想象一下,如果有一天你遇到一个朋友,他不仅能从左到右读懂你的话,还能同时从右到左理解你的意思,甚至能猜到你话里没说完的那个词。这听起来很神奇对吧?这就是BERT(Bidirectional Encoder Representations from Transformers)在2018年10月横空出世时给整个自然语言处理领域带来的震撼。
网页版:https://www.genspark.ai/api/page_private?id=uosaprfg
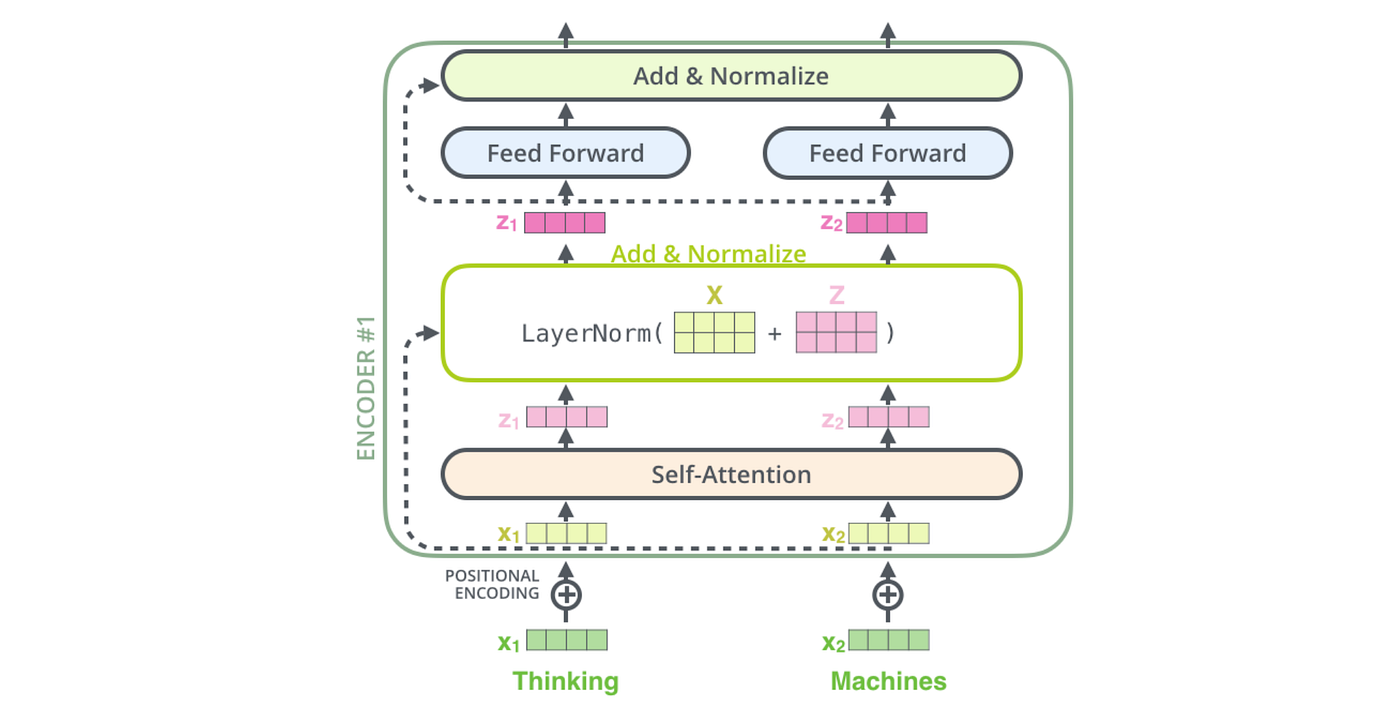
一场语言理解的革命
在BERT出现之前,大多数语言模型就像只有一只眼睛的独眼龙,要么只能从左往右看文字(比如GPT-1),要么只能处理固定的上下文窗口。而BERT就像突然给这个独眼龙装上了一双眼睛,让它能够同时看到句子的前后文,这种双向理解能力让它在理解语言时变得前所未有的聪明。
Google的研究团队在论文中展示了一个令人惊叹的数据:BERT在11个自然语言处理任务上都创造了新的记录,GLUE基准测试分数达到了80.5%,比之前的最好成绩提升了7.7个百分点。这就像一个学霸突然在所有科目上都拿了满分,让整个学术界都为之震惊。
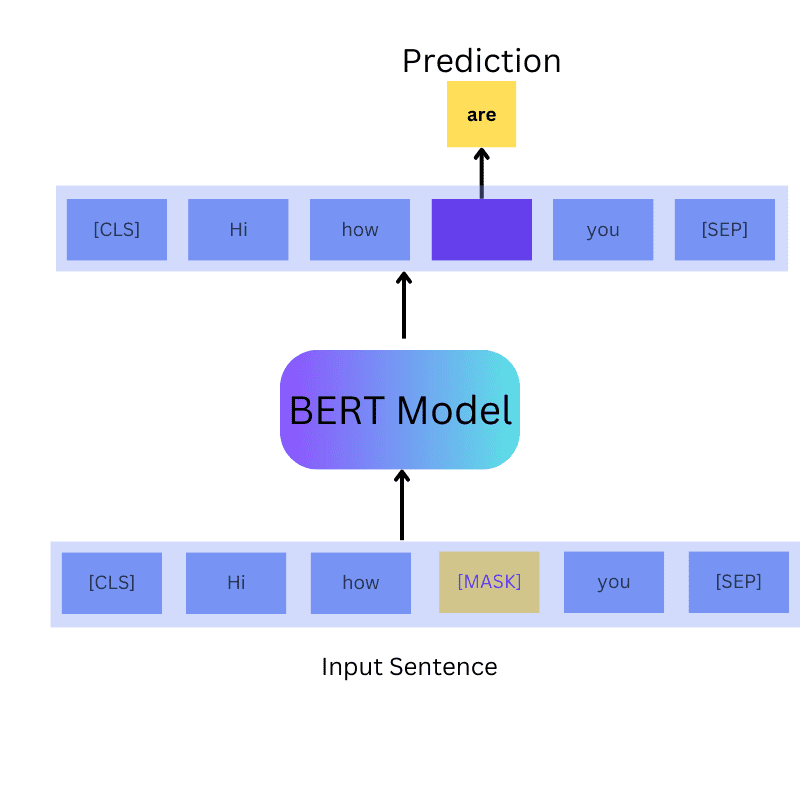
两个绝妙的"游戏":MLM和NSP
BERT的成功秘诀在于它独特的预训练方式,就像给孩子设计了两个特别有趣的语言游戏。
第一个游戏:猜猜我是谁(Masked Language Model – MLM)
想象你在和朋友玩一个填词游戏,朋友给你一句话:"今天天气真___,我们去公园散步吧。" 你需要根据前后文猜出空白处应该填什么词。BERT就是在玩这样的游戏,不过它玩得更加复杂。
BERT会随机遮挡掉15%的词汇,然后训练自己去预测这些被遮挡的词。但这里有个巧妙的设计:这15%的词中,80%会被替换成特殊的[MASK]标记,10%会被随机替换成其他词汇,还有10%保持不变。这种混合策略让BERT不会过度依赖[MASK]标记,在实际应用时表现更加稳定。
第二个游戏:这两句话有关系吗?(Next Sentence Prediction – NSP)
第二个游戏更像是逻辑推理题。给BERT两个句子,让它判断第二个句子是否是第一个句子的自然延续。比如:
句子A:"我今天感觉有点累。"
句子B:"所以我决定早点休息。" (这是合理的延续)
句子A:"我今天感觉有点累。"
句子B:"月亮今晚特别圆。" (这就不是合理的延续)
通过这个任务,BERT学会了理解句子之间的逻辑关系,这对后续的问答、文本推理等任务非常重要。
BERT家族的进化史:越来越聪明的"兄弟姐妹"

RoBERTa:优化训练的"学霸"
2019年,Facebook AI推出了RoBERTa(Robustly Optimized BERT Approach),就像是BERT的学霸兄弟。RoBERTa发现原版BERT其实还没有发挥出全部潜力,于是做了几个关键改进:
