还记得小时候玩的那个游戏吗?老师在黑板上画几个简单的线条,我们立刻就能喊出"房子!"。那时候觉得这是世界上最自然不过的事情,直到长大后才发现,让计算机做到这一点,竟然如此困难。
这就是我与卷积神经网络(CNN)的初次相遇。它就像一个模仿人类视觉系统的魔法师,能够从混乱的像素中发现秩序,从抽象的数字中识别出具体的图像。今天,让我们一起踏上这场关于视觉智能的奇妙旅程。
网页版:https://tywqkhtr.gensparkspace.com/
视频版:https://www.youtube.com/watch?v=aXIjeI1l1E4
音频版:https://notebooklm.google.com/notebook/4cb30a52-fca8-4c33-afe0-b0e2a02e3715/audio
一个关于模式识别的故事
想象一下,你正在教一个从未见过世界的孩子如何识别物体。你会怎么做?
你可能会先教他认识最基本的形状:直线、曲线、角度。然后逐渐组合这些简单的元素,形成更复杂的图案:窗户是由直线组成的方形,房子是三角形屋顶加上方形墙体。这正是CNN的工作原理——从简单到复杂,层层递进。

根据DataCamp的研究,CNN的灵感直接来源于人类的视觉皮层。我们的大脑中有专门负责检测边缘的神经元,有专门识别形状的神经元,还有专门处理复杂图案的神经元。CNN巧妙地模仿了这种层次化的处理方式。
卷积层:世界上最专业的"放大镜"
卷积层就像一个携带着各种"放大镜"的侦探,每个放大镜都有自己的专长。有的专门寻找水平线条,有的擅长发现垂直边缘,还有的专门检测曲线。
让我们用一个具体的例子来理解这个过程。假设我们有一张28×28像素的手写数字图片(这正是著名的MNIST数据集中图片的尺寸)。卷积层会用一个3×3的小窗口(我们称之为卷积核或过滤器)在整张图片上滑动,就像用放大镜仔细检查每一个角落。

每当这个3×3的窗口覆盖图片的一部分时,它会进行数学运算(具体来说是逐元素相乘然后求和),得到一个数值。这个数值反映了当前位置与该过滤器所寻找的模式的匹配程度。如果匹配度高,数值就大;匹配度低,数值就小。
根据TensorFlow官方教程的数据显示,在CIFAR-10数据集上,一个简单的CNN在仅仅10个训练周期后就能达到71.6%的准确率。这个成绩对于一个只有几层的网络来说相当令人印象深刻。
池化层:智慧的"总结大师"
如果说卷积层是细心的侦探,那么池化层就是智慧的总结大师。它的任务是对卷积层收集到的大量信息进行筛选和压缩,保留最重要的特征,同时减少数据量。
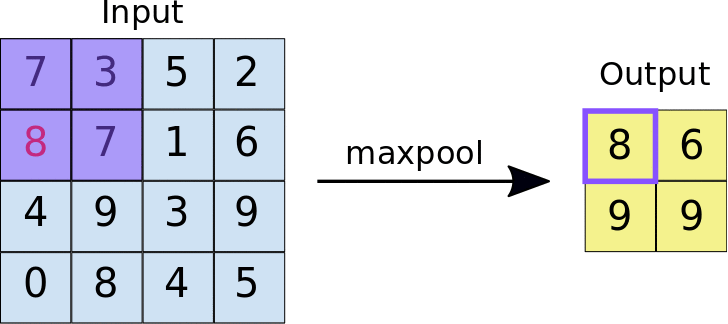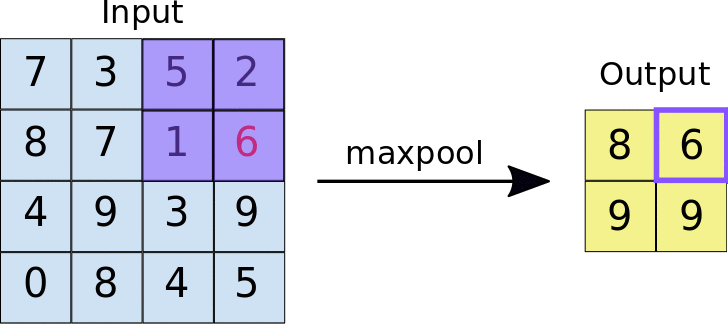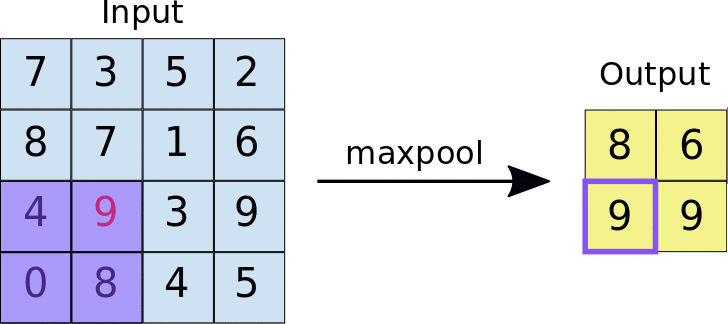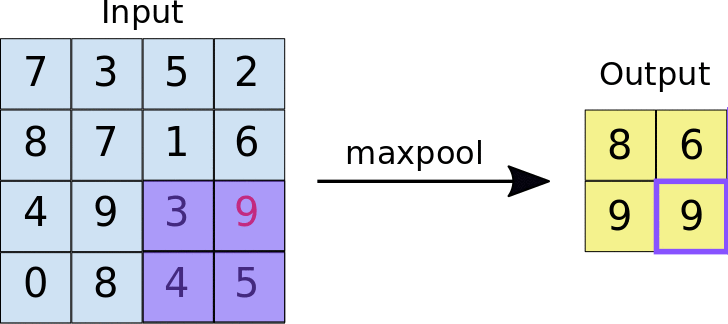
