上周和一位技术负责人聊天,他说团队花了两个月开发一个智能体系统,结果发现简单的工作流就能解决问题,而且更稳定、更便宜。这让我开始思考一个问题:在AI应用开发中,我们是不是被"智能体"这个概念迷惑了?工作流(Workflow)和智能体(Agent)到底有什么本质区别?更重要的是,你的项目真的需要智能体吗?
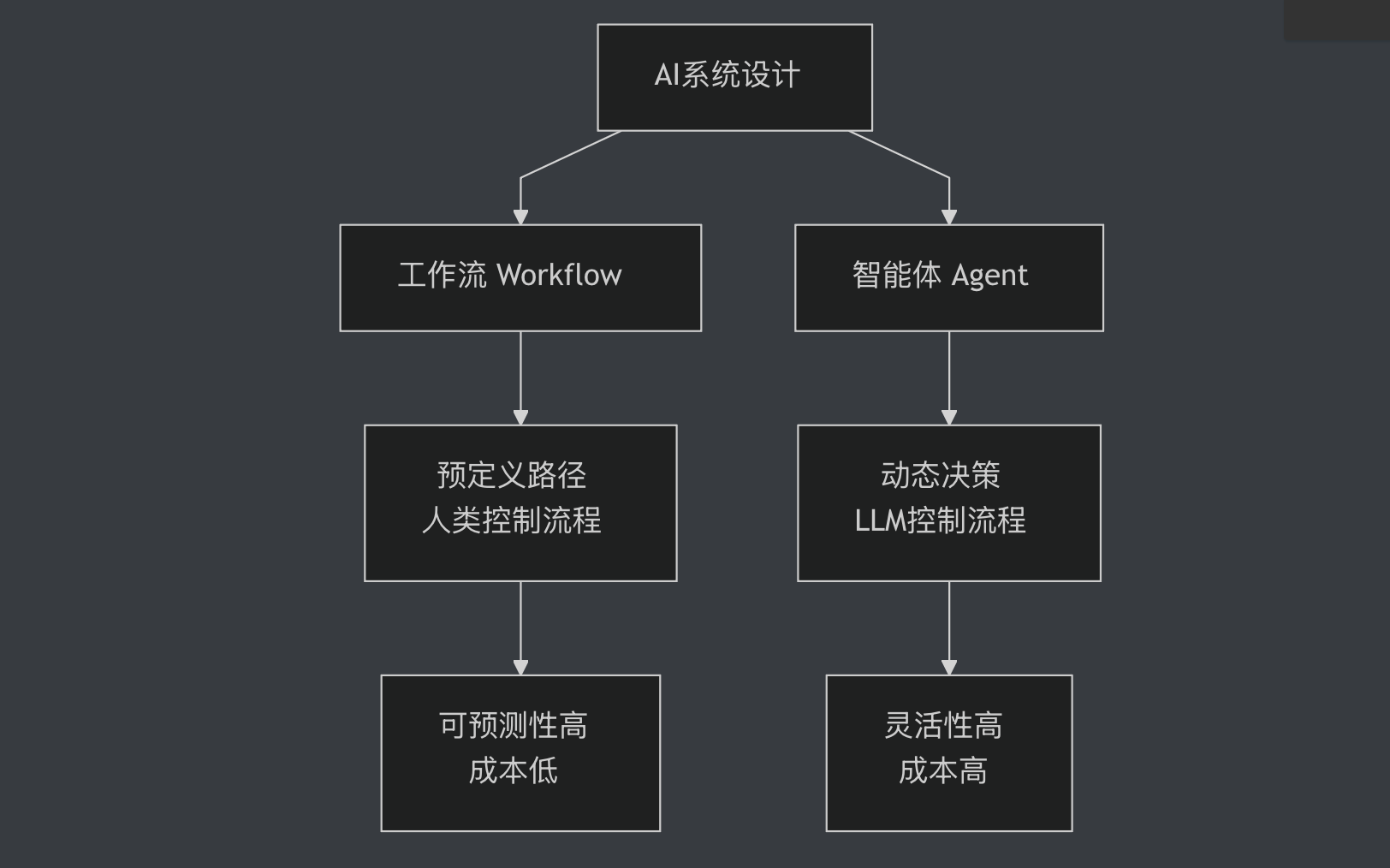
在AI应用开发中,工作流和智能体是两种常见的系统设计模式。根据LangChain创始人Harrison Chase的定义,工作流是通过预定义的代码路径来编排LLM和工具的系统,而智能体则是LLM动态指导自己的流程和工具使用的系统。听起来很简单对吧?但实际应用中,这个区别会带来完全不同的开发成本、运行成本和可靠性。更关键的是,很多团队在盲目追求智能体的"酷炫"时,忽略了工作流在可靠性、成本和维护性上的巨大优势。Anthropic在他们的官方指南中明确指出:当你能用工作流解决问题时,就不要用智能体。这不是保守,而是工程智慧。
工作流:预定义的确定性路径
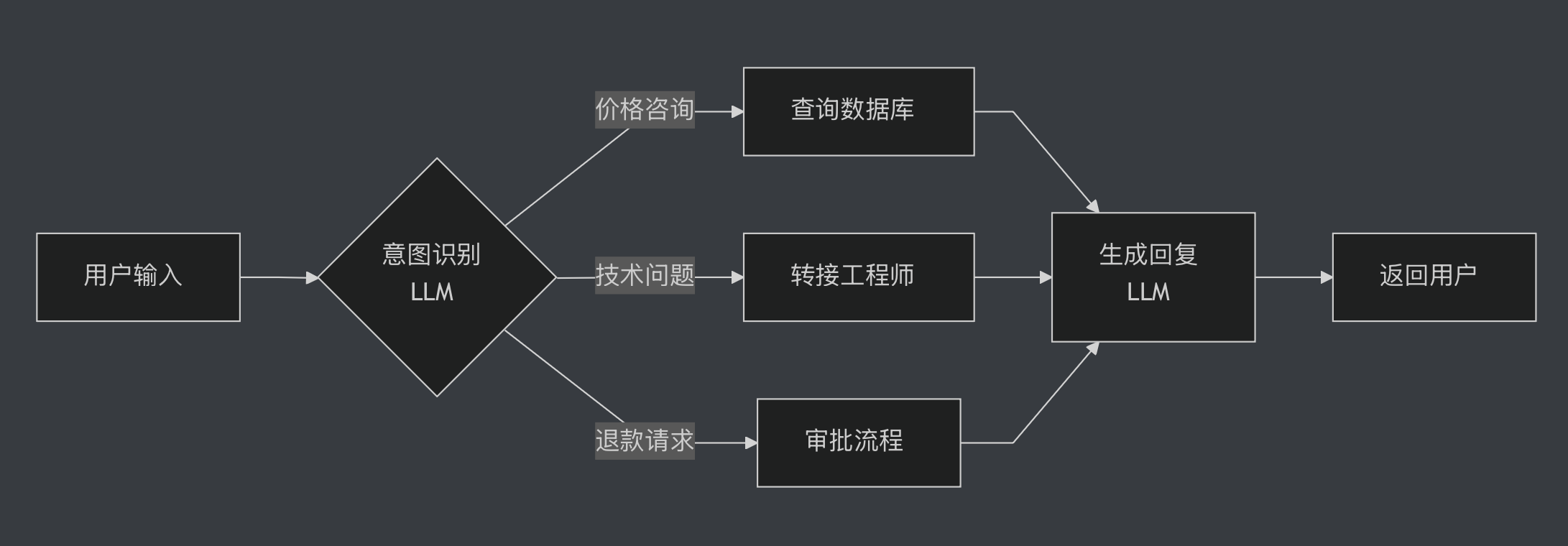
什么是工作流?想象你在用自动化工具处理客户咨询。你定义好规则:如果客户问价格,查询数据库;如果问技术问题,转接工程师;如果要退款,走审批流程。每一步都是你提前设计好的,LLM只负责理解用户意图和生成回复,但不决定下一步做什么。这就是工作流的核心特点:人类设计流程,LLM执行任务。你可以把工作流想象成一个精心设计的流水线,每个环节都有明确的输入输出,LLM只是其中一个环节的执行者。
