想象一下,你正在教一个三岁的小朋友如何区分猫和狗。你拿出一张张照片,指着猫说"这是猫咪",指着狗说"这是小狗"。经过反复训练,小朋友学会了识别。但如果你只是给他一堆动物照片,让他自己分类会怎样?或者更有趣的是,如果你像训练宠物狗一样,每次他做对了就给奖励,做错了就轻轻批评,会发生什么?
网页版: https://edastzpt.gensparkspace.com/
视频版:https://www.youtube.com/watch?v=9FhHg36Yx2E
音频版:https://notebooklm.google.com/notebook/7faea183-01a1-4fbb-b54f-bc6bb7a6610f/audio
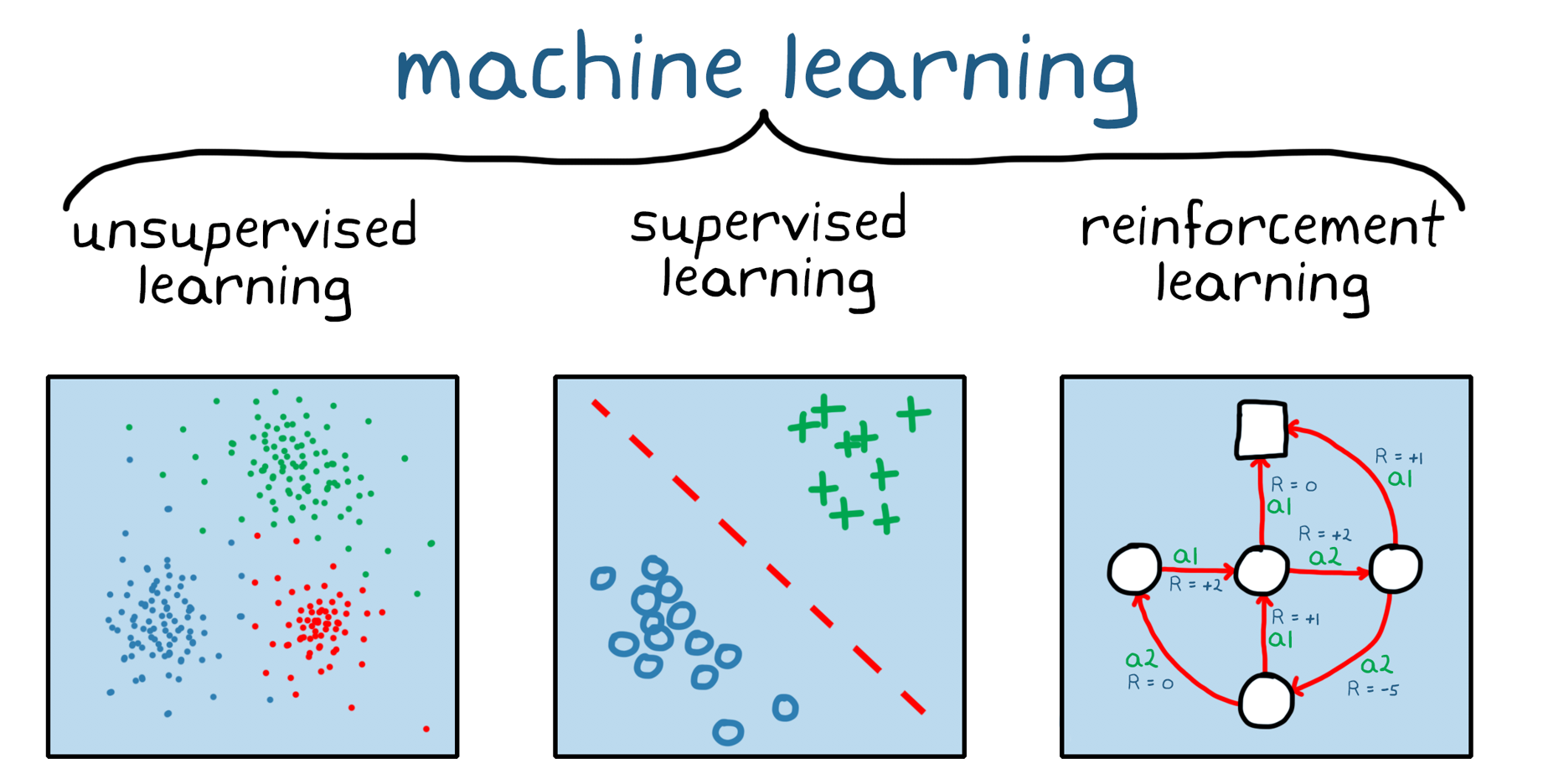
这个简单的生活场景,其实完美诠释了机器学习的三大核心类型:监督学习、无监督学习和强化学习。

监督学习:有老师的课堂
监督学习就像传统的课堂教学,有老师、有教材、有标准答案。在机器学习的世界里,监督学习需要大量的标记数据,就像给每张照片都贴上了标签。
分类:把世界分门别类
分类任务就是把数据分到不同的类别里。最经典的例子是邮件垃圾分类。Gmail每天处理数十亿封邮件,它需要快速判断哪些是垃圾邮件,哪些是正常邮件。这个系统通过学习海量已标记的邮件数据,掌握了垃圾邮件的特征模式。
真实案例一:医疗诊断的革命
在新冠疫情期间,机器学习分类算法被广泛应用于COVID-19的诊断。通过分析CT影像和症状数据,AI系统能够快速判断患者是否感染,准确率甚至超过了一些经验丰富的医生。
真实案例二:金融反欺诈的守护者
信用卡公司每秒都在运行复杂的分类算法。当你在异地刷卡时,系统会瞬间分析这笔交易是否异常。如果你平时在北京消费,突然在上海有大额交易,系统可能会暂时冻结卡片并发送验证短信。
真实案例三:自动驾驶的"眼睛"
特斯拉的自动驾驶系统需要实时识别道路上的各种物体:行人、车辆、交通标志、障碍物。每一个摄像头捕捉的画面都需要被快速分类,这关乎生命安全。
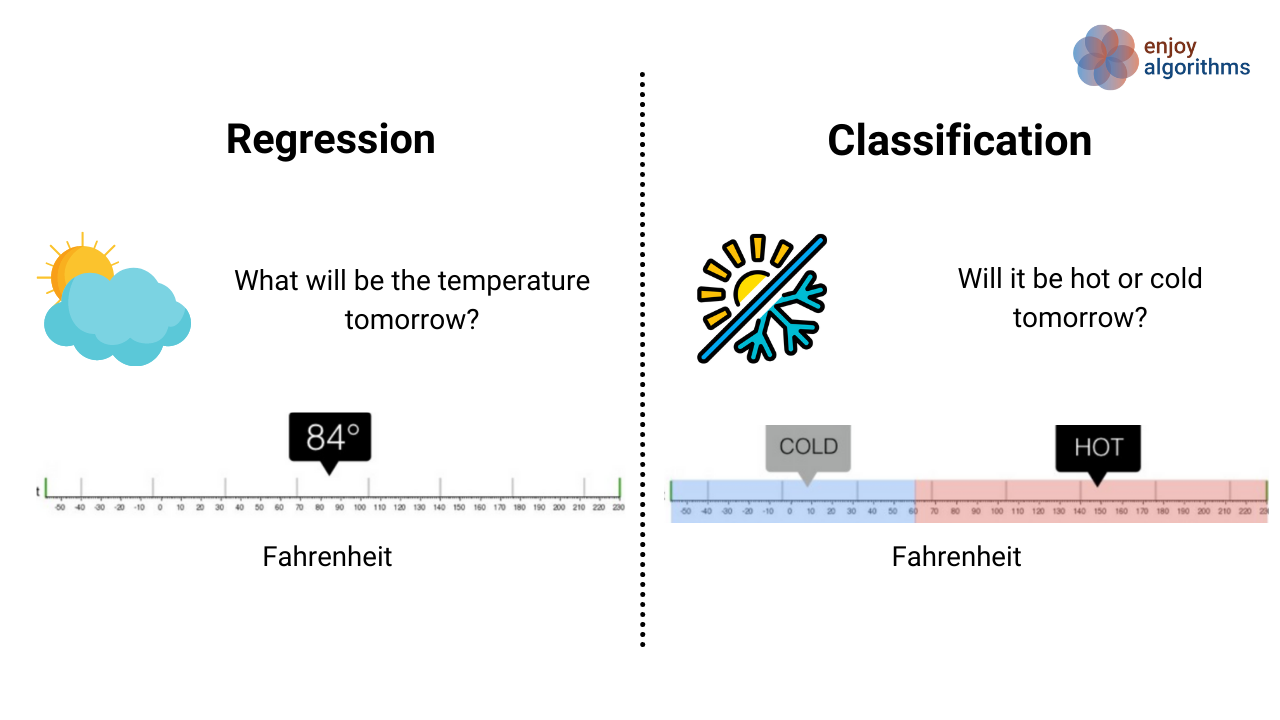
回归:预测连续的未来
如果说分类是选择题,那么回归就是填空题。回归预测的是具体的数值,比如房价、股价、温度等连续变量。
真实案例一:房价预测的魔法
当你在链家或贝壳找房上搜索时,系统会根据地段、面积、装修程度、楼层等因素,预测房屋的合理价格。这背后运行的就是回归算法,它分析了数十万套房屋的历史交易数据。
