网页版:https://hleqxcyp.gensparkspace.com
视频版:https://www.youtube.com/watch?v=RkxLiFfZggo
音频版:https://notebooklm.google.com/notebook/0b092734-7343-48b8-bc1e-5a416afae249/audio
目录
引言
随着人工智能技术的飞速发展,多模态信息处理已成为当前研究的热点领域。传统的检索系统往往局限于单一模态,难以处理现实世界中复杂多变的信息形式。多模态检索通过融合图像、文本等多种信息源,实现了更加智能和自然的信息获取方式,为知识管理和信息检索带来了革命性的变革。
本文将详细介绍一套完整的多模态检索与文档问答系统,聚焦于图像与文本的联合检索、视觉理解增强及语义标签自动生成等核心技术,并重点关注系统的隐私保护与实时性优化方案。通过这些前沿技术的集成,我们旨在构建一个高效、准确且用户友好的智能检索系统。
多模态检索技术概述
多模态检索技术是一种能够处理并检索多种不同类型数据(如文本、图像、音频、视频等)的先进技术框架。与传统单模态检索系统相比,多模态检索能够同时理解和处理多种信息形式,并在统一的语义空间中建立它们之间的关联。
多模态检索的核心特点:
- 跨模态理解:能够理解不同模态之间的语义联系,如根据文本描述检索相关图像,或根据图像内容生成相应的文本描述
- 联合嵌入学习:通过深度学习模型将不同模态的数据映射到同一语义空间,便于相似性计算
- 多源信息融合:综合利用来自不同模态的信息,提高检索准确性与全面性
- 自适应表征:根据不同任务和用户需求,动态调整各模态信息的权重和重要性
系统架构设计
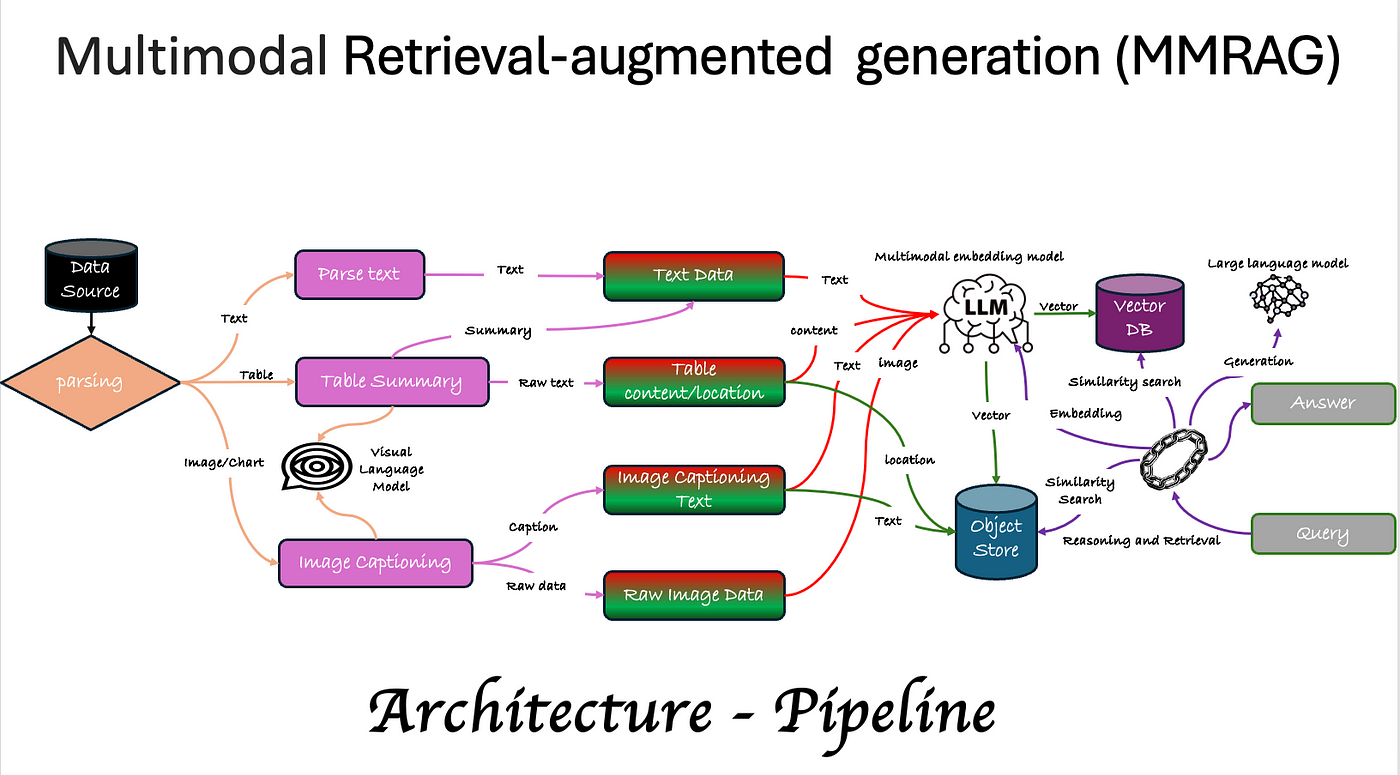
多模态检索与文档问答系统的整体架构设计着眼于高效处理和检索多种模态信息,同时保持系统的可扩展性和灵活性。系统架构主要包括以下几个核心模块:
1. 数据采集与预处理模块
- 多源数据获取:支持从不同来源获取文本、图像等多模态数据
- 数据清洗与规范化:对原始数据进行去噪、格式转换等预处理操作
- 特征提取与增强:从原始数据中提取有效特征,并通过增强技术提高特征质量
2. 多模态嵌入与索引模块
- 联合嵌入模型:将不同模态的数据映射到统一的特征空间
- 向量索引构建:建立高效的向量索引结构,支持快速相似性搜索
- 动态更新机制:支持索引的增量更新,适应数据的实时变化
3. 检索与排序模块
- 多模态查询解析:理解用户输入的多模态查询意图
- 相似度计算:基于嵌入向量计算查询与候选项的相似度
- 排序与重排序:结合多种因素对检索结果进行排序优化
4. 文档问答与推理模块
- 上下文理解:理解问题与相关文档的语境
- 多模态推理:结合文本和视觉信息进行深度推理
- 答案生成:基于检索到的信息生成准确、自然的答案
5. 隐私保护与安全模块
- 数据匿名化:对敏感信息进行脱敏处理
- 访问控制:基于角色的精细权限管理
- 审计日志:记录系统操作,便于安全审计
6. 用户交互与反馈模块
- 自适应界面:根据用户需求和使用场景调整交互方式
- 用户反馈收集:获取用户对系统回答的评价和改进建议
- 持续学习:根据用户反馈不断优化系统表现

核心技术详解
图像-文本联合检索
图像-文本联合检索(Image-Text Joint Retrieval)是多模态检索中的关键技术,它能够同时处理并建立图像和文本之间的语义关联,实现跨模态的信息检索。
技术原理
图像-文本联合检索的核心是构建一个统一的语义空间,在这个空间中,相关的图像和文本被映射到相近的位置。实现这一目标主要依赖以下技术:
-
对比学习(Contrastive Learning):