工作流的优势在于可预测性。Anthropic在他们的指南中特别强调,工作流适合那些任务边界清晰、步骤可枚举的场景。比如文档处理流程:提取文本、分类、摘要、存储。每一步都是确定的,你知道系统会做什么,不会做什么。这种可预测性对于需要合规审计的企业应用至关重要。银行的贷款审批系统、医疗诊断辅助系统、法律文书生成系统,都必须保证每一步的可追溯性和可解释性。你能想象一个银行系统让LLM自己决定是否批准贷款吗?那会是监管噩梦。工作流天然满足这个需求,因为每一步都是人类设计的,每一个决策点都有明确的规则。
工作流的另一个优势是成本和延迟。因为流程是预定义的,系统不需要反复调用LLM来决定下一步,这意味着更少的API调用、更低的成本、更快的响应速度。让我给你一个具体的数字对比:根据我们团队的实际测试,一个典型的客服工作流,每次对话平均调用LLM 2-3次(意图识别加回复生成)。而同样的任务如果用智能体实现,LLM需要在每个决策点都被调用,平均5-8次。对于日处理10万次咨询的系统,假设每次LLM调用成本0.002美元(GPT-4级别),工作流每天成本是400-600美元,而智能体是1000-1600美元。一个月下来,智能体要多花18000-30000美元。这还没算延迟成本:工作流平均响应时间1-2秒,智能体需要3-5秒。对于客服系统来说,每多一秒等待,用户满意度就会下降。
但工作流也有明显的局限性。当任务变得复杂、动态、难以预测时,预定义所有路径就变得不现实。比如你要开发一个研究助手,它需要根据搜索结果决定是否需要更多信息、从哪个角度深入、何时停止。这种场景下,工作流会变得非常复杂:你需要预见所有研究路径、所有信息缺口、所有决策分支。这不仅开发成本高昂,而且一旦遇到未预见的情况,系统就会失效。更糟糕的是,随着需求变化,你需要不断修改工作流的分支逻辑,维护成本会越来越高。这时候,你就需要考虑智能体了。
智能体:LLM驱动的动态决策
