
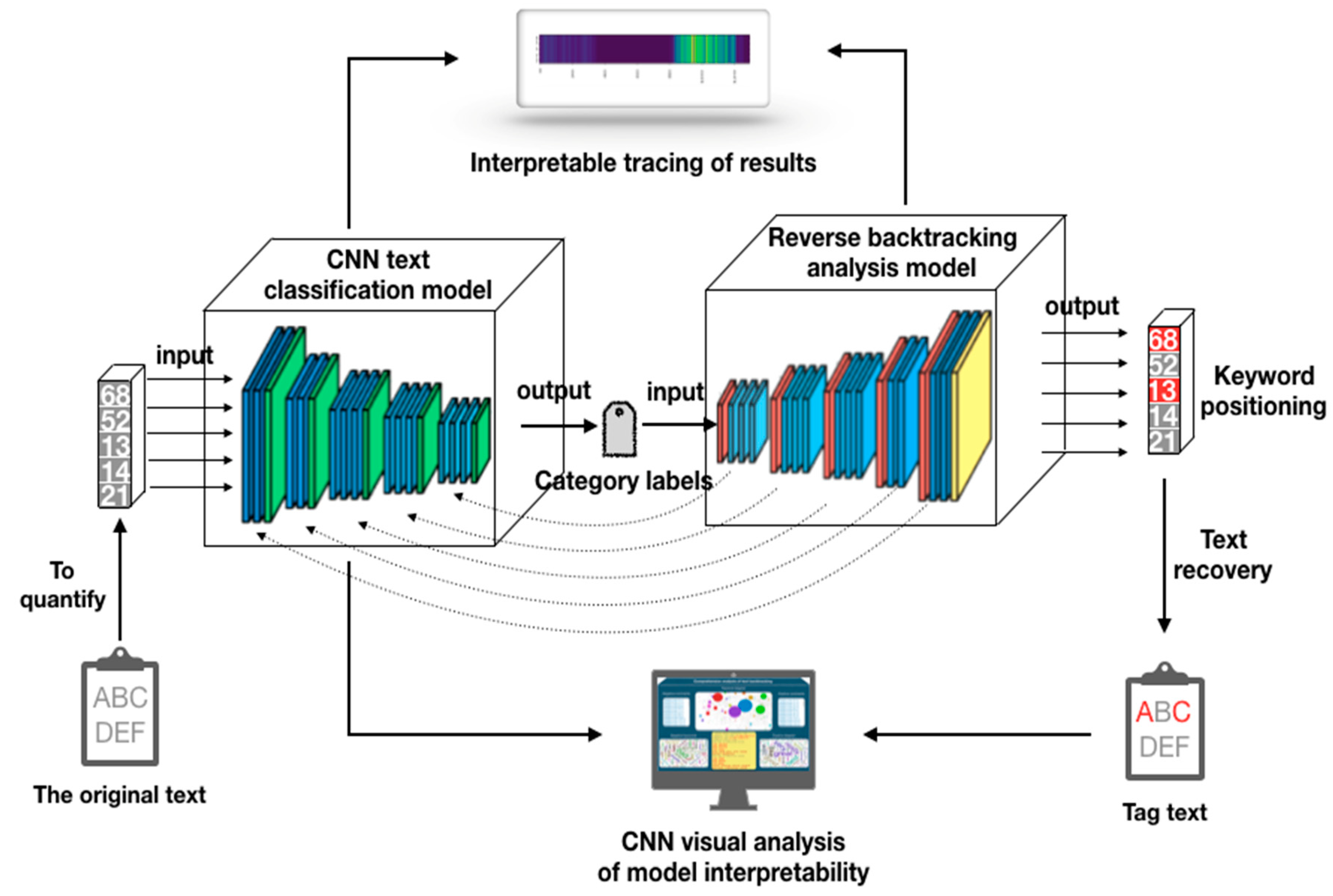
想象一下,如果你是一位产品经理,每天面对着成千上万条用户评论,你会如何快速了解用户对产品的真实感受。或者,如果你是一名新闻编辑,需要在海量的文章中快速找到特定主题的内容,你又会怎么做。这就是文本分类与情感分析技术诞生的原因——让机器像人类一样理解和分析文本。
网页版:https://wtlwrfhr.gensparkspace.com/
视频版:https://www.youtube.com/watch?v=SYmnz55flqI
技术演进的故事:从规则到智能
传统方法的朴素智慧
故事要从1960年代说起,那时的研究者们就像古代的工匠一样,试图用最简单的工具解决复杂的问题。朴素贝叶斯成为了第一个吃螃蟹的算法,它基于一个看似天真的假设:文本中的每个词都是独立的。虽然这个假设在现实中并不完全成立,但正是这种"朴素"让它能够快速有效地处理文本分类任务。

随后登场的支持向量机(SVM)就像一位精准的射手,它通过寻找最优的超平面来分割不同类别的文本。当配合TF-IDF特征提取技术时,SVM在文本分类任务上展现出了令人印象深刻的性能。研究表明,传统方法在小数据集上往往比深度学习方法表现更好,这一点至今仍然适用。
深度学习的技术突破
2010年代的到来带来了一场技术革命。TextCNN的出现就像是为文本分析领域打开了一扇新的大门。Kim在2014年的开创性工作展示了如何将原本用于图像处理的卷积神经网络应用到文本分类中。
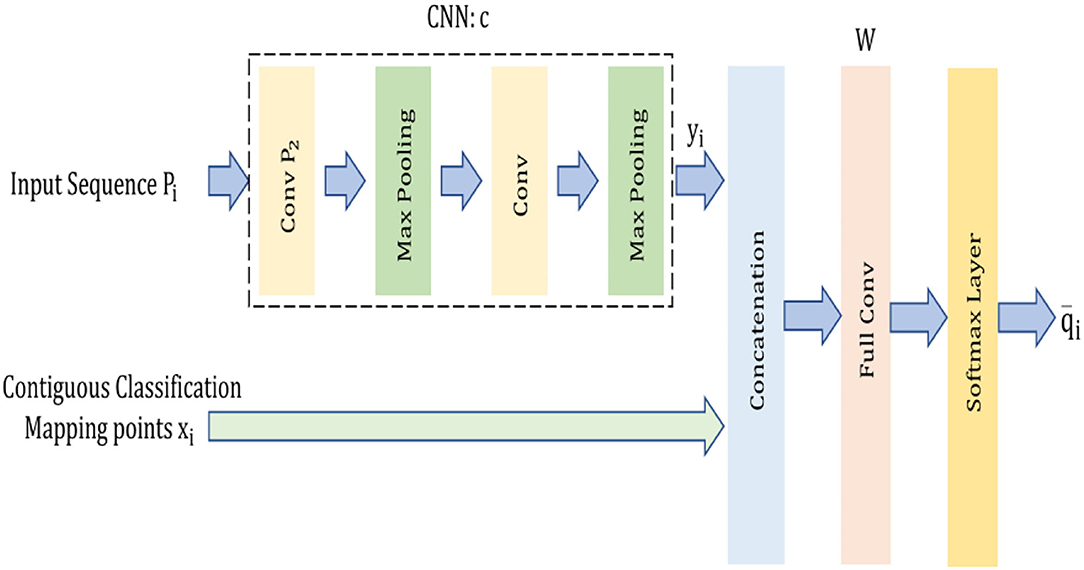
TextCNN的工作原理就像是用不同大小的滤镜来扫描文本,每个滤镜都能捕捉到不同长度的n-gram特征。比如,一个大小为3的滤镜可能会识别出"非常好"这样的三元组合,而大小为5的滤镜则可能捕捉到"这部电影非常精彩"这样更长的语义模式。
RNN与LSTM的序列建模能力
如果说CNN擅长捕捉局部特征,那么RNN家族就是处理序列信息的专家。LSTM(长短期记忆网络)的出现解决了传统RNN的梯度消失问题,它通过巧妙的门控机制来控制信息的流动。
实践案例显示,在情感分析任务中,PyTorch实现的LSTM模型在训练速度上通常优于TensorFlow的Keras实现,但在准确率方面后者略胜一筹。这种差异主要源于不同框架的底层优化策略。

BERT:预训练模型的时代