- 通过最大化相关图像-文本对的相似性,同时最小化不相关对的相似性,学习有效的表示
- 典型的损失函数包括InfoNCE、CLIP损失等
-
跨模态特征提取:
- 图像部分:使用CNN或Vision Transformer等模型提取视觉特征
- 文本部分:使用BERT、RoBERTa等模型提取文本特征
-
联合嵌入(Joint Embedding):
- 设计专门的映射函数,将不同模态的特征投影到共享的语义空间
- 确保相似语义的图像和文本在该空间中的距离较近
实现方案
- 基于CLIP的联合检索:
- 利用预训练的CLIP(Contrastive Language-Image Pre-training)模型对图像和文本进行编码
- 通过余弦相似度计算图像和文本的匹配程度
- 支持图像到文本(I2T)和文本到图像(T2I)的双向检索
# 基于CLIP的图像-文本联合检索示例代码
import torch
from PIL import Image
import clip
# 加载CLIP模型
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
# 准备图像和文本
image = preprocess(Image.open("example.jpg")).unsqueeze(0).to(device)
texts = ["一只猫在草地上", "一只狗在沙滩上", "一辆红色的汽车"]
text_tokens = clip.tokenize(texts).to(device)
# 计算图像和文本特征
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text_tokens)
# 归一化特征
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
# 计算相似度
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)
values, indices = similarity[0].topk(3)
# 输出结果
for value, index in zip(values, indices):
print(f"{texts[index]}: {value.item():.2f}%")
- 基于多分支网络的联合检索:
- 设计专门的图像和文本处理分支
- 使用注意力机制增强跨模态特征的交互
- 采用多任务学习同时优化多个目标
视觉理解增强
视觉理解增强是多模态检索系统中提升图像内容理解能力的关键技术环节,通过结合先进的计算机视觉和深度学习方法,实现对图像内容的深度解析和语义提取。
关键技术
-
细粒度视觉特征提取:
- 区域感知的特征提取:识别并提取图像中的关键区域和对象特征
- 层次化视觉表示:从低级视觉特征到高级语义概念的表示学习
- 多尺度特征融合:结合不同尺度的特征,捕捉图像的局部细节和全局上下文
-
视觉-语言预训练:
- 基于大规模图像-文本对数据进行预训练
- 学习视觉与语言之间的对应关系和语义映射
- 通过自监督学习任务增强模型的迁移能力
-
视觉场景图构建:
- 识别图像中的对象(如人物、物体、背景等)
- 提取对象之间的关系(空间位置、交互方式等)
- 构建结构化的场景表示,便于复杂查询处理
技术实现
基于注意力机制的视觉理解:
# 基于Transformer的视觉理解增强示例代码
import torch
from transformers import ViTFeatureExtractor, ViTModel
# 加载预训练的Vision Transformer模型
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224')