什么是智能体?想象你有一个真正的助手,你告诉他"帮我研究一下量子计算的最新进展",他会自己决定:先搜索什么关键词、阅读哪些论文、是否需要查看代码示例、何时认为信息足够了。这就是智能体的核心:LLM不仅执行任务,还决定执行什么任务、以什么顺序执行。你可以把智能体想象成一个有自主权的员工,你只需要告诉他目标,他会自己规划路径。
智能体的工作模式通常是一个循环:LLM接收当前状态、决定调用哪个工具、执行工具获得反馈、根据反馈决定下一步、重复直到任务完成。这个循环让智能体能够处理开放式、探索性的任务。根据IBM的定义,智能体在决策过程中是自主的,但需要人类定义目标和规则。这种自主性既是智能体的优势,也是它最大的风险来源。因为你无法完全预测LLM会做出什么决策,你只能通过提示词、工具描述、状态设计来引导它。这就像管理一个有创造力但有时会跑偏的员工,你需要不断调整指导方式。
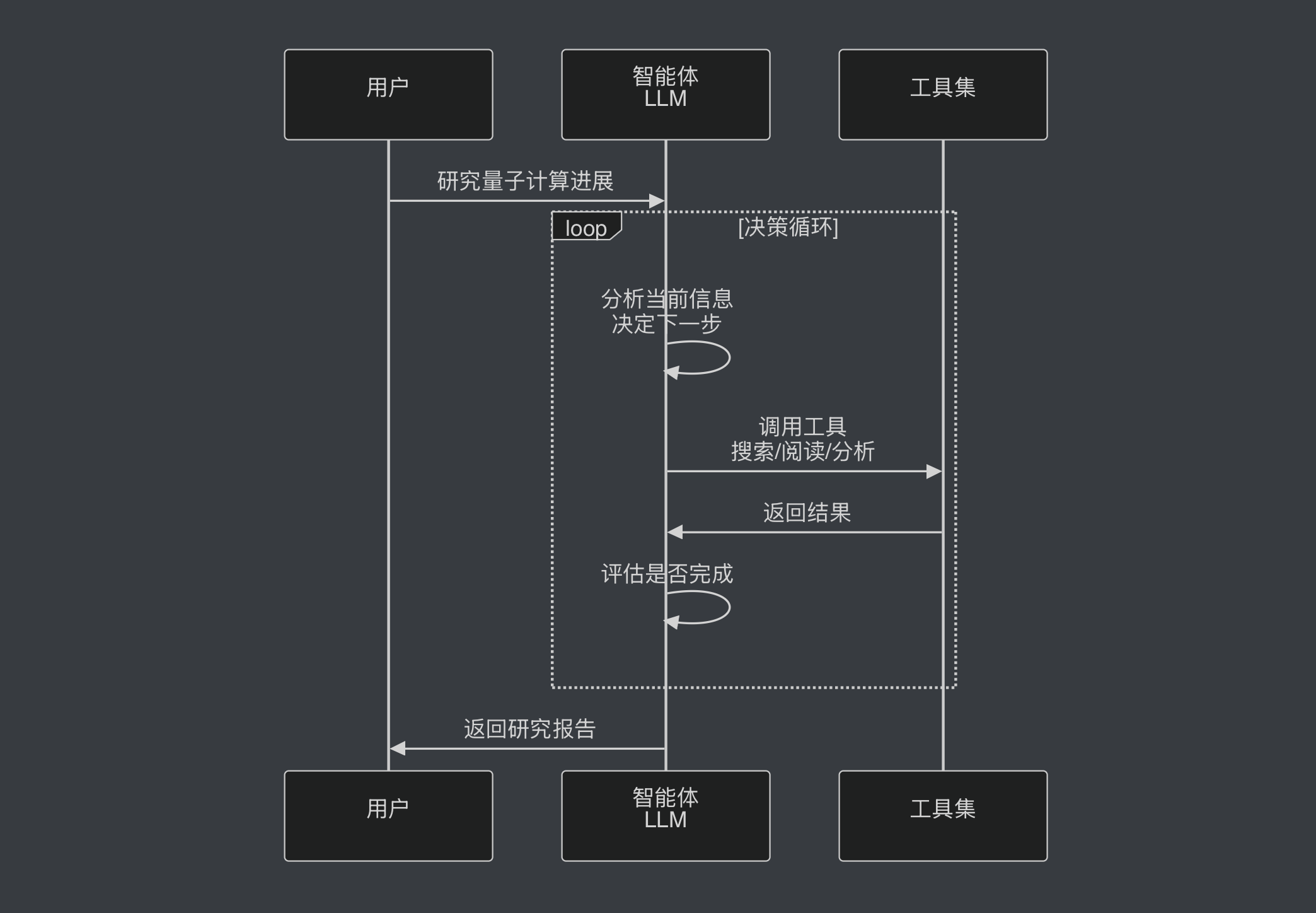
智能体的优势在于灵活性和适应性。它可以处理那些你无法提前预测所有步骤的任务。OpenAI的Deep Research就是一个典型案例:它能根据搜索结果动态调整研究方向,在某个方向信息不足时自动切换角度,这种灵活性让它能完成真正的开放式研究任务。再比如代码调试:智能体可以先运行代码、看到错误、搜索解决方案、尝试修复、再次运行、如果还有问题就换个思路。这种动态调整的能力是工作流难以实现的。你能提前列举出所有的bug和对应的修复步骤吗?显然不能。
但智能体也有明显的缺点,而且这些缺点往往被低估。首先是可靠性问题。LLM会做出错误决策、陷入循环、或者偏离目标。根据LangChain在2024年的开发者调查,"性能质量"是阻碍智能体投入生产的最大障碍,有67%的受访者表示智能体的可靠性不足以支撑业务关键应用。为什么LLM会犯错?核心原因是上下文不足或不正确。LLM在决策时依赖的是你给它的系统提示、工具描述、历史对话和当前状态。如果工具描述不清晰(比如"search"工具到底搜索什么范围),LLM就会误用。