真实案例二:股市预测的挑战
华尔街的量化交易团队使用复杂的回归模型预测股价走势。虽然股市充满不确定性,但通过分析历史价格、交易量、新闻情感等数据,算法能够捕捉到一些微妙的模式。
真实案例三:天气预报的进化
现代天气预报的准确性相比几十年前有了质的飞跃。气象部门使用回归模型分析大气压、湿度、风速等数据,预测未来几天的温度和降雨概率。
无监督学习:没有标准答案的探索
无监督学习就像让孩子自己整理玩具箱。没有人告诉他哪些玩具应该放在一起,但孩子会根据自己的理解,把相似的玩具归类。这种学习方式在处理未标记数据时特别有用。
聚类:物以类聚的智慧
聚类算法能够自动发现数据中的隐藏模式,把相似的数据点归为一类。
真实案例一:精准营销的秘密武器
亚马逊通过聚类算法分析用户的购买行为,发现了一些有趣的消费群体:比如"深夜购物族"(经常在晚上11点后购买零食)、"健身达人"(同时购买蛋白粉和运动装备)、"新手妈妈"(购买婴儿用品的模式相似)。基于这些发现,亚马逊能够推送更精准的广告。
真实案例二:城市规划的数据支撑
滴滴出行通过分析乘客的出行数据,发现了城市中的热点区域和交通流量模式。这些发现帮助城市规划者优化公交线路,缓解交通拥堵。
真实案例三:疾病研究的新视角
医学研究者使用聚类算法分析基因数据,发现了一些疾病的新亚型。比如,原本认为是同一种癌症的患者,通过基因聚类分析发现实际上可能需要不同的治疗方案。

降维:化繁为简的艺术
降维技术就像给复杂的数据拍一张"全家福",把高维数据投影到低维空间,方便人类理解和可视化。
真实案例一:推荐系统的幕后英雄
Netflix拥有数万部影视作品和数亿用户的观看数据。如何在这个庞大的数据空间中发现规律?Netflix使用降维技术将用户和电影都映射到一个低维空间中,发现了"动作片爱好者"、"文艺片粉丝"等群体的观影偏好。
真实案例二:图像压缩的智能化
JPEG图像压缩本质上就是一种降维技术。通过保留图像的主要特征,丢弃不重要的细节,实现了在保持视觉质量的同时大幅减少文件大小。
真实案例三:基因组学研究的突破
人类基因组包含约30亿个碱基对,这是一个极高维的数据空间。研究人员使用PCA等降维技术,在二维平面上可视化不同人群的基因差异,发现了人类迁徙的历史轨迹。
强化学习:在试错中成长
强化学习最像人类的学习方式。就像训练一只小狗,做对了给零食奖励,做错了轻声批评。在这个过程中,智能体通过与环境的互动,学会了最优的行为策略。
智能体、环境与奖励的三角关系
