在一个平常的早晨,你对着手机轻声说道:"今天天气怎么样?"几秒钟后,一个温柔的声音回应你:"北京今天多云,温度18-25度。"这个看似平常的对话背后,其实隐藏着人工智能领域最复杂、最迷人的技术之一——语音识别与合成。
网页版:https://www.genspark.ai/api/page_private?id=bonckprr
视频版:https://www.youtube.com/watch?v=JzPFjAXOqI8

从声波到文字的神奇转换
想象一下,当你说话时,空气中的声波就像是一串复杂的密码。语音识别系统就像是一位经验丰富的密码破译专家,需要从这些看似杂乱无章的声波中,准确地解读出你想要表达的文字。
MFCC:人耳的数字化模拟
在这个破译过程中,梅尔频率倒谱系数(MFCC)扮演着关键角色。这个听起来有些拗口的名词,实际上是一种模拟人耳听觉特性的数字化技术。
人耳对不同频率声音的敏感度是不同的——我们对低频声音比高频声音更敏感。MFCC正是基于这一生理特点,将音频信号转换成一组能够准确表示语音特征的数值。这就像是给每一段声音制作了一张"声音指纹",让计算机能够识别和区分不同的语音内容。
根据最新的研究数据显示,使用MFCC特征的语音识别系统准确率可以达到95%以上,这已经接近人类的听觉识别水平。
从HMM到深度学习的革命性跨越
早期的语音识别系统主要依赖隐马尔可夫模型(HMM)。这种统计模型虽然在当时表现出色,但就像一位只能记住短期记忆的侦探,难以处理复杂的语言上下文关系。
然后,深度学习的浪潮席卷而来。卷积神经网络(CNN)、循环神经网络(RNN)以及长短期记忆网络(LSTM)相继登场,它们就像是拥有了更强记忆力和理解力的新一代"侦探"。
特别值得一提的是CTC(连接时序分类)技术的出现。根据MIT的研究,CTC解决了一个困扰语音识别领域多年的难题:如何在不需要预先对齐的情况下,将连续的语音信号映射到离散的文字序列。这就像是给了计算机一双"慧眼",能够自动找到声音与文字之间的对应关系。