最常用的池化方式是最大池化(Max Pooling)。想象一下,你正在整理一堆考试成绩,每4个成绩为一组,然后只保留每组中的最高分。这就是最大池化的工作原理——它会在每个2×2的区域中选择最大的数值,丢弃其他三个。
这样做有什么好处呢?首先,它大大减少了数据量,让后续的计算更加高效。根据GeeksforGeeks的分析,一个2×2的最大池化操作可以将特征图的尺寸减小到原来的四分之一。其次,它增强了网络的鲁棒性,使得即使图像稍有平移或变形,网络依然能够正确识别。
全连接层:最终的"决策者"
经过层层卷积和池化操作后,图像已经被转换成了一系列高度抽象的特征。现在轮到全连接层登场了——它就像一个经验丰富的法官,需要根据这些证据做出最终判决。
全连接层会将所有的特征"摊平"成一个长向量,然后通过复杂的权重计算,得出每个可能类别的概率分数。对于MNIST数字识别任务,它需要输出10个概率值,分别对应数字0到9。
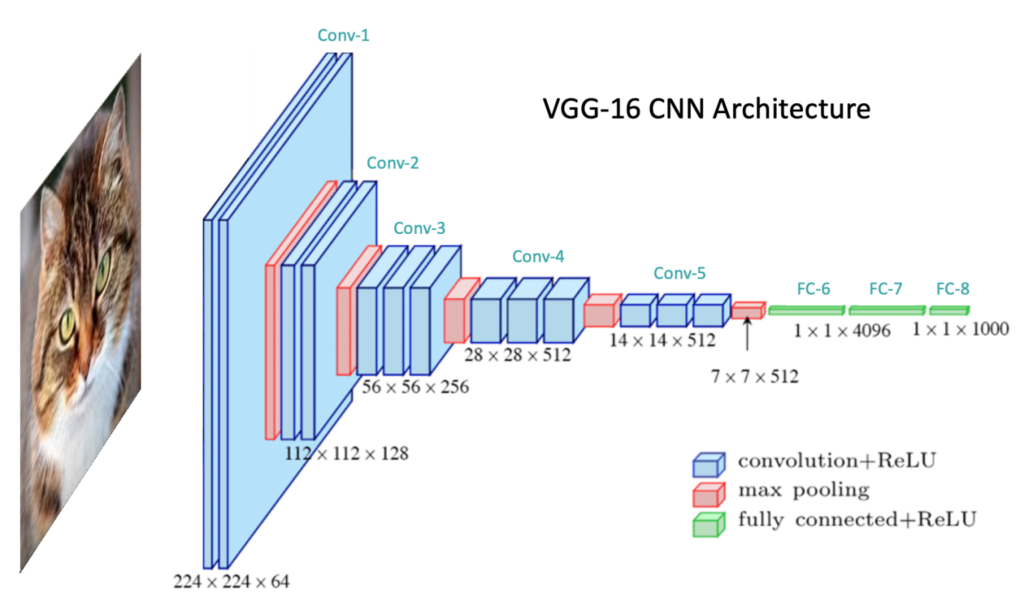
PyTorch实现:让理论变成现实
理论听起来很美好,但真正让我兴奋的是看到它们在代码中变成现实。让我们用PyTorch来实现一个简单而有效的CNN。
根据Nextjournal的实战教程,我们可以构建一个包含两个卷积层和两个全连接层的网络:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
# 第一个卷积层:1个输入通道,32个输出通道,3x3卷积核
self.conv1 = nn.Conv2d(1, 32, 3, 1)
# 第二个卷积层:32个输入通道,64个输出通道,3x3卷积核
self.conv2 = nn.Conv2d(32, 64, 3, 1)
# Dropout层用于防止过拟合
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
# 全连接层
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
# 第一个卷积+ReLU+最大池化
x = self.conv1(x)
x = F.relu(x)
# 第二个卷积+ReLU+最大池化
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
# 展平特征图
x = torch.flatten(x, 1)
# 全连接层
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
这个网络结构看似简单,但在MNIST数据集上仅仅训练3个周期就能达到97%的准确率。这个数字背后蕴含着深刻的含义——它说明了CNN架构的强大表达能力。
