想象一下,如果有人问你"国王"和"王后"之间有什么关系,你会毫不犹豫地回答:"一个是男性君主,一个是女性君主。"但是,如果让计算机来理解这种关系,事情就变得有趣多了。今天,让我们踏上一场奇妙的词向量探索之旅,看看人工智能是如何从最简单的独热编码开始,一步步学会理解语言中深层的语义关系的。
网页版: https://lhnywsjd.gensparkspace.com/
视频版: https://www.youtube.com/watch?v=YTMNeYg9ZFI
从稀疏到密集:语言表示的华丽转身
独热编码:数字世界的第一次握手
在词向量发展的早期,研究者们面临着一个基本问题:如何让计算机理解文字。最直观的方法就是独热编码(One-Hot Encoding)。
想象一下,如果我们要表示"苹果"、"香蕉"、"橘子"这三个词,独热编码会这样做:
- "苹果" → [1, 0, 0]
- "香蕉" → [0, 1, 0]
- "橘子" → [0, 0, 1]

这种方法简单粗暴,就像给每个词发了一张身份证,但问题也很明显:所有词语之间的距离都相等,计算机无法理解"苹果"和"橘子"都是水果,它们之间应该比"苹果"和"汽车"更相似。
词袋模型:收集语言的碎片
为了解决这个问题,研究者们提出了词袋模型(Bag-of-Words)。这就像把一篇文章撕碎,然后数数每个词出现了多少次。虽然失去了词语的顺序信息,但至少能反映出文档的主题特征。
TF-IDF(Term Frequency-Inverse Document Frequency)则更进一步,它不仅考虑词语在当前文档中的频率,还考虑了这个词在整个语料库中的稀有程度。就像一个聪明的图书管理员,既知道某本书被借阅的频率,也知道这本书在整个图书馆中的珍贵程度。
Word2Vec:语义空间的第一次革命
神经网络的语言启蒙
真正的转折点出现在2013年,当Google的研究团队发布了Word2Vec时。这个模型基于一个简单而深刻的想法:相似的词往往出现在相似的上下文中。

Word2Vec提供了两种训练方式:
CBOW(Continuous Bag of Words):给定上下文词语,预测中心词。就像看到"我喜欢吃___",模型需要猜测空白处可能是"苹果"。
Skip-gram:给定中心词,预测周围的词语。就像看到"苹果",模型需要猜测周围可能出现"甜"、"红色"、"水果"等词。
数学魔法:向量运算的语义奇迹
