引子:一个改变世界的翻译实验
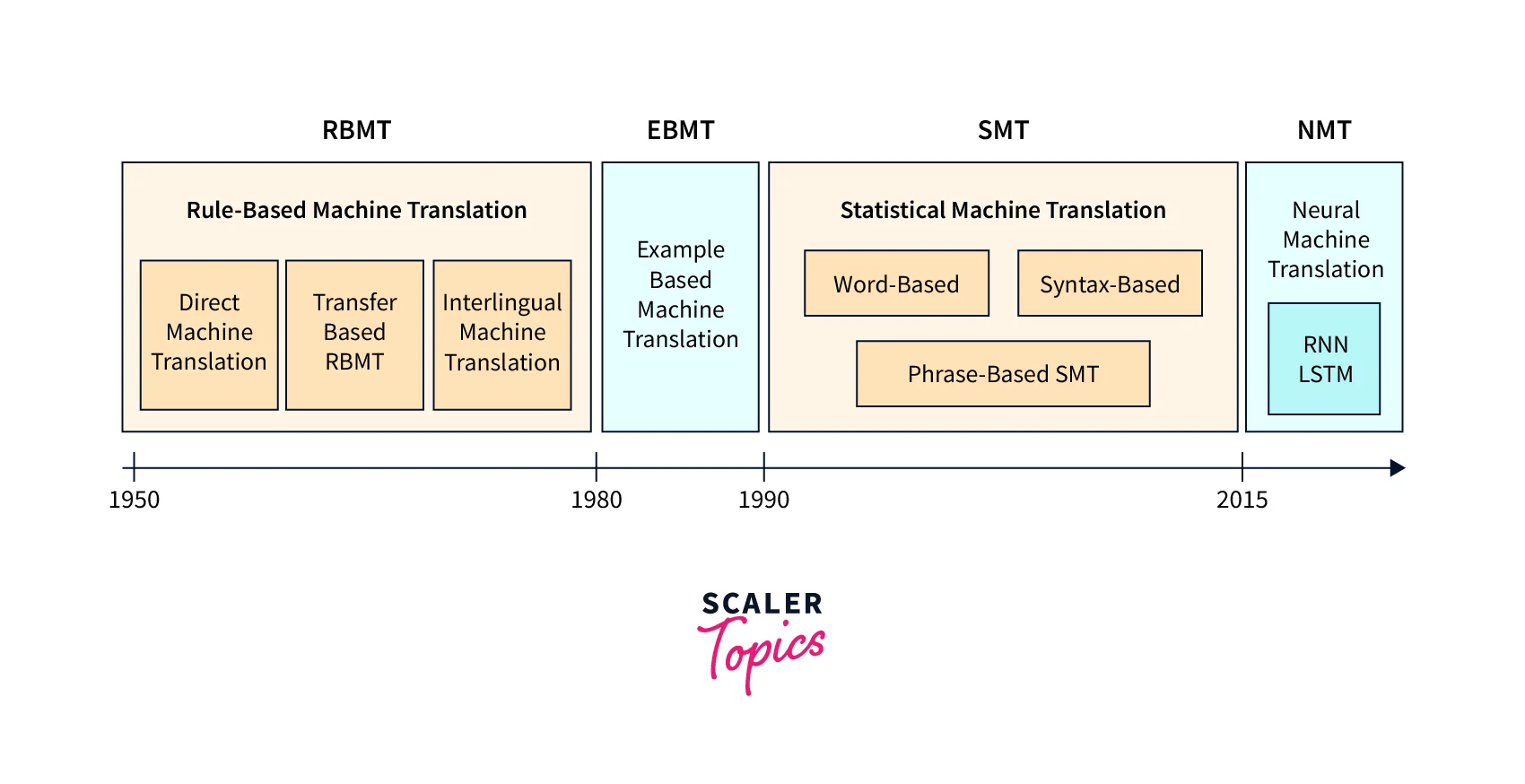
图1:机器翻译技术的发展历程概览
2024年的一个普通午后,WMT24机器翻译大会上发布了一组令人震惊的数据:在242个翻译系统的激烈竞争中,传统的神经机器翻译系统几乎全军覆没,而大语言模型Claude 3.5 Sonnet一举拿下9个语言对的冠军。这不仅仅是一次技术更新,而是机器翻译领域的一次彻底革命。
视频版:https://youtu.be/VGMGcISF5Do
想象一下,如果巴别塔的建造者们拥有了现代的大语言模型,也许人类的语言障碍早就不复存在了。今天,我们正站在这样一个历史转折点上——LLM正在以前所未有的方式重新定义机器翻译。
数字背后的故事:LLM翻译能力的惊人跃进
图2:从SMT到NMT再到LLM的技术演进历程

让我们从一些令人瞠目结舌的数字开始。Lokalise的最新研究显示,Claude 3.5 Sonnet在无任何上下文信息的情况下,仍能在78%的时间里产出"优质"翻译。这个数字意味着什么?传统的Google Translate在同样的评估中BLEU分数仅为70.1,而DeepL虽然能达到80.3,但这已经是经过多年优化的商业产品。
图3:主流翻译系统性能对比图

更令人震撼的是,根据2025年翻译自动化状态报告,LLM现在占据了顶级翻译系统中89%的份额,相比2024年的55%几乎翻了一番。这种增长速度在技术史上极为罕见,就像智能手机在短短几年内彻底改变人们的生活方式一样。
