在机器学习的世界里,有这样一个令人头疼的问题:我们总是渴望拥有大量标记好的数据来训练模型,但现实往往事与愿违。想象一下,你是一位刚入职的数据科学家,老板交给你一个任务:用公司的邮件数据训练一个垃圾邮件分类器。你兴冲冲地打开数据库,却发现面前有100万封邮件,但其中只有1000封被人工标记为"垃圾邮件"或"正常邮件"。
网页版:https://oronecpf.gensparkspace.com/
视频版:https://www.youtube.com/watch?v=ESI9fh0OpLU
音频版:https://notebooklm.google.com/notebook/6931ae50-c256-4a90-b806-1a7e3559801c/audio
这种情况在现实中比比皆是。医疗影像诊断需要专业医生标注,自动驾驶需要工程师逐帧标记物体,语音识别需要语言学家转录文本。标记数据的过程不仅耗时费力,还需要专业知识,成本高昂。但是,未标记的数据却触手可得,仿佛在对我们说:"我们就在这里,快来利用我们吧!"
这就是半监督学习诞生的背景。它就像一位智慧的老师,不仅能从少量的标记样本中学习,还能从大量未标记的数据中挖掘出有价值的信息。今天,让我们一起踏上这段探索之旅,了解半监督学习是如何在数据稀缺的世界中发挥智慧的。
半监督学习的哲学思考
在深入技术细节之前,我们先来思考一个哲学问题:未标记的数据真的有用吗?这个问题的答案隐藏在半监督学习的核心假设中,就像探索未知世界的指南针。
平滑性假设(Smoothness Assumption):如果两个数据点在输入空间中很接近,那么它们的标签应该是相同的。这个假设告诉我们,数据的分布不是随机的,而是有某种内在的连续性。
想象你正在学习识别不同品种的花朵。如果你看到两朵花在颜色、形状、大小等方面都很相似,那么它们很可能是同一品种。即使其中一朵没有标签,你也可以通过另一朵有标签的花来推断它的品种。
聚类假设(Cluster Assumption):属于同一聚类的数据点应该有相同的标签。这意味着决策边界应该穿过数据密度较低的区域。
这个假设更加直观。如果你在一个花园里看到玫瑰都聚集在一个区域,牡丹聚集在另一个区域,那么新发现的一朵花很可能属于它所在区域的主导品种。
