码示例和故障排除指南。每种内容类型都有其特定的结构和信息密度,需要不同的分块策略。
三种主流分块策略的实战对比
不同分块策略的性能特征对比图
固定大小分块就像用标准尺子切面包,简单粗暴但有效。每个chunk保持相同的token数量,通常是512或1024个token。这种方法的最大优势是可预测性强,特别适合快速原型开发。但它的问题也很明显:可能在句子中间切断,破坏语义完整性。
递归分块更像是一个有经验的编辑在分段落。它首先尝试在自然的分界点(如段落、句子)进行切分,如果块太大再进一步细分。LangChain的RecursiveCharacterTextSplitter正是基于这个思想设计的,它能够保持文档的原始结构,同时确保每个chunk不超过指定大小。
语义分块是最智能的方法,它使用嵌入模型来识别语义边界。当文本的主题发生转换时,系统会自动创建新的chunk。这种方法虽然计算成本更高,但能够产生语义上最完整的chunks。
数据显示,在技术文档的问答任务中,语义分块的准确率比固定大小分块高出15-20%,但处理时间增加了约3倍。
向量嵌入:让机器理解文本的"DNA"
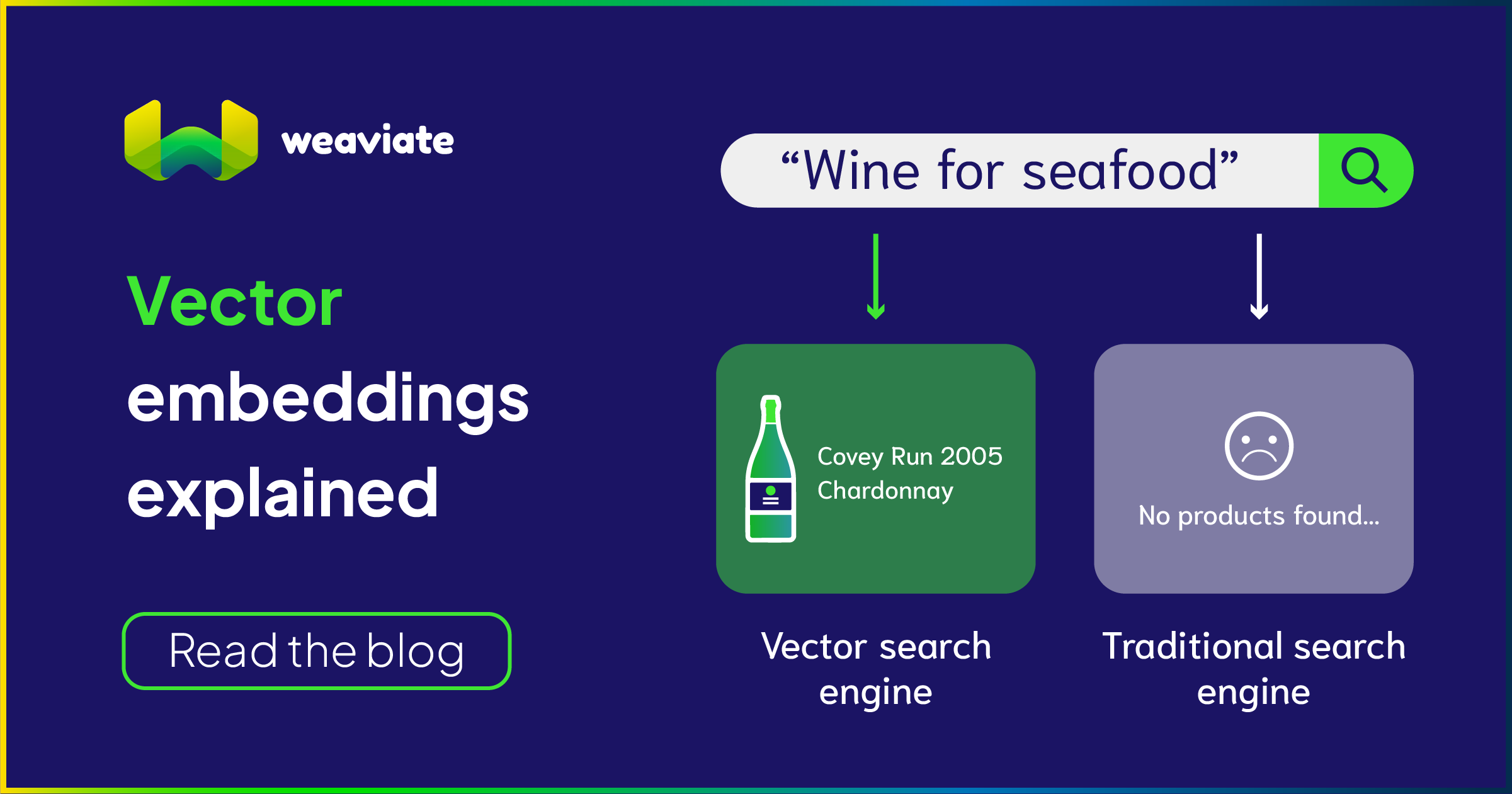
向量嵌入将文本转换为高维空间中的点,相似内容聚集在一起 – Weaviate
如果说分块是将信息合理组织,那么向量嵌入就是为每个信息片段生成独特的"DNA指纹"。这个过程将人类语言转换成机器能够精确理解和比较的数字形式。
嵌入的魔法原理
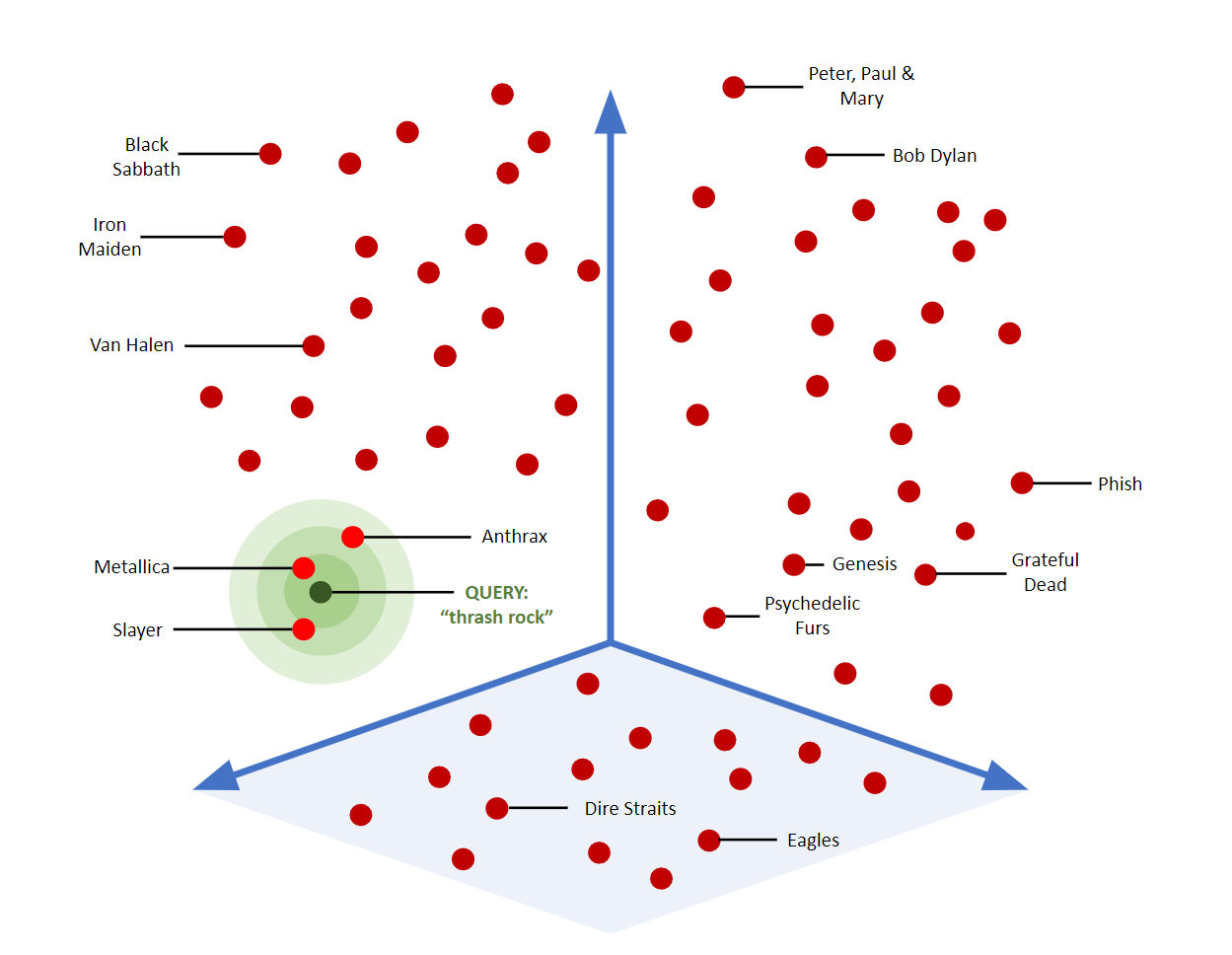
向量相似度搜索的工作原理:在高维空间中寻找最近邻 – Couchbase