在强化学习的世界里,有三个关键角色:智能体(Agent)、环境(Environment)和奖励(Reward)。智能体是决策者,环境是它所处的世界,奖励是对其行为的反馈。
真实案例一:AlphaGo的传奇
2016年,AlphaGo战胜了世界围棋冠军李世石,震惊了世界。AlphaGo通过自我对弈,在数百万盘棋局中学习。每一步棋都是一个决策,胜负就是最终的奖励信号。更神奇的是AlphaGo Zero,它完全通过自我对弈学会了围棋,没有使用任何人类棋谱。
真实案例二:自动驾驶的进化之路
AWS DeepRacer是一个1/18比例的自动驾驶赛车。它通过强化学习在赛道上学习驾驶。开始时,小车经常撞墙或者偏离赛道,但通过不断试错,它学会了如何在弯道减速、如何选择最优路线。
真实案例三:游戏AI的革命
OpenAI Five在Dota 2游戏中战胜了人类职业选手。在这个复杂的多人实时策略游戏中,AI需要同时考虑资源分配、团队协作、战术决策等多个维度。通过数千小时的游戏训练,AI学会了一些连人类玩家都没想到的策略。
强化学习在产业中的惊人应用
真实案例一:数据中心的节能大师
Google的DeepMind团队将强化学习应用于数据中心的冷却系统,结果令人震惊:能耗降低了40%。AI系统学会了根据服务器负载、外部温度、时间等因素,智能调节冷却参数。这不仅节省了巨额电费,还大大减少了碳排放。
真实案例二:华尔街的智能交易员
IBM开发了基于强化学习的交易系统,能够在复杂的金融市场中做出买入、卖出或持有的决策。系统通过分析市场数据、新闻情感、经济指标等信息,学会了在不同市场条件下的最优策略。
真实案例三:个性化推荐的进化
YouTube的推荐系统使用强化学习来优化用户体验。系统不仅考虑用户当前的兴趣,还会预测推荐内容对用户长期满意度的影响。如果发现某类内容会让用户产生"信息茧房"效应,系统会适当推荐一些多样化的内容。
三种学习方式的深度对比
让我们用一个生动的比喻来理解这三种学习方式的本质区别:
监督学习就像传统的学校教育。老师拿着教科书,告诉学生每道题的标准答案。学生通过大量练习,掌握了解题规律。这种方式效率高,但局限于已知问题。
无监督学习就像自由探索的艺术创作。没有人告诉画家应该画什么,但画家通过观察世界,发现了色彩的搭配规律、构图的美学原则。这种方式能发现意想不到的模式,但需要更强的洞察力。
强化学习就像学习骑自行车。没有人能通过理论讲解让你学会骑车,你必须亲自上车,在摔倒和平衡中不断调整。最终,你的身体记住了保持平衡的技巧。这种方式最接近人类的自然学习过程。