传统翻译方法的"三国演义"

图4:神经机器翻译与生成式AI模型的技术架构对比
要理解LLM翻译革命的意义,我们需要回顾一下机器翻译的发展历程。这就像一部精彩的"三国演义",三种主要方法各领风骚:
统计机器翻译(SMT)时代:这是机器翻译的"蜀汉时期",依靠大量的并行语料库和统计模型。SMT就像诸葛亮一样,通过精密的计算和规则来"运筹帷幄",但面对复杂的语言现象时往往显得力不从心。研究显示,SMT主要通过基于短语的元素拼接来工作,这种方法在处理长距离依赖关系时经常出现断裂。
神经机器翻译(NMT)时代:如果说SMT是诸葛亮,那么NMT就是关羽——勇猛而专一。NMT引入了注意力机制,能够捕捉整个句子的语义关系。相关研究表明,NMT在27个自然语言处理任务中的表现都明显优于SMT,这标志着机器翻译从"拼接时代"进入了"理解时代"。
大语言模型(LLM)时代:而现在的LLM,就像是集三家之长的司马懿,不仅具备了前两者的优点,还拥有了全新的能力。最新研究指出,LLM更善于理解上下文和更广泛的信息语义,这使得它们在翻译时不再局限于词对词的对应,而是真正理解了文本的含义。
评估指标的"进化论":从BLEU到COMET的华丽转身
图5:BLEU与COMET评估指标的工作原理对比

说到翻译质量评估,我们不得不提到一场正在发生的"指标革命"。传统的BLEU指标就像是用尺子测量一幅画的好坏——虽然客观,但往往错过了最重要的东西。
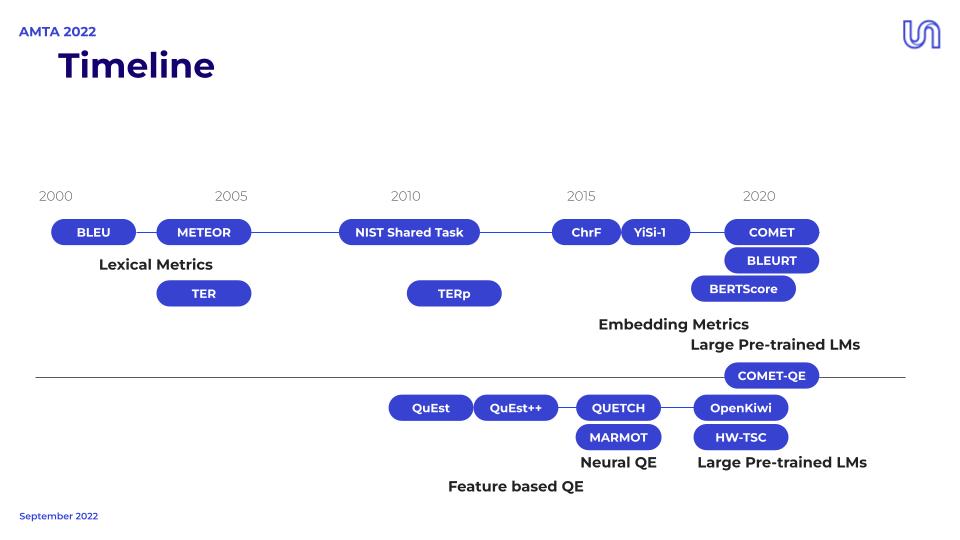