TensorFlow的实现之美
如果说PyTorch以其动态图的灵活性著称,那么TensorFlow则以其完整的生态系统和部署便利性闻名。让我们看看同样的CNN在TensorFlow中是如何实现的:
import tensorflow as tf
from tensorflow.keras import layers, models
# 构建模型
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10)
])
# 编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
TensorFlow的Keras API让模型构建变得极其简洁。根据TensorFlow官方文档的测试结果,这个模型在CIFAR-10数据集上训练10个周期后,测试准确率可以达到71.63%。
参数的魔法:Padding、Stride和Kernel Size
CNN的魅力不仅在于其架构的巧妙,更在于参数调整的艺术性。每一个参数的改变都会对模型性能产生微妙而深远的影响。
**卷积核大小(Kernel Size)**的选择就像选择合适的画笔。3×3的小卷积核善于捕捉细节,就像细笔适合勾勒轮廓;5×5或7×7的大卷积核则能够感知更大范围的特征,如同宽笔适合大面积渲染。研究表明,现代CNN架构普遍偏爱3×3卷积核,因为多个小卷积核的组合既能保持感受野的大小,又能减少参数数量。
**步幅(Stride)**决定了卷积核移动的步长。步幅为1意味着精细扫描,不放过任何细节;步幅为2则相当于跳跃式前进,快速缩小特征图尺寸。根据深度学习教程网站的分析,合理的步幅设置可以在保持性能的同时显著减少计算量。
**填充(Padding)**则像是给图像加上保护边框。零填充(Zero Padding)可以确保边缘像素也能被充分利用,防止特征图过快缩小。这个看似简单的技巧,实际上对维持深层网络的性能至关重要。
可视化的奇迹:看见CNN在"思考"
最让我震撼的是第一次看到CNN内部工作过程的可视化。那些原本抽象的卷积操作突然变得生动具体,就像透过显微镜观察细胞分裂一样令人兴奋。

CNN Explainer是一个革命性的可视化工具,它让我们能够实时观察CNN的每一层是如何处理图像的。你可以上传一张图片,然后看着它在网络中的旅程:从原始像素到边缘检测,从局部特征到全局模式,最终形成分类结果。
更有趣的是,不同层的卷积核学会了识别不同层次的特征。第一层的卷积核通常学会了检测简单的边缘和纹理;第二层开始组合这些基本特征,形成更复杂的图案;而更深的层则能够识别出完整的物体部件,比如眼睛、鼻子或者车轮。
MNIST实战:从理论到实践的完美诠释