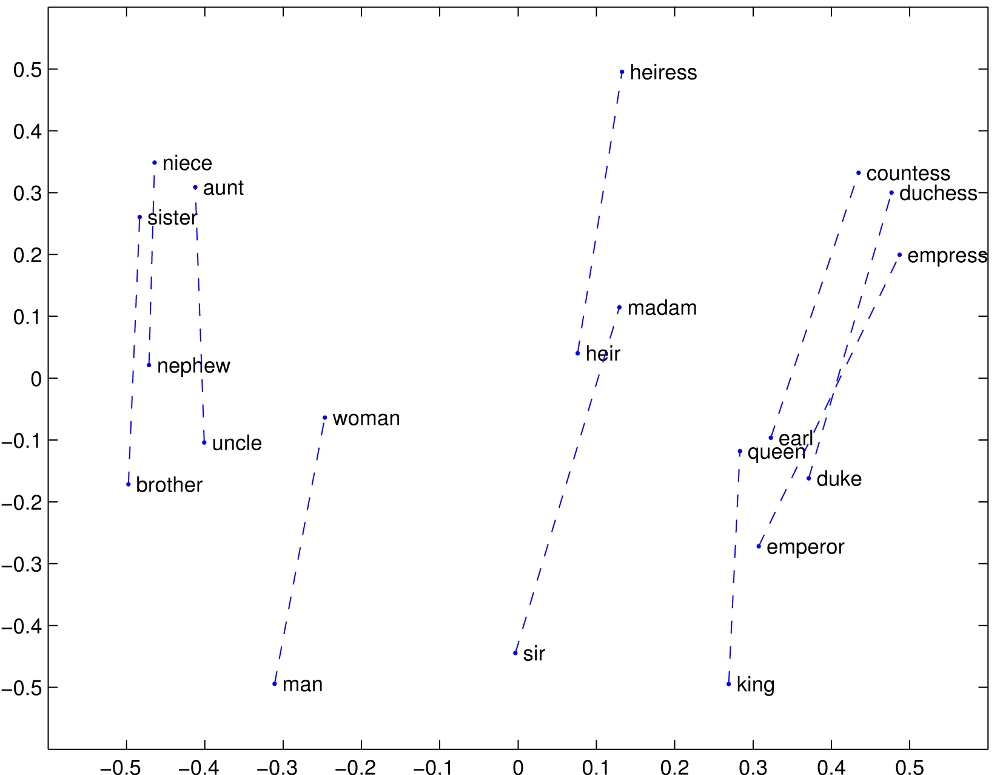
Word2Vec最令人惊叹的特性是它的向量运算能力。研究者发现,在Word2Vec创建的向量空间中,存在着令人震撼的线性关系:
vector(国王) – vector(男人) + vector(女人) ≈ vector(王后)

这不仅仅是数学上的巧合,它意味着模型真正理解了性别这个概念在语义空间中的表示。类似的关系还有很多:
- vector(巴黎) – vector(法国) + vector(意大利) ≈ vector(罗马)
- vector(走) – vector(走了) + vector(游泳) ≈ vector(游泳了)
GloVe:全局视野的语义理解
虽然Word2Vec已经很强大,但斯坦福大学的研究者们觉得还不够。他们在2014年提出了GloVe(Global Vectors for Word Representation),这个模型不仅考虑局部的上下文信息,还充分利用了全局的统计信息。
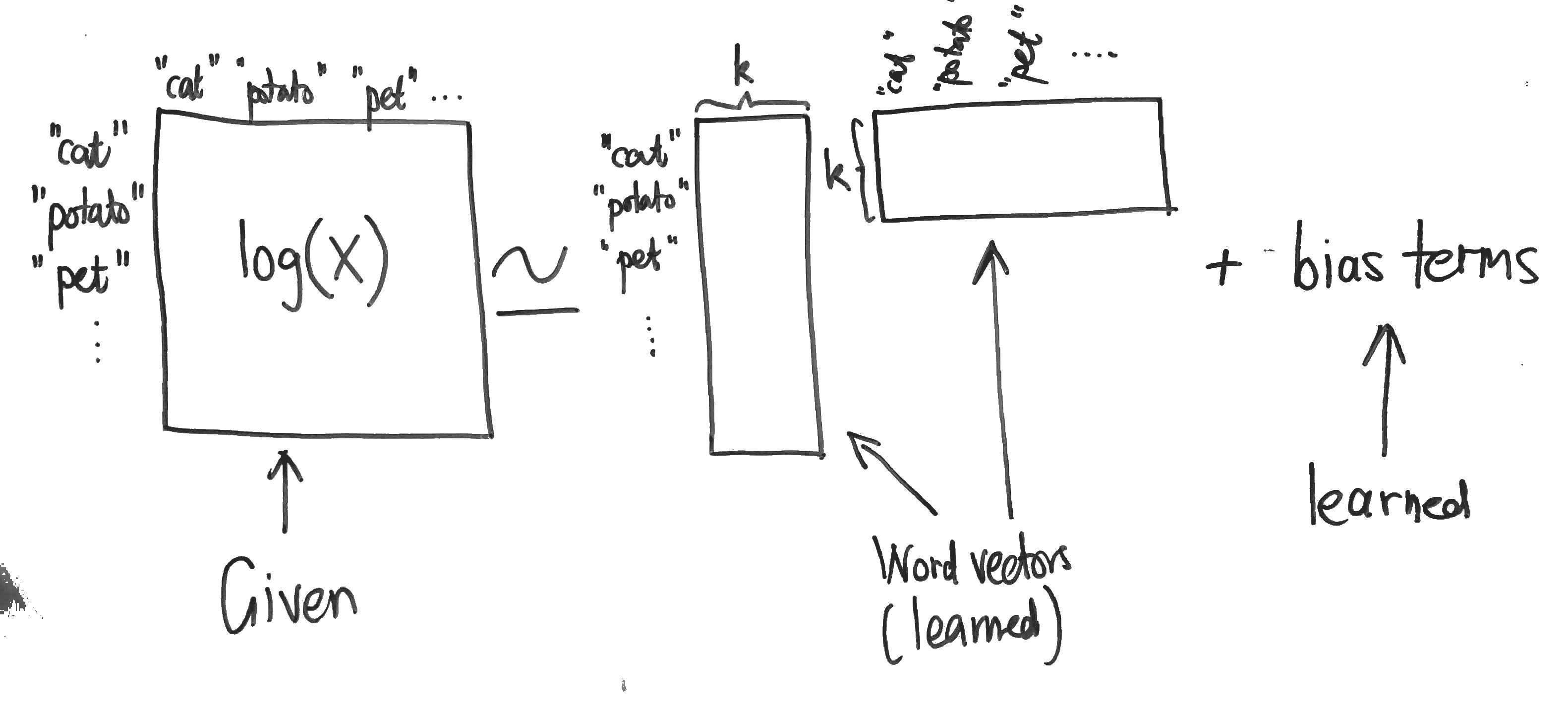
GloVe的核心思想是构建一个词语共现矩阵,然后对这个矩阵进行分解。就像一个经验丰富的语言学家,不仅观察单个句子中词语的关系,还统计整个语料库中词语的共现模式。
通过这种方法,GloVe在类比推理任务上表现出色,在语法和语义关系的捕获上都有不错的效果。
FastText:字符级的智慧
Facebook的研究团队没有止步于此。他们发现了一个问题:Word2Vec和GloVe都无法处理训练时没有见过的词语。于是在2016年,他们推出了FastText。
FastText的创新在于它不仅考虑完整的词语,还将词语分解为字符n-gram。例如,"apple"会被分解为"ap"、"pp"、"pl"、"le"等子词单元。这样做的好处是:
- 处理未知词语:即使遇到训练时没见过的词,也能基于其字符组成给出合理的向量表示
- 捕获形态学信息:能更好地理解词根、前缀、后缀的语义贡献
- 适应形态丰富的语言:对于德语、芬兰语等形态变化复杂的语言表现更佳
上下文的觉醒:ELMo的革命
到了2018年,AI领域迎来了另一个重要时刻。艾伦人工智能研究所推出了ELMo(Embeddings from Language Models),这标志着从静态词向量向动态上下文词向量的转变。

一词多义的智慧