流形假设(Manifold Assumption):高维数据实际上位于低维流形上,在同一流形上的数据点应该有相同的标签。
这个假设最为抽象,但也最为深刻。它告诉我们,看似复杂的高维数据实际上遵循着某种简单的低维结构。就像地球表面看起来是二维的,但实际上是三维球体的表面一样。
基于这些假设,半监督学习发展出了多种巧妙的算法,每一种都有其独特的思路和应用场景。让我们依次探索这些算法的奥秘。
标签传播:让信息如水流般传递
标签传播算法是半监督学习中最直观、最优雅的方法之一。它的核心思想就像在平静的湖面上投下一颗石子,涟漪会逐渐扩散到整个湖面。
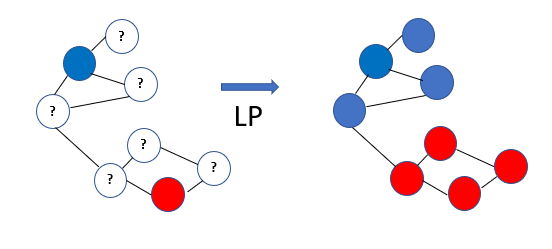
标签传播算法:信息如涟漪般在数据图中传播
想象你是一个小镇的邮递员,需要给每家每户送信。有些房子的门牌号清晰可见(标记数据),有些则模糊不清(未标记数据)。你的任务是推断出所有房子的门牌号。标签传播算法就像一个聪明的邮递员,它会根据邻居房子的门牌号来推断模糊房子的号码。
标签传播算法步骤:
- 构建图结构:将每个数据点看作图中的一个节点,根据相似度连接节点
- 初始化标签:已标记的数据点保持原有标签,未标记的数据点标签设为0
- 迭代传播:每个节点的标签根据邻居节点的标签进行更新
- 收敛判断:重复迭代直到标签分布稳定
这个算法的美妙之处在于它的简洁性。标签传播不需要复杂的数学推导,却能够有效地利用数据的内在结构。在实际应用中,它特别适合处理图像分割、社交网络分析等具有明显空间或关系结构的问题。
然而,标签传播也有其局限性。它假设相似的数据点应该有相同的标签,但在现实中,这个假设并不总是成立。比如在欺诈检测中,欺诈者可能会故意模仿正常用户的行为,使得欺诈和正常交易在特征空间中很接近。
自训练:让模型成为自己的老师
如果说标签传播是一个集体智慧的过程,那么自训练就是一个个体成长的故事。它就像一个勤奋的学生,通过不断地自我测试和学习来提高自己的能力。
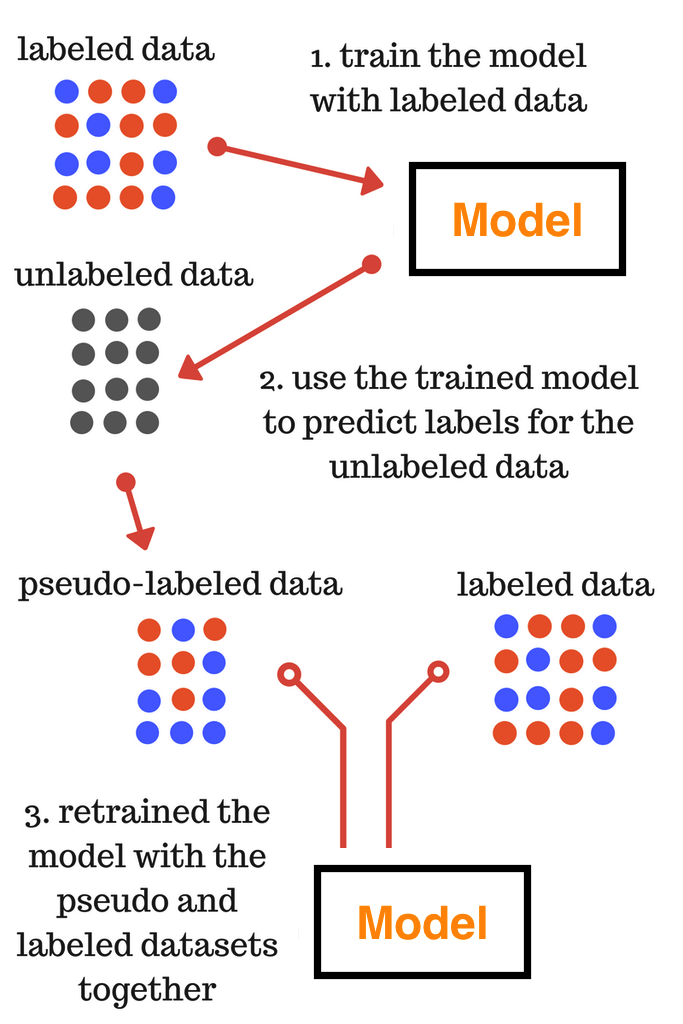
自训练算法:模型通过自我学习不断提升
想象你正在学习一门新的语言。最开始,你只认识一些基本单词(标记数据)。但是通过阅读大量的文章(未标记数据),你开始能够猜测一些不认识单词的意思。如果你对某个单词的意思很确定,你就会把它加入到你的词汇表中。这样,你的词汇量会越来越大,理解能力也会越来越强。