现代的嵌入模型,如OpenAI的text-embedding-ada-002,能够将文本转换成1536维的向量空间。在这个高维空间中,语义相近的文本会聚集在一起,而语义差异大的文本则相距甚远。
这种转换的精妙之处在于它能够捕捉到人类语言中的细微差别。比如"汽车发动机故障"和"车辆引擎问题"在传统的关键词匹配中可能被认为是完全不同的查询,但在向量空间中它们却非常接近。
中文嵌入的特殊挑战
中文文本的嵌入面临着独特的挑战。中文的语法结构、词汇构造方式都与英文有显著差异。更重要的是,中文的语境依赖性更强,同一个词在不同上下文中的含义可能完全不同。
BGE(BAAI General Embedding)模型专门针对中文优化,在中文语义理解任务中的表现显著优于通用的多语言模型。实际测试表明,使用专门的中文嵌入模型可以将中文文档的检索准确率提升25%以上。
向量数据库:高维搜索的竞技场

主流向量数据库的全面对比分析图表 – Medium技术分析
选择合适的向量数据库就像选择一辆赛车,不同的数据库在不同的赛道上表现各异。
四大主流方案的深度解析
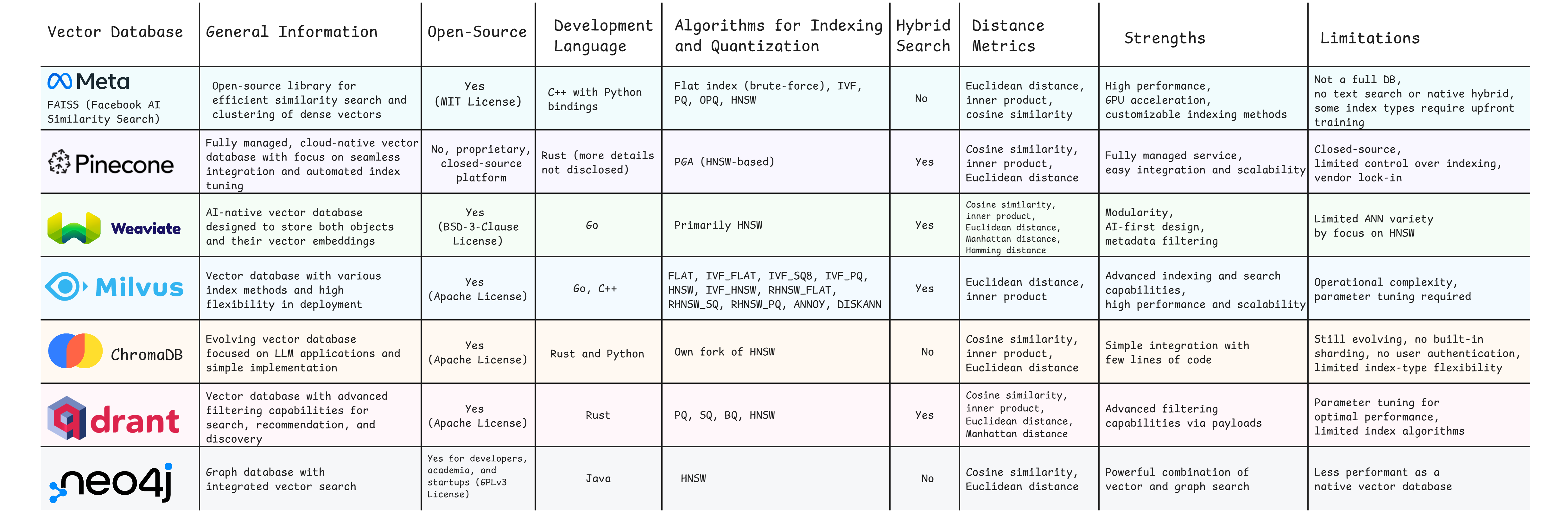
各大向量数据库的详细特性对比表
**FAISS(Facebook AI Similarity Search)**是这个领域的性能之王。作为Meta开源的解决方案,FAISS在大规模数据集上的表现让人印象深刻,单机能够处理10亿级别的向量,查询延迟保持在毫秒级别。但它的学习曲线陡峭,需要深入了解各种索引算法才能发挥最佳性能。
ChromaDB则走的是简约路线。其"开箱即用"的设计理念让开发者能够在几行代码内搭建起一个可用的向量检索系统。虽然在大规模场景下性能有限,但对于中小型应用和快速原型开发来说,ChromaDB是最佳选择。