MNIST手写数字识别被誉为计算机视觉领域的"Hello World",它的重要性不仅在于其简单易懂,更在于它完美展示了CNN的核心能力。
这个数据集包含70,000张28×28像素的灰度图像,其中60,000张用于训练,10,000张用于测试。每张图像都是一个手写数字(0-9),看似简单,但其中蕴含的变化却异常复杂:不同的书写风格、倾斜角度、粗细变化、甚至是扫描噪声。
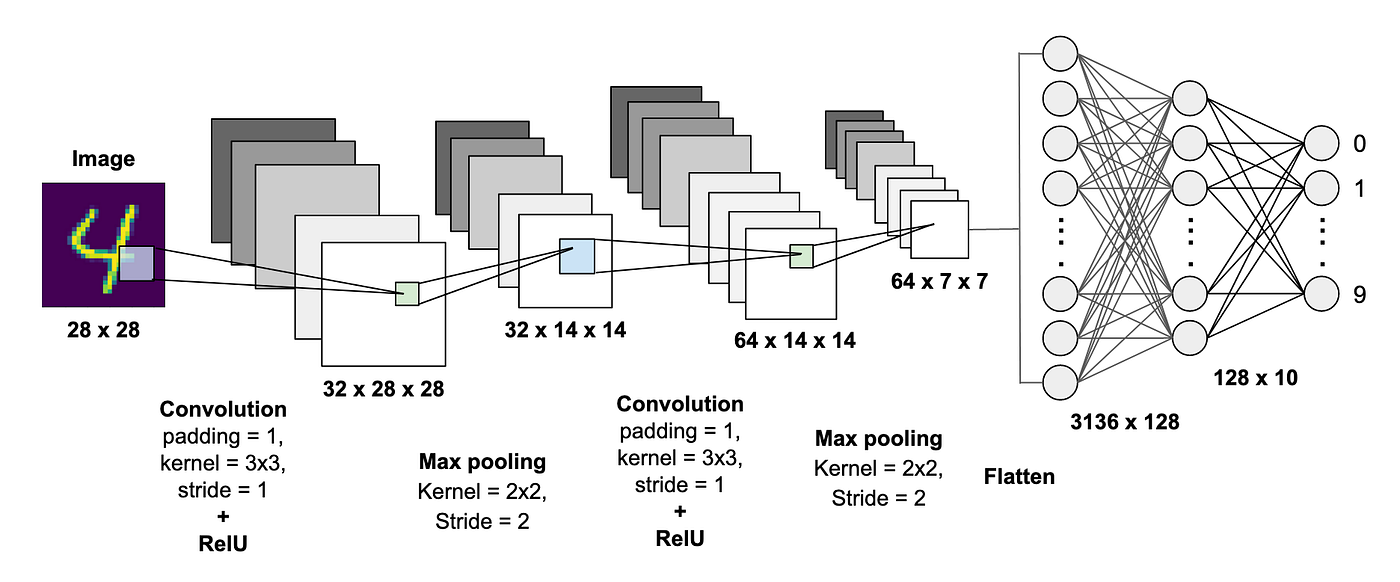
让我们分析一下CNN在这个任务上的表现数据。根据Machine Learning Mastery的深度分析,一个基础的CNN架构通常能够达到以下性能指标:
- 训练准确率:通常在10个周期后超过99%
- 测试准确率:稳定维持在98-99%之间
- 训练时间:在现代GPU上通常不超过5分钟
- 模型大小:通常小于10MB,便于部署
这些数字背后反映了CNN相比传统机器学习方法的巨大优势。在CNN出现之前,MNIST的最佳成绩停留在95%左右,而且需要大量的手工特征工程。CNN的出现彻底改变了这一局面。
超越MNIST:CNN的广阔应用天地
虽然MNIST是一个优雅的入门案例,但CNN的真正威力在更复杂的现实应用中才得以完全展现。
在医学影像领域,CNN已经能够在某些疾病诊断上超越人类专家的准确率。Google的研究团队开发的糖尿病视网膜病变检测系统,准确率达到了90%以上,而且处理速度比人类医生快数百倍。这意味着在医疗资源匮乏的地区,AI可以为更多患者提供及时的初步诊断。
在自动驾驶领域,CNN是实现环境感知的核心技术。特斯拉的Autopilot系统每天处理数百万英里的行驶数据,其中CNN负责识别道路标志、行人、车辆等关键目标。根据特斯拉公布的数据,启用Autopilot的车辆事故率比人类驾驶员低约10倍。
性能优化的艺术
让CNN达到最佳性能需要在多个维度上进行细致的调优,这更像是一门艺术而非科学。
数据增强是提升模型泛化能力的重要手段。通过随机旋转、缩放、翻转训练图像,我们可以人为地扩大数据集规模。研究显示,适当的数据增强可以将模型准确率提升2-5个百分点,这在竞争激烈的应用场景中往往是决定性的优势。
正则化技术则是防止过拟合的利器。Dropout技术通过随机"关闭"一部分神经元,迫使网络学习更加鲁棒的特征表示。Batch Normalization则通过标准化每一层的输入,加快了训练速度并提升了模型稳定性。根据DataCamp的综合分析,合理使用这些技术可以将训练时间缩短30-50%。
学习率调度的重要性经常被初学者忽视。一个好的学习率调度策略可以让模型在训练初期快速收敛,在后期精细调优。余弦退火、阶梯衰减等策略在不同场景下都有其独特价值。
框架选择的智慧
PyTorch和TensorFlow作为当今最主流的深度学习框架,各有其独特优势。选择合适的框架往往决定了项目的成败。