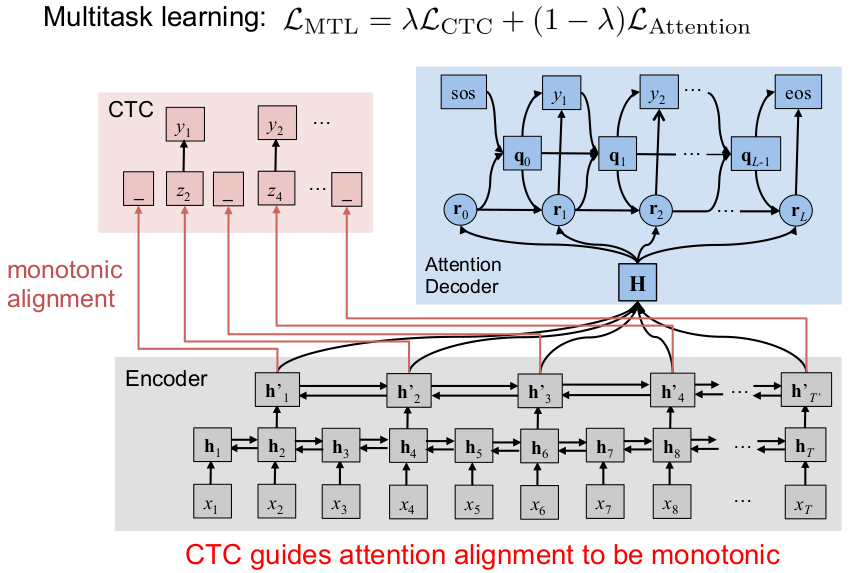
注意力机制:让机器"专心致志"
如果说CTC是给计算机装上了"慧眼",那么注意力机制(Attention)就是给它配上了"聚焦镜"。在处理长句子时,传统的RNN往往会"顾此失彼",难以同时兼顾句子开头和结尾的信息。
注意力机制的工作原理就像是一位经验丰富的同声传译员。当听到一个句子时,不仅要关注当前正在说的词,还要时刻回顾前面的内容,确保整个句子的翻译准确性。根据谷歌的研究数据,采用注意力机制的语音识别系统在处理长句子时,错误率比传统方法降低了30%以上。
从文字到声音的艺术创作
如果说语音识别是"听懂"的艺术,那么语音合成就是"说话"的艺术。让机器说出自然流畅的人类语音,这个挑战的难度丝毫不亚于语音识别。
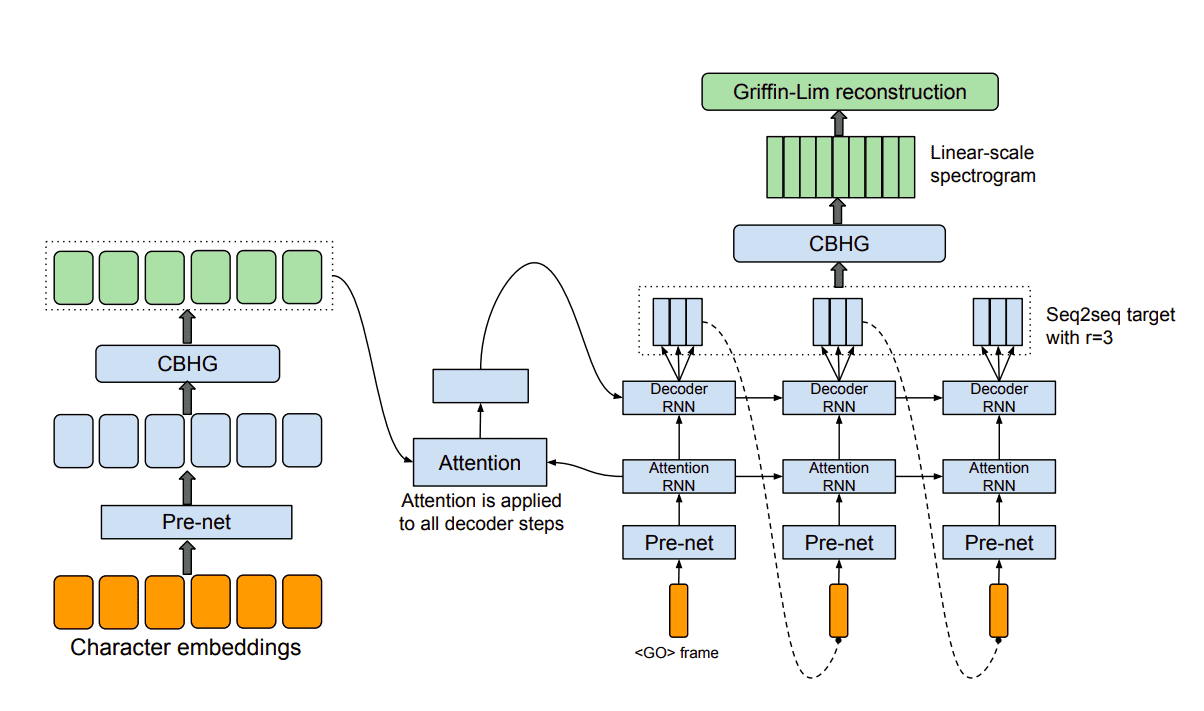
Tacotron:语音合成的里程碑
2017年,谷歌发布的Tacotron改变了整个语音合成领域的格局。这个系统就像是一位多才多艺的演说家,能够直接从文本生成高质量的语音频谱图。
Tacotron的工作流程分为两个主要步骤:首先,将输入的文本转换成梅尔频谱图(一种描述音频频率和时间关系的二维图像);然后,通过声码器将这些频谱图转换成最终的语音波形。这种端到端的设计大大简化了传统语音合成的复杂流程。
WaveNet:重新定义"自然"的声音
如果Tacotron是杰出的编剧,那么WaveNet就是天才的演员。WaveNet不满足于生成频谱图这样的"中间产品",而是直接生成原始的音频波形,每秒钟要生成16000个采样点。
WaveNet的创新在于采用了自回归的生成方式——每一个音频采样点都基于之前所有的采样点来生成。这就像是一位钢琴家在演奏时,每一个音符都要考虑前面所有音符的影响。根据DeepMind的测试结果,WaveNet生成的语音在自然度评分上达到4.21分(满分5分),首次超越了传统语音合成系统。