2018年,BERT的横空出世彻底改变了NLP领域的游戏规则。这个基于Transformer架构的预训练模型就像是一位博览群书的学者,它在海量的文本数据上进行预训练,然后针对特定任务进行微调。
在情感分析任务上,BERT的表现往往能够达到90%以上的准确率,远超传统方法。它的双向编码能力让它能够同时理解文本的前后文信息,这对于情感分析这种高度依赖语境的任务来说至关重要。
技术对比:各显神通的方法论
性能对比分析
根据最新的综述研究,不同方法在各种数据集上的表现差异显著:
传统方法的优势:
- 朴素贝叶斯:参数少,对缺失数据不敏感,算法简单
- SVM:能处理高维和非线性问题,泛化能力强
- 决策树:结果易于理解和解释
深度学习的突破:
- CNN:能够自动学习局部特征,无需手工特征工程
- LSTM:擅长处理长序列依赖关系
- BERT:利用大规模预训练,在多项任务上取得SOTA性能
框架选择的考量
在实际项目中,TensorFlow vs PyTorch的选择往往取决于具体需求:
TensorFlow的优势:
- 生产环境部署更加方便
- 社区资源丰富,文档完善
- TensorBoard可视化工具强大
PyTorch的特点:
- 动态计算图,调试更加直观
- 研究人员更加偏爱
- 训练速度通常更快
实际应用:技术如何改变世界
商业应用的广阔前景
情感分析在商业领域的应用已经渗透到各个角落:
电商平台的智能分析:
亚马逊利用情感分析技术自动分析数百万条产品评论,不仅帮助用户快速了解产品质量,还为商家提供改进建议。系统能够识别出评论中的关键问题,比如"电池续航差"、"屏幕质量好"等具体反馈。
社交媒体监控:
Twitter每天产生约5亿条推文,品牌方通过情感分析技术实时监控用户对产品或事件的反应。当负面情绪激增时,系统会立即报警,让公关团队能够及时应对危机。
金融市场预测:
华尔街的量化基金使用情感分析技术分析新闻报道、社交媒体讨论和分析师报告,将情感指标作为投资决策的重要参考。研究显示,新闻情感与股价波动之间存在显著相关性。
技术挑战与解决方案
讽刺与反语识别:
"这部电影真是太’精彩’了,我都睡着了三次"——这样的表达对机器来说是个巨大挑战。最新的BERT等预训练模型通过大量的语境学习,在这方面有了显著改进。
多语言处理:
全球化的今天,企业需要处理多种语言的用户反馈。fastText等工具通过跨语言词向量技术,让模型能够在多种语言间迁移学习。
