想象一下,你正站在一个巨大的迷宫入口前,手里拿着一堆杂乱无章的数据,心中怀着一个朴素的愿望:让机器理解这个世界,并帮助人们做出更好的决策。这就是每一个机器学习项目的开始,充满了未知和挑战,但也蕴藏着无限的可能性。
网页版:https://dsgyvdkr.gensparkspace.com/
视频版:https://www.youtube.com/watch?v=4w0PMPeR1rg
音频版:https://notebooklm.google.com/notebook/78802c77-5ff3-4acd-a3f7-2d0c252ea657/audio
在经历了数百个机器学习项目后,我发现最成功的项目都有一个共同点:它们都遵循着一套完整的生命周期流程。就像建造一座房子需要从地基开始,一个成功的机器学习项目也需要从问题定义开始,一步步走向最终的部署和维护。
故事的开始:当我们谈论End-to-End时,我们在谈论什么
端到端机器学习项目不仅仅是写几行代码训练一个模型那么简单。它是一个完整的生命周期,就像养育一个孩子一样,需要从怀孕期的规划开始,到出生后的持续关爱。
根据DataCamp的研究,标准的机器学习生命周期包含六个核心阶段:项目规划、数据准备、模型工程、模型评估、模型部署以及监控维护。每个阶段都有其独特的挑战和价值,缺少任何一个环节都可能导致项目的失败。
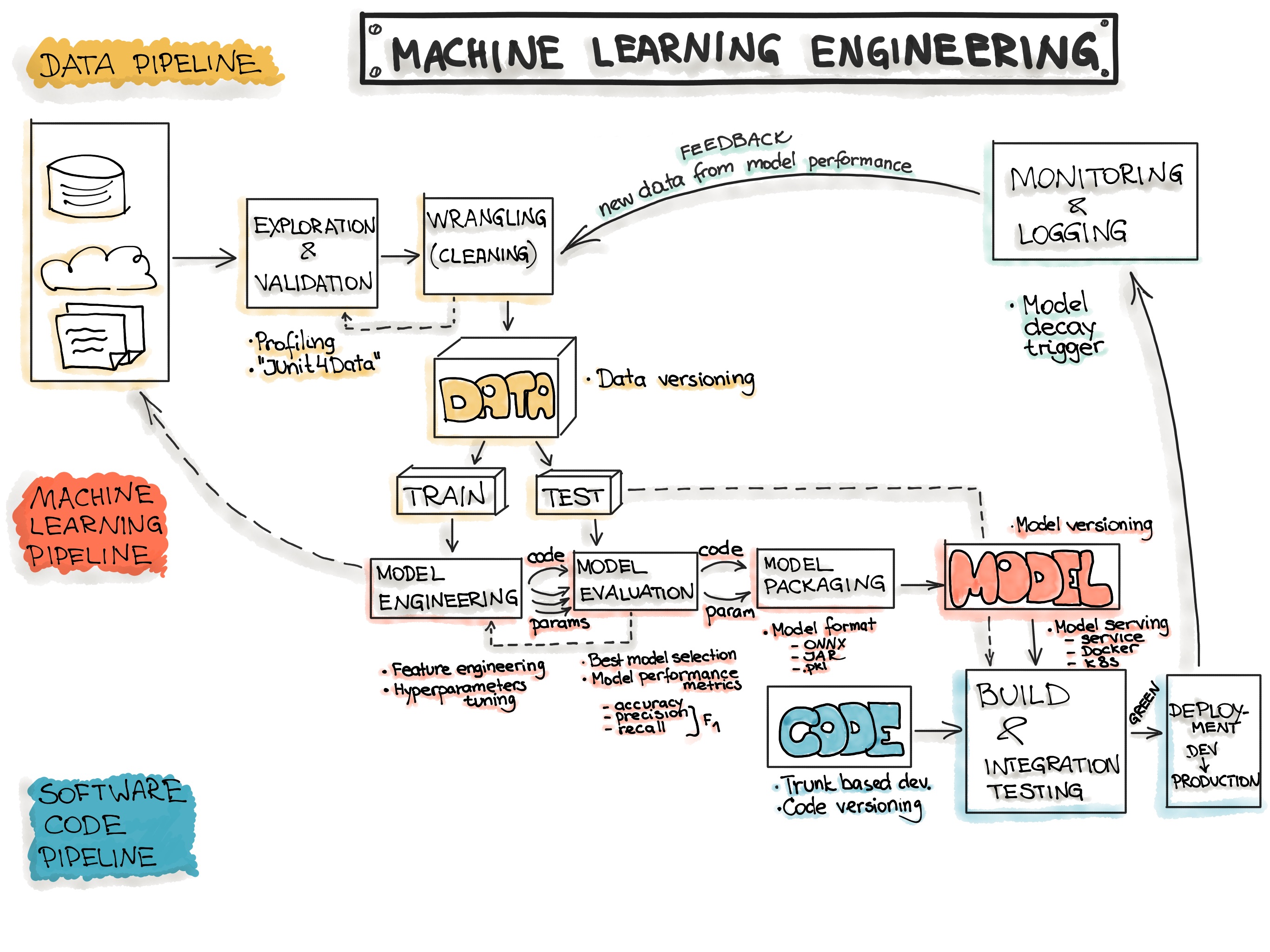
让我们通过几个真实的项目案例来看看这个过程是如何展开的。
第一幕:客户流失预测的惊险之旅
记得我第一次接触客户流失预测项目时的紧张感。一家电商公司发现他们的客户正在大量流失,每个月流失率高达16.8%,这意味着每6个客户中就有一个会离开。CEO焦急地问:"我们能提前知道哪些客户可能流失吗?"