如果历史对话太长导致关键信息被遗忘,LLM就会重复无效操作。如果系统提示过于宽泛(比如"尽力完成任务"),LLM就会无限扩展任务范围。我们团队曾经遇到一个案例:一个客服智能体被要求"帮助用户解决问题",结果它开始主动联系供应商、修改订单、甚至尝试退款,完全超出了预期范围。这就是为什么构建可靠的智能体如此困难:你需要精心设计每一个提示、每一个工具描述、每一个状态表示,确保LLM在每个决策点都有正确的上下文。
其次是成本和延迟。前面提到,智能体每次对话需要5-8次LLM调用,是工作流的2-3倍。但这还不是全部成本。更隐蔽的成本是调试和维护:当智能体出错时,你需要回溯整个决策链,分析每一步的输入输出,找出哪里的上下文出了问题。这个过程远比调试工作流复杂。我们团队曾经花了两天时间调试一个智能体的错误决策,最后发现是工具描述中的一个词("可选")被LLM理解成了"不重要",导致它跳过了关键步骤。这种问题在工作流中根本不会出现,因为流程是固定的。
核心对比:五个关键维度
让我们从五个维度系统地对比工作流和智能体。第一个维度是控制方式。工作流是人类控制流程,LLM只负责理解和生成;智能体是LLM控制流程,人类只定义目标。这个区别决定了系统的可预测性和灵活性。如果你的任务需要严格的合规性和可追溯性,工作流是唯一选择。如果你的任务需要灵活应对未知情况,智能体更合适。
第二个维度是适用场景。工作流适合任务边界清晰、步骤可枚举的场景,比如文档处理、客服咨询、数据分析。智能体适合开放式、探索性的任务,比如研究助手、代码调试、创意写作。第三个维度是复杂度。工作流的复杂度在于设计阶段,你需要提前考虑所有路径;智能体的复杂度在于运行时,你需要确保LLM做出正确决策。第四个维度是成本。前面提到,智能体的API成本是工作流的2-3倍,调试成本更是数倍。第五个维度是可维护性。工作流的逻辑清晰,容易调试和优化;智能体的行为动态,难以预测和调试。