想想"bank"这个词,在"河岸边散步"和"去银行取钱"这两个句子中,它的含义完全不同。传统的Word2Vec只能给"bank"一个固定的向量表示,但ELMo能够根据不同的上下文生成不同的向量。
ELMo使用双向LSTM语言模型,从大量无标注文本中学习。它不仅能区分同一个词在不同语境下的含义,还能为新出现的词语生成有意义的表示。
深层特征的融合
ELMo的另一个创新是它使用了语言模型的多个层次信息。研究发现:
- 底层特征:更适合处理语法任务(如词性标注)
- 高层特征:更适合处理语义任务(如情感分析)
通过学习不同层次特征的权重组合,ELMo能够针对不同任务进行优化。
实践探索:用Gensim构建你的词向量世界
理论再精彩,不如动手实践。让我们看看如何使用Gensim库训练自己的Word2Vec模型:
from gensim.models import Word2Vec
from gensim import utils
# 准备训练数据
sentences = [
['词向量', '技术', '发展', '迅速'],
['自然', '语言', '处理', '应用', '广泛'],
['机器学习', '算法', '不断', '优化']
]
# 训练Word2Vec模型
model = Word2Vec(sentences=sentences,
vector_size=100, # 向量维度
window=5, # 窗口大小
min_count=1, # 最小词频
workers=4) # 线程数
# 查找相似词
similar_words = model.wv.most_similar('词向量', topn=5)
print(similar_words)
# 计算语义相似度
similarity = model.wv.similarity('机器学习', '算法')
print(f'相似度: {similarity:.4f}')
语义相似度的探索
通过训练好的模型,我们可以进行各种有趣的实验:
- 找相似词:输入一个词,找出最相似的其他词语
- 类比推理:验证"国王-男人+女人=王后"这样的关系
- 语义聚类:将意思相近的词语聚集在一起
- 异常检测:在一组词中找出不相关的词语
词向量的局限性与挑战
尽管词向量技术取得了巨大成功,但它们仍然面临着一些挑战:
一词多义问题
即使是ELMo这样的上下文词向量,在处理高度歧义的词语时仍有困难。比如"打"这个字在中文里有几十种不同的含义。