图6:机器翻译评估指标的发展时间线
BLEU(双语评估替补)指标自2002年诞生以来,一直是机器翻译评估的"黄金标准"。它通过比较机器翻译与人工参考译文的n-gram重叠度来评分。根据Google的评估标准,BLEU分数在40-50之间代表高质量翻译,30-40为可理解译文,20-30虽然语法错误较多但大意清楚。
然而,BLEU指标有一个致命缺陷:它只关注表面的词汇匹配,而忽视了语义的一致性。想象一下,如果有人把"我爱你"翻译成"I adore you"而不是"I love you",BLEU可能会给出较低的分数,尽管前者在某些语境下可能更加准确。
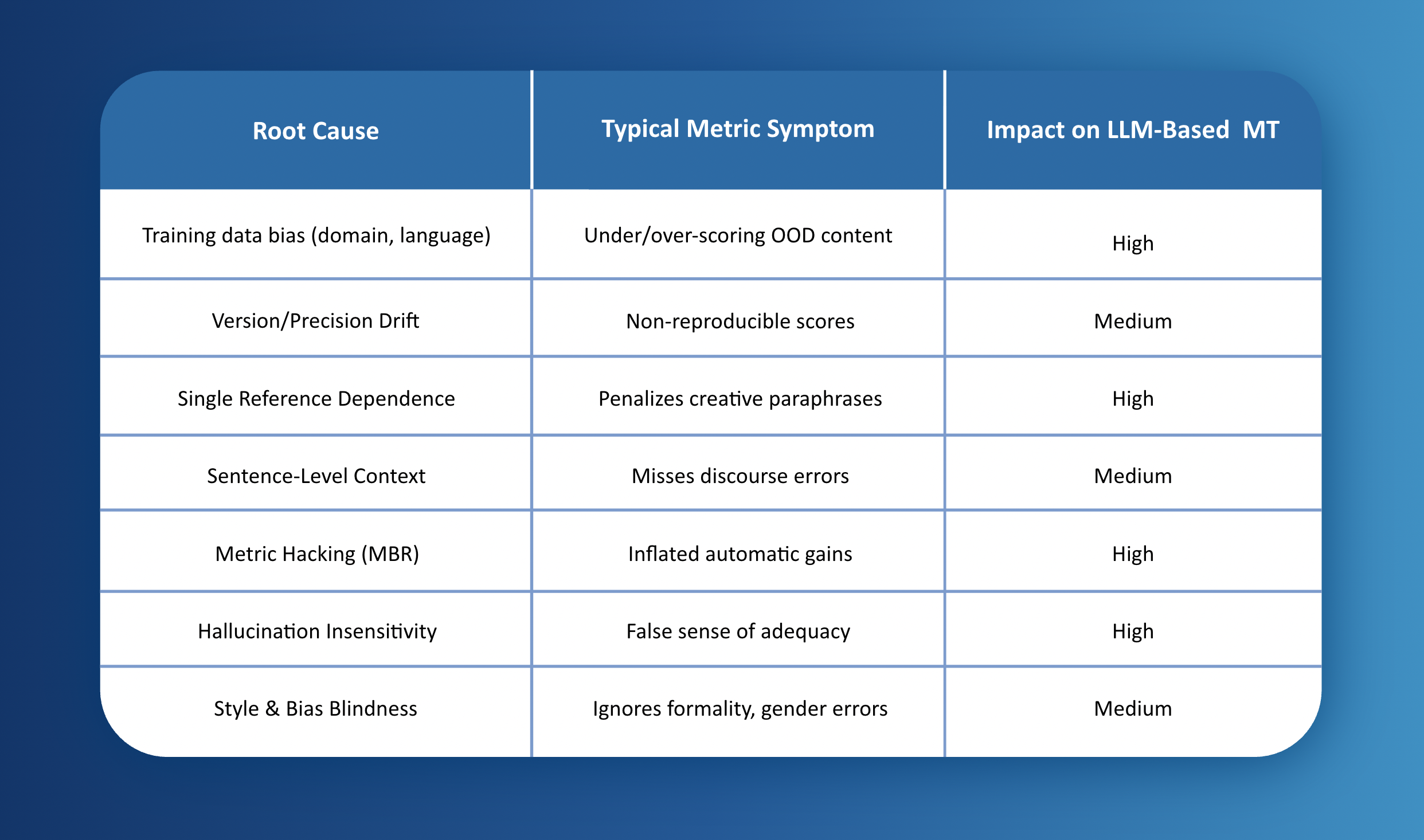
图7:COMET指标在LLM时代的评估优势
这时候,COMET(跨语言优化翻译评估指标)横空出世。据研究显示,COMET通过关注语义内容,在面对词序变化、同义词使用和意译时表现出更强的鲁棒性。它就像是从用尺子测量画作升级到了用艺术批评的眼光来欣赏——不仅看形式,更看内涵。
零样本翻译:LLM的"超能力"
图8:LLM零样本跨语言翻译能力网络图

LLM最令人惊叹的能力之一,就是它的零样本和少样本翻译能力。这就像是一个天才语言学家,即使从未系统学习过某种语言,也能凭借对语言规律的深度理解进行翻译。