Pinecone代表了托管服务的最高水准。它解决了向量数据库部署和运维的所有复杂性,提供自动扩缩容、数据备份、监控告警等企业级功能。代价是相对较高的成本和对云服务的依赖。
Weaviate则试图在功能丰富性和易用性之间找到平衡。它不仅支持向量搜索,还提供了图数据库的功能,能够处理复杂的关系查询。在需要多模态搜索(文本、图片、音频)的场景下,Weaviate表现出色。
性能基准测试的真实数据

向量数据库功能特性对比表 – DataAspirant
在一个包含100万文档的真实数据集上,不同数据库的表现差异显著:
- 查询延迟:FAISS平均5ms,Pinecone平均15ms,Weaviate平均25ms,ChromaDB平均50ms
- 吞吐量:FAISS每秒可处理10000+查询,Pinecone约5000,Weaviate约3000,ChromaDB约1000
- 内存使用:FAISS最优化,Weaviate居中,ChromaDB和Pinecone相对较高
但这些数字只是一方面。在实际应用中,开发效率、运维成本、功能完整性往往比纯性能数字更重要。
实现框架:LangChain vs LlamaIndex的哲学差异
LangChain与LlamaIndex在RAG实现中的架构对比
选择开发框架就像选择编程语言,不同的框架体现了不同的设计哲学。
LangChain:模块化的乐高积木
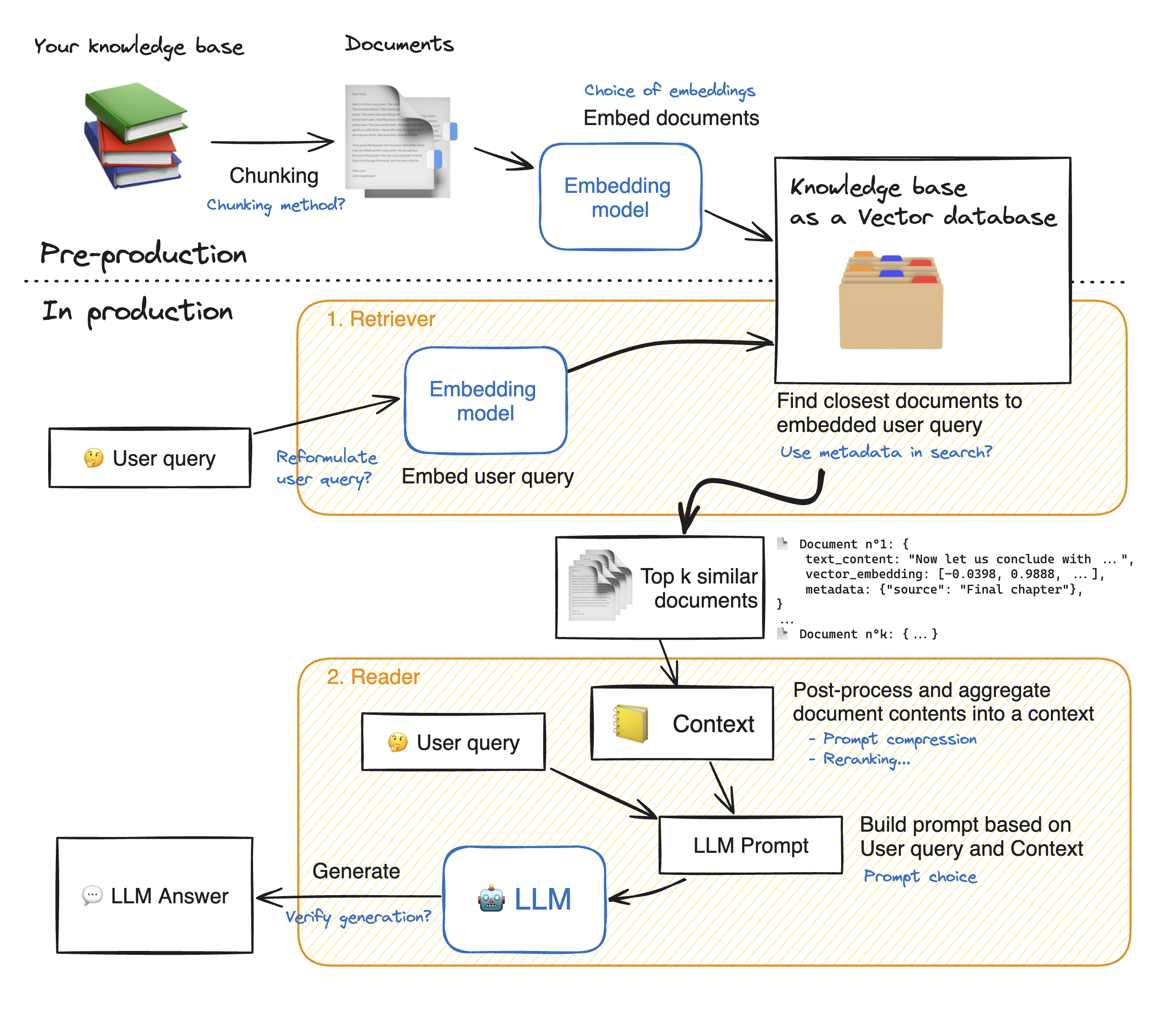