语言的动态性
语言是不断发展变化的,新词不断涌现,旧词的含义也在演化。如何让词向量模型适应这种动态变化,是一个持续的挑战。
文化和领域差异
不同文化背景和专业领域中,同一个词可能有完全不同的含义和联想。通用的词向量模型很难捕捉这些细微差别。
词向量技术的实际应用
搜索引擎优化
现代搜索引擎大量使用词向量技术来理解查询意图。当你搜索"苹果电脑"时,系统能够理解你想要的是Mac电脑,而不是苹果水果。
推荐系统
电商平台使用词向量来理解商品描述和用户评论,从而提供更精准的推荐。
机器翻译
词向量为机器翻译提供了语义基础,让翻译结果更加自然流畅。
情感分析
通过词向量,系统能够理解文本中的情感色彩,为企业提供舆情分析服务。
展望未来:从词向量到语言理解
词向量技术的发展并没有止步于ELMo。随后的BERT、GPT等预训练语言模型,都是在词向量技术基础上的进一步发展。这些模型不仅能理解单词之间的关系,还能理解句子、段落甚至整篇文章的语义。
多模态融合
未来的词向量不仅会处理文字,还会融合图像、音频等多种模态信息,实现更全面的语义理解。
个性化词向量
针对不同用户的语言习惯和知识背景,生成个性化的词向量表示,让AI助手更懂你。
可解释性增强
让词向量不再是"黑盒子",而是能够解释为什么两个词相似,语义关系是如何形成的。
动手实践:构建你的词向量实验室
如果你对词向量技术充满好奇,不妨从以下几个方面开始实践:
1. 数据收集与预处理
- 收集你感兴趣领域的文本数据
- 进行分词、去噪、标准化等预处理
- 构建词汇表,处理低频词和未知词
2. 模型训练与调优
- 尝试不同的词向量模型(Word2Vec、GloVe、FastText)
- 调整超参数(向量维度、窗口大小、学习率等)
- 使用不同的训练策略(CBOW vs Skip-gram)
3. 效果评估与可视化
- 使用类比推理任务评估模型效果
- 通过t-SNE等方法可视化词向量空间
- 分析模型在特定任务上的表现
词向量技术的发展历程,就像人类对语言理解的不断深化。从最初的符号表示,到今天的语义理解,每一步都是人工智能向真正的语言智能迈进的重要里程碑。在这个充满可能性的领域里,每个人都可以成为语言与计算机之间的桥梁建设者。
通过学习和实践词向量技术,我们不仅能够构建更智能的NLP应用,更重要的是,我们正在参与创造一个机器能够真正理解人类语言的未来。这个未来,值得我们每个人的探索和贡献。