问题定义:找到北极星
这个阶段就像在黑暗中寻找北极星。我们需要明确几个关键问题:
- 什么算作"流失"?是30天没有购买,还是90天?
- 我们希望提前多久预测到流失?
- 预测准确率达到多少才算成功?
研究显示,电商客户流失预测项目的成功关键在于明确定义流失标准。我们最终将"连续3个月无购买行为"定义为流失,目标是提前1个月预测,准确率要达到85%以上。
数据探索:揭开用户行为的神秘面纱
数据探索阶段就像侦探破案一样令人兴奋。我们发现了许多有趣的模式:
- 购买频率越高的用户,流失概率越低
- 客服投诉次数与流失率呈正相关
- 使用优惠券的用户流失率比不使用的低30%
这些发现不仅帮助我们理解了用户行为,还为后续的特征工程提供了重要线索。
特征工程:数据的炼金术
特征工程是整个项目中最具创造性的部分。我们创建了几十个特征:
- RFM特征(最近购买时间、购买频率、购买金额)
- 行为趋势特征(购买频率变化、金额变化趋势)
- 交互特征(客服互动频率、优惠券使用情况)
最终,我们的模型在测试集上达到了87%的准确率,成功帮助公司将流失率降低了25%。
第二幕:二手车价格预测的数据迷宫
如果说客户流失预测是一部悬疑片,那么二手车价格预测就像是一部冒险电影。我们需要在充满噪声和异常值的数据迷宫中找到价格的真相。
数据质量的挑战
IEEE的研究表明,二手车价格预测项目面临的最大挑战是数据质量问题。我们遇到了各种"奇葩"数据:
- 里程数为0但年份是2015年的"新车"
- 价格比新车还贵的二手车
- 同一型号车但价格差异巨大
这些异常数据就像迷宫中的陷阱,需要我们小心识别和处理。
特征工程的艺术
在二手车价格预测中,特征工程更像是一门艺术。除了显而易见的特征(年份、里程、品牌),我们还创造了一些巧妙的特征:
- 车辆年龄与里程的比值(反映使用强度)
- 品牌溢价指数(基于历史成交数据)
- 地区价格指数(不同城市的价格差异)
最终模型能够预测二手车价格,平均误差控制在8%以内,为用户提供了可靠的价格参考。
第三幕:推荐系统的心理学
推荐系统项目是最接近心理学的机器学习应用。正如Criteo的专家所说:"推荐系统是关于理解人类心理的,包含所有复杂性和奇怪的方面。"
从简单开始的智慧
构建推荐系统时,我们学到了一个重要教训:永远从最简单的方法开始。
- 阶段1:最受欢迎的商品推荐
- 阶段2:历史浏览商品推荐
- 阶段3:基于共现的商品推荐
- 阶段4:矩阵分解
- 阶段5:深度学习
令人惊讶的是,简单的"最受欢迎商品"推荐策略往往表现得相当不错,这成为了我们后续所有复杂算法需要超越的基准。
协同过滤的魔力
协同过滤算法让我们见识到了数据的魔力。通过分析用户行为模式,系统能够发现人类自己都没有意识到的偏好关联。比如,购买婴儿用品的用户往往对有机食品也有较高需求,这种关联性为交叉销售提供了宝贵的线索。
项目管理的艺术:让混乱变得有序
在经历了多个项目后,我们意识到技术只是成功的一部分,项目管理同样重要。Medium上的最佳实践指南建议采用模块化的代码组织方式:
project/
├── data/
│ ├── raw/
│ ├── processed/
│ └── external/
├── models/
├── notebooks/
├── src/
│ ├── data/
│ ├── features/
│ ├── models/
│ └── visualization/
├── reports/
└── references/
这种结构让团队成员能够快速理解项目布局,大大提高了协作效率。
实验跟踪的重要性
在模型迭代过程中,我们发现实验跟踪至关重要。使用MLflow等工具记录每次实验的参数、指标和结果,让我们能够:
- 复现最佳结果
- 分析参数对性能的影响
- 避免重复无效的尝试
这就像为每次实验拍照存档,当需要回顾时能够快速找到关键信息。
部署的现实:从实验室到生产环境