model = ViTModel.from_pretrained('google/vit-base-patch16-224')
# 处理图像
from PIL import Image
image = Image.open('example.jpg')
inputs = feature_extractor(images=image, return_tensors="pt")
# 提取视觉特征
with torch.no_grad():
outputs = model(**inputs)
# 获取[CLS]标记的输出作为图像的全局表示
image_features = outputs.last_hidden_state[:, 0, :]
# 获取所有patch的特征表示,用于细粒度理解
patch_features = outputs.last_hidden_state[:, 1:, :]
多粒度视觉信息提取:
视觉理解增强系统可以同时在多个粒度层次上处理图像信息:
- 全局层面:理解整体场景、风格和氛围
- 对象层面:识别和定位具体物体、人物等实体
- 局部层面:捕捉细节、材质和精细特征
- 关系层面:分析实体间的空间和语义关系
语义标签自动生成
语义标签自动生成是多模态检索系统中的重要组成部分,它能够为图像、文本等多模态内容自动添加高质量的语义标签,大幅提升检索效率和准确性。
技术原理
-
多级标签生成框架:
- 基础标签识别:识别内容中的基本对象、概念和场景
- 关系标签提取:分析内容中实体之间的关系
- 抽象标签推断:基于内容推断更高层次的抽象概念、情感和主题
-
多模态特征融合:
- 早期融合:在特征提取初期就将多模态信息结合
- 晚期融合:分别提取各模态特征后再进行整合
- 混合融合:在网络的不同层次进行特征交互和融合
-
标签优化与过滤:
- 置信度评估:对生成标签的可靠性进行评估
- 语义一致性验证:确保标签之间的语义关系合理
- 冗余过滤:消除重复或高度相关的标签
实现方法
基于多模态预训练模型的标签生成:
# 基于多模态预训练模型的语义标签生成示例代码
from transformers import VisionEncoderDecoderModel, ViTFeatureExtractor, AutoTokenizer
import torch
from PIL import Image
# 加载模型和处理器
model = VisionEncoderDecoderModel.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
feature_extractor = ViTFeatureExtractor.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
tokenizer = AutoTokenizer.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 设置生成参数
max_length = 16
num_beams = 4
gen_kwargs = {"max_length": max_length, "num_beams": num_beams}
# 处理图像并生成标签
def predict_tags_from_image(image_path):
image = Image.open(image_path).convert('RGB')
pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
pixel_values = pixel_values.to(device)