PyTorch以其动态计算图和Pythonic的设计哲学赢得了研究社区的青睐。Facebook、OpenAI等顶级研究机构都将PyTorch作为首选框架。其即时执行的特性让调试变得异常便利,特别适合快速原型开发和算法研究。
TensorFlow则在生产部署方面具有无可比拟的优势。Google的强大生态系统支持让TensorFlow模型可以轻松部署到移动设备、Web浏览器,甚至是边缘计算设备。TensorFlow Lite、TensorFlow.js等衍生产品进一步扩展了其应用边界。
根据Stack Overflow 2023年的开发者调查,在深度学习框架使用率上,TensorFlow以42.3%位居第一,PyTorch以39.1%紧随其后。这个数据反映了两个框架在不同应用场景下的分工:TensorFlow主导产业应用,PyTorch引领学术研究。
未来展望:CNN的进化之路
站在今天回望CNN的发展历程,我们见证了从LeNet-5到ResNet,从AlexNet到EfficientNet的技术跃迁。每一次架构创新都带来了性能的显著提升和应用边界的拓展。
Vision Transformer(ViT)的出现为计算机视觉带来了新的可能性。虽然Transformer最初是为自然语言处理设计的,但其在图像处理任务上的表现同样令人印象深刻。这种跨模态的技术迁移体现了深度学习领域的融合趋势。
自监督学习正在重新定义我们对标注数据的依赖。通过巧妙的预训练任务设计,模型可以从无标签数据中学习到丰富的视觉表示。这为解决数据稀缺问题提供了新的思路。
神经网络架构搜索(NAS)让网络设计本身也变得可学习。AlphaGo的成功证明了AI在复杂决策任务上的潜力,而NAS则将这种能力应用到了网络架构优化上。未来,我们可能会看到完全由AI设计的网络架构。
结语:一段永不结束的探索之旅
回顾这段CNN的学习之旅,我深深感受到了技术进步的力量。从最初那个简单的"房子"识别问题,到今天能够诊断疾病、驾驶汽车的复杂AI系统,CNN不仅改变了计算机视觉,更重新定义了人机交互的可能性。
但这仅仅是开始。每一个卷积核的设计、每一次参数的调整、每一种新架构的提出,都在推动着我们对视觉智能理解的边界。正如IBM的专家在视频中所说,CNN让计算机能够像人类一样"看见"世界,但它们的潜力远不止于此。
在这个AI快速发展的时代,学习CNN不仅是掌握一种技术,更是参与塑造未来的过程。当我们训练一个模型识别手写数字时,我们实际上是在教会机器理解人类的表达方式;当我们优化网络架构时,我们是在探索智能的本质。
技术的学习永无止境,但正是这种永恒的探索精神,让我们能够不断突破可能性的边界。下一次当你看到一个简单的卷积操作时,也许你会想起这段关于视觉智能的故事,想起那些让像素变成智慧的魔法时刻。