自训练算法步骤:
- 初始训练:使用标记数据训练一个基础分类器
- 预测标签:用训练好的模型对未标记数据进行预测
- 筛选高置信度样本:选择预测置信度高的样本作为伪标签
- 扩充训练集:将伪标签样本加入原始训练集
- 重新训练:在扩充后的训练集上重新训练模型
- 迭代优化:重复上述过程直到收敛
自训练的关键在于置信度的选择。就像学习语言时,你不会把每个猜测的单词都加入词汇表,而是只选择那些你很确定意思的单词。在机器学习中,这个"确定性"通常用概率来衡量。
自训练算法的一个重要优势是它的通用性。几乎任何监督学习算法都可以被包装成自训练算法。无论是决策树、支持向量机还是神经网络,都可以通过自训练来利用未标记数据。
但是,自训练也面临着一个重要问题:错误传播。如果模型在早期阶段产生了错误的伪标签,这些错误会在后续的训练中被放大,就像谣言在传播过程中会越传越离谱。为了缓解这个问题,研究者们提出了各种正则化和去噪技术。
协同训练:三人行,必有我师
协同训练体现了"三人行,必有我师"的智慧。它不是依靠单一的模型来学习,而是让多个模型相互协作,彼此学习,共同成长。这种方法特别适合处理具有多个视角或特征集合的数据。
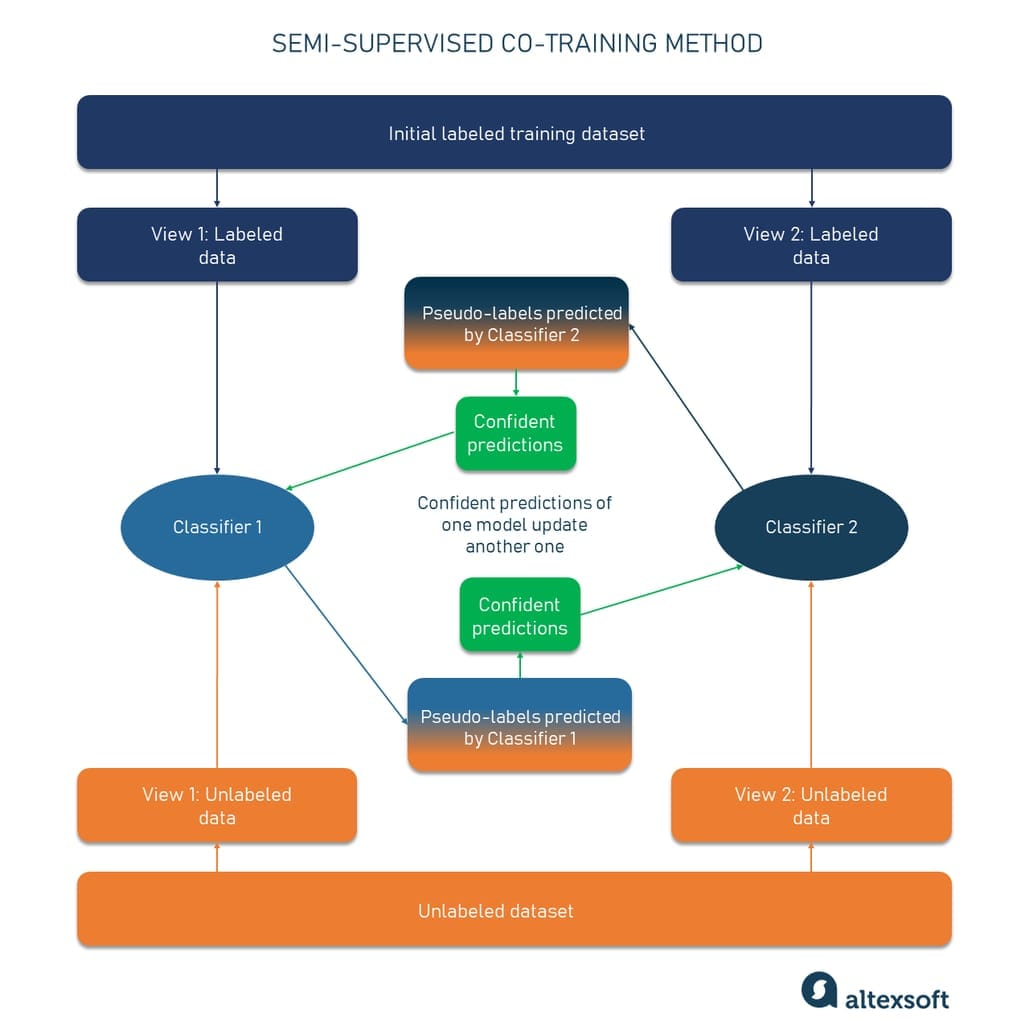
协同训练:多个模型从不同视角学习,相互协作
想象你和朋友一起看电影。你更擅长理解剧情和对话,而朋友更擅长观察画面和特效。看完电影后,你们互相分享各自的理解和感受,这样每个人都能获得更全面的观影体验。协同训练就是这样一个过程,不同的模型从不同的角度观察数据,然后分享他们的"见解"。
协同训练算法步骤:
- 特征分割:将特征空间分割成多个互补的视图
- 独立训练:在每个视图上训练独立的分类器
- 相互预测:每个分类器对未标记数据进行预测
- 交换标签:分类器之间交换高置信度的预测结果
- 更新模型:使用新的伪标签重新训练各个分类器
- 迭代改进:重复交换和更新过程
协同训练的核心假设是不同视图之间的条件独立性。也就是说,在给定真实标签的情况下,不同视图提供的信息应该是独立的。这个假设在许多实际应用中都能得到满足。