# 生成文本描述
output_ids = model.generate(pixel_values, **gen_kwargs)
preds = tokenizer.batch_decode(output_ids, skip_special_tokens=True)
caption = preds[0].strip()
# 从描述中提取关键词作为标签
import nltk
from nltk.corpus import stopwords
nltk.download('punkt')
nltk.download('stopwords')
words = nltk.word_tokenize(caption.lower())
stop_words = set(stopwords.words('english'))
tags = [word for word in words if word.isalnum() and word not in stop_words]
return list(set(tags)), caption
# 使用示例
image_path = "example.jpg"
tags, caption = predict_tags_from_image(image_path)
print(f"生成的标签: {tags}")
print(f"图像描述: {caption}")
层次化语义标签体系:
一个完善的语义标签生成系统通常采用层次化的标签体系设计:
- 一级标签:基本类别(人物、动物、风景等)
- 二级标签:细分类别(成人、儿童、猫、狗、山脉、海滩等)
- 三级标签:属性特征(微笑、奔跑、晴朗、古典等)
- 关系标签:描述实体间的互动和关系
多模态文档问答系统实现
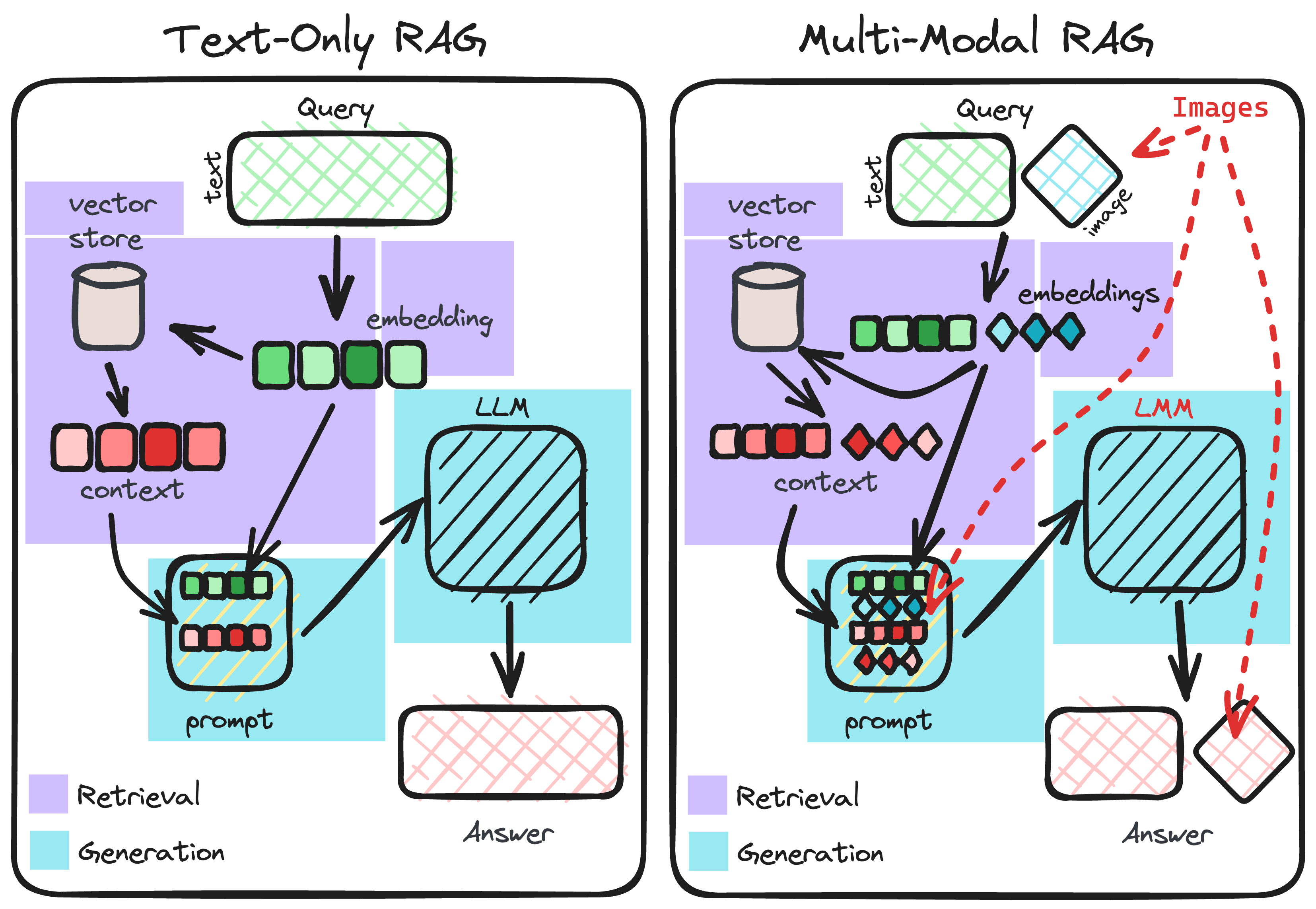
多模态文档问答系统是一种能够理解并回答包含文本、图像等多种模态信息的文档查询的智能系统。这类系统不仅需要处理纯文本文档,还能理解图表、图片中的视觉信息,并将多模态信息整合以提供准确的答案。
系统架构
多模态文档问答系统的典型架构包括以下核心组件:
-
文档处理与索引模块
- 文本提取与规范化
- 图像内容分析与表示
- 多模态特征提取与索引建立
-
查询理解与处理模块
- 意图识别
- 查询改写与扩展
- 多模态查询表示
-
检索与排序模块
- 多级检索策略
- 相关性评分
- 结果重排序
-
答案生成模块
- 上下文理解与融合
- 多模态推理
- 自然语言答案生成

关键技术实现
1. 多模态检索增强生成(Multimodal RAG)
多模态RAG是当前文档问答系统的主流技术范式,它结合了检索和生成两个关键步骤:
# 多模态RAG系统的核心流程伪代码
def multimodal_rag(query, document_collection):
# 1. 查询处理
processed_query = query_processor.process(query)
# 2. 多模态检索
relevant_chunks = retriever.retrieve(processed_query, document_collection)
# 3. 上下文构建
context = context_builder.build(relevant_chunks, query)
# 4. 答案生成
answer = answer_generator.generate(query, context)
# 5. 答案验证与引用
verified_answer = answer_verifier.verify(answer, relevant_chunks)
cited_answer = citation_adder.add_citations(verified_answer, relevant_chunks)