- 放弃NSP任务:RoBERTa发现NSP任务可能太简单了,反而影响了模型学习更复杂的语言表示
- 更大的训练数据:使用了160GB的文本数据,是BERT的10倍多
- 更长的训练时间:训练了500K步,而BERT只训练了100K步
- 动态掩码:每次训练时都生成新的掩码模式,而不是使用固定的掩码
这些看似简单的改进让RoBERTa在多个基准测试上都超过了BERT,就像一个学生通过更科学的学习方法取得了更好的成绩。
ALBERT:聪明的"省钞票专家"

ALBERT(A Lite BERT)就像是BERT家族的精打细算的弟弟,它发现可以用更少的参数达到同样甚至更好的效果。ALBERT的两个核心创新特别有趣:
- 嵌入参数分解:把原来的大矩阵分解成两个小矩阵相乘,就像把一个大房间改成两个小房间,空间利用更高效
- 跨层参数共享:让不同层共享相同的参数,就像多个兄弟姐妹共用一套衣服,既省钱又实用
最神奇的是,ALBERT-xxlarge虽然只有223M参数(比BERT-large少了很多),但在多个任务上的表现都更好。这就像用更少的材料建了一栋更坚固的房子。
DeBERTa:注意力机制的"建筑师"

2020年,微软推出了DeBERTa(Decoding-enhanced BERT with Disentangled Attention),它就像是注意力机制的建筑师,重新设计了BERT看待文字的方式。
DeBERTa的核心创新是分离注意力机制:它把每个词分解成两个向量,一个表示内容,一个表示位置。就像给每个人准备了两张名片,一张写着"我是谁",一张写着"我在哪里"。这种设计让模型能更好地理解词汇之间的相对位置关系。
实战演练:用Hugging Face驯服BERT
说了这么多理论,让我们来看看如何在实际项目中使用BERT。Hugging Face Transformers库就像是BERT的"驯兽师工具包",让我们能够轻松地使用这些强大的模型。
快速上手:让BERT猜词
from transformers import pipeline
# 创建一个填词管道
fill_mask = pipeline("fill-mask", model="bert-base-uncased")
# 让BERT猜猜这个词
result = fill_mask("The weather is [MASK] today.")
print(result)
这就像给BERT出了一道填空题,它会根据上下文给出最可能的答案。
微调BERT:教它做新任务
微调BERT就像教一个已经很聪明的学生学习新技能。假设我们要让BERT学会情感分析:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from transformers import Trainer, TrainingArguments