XGLM研究展示了一个令人印象深刻的例子:XGLM-7.5B模型在FLORES-101基准测试中,在171个语言对中超越了GPT-3,甚至在45个方向上超越了官方监督基线。这意味着什么?想象一下,一个从未见过中文-斯瓦希里语翻译样本的模型,却能够准确地在这两种语言之间进行转换,这简直就是语言学习的"魔法"。
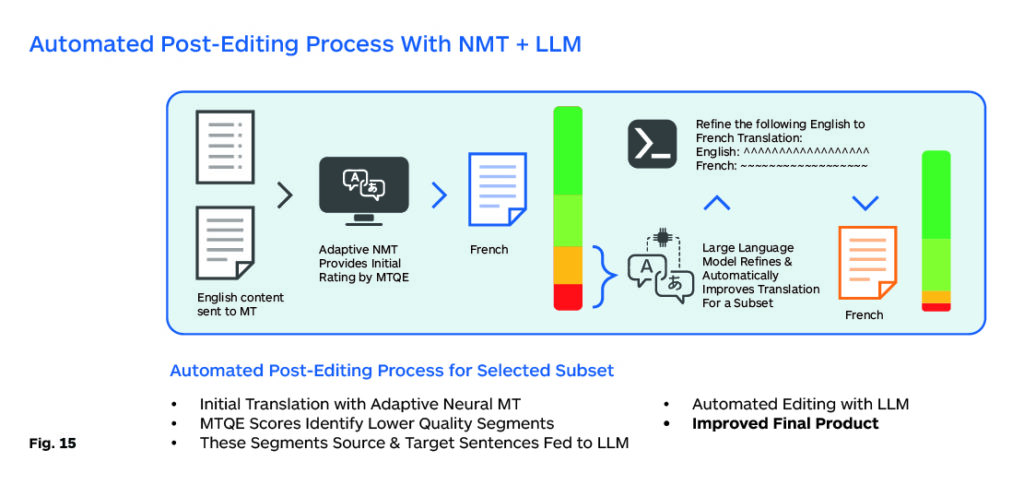
图9:LLM跨语言翻译能力的技术路径
更有趣的是,研究发现Chain-of-Dictionary提示策略能够显著提升低资源语言的翻译效果。这种方法通过在提示中嵌入词汇映射链(比如"river means 河流 means fleuve means Fluss"),帮助模型建立跨语言的词汇关联。这就像是给模型提供了一本多语言词典,让它能够更好地理解不同语言之间的对应关系。
跨语言信息检索:打破语言的壁垒

图10:跨语言信息检索系统架构示意图
除了翻译,LLM在跨语言信息检索(CLIR)方面的表现同样令人刮目相看。最新研究表明,大型密集检索模型即使没有专门针对跨语言检索任务进行训练,也能在零样本设置下实现出色的性能。
这意味着什么?想象一下,你用中文提问"人工智能的发展历史",系统不仅能返回中文资料,还能智能地检索到相关的英文、法文、德文等多种语言的权威文献,并按相关性进行排序。这种能力对于全球化时代的知识获取具有革命性意义。
图11:多语言词嵌入的跨语言语义空间映射
研究显示,LLM作为列表式重排序器在跨语言信息检索系统中表现出色,特别是在处理英文查询和非英文文档的匹配时。这种能力的背后,是LLM对多语言语义空间的深度理解。
商业应用的现实考量:成本与效果的平衡