比如在网页分类中,我们可以将网页的文本内容作为一个视图,将网页的链接结构作为另一个视图。在语音识别中,我们可以将音频特征作为一个视图,将语言模型作为另一个视图。协同训练通过这种多视角的学习方式,能够更好地挖掘数据中的信息。
协同训练的一个重要优势是它能够减少过拟合的风险。由于不同的模型从不同的角度学习,它们的错误往往是不相关的,因此通过相互协作可以互相纠正错误。这就像多个专家会诊,能够提高诊断的准确性。
生成式半监督学习:创造中的智慧
生成式半监督学习是最令人着迷的方法之一。它不仅要学会分类,还要学会"创造"。这种方法的核心思想是:如果一个模型能够生成逼真的数据,那么它一定对数据的内在结构有着深刻的理解。
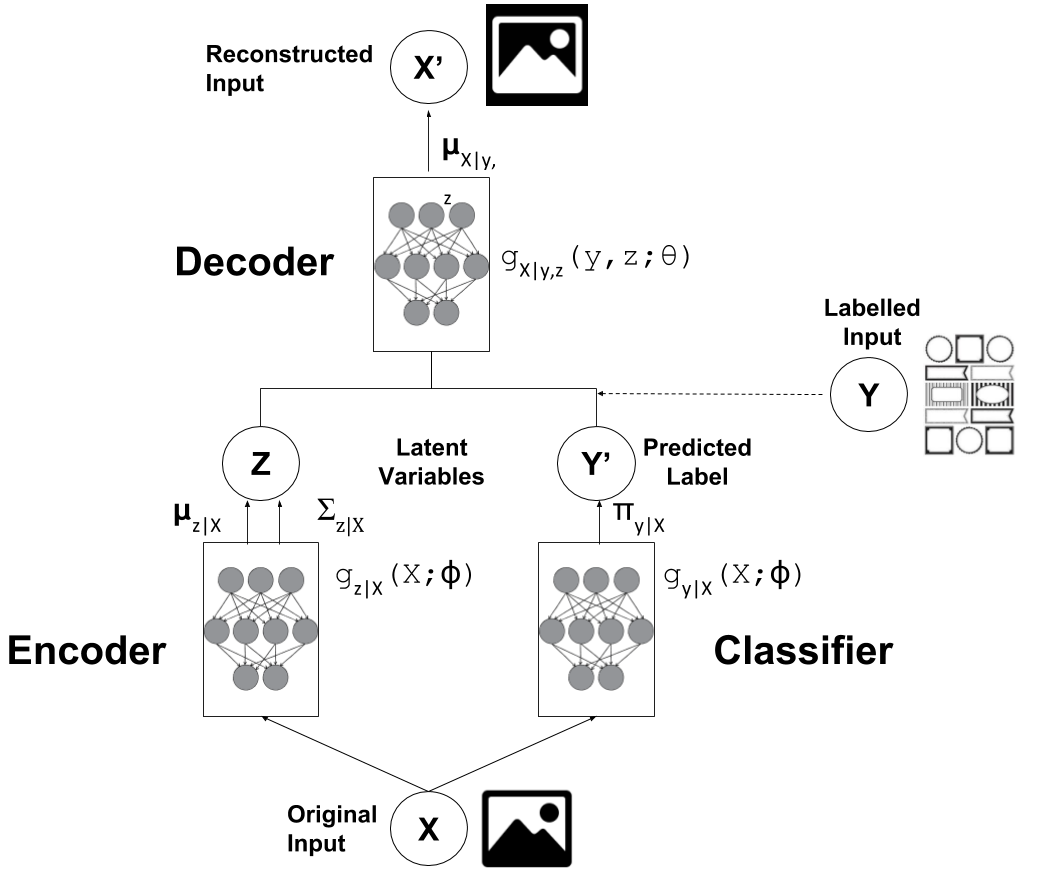
生成式半监督学习:通过生成模型理解数据结构
想象你是一位艺术家,要学会画不同风格的画。传统的方法是看大量的画作样本,然后学会分辨不同的风格。但是生成式方法不同,它要求你不仅要会分辨,还要会创作。当你能够画出各种风格的画时,你对这些风格的理解一定比仅仅会分辨的人更深刻。
在机器学习中,生成式半监督学习通常使用变分自编码器(VAE)或生成对抗网络(GAN)等生成模型。这些模型试图学习数据的潜在表示,然后通过这个表示来进行分类。
生成式半监督学习的关键思想:
- 联合学习:同时学习数据的生成分布和判别边界
- 潜在表示:通过学习数据的潜在表示来提高分类性能
- 正则化效应:生成任务对判别任务起到正则化作用
- 数据增强:通过生成新样本来扩充训练集
生成式半监督学习的一个重要优势是它能够学习到数据的深层结构。传统的判别式方法只关注决策边界,而生成式方法试图理解整个数据分布。这种更深层的理解往往能够带来更好的泛化性能。
在实际应用中,生成式半监督学习在图像分类、语音识别、自然语言处理等领域都取得了显著的成果。特别是在数据量较小的情况下,生成式方法往往能够表现出更好的性能。
实践中的智慧:选择合适的算法
面对这么多的半监督学习算法,你可能会问:在实际应用中,我应该选择哪种算法呢?这个问题没有标准答案,因为每种算法都有其适用的场景和局限性。
如果你的数据具有明显的空间结构或关系结构,比如图像分割或社交网络分析,标签传播可能是一个好的选择。它简单直观,计算效率高,而且往往能够取得不错的效果。