LangChain实现的完整RAG工作流程图 – Hugging Face
LangChain的设计理念是将复杂的LLM应用拆解成可组合的模块。它提供了丰富的"积木"——从文档加载器到文本分割器,从嵌入模型到向量存储,每个组件都可以独立使用或任意组合。
这种模块化设计的优势是极高的灵活性。你可以轻松地尝试不同的分块策略,切换不同的嵌入模型,或者集成多个向量数据库。但这种灵活性也带来了复杂性,特别是在处理组件间的兼容性和错误调试时。
LlamaIndex:专注RAG的精密工具
LlamaIndex的高级RAG实现架构图
相比之下,LlamaIndex更像是一把专门为RAG任务锻造的瑞士军刀。它内置了大量针对RAG优化的功能,从智能的文档解析到高效的索引结构,从多样的查询模式到自动的性能优化。
LangChain与LlamaIndex功能特性详细对比
LlamaIndex的强项在于它的"开箱即用"能力。一个简单的VectorStoreIndex就能够处理从文档加载到答案生成的整个流程,同时还提供了丰富的配置选项来满足高级需求。
实际项目中的选择策略
在一个真实的企业项目中,技术选型往往需要考虑多个维度。如果你的团队有丰富的LLM应用开发经验,并且需要深度定制各个环节,LangChain可能是更好的选择。它的模块化设计让你能够精确控制每个步骤,实现最优的性能调优。
但如果你的目标是快速构建一个可靠的RAG系统,并且团队的重点是业务逻辑而非底层技术细节,LlamaIndex会是更明智的选择。它的高级抽象和内置优化能够让你专注于解决实际问题,而不是纠结于技术实现。
性能优化:从理论到实践的距离
构建RAG系统时,理论上的最优配置往往与实际应用中的最佳方案有显著差异。