图12:主流LLM翻译服务的综合对比
尽管LLM在翻译质量上已经展现出明显优势,但在实际应用中仍需要考虑成本因素。根据业界预测,LLM翻译在2025年的成本大约为每千词10美元,但预计到2028年可能降至2美元或更低。
同时,速度仍然是一个挑战。对比研究显示,传统NMT模型的翻译速度比LLM快100-500倍。Google的神经机器翻译引擎通常能在毫秒级别内完成翻译,比LLM快20倍。这就像是精确制导导弹与轰炸机的区别——前者精准但代价高昂,后者快速但可能不够精细。
低资源语言的希望之光
图13:LLM在低资源语言处理中的跨语言迁移学习
LLM翻译革命最激动人心的一面,或许是它为低资源语言带来的希望。研究表明,LLM能够通过跨语言迁移学习,即使在缺乏大量并行语料的情况下,也能为低资源语言提供相对高质量的翻译服务。
这对全球语言多样性的保护具有重要意义。世界上有超过7000种语言,但其中很多面临着数字化缺失的困境。LLM的零样本能力可能成为这些语言数字化的桥梁,让更多的语言能够在数字世界中存续和发展。
顶级LLM翻译系统的激烈竞争

图14:Claude 3.5 Sonnet、GPT-4o等顶级模型的基准测试对比
在LLM翻译的战场上,各大技术巨头正在展开激烈的竞争。最新评测结果显示:
- Claude 3.5 Sonnet: 在WMT24中赢得9个语言对,平均78%的优质翻译率
- GPT-4o: 在所有自动翻译指标上表现卓越,但成本较高