模型部署是许多数据科学家的痛点,因为这需要考虑许多在实验阶段不会遇到的问题:
性能与资源的平衡
在实验阶段,我们可能训练了一个有着数百万参数的复杂模型,但在生产环境中,响应时间必须控制在毫秒级别。这要求我们在准确性和速度之间找到平衡点。
A/B测试的智慧
部署新模型时,我们采用了渐进式发布策略:
- 5%流量给基础算法(作为基准)
- 50%流量给当前生产模型
- 45%流量给新模型
这种策略让我们能够安全地验证新模型的效果,同时最小化潜在风险。
监控与维护:永不结束的故事
机器学习项目的部署不是终点,而是一个新的开始。模型在生产环境中会面临数据漂移、概念漂移等挑战。
数据漂移的案例
在客户流失预测项目中,我们发现模型性能在部署6个月后开始下降。深入分析后发现,由于疫情影响,用户的购买行为发生了显著变化,导致原有模型的预测能力下降。
这提醒我们需要建立自动化的监控系统,及时发现并处理这些变化。
持续学习的必要性
为了应对不断变化的环境,我们实施了持续学习策略:
- 定期重新训练模型
- 监控关键指标的变化
- 建立自动化的异常检测系统
经验教训:那些年我们踩过的坑
回顾这些项目,我们总结出几个重要的经验教训:
数据质量胜过算法复杂度
在二手车价格预测项目中,我们花费了大量时间尝试各种复杂算法,但最终发现,改善数据质量比复杂算法带来的提升更大。高质量的数据是成功的基础。
业务理解至关重要
技术人员往往容易沉迷于算法的优化,而忽略了业务需求。在推荐系统项目中,我们发现用户更关心推荐的多样性而不是准确性,这完全改变了我们的优化目标。
简单方法的威力
正如推荐系统专家所说,简单的方法往往出人意料地有效。在开始复杂的深度学习实验之前,确保你已经充分挖掘了简单方法的潜力。
工具链的演进:从手工作坊到自动化工厂
随着项目经验的积累,我们的工具链也在不断演进:
开发阶段工具
- 数据探索:Pandas, Matplotlib, Seaborn
- 模型开发:Scikit-learn, XGBoost, TensorFlow
- 实验跟踪:MLflow, Weights & Biases
部署阶段工具
- 容器化:Docker, Kubernetes
- API开发:FastAPI, Flask
- 监控:Prometheus, Grafana
持续集成工具
- 版本控制:Git, DVC
- 自动化测试:Pytest, Github Actions
- 部署流水线:Jenkins, GitLab CI
这些工具的组合让我们能够构建一个从开发到部署的完整自动化流水线。
未来展望:机器学习项目的新趋势
机器学习项目的实践正在快速演进,几个新趋势值得关注:
AutoML的崛起
自动化机器学习工具正在降低机器学习项目的门槛,让更多的业务人员能够参与到项目中来。但这并不意味着数据科学家会被替代,而是需要我们专注于更高层次的问题解决。
MLOps的成熟
MLOps实践正在从概念走向成熟,标准化的流程和工具让机器学习项目的交付变得更加可靠和高效。
实时机器学习
随着业务需求的变化,越来越多的场景需要实时的机器学习能力,这对系统架构和模型设计提出了新的挑战。
写在最后:每个项目都是一次冒险
每个端到端的机器学习项目都像是一次独特的冒险之旅。你永远不知道会在数据中发现什么有趣的模式,会遇到什么样的技术挑战,会学到什么新的经验教训。
但正是这种不确定性让这个领域如此令人兴奋。当你看到自己训练的模型在真实世界中发挥作用,帮助企业做出更好的决策,改善用户体验时,所有的努力都是值得的。
记住,成功的机器学习项目不仅仅是技术问题,更是人的问题。它需要跨学科的协作,需要对业务的深入理解,需要持续的学习和改进。最重要的是,它需要耐心和毅力,因为真正有价值的项目很少能够一蹴而就。
所以,当你下次站在新项目的起点时,不要害怕挑战,拥抱未知,享受这个过程。因为在机器学习的世界里,每一次尝试都可能带来意想不到的收获,每一个项目都可能改变我们对世界的理解。