如果你有一个现成的监督学习模型,并且希望快速地将其扩展到半监督场景,自训练是一个很好的选择。它的实现简单,适用性广,而且可以与任何基础分类器结合使用。
如果你的数据具有多个不同的视角或特征集合,协同训练可能是最佳选择。它能够充分利用不同视角的信息,提高模型的鲁棒性和准确性。
如果你的数据量较小,或者你希望对数据有更深层的理解,生成式半监督学习可能是最合适的方法。虽然它的计算复杂度较高,但往往能够取得更好的泛化性能。
未来的展望:半监督学习的新天地
半监督学习作为机器学习的一个重要分支,正在快速发展。随着深度学习技术的进步,我们看到了许多新的半监督学习方法,比如一致性正则化、混合增强、对抗训练等。
在大数据时代,数据的获取变得越来越容易,但标注数据的成本依然很高。半监督学习为我们提供了一种有效的解决方案,让我们能够在有限的标注数据下训练出高质量的模型。
随着人工智能在各个领域的应用越来越广泛,半监督学习的重要性也日益凸显。在医疗诊断、自动驾驶、语音识别、自然语言处理等领域,半监督学习都有着广阔的应用前景。
更重要的是,半监督学习体现了一种重要的学习哲学:我们不仅要从已知中学习,还要从未知中汲取智慧。这种思想不仅适用于机器学习,也适用于人类的学习和认知过程。
结语:在数据稀缺中寻找智慧
回到文章开头的那个场景:面对100万封邮件和1000个标签,我们不再感到绝望。通过半监督学习,我们可以让算法从这99万9千封未标记的邮件中学到宝贵的知识,从而训练出一个高质量的垃圾邮件分类器。
半监督学习教会我们一个重要的道理:在这个数据爆炸的时代,真正的智慧不在于拥有更多的标记数据,而在于如何从有限的标记数据和丰富的未标记数据中提取最大的价值。
正如一位智者所说:"授人以鱼,不如授人以渔。"半监督学习就是这样一种"渔"的技术,它让我们在数据的海洋中,用有限的"鱼"(标记数据)学会捕捉更多的"鱼"(知识和洞察)。
在这个充满挑战和机遇的时代,半监督学习为我们打开了一扇通往智慧的大门。让我们携手前行,在数据稀缺中寻找智慧,在未知中发现真理,在学习中成长。
愿每一位读者都能在自己的学习和工作中,运用半监督学习的思想,从有限的已知中挖掘无限的可能,在数据的世界里发现更多的美好和智慧。