| 维度 | 工作流 | 智能体 | 数据支撑 |
|---|---|---|---|
| 控制方式 | 人类控制流程 | LLM控制流程 | – |
| LLM调用次数 | 2-3次/对话 | 5-8次/对话 | 实测数据 |
| 月成本(10万次) | $12,000-18,000 | $30,000-48,000 | 基于GPT-4定价 |
| 响应延迟 | 1-2秒 | 3-5秒 | 实测数据 |
| 可靠性 | 高(流程固定) | 中(67%开发者认为不足) | LangChain 2024调查 |
| 适用场景 | 确定性任务 | 探索性任务 | – |
| 可维护性 | 容易调试 | 困难(需回溯决策链) | – |
如何选择:决策树指南
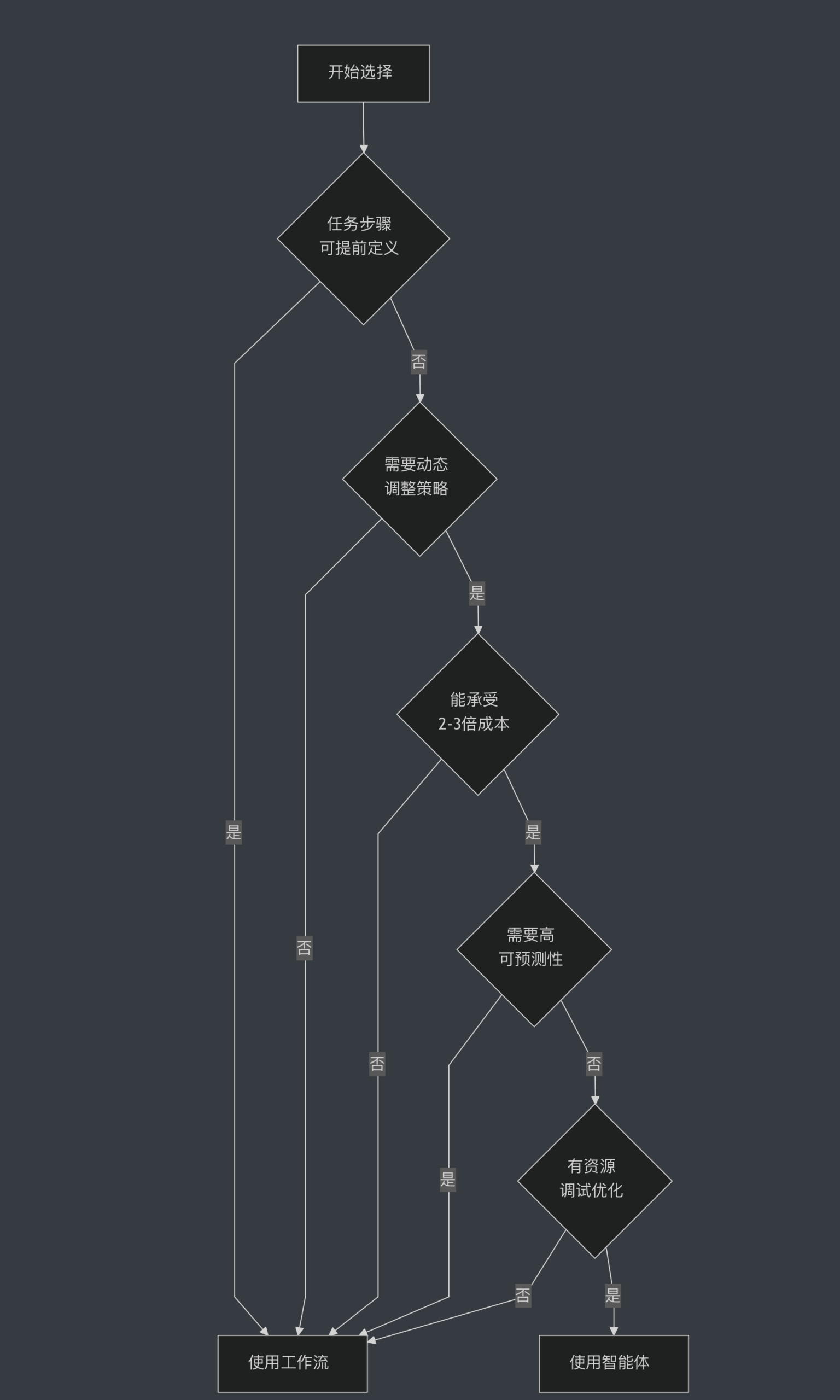
如何决定用工作流还是智能体?让我给你一个实用的决策树。首先问自己:你的任务是否可以提前定义所有步骤?如果可以,用工作流。如果不行,继续下一个问题:你的任务是否需要动态调整策略?如果需要,考虑智能体。如果不需要,还是用工作流。第三个问题:你能承受智能体的成本和延迟吗?如果不能,即使任务需要灵活性,也要想办法用工作流实现。第四个问题:你的应用是否需要高可预测性(比如金融、医疗、法律)?如果需要,优先考虑工作流。最后一个问题:你是否有足够的资源来调试和优化智能体?如果没有,从工作流开始。
实际上,大多数生产系统是工作流和智能体的混合。Anthropic在他们的指南中特别强调这一点:你应该从最简单的解决方案开始,只在必要时增加复杂度。这意味着:先尝试工作流,如果遇到瓶颈再引入智能体。而且,即使使用智能体,也要在关键节点加入工作流的确定性控制。一个典型的混合模式是:用工作流定义主流程,在需要灵活性的节点嵌入智能体。