基本术语的生活化解读
在机器学习的世界里,有一些基本术语需要掌握,让我们用生活化的语言来理解:
特征就像人的特征:身高、体重、年龄、收入等。在房价预测中,房屋的特征可能包括面积、地段、楼层、装修等级。
标签就是你想预测的答案。在垃圾邮件分类中,标签就是"垃圾邮件"或"正常邮件";在房价预测中,标签就是具体的价格数字。
模型就像一个经验丰富的专家。通过学习大量案例,这个专家掌握了判断规律。当遇到新情况时,专家能够给出预测。
损失函数就像考试评分标准。它衡量模型的预测与真实答案之间的差距。差距越小,得分越高;差距越大,需要继续学习改进。
训练集和测试集就像学习和考试的关系。训练集是用来学习的练习题,测试集是最终的考试题。只有在考试中表现好,才说明真正掌握了知识。
概念图:三种学习类型的可视化对比
想象一个三层楼的学习大厦:
一楼:监督学习
- 输入:带标签的数据(照片+标签)
- 处理:学习输入与标签之间的映射关系
- 输出:对新数据的预测结果
- 目标:最小化预测误差
二楼:无监督学习
- 输入:无标签的原始数据
- 处理:发现数据中的隐藏结构和模式
- 输出:数据的聚类结果或降维表示
- 目标:发现数据的内在规律
三楼:强化学习
- 输入:环境状态信息
- 处理:智能体与环境交互,根据奖励调整策略
- 输出:在特定状态下的最优行动
- 目标:最大化长期累积奖励
每一层楼都有自己独特的学习方式,但它们又相互关联,共同构成了机器学习的完整体系。
现实世界中的融合应用
在实际应用中,这三种学习方式常常会融合使用,创造出更强大的AI系统:
自动驾驶汽车结合了所有三种学习方式:使用监督学习识别交通标志和行人,使用无监督学习发现交通模式,使用强化学习优化驾驶策略。
智能助手如Siri或小爱同学,使用监督学习理解语音指令,使用无监督学习分析用户行为模式,使用强化学习优化对话策略。
电商推荐系统使用监督学习预测用户对商品的评分,使用无监督学习发现用户群体,使用强化学习优化推荐时机和方式。
这些应用的成功,正是三种学习方式优势互补的结果。监督学习提供基础认知能力,无监督学习发现隐藏规律,强化学习优化决策策略。
机器学习的魅力就在于此:它不是简单的技术堆砌,而是对人类学习过程的深度模拟和超越。从教小孩认识猫狗,到训练AI系统解决复杂问题,我们正在见证一个智能时代的到来。
在这个过程中,每一个算法的突破,每一个应用的成功,都在推动着人类文明向前发展。而我们,正站在这个激动人心的历史节点上,既是见证者,也是参与者。