- Gemini 1.5 Pro: 在多数测试中表现良好,但在某些语言对上存在局限
- 传统MT系统: DeepL和Google Translate仍在某些特定场景下保持竞争力
这种竞争态势推动着整个行业的快速发展,每一次技术更新都可能重新洗牌市场格局。
挑战与前景:翻译的未来图景
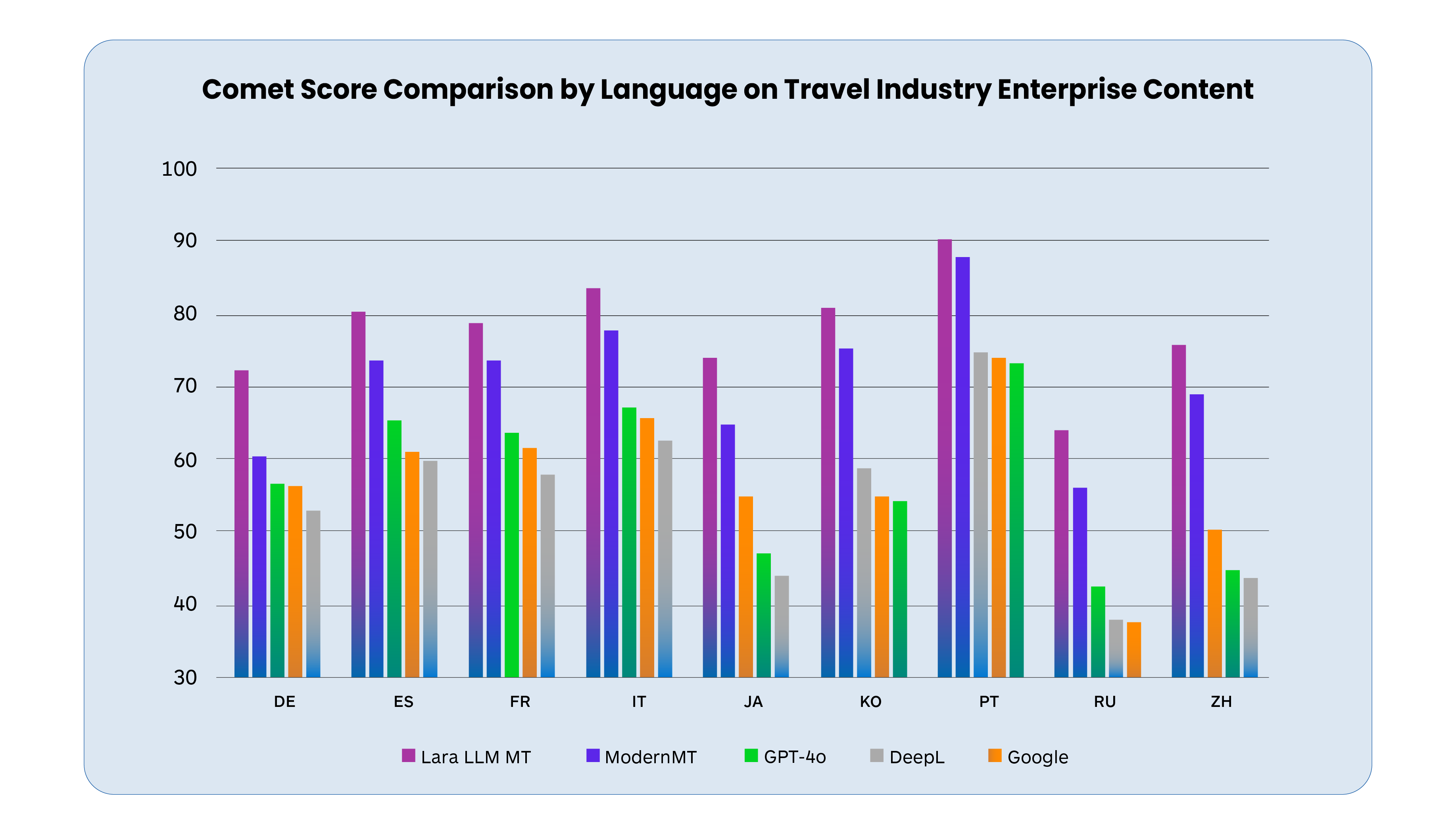
图15:现代机器翻译质量评估中COMET分数的对比分析
当然,LLM翻译也并非完美无缺。研究指出,幻觉现象、评估不一致性和固有偏见仍然是需要解决的挑战。就像任何革命性技术一样,LLM翻译也需要在发展中不断完善。
但展望未来,我们有理由保持乐观。随着模型规模的不断扩大、训练数据的持续丰富以及算法的持续优化,LLM翻译有望在保持高质量的同时,实现更快的速度和更低的成本。
结语:我们正在见证历史

图16:机器翻译技术发展的完整历程
从统计机器翻译到神经机器翻译,再到如今的大语言模型翻译,我们见证了机器翻译技术的三次重大跃迁。每一次跃迁都不仅仅是技术的进步,更是人类打破语言障碍、促进文明交流的努力。
当Claude 3.5 Sonnet在78%的情况下产出优质翻译,当LLM在89%的顶级翻译系统中占据主导地位,当零样本翻译让低资源语言看到希望之光——我们不仅在见证一场技术革命,更在见证人类交流方式的根本性变革。
也许在不远的将来,语言将不再是阻隔人类交流的壁垒,而是丰富人类文明的多彩表达。那时候,我们会回望今天,意识到我们正处在历史的转折点上——一个语言的数字化革命时代。