# 加载预训练模型和分词器
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)
# 准备训练数据
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# 设置训练参数
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=64,
warmup_steps=500,
weight_decay=0.01,
)
# 开始训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
)
trainer.train()
这个过程就像给BERT报了一个"情感分析培训班",通过具体的例子教它如何判断文本的情感倾向。
BERT vs 前辈们:一场技术革命
为了理解BERT的革命性,我们来看看它和前辈们的对比。在BERT之前,ELMo虽然也能产生上下文相关的词向量,但它是通过分别训练左到右和右到左的语言模型来实现双向性,就像两个人分别从文章的两端往中间读。而BERT则是真正的双向理解,就像一个人能同时看到整句话的全貌。
GPT-1则完全是从左到右的单向模型,虽然在生成任务上表现很好,但在理解任务上就显得力不从心了。
BERT的影响:改变整个NLP格局
BERT的出现不仅仅是一个新模型的诞生,更是整个自然语言处理范式的转变。它确立了"预训练+微调"的标准流程,这种方法后来被GPT系列、T5等模型延续和发展。
在工业界,BERT也带来了实实在在的影响。Google在2019年宣布将BERT应用到搜索引擎中,能够更好地理解搜索查询的意图。许多公司也开始使用BERT来改进自己的客服机器人、内容推荐系统等。
技术细节:BERT的内在美
从技术角度来看,BERT使用了Transformer的编码器部分,这个架构最初在论文"Attention Is All You Need"中提出。BERT-Base有12层Transformer编码器,每层有12个注意力头,隐藏层维度为768;而BERT-Large则有24层,16个注意力头,隐藏层维度为1024。
BERT的词汇表包含30,000个WordPiece标记,这种分词方法能够很好地处理未登录词和词汇变形。输入序列的最大长度为512个标记,包括特殊的[CLS]和[SEP]标记。
展望未来:BERT的传承
虽然现在大语言模型的风头正盛,但BERT建立的基础依然重要。许多最新的模型,如RoBERTa、ALBERT、DeBERTa等,都是在BERT的基础上改进而来。即便是现在的GPT系列模型,也借鉴了BERT在预训练任务设计上的很多思想。
BERT教会了我们,有时候最简单的想法往往能带来最深远的影响。让机器同时看到文字的前后文,这个看似简单的改变,却引发了整个领域的革命。这就像是给机器装上了一双眼睛,让它真正开始"看懂"人类的语言。