真实场景中的挑战
在处理企业内部文档时,你会发现现实比教科书复杂得多。文档可能包含扫描的PDF(OCR错误)、复杂的表格(结构信息丢失)、多语言混合内容(嵌入模型困惑)、以及大量的专业术语(训练数据不足)。
每种挑战都需要特定的解决方案。对于扫描PDF,需要在OCR之后进行文本清理和错误纠正;对于表格数据,可能需要将结构信息转换为自然语言描述;对于专业术语,则需要构建领域特定的词汇表或微调嵌入模型。
迭代优化的实战方法
成功的RAG系统往往是通过不断迭代优化得来的。一个典型的优化流程包括:
首先建立基线系统,使用最简单的配置(固定大小分块、通用嵌入模型、单一向量数据库)来验证整体架构的可行性。然后收集真实的用户查询和反馈,建立评估数据集。
接下来是系统性的实验。改变chunk大小(从256到2048 tokens)、尝试不同的分块策略、测试多种嵌入模型、调整检索参数。每次变更都要在标准数据集上评估效果,记录准确率、召回率、延迟等关键指标。
最关键的是引入人工评估。自动化指标虽然重要,但无法完全反映用户体验。定期邀请领域专家评估系统回答的质量,特别关注事实准确性、逻辑完整性和表达清晰度。
成本与效果的平衡艺术
在企业环境中,技术方案的成功不仅取决于技术指标,还要考虑成本效益。
隐藏的成本因子
RAG系统的成本构成比想象中复杂。除了显而易见的计算资源(嵌入模型推理、向量数据库存储、LLM调用),还有大量隐性成本:数据预处理的人工投入、系统调优的时间成本、持续运维的人力投入。
以一个处理10万文档的企业知识库为例,仅嵌入生成就可能需要数千美元的API调用费用。如果使用Pinecone这样的托管服务,月度存储和查询费用可能达到数百美元。而如果选择自建FAISS方案,虽然运行成本较低,但开发和运维投入可能是托管服务费用的数倍。