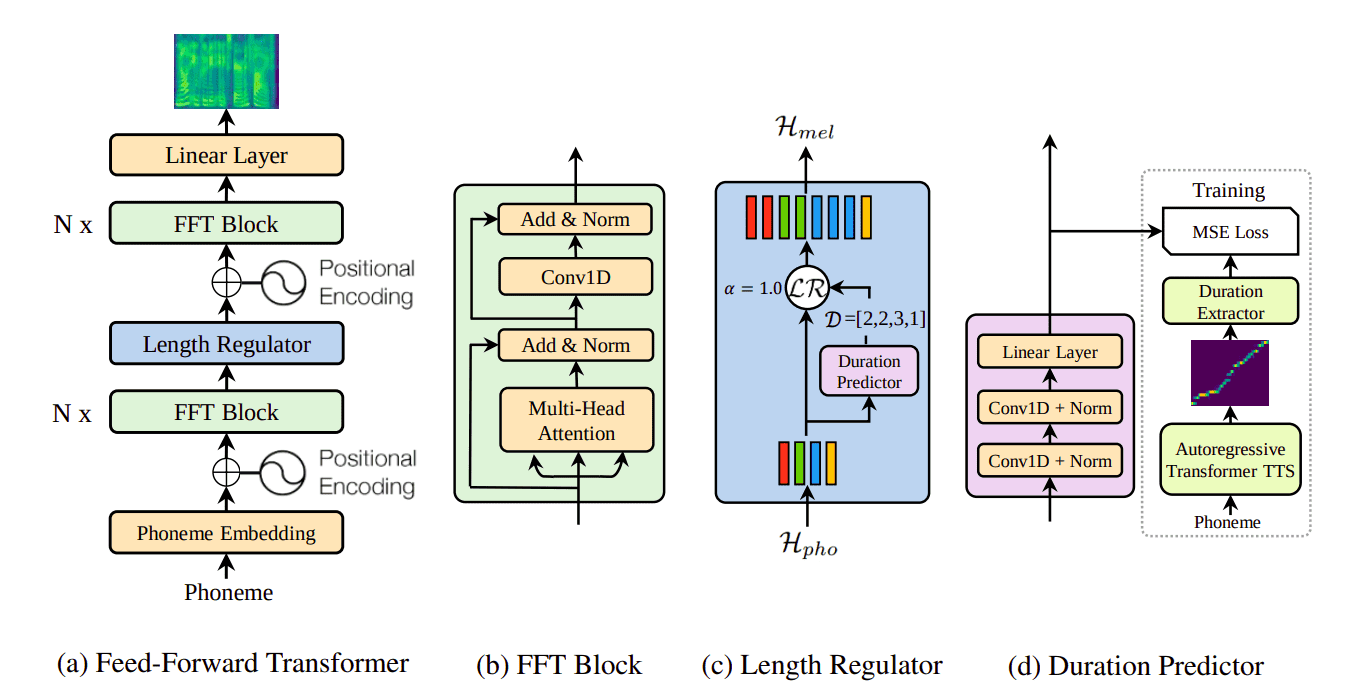
FastSpeech:速度与质量的完美平衡
然而,WaveNet的高质量是以牺牲速度为代价的。生成一秒钟的语音可能需要几分钟的计算时间。这就像是一位画家虽然能画出精美的作品,但速度太慢,无法满足实时对话的需求。
FastSpeech的出现解决了这个问题。通过采用并行生成策略而非串行生成,FastSpeech将语音合成速度提升了270倍,同时还保持了接近Tacotron的音质。这种技术突破使得实时语音合成成为可能。
端到端的智能对话系统
现代语音技术的发展趋势是端到端(End-to-End)系统的兴起。传统的语音处理流水线包含多个独立的模块:语音识别、自然语言理解、对话管理、自然语言生成、语音合成等。每个模块都可能引入误差,最终积累成系统性的性能下降。
混合CTC/注意力架构
最新的研究表明,混合CTC/注意力架构在端到端语音识别中表现出色。这种架构结合了CTC在对齐方面的优势和注意力机制在建模长依赖关系方面的能力。在LibriSpeech数据集上的测试显示,这种混合架构比单独使用任一技术的准确率都要高出5-10%。
跨语言的智能桥梁
语音翻译代表了语音技术的最新前沿。想象一下,你用中文说话,系统不仅要"听懂"你在说什么,还要理解其含义,然后用流利的英语"说"出来。这个过程涉及语音识别、机器翻译和语音合成三个复杂的AI任务。
Meta的SeamlessM4T是这一领域的代表作品。这个系统支持近100种语言的语音和文本翻译,延迟时间仅为2秒左右。在实际测试中,该系统在常见语言对之间的翻译质量已经接近专业人工翻译水平。
实践中的技术实现
对于想要动手实践的开发者来说,PyTorch和TensorFlow都提供了丰富的预训练模型和工具包。以下是一些关键的实现要点:
特征提取方面:现代深度学习模型通常直接从原始音频波形学习特征,而不再依赖手工设计的MFCC特征。这种端到端的学习方式能够发现人类无法察觉的音频模式。
模型架构选择:对于实时应用,建议使用基于CNN的轻量级模型;对于高精度要求的应用,可以选择基于Transformer的大型模型。
数据增强技术:通过添加噪声、改变说话速度、调整音调等方式来增强训练数据,可以显著提升模型的鲁棒性。
技术发展的挑战与机遇
尽管语音技术已经取得了显著进展,但仍然面临着诸多挑战。方言和口音的识别仍然是一个难题——同样的中文,北京话和广东话在声学特征上存在巨大差异。噪声环境下的语音识别准确率也有待提升——在嘈杂的餐厅或车站,人类尚且需要集中注意力才能听清对话,更何况是机器。
情感表达是另一个重要的发展方向。目前的语音合成系统虽然能够生成自然流畅的语音,但在表达情感方面还显得较为机械。未来的发展趋势是让机器不仅能够"说话",还能够带着情感去"表达"。
展望未来的智能语音世界
随着计算能力的不断提升和算法的持续优化,我们正在迈向一个更加智能的语音交互时代。在不久的将来,我们可能会看到:
- 能够实时理解和翻译任意语言的通用语音助手
- 具备情感理解和表达能力的个性化语音系统
- 在极端噪声环境下仍能准确工作的鲁棒语音识别技术
- 能够模拟任何人声音特征的高保真语音合成技术
这些技术的发展不仅会改变我们与机器的交互方式,更会为教育、医疗、娱乐等各个领域带来革命性的变化。当机器真正学会"听懂"和"说话"时,人工智能将变得更加贴近人类,成为我们生活中不可或缺的智能伙伴。
语音识别与合成技术的发展历程,就像是人类在数字世界中重新发明"语言"的过程。从最初简单的声音识别,到今天能够进行自然对话的智能系统,每一步进展都见证着人工智能向更高智能水平的迈进。在这个充满可能性的技术领域里,每一次突破都在让机器变得更加"人性化",让人工智能真正走进我们的日常生活。