比如客服系统:用工作流处理常见问题(价格、退款、物流),用智能体处理复杂咨询(技术问题、定制需求)。这样既保证了大部分场景的可靠性和效率,又提供了处理特殊情况的灵活性。根据我们团队的经验,这种混合模式可以让80%的请求走工作流(低成本、高可靠),20%的复杂请求走智能体(高灵活性),整体成本比纯智能体降低60%,可靠性比纯智能体提升40%。
实践建议:从简单开始
如果你正在开发AI应用,我的建议是:从工作流开始。先用最简单的方式解决问题,只在遇到明确瓶颈时才引入智能体。Anthropic和OpenAI都在他们的官方文档中强调这一点:不要为了炫技而使用智能体,要为了解决实际问题。你的用户关心的是系统是否可靠、快速、便宜,而不是你用了多酷的技术。我见过太多团队花了几个月开发一个复杂的智能体系统,最后发现简单的工作流就能解决90%的问题,而且更稳定、更便宜、更容易维护。
具体来说,你可以这样做:第一步,明确定义任务边界和成功标准。什么是必须完成的,什么是可选的,什么是绝对不能做的。第二步,尝试用工作流实现,看看能走多远。列出所有的决策点,为每个决策点定义规则。第三步,识别工作流的瓶颈(通常是需要动态决策的地方)。哪些决策点的规则太复杂,哪些情况无法提前预见。第四步,在瓶颈处引入智能体,但保持其他部分的工作流结构。给智能体明确的边界和工具,不要让它有太大的自主权。第五步,持续监控和优化,确保系统的可靠性和成本可控。记录每次智能体的决策,分析哪些决策是正确的,哪些是错误的,不断优化提示词和工具描述。
记住,工作流和智能体不是非此即彼的选择,而是一个连续的光谱。你的系统可以在这个光谱上找到最适合的位置。随着模型能力的提升,智能体会变得更可靠、更便宜,但工作流的简单性和可预测性永远有价值。关键是根据你的具体需求做出明智的选择。今晚就试试重新审视你的AI应用,找到适合你的平衡点,才能构建真正可靠的AI应用。