渐进式的成本优化策略
明智的做法是采用渐进式的成本优化策略。初期使用托管服务快速验证概念,一旦系统稳定且规模扩大,再考虑向自建方案迁移。
在技术实现上,可以通过多种方式降低成本:使用更小但性能相当的嵌入模型、实现智能的缓存策略减少重复计算、采用混合存储架构(热数据用高性能存储,冷数据用低成本存储)、以及优化chunk策略减少无效的向量存储。
未来展望:RAG技术的演进方向
RAG技术正在快速演进,未来的发展趋势值得关注。
多模态RAG的兴起
下一代RAG系统将不再局限于文本,而是能够处理图片、音频、视频等多种模态的信息。想象一个技术支持系统,它不仅能回答文字问题,还能分析产品图片、理解演示视频,提供更直观和准确的帮助。
自适应优化的智能化
未来的RAG系统将具备自我学习和优化的能力。它们能够根据用户反馈自动调整检索策略、优化chunk边界、甚至微调嵌入模型,实现真正的"智能化运维"。
实时知识更新
传统RAG系统的知识更新需要重新处理整个文档库。未来的系统将支持增量更新,能够实时融入新的信息,保持知识的时效性。
RAG技术的这次革命,不仅仅是技术的进步,更是对信息获取方式的重新定义。它让机器具备了类似人类专家的能力:不仅知道答案,还知道答案的来源和依据。在这个信息爆炸的时代,RAG为我们提供了一种全新的方式来驾驭知识的海洋。
技术的价值最终体现在解决实际问题的能力上。RAG技术的真正意义不在于其复杂的算法实现,而在于它能让每个人都拥有一个智能的知识助手,让信息的价值得到最大化的释放。这种技术与人文的结合,正是AI时代最动人的篇章。