细粒度情感分析:
简单的正负面分类已经无法满足复杂的业务需求。现代系统能够识别出愤怒、喜悦、恐惧、惊讶等多种情感状态,甚至能够检测情感的强度级别。
实践指南:如何选择合适的方法
数据规模决定技术路线
小数据集(<10万条):
传统机器学习方法往往是更好的选择。朴素贝叶斯配合TF-IDF特征,不仅训练速度快,而且准确率通常不输深度学习方法。
中等数据集(10万-100万条):
CNN和LSTM开始显现优势。TextCNN的简单架构特别适合这个规模的数据,而且计算成本相对较低。
大数据集(>100万条):
BERT等预训练模型的威力得以充分发挥。虽然计算成本较高,但性能提升明显。
业务需求指导技术选型
实时性要求高:
选择轻量级模型,如朴素贝叶斯或轻量版的CNN。研究显示,经过优化的TextCNN可以在毫秒级完成预测。
准确率要求高:
BERT fine-tuning是当前的最佳选择,特别是在关键业务场景中,额外的计算成本是值得的。
可解释性要求高:
传统方法如决策树或线性模型能够提供清晰的决策路径,这在金融、医疗等监管严格的行业中尤为重要。
未来展望:技术发展的新趋势
多模态情感分析
未来的情感分析不再局限于文本,而是结合图像、音频、视频等多种模态信息。想象一下,系统不仅能分析用户评论的文字内容,还能理解配图的情感色彩和语音的情感语调。
少样本学习
Few-shot learning技术的发展让模型能够在极少量标注数据上快速适应新的任务或领域。这对于处理长尾需求和新兴领域的情感分析具有重要意义。
联邦学习与隐私保护
随着数据隐私法规的完善,如何在保护用户隐私的前提下进行情感分析成为新的挑战。联邦学习技术允许模型在不共享原始数据的情况下进行协作训练。
技术实践的深度思考
从朴素贝叶斯到BERT,文本分类与情感分析技术的发展历程就像是人工智能领域的一个缩影。每一次技术突破都建立在前人的基础之上,而每一种方法都有其独特的价值和适用场景。
作为技术从业者,我们需要明白的是,没有万能的算法,只有最适合特定问题的解决方案。在追求最新技术的同时,也不应忽视传统方法的价值。有时候,一个简单的朴素贝叶斯分类器可能比复杂的深度学习模型更加适用。
技术的进步从未停止,而我们需要做的是保持学习的热情,在理解技术原理的基础上,结合实际业务需求,选择最合适的技术方案。这样,我们才能真正让技术为业务赋能,为用户创造价值。