return cited_answer
2. 多模态文档解析与理解
# 多模态文档解析示例代码
from PIL import Image
import pytesseract
from transformers import CLIPProcessor, CLIPModel
import fitz # PyMuPDF
# 加载多模态理解模型
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
def extract_multimodal_content(pdf_path):
# 打开PDF文件
doc = fitz.open(pdf_path)
multimodal_content = []
# 遍历每一页
for page_num, page in enumerate(doc):
# 提取文本内容
text = page.get_text()
if text.strip():
multimodal_content.append({"type": "text", "content": text, "page": page_num})
# 提取图像内容
image_list = page.get_images(full=True)
for img_index, img in enumerate(image_list):
xref = img[0]
base_image = doc.extract_image(xref)
image_bytes = base_image["image"]
# 保存图像并处理
image = Image.open(BytesIO(image_bytes))
# 提取图像中的文本(OCR)
image_text = pytesseract.image_to_string(image)
# 使用CLIP为图像生成视觉特征
inputs = processor(images=image, return_tensors="pt")
image_features = model.get_image_features(**inputs)
multimodal_content.append({
"type": "image",
"content": image,
"ocr_text": image_text,
"features": image_features,
"page": page_num,
"position": img_index
})
return multimodal_content
3. 多模态问答模型
当前多模态文档问答系统大多采用基于大型语言模型的架构,例如GPT-4V、Claude 3 Opus、Gemini Pro等多模态大语言模型,这些模型能够同时理解文本和图像输入,并生成连贯的回答。
# 基于多模态LLM的问答示例代码
from openai import OpenAI
import base64
client = OpenAI()
def encode_image_to_base64(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def multimodal_qa(question, image_path=None, context=None):
messages = [{"role": "system", "content": "你是一个多模态文档问答助手,能够理解文本和图像并提供准确回答。"}]
# 添加用户问题和上下文
user_message = {"role": "user", "content": []}
if context:
user_message["content"].append({"type": "text", "text": f"上下文信息:{context}"})
if image_path:
base64_image = encode_image_to_base64(image_path)
user_message["content"].append(
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
)
user_message["content"].append({"type": "text", "text": f"问题:{question}"})
messages.append(user_message)
# 调用API获取回答
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=messages,
max_tokens=500
)
return response.choices[0].message.content
系统评估与优化
多模态文档问答系统的评估通常从以下几个维度进行:
- 答案准确性:回答的正确程度
- 检索效率:系统从大量文档中找到相关信息的速度
- 多模态理解能力:系统理解和整合不同模态信息的能力
- 鲁棒性:对各种查询和数据质量变化的适应能力
- 可解释性:系统能够解释其回答来源和推理过程的程度
针对这些维度,可以采用以下优化方法:
- 检索优化:使用混合检索策略,结合语义和关键词搜索
- 模型蒸馏:通过知识蒸馏减小模型尺寸,提升推理速度
- 数据增强:使用合成数据扩充训练集,提高多模态理解能力
- 上下文优化:动态调整提供给模型的上下文窗口大小
- 引用追踪:添加来源引用,增强回答的可信度和可追溯性

隐私保护与实时性优化
在多模态检索与文档问答系统中,隐私保护和实时性优化是两个相互制约又缺一不可的关键因素。良好的系统设计需要在两者之间找到平衡点,既能保护用户数据安全,又能提供快速响应的用户体验。
隐私保护机制
1. 数据匿名化与脱敏
多模态系统处理的数据往往包含敏感信息,如人脸、个人身份信息等,需要采取以下措施进行保护:
- 面部模糊化:自动检测并模糊化图像中的人脸区域
- 个人信息脱敏:识别并替换文本中的姓名、电话、地址等敏感信息
- 元数据清理:移除图像和文档中的EXIF数据等元信息
具体实现:
# 图像隐私保护示例代码
import cv2
import numpy as np
def anonymize_face(image_path, output_path):
# 加载图像
image = cv2.imread(image_path)
# 加载人脸检测器
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
# 检测人脸
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.1, 4)
# 对每个检测到的人脸进行模糊处理
for (x, y, w, h) in faces:
face_roi = image[y:y+h, x:x+w]
# 高斯模糊
blurred_face = cv2.GaussianBlur(face_roi, (99, 99), 30)
# 将模糊后的人脸放回原图
image[y:y+h, x:x+w] = blurred_face
# 保存处理后的图像
cv2.imwrite(output_path, image)
return output_path
2. 联邦学习与去中心化计算
为了避免将敏感数据集中存储,系统可以采用联邦学习方式,让模型在用户本地设备上训练,只传输模型更新而非原始数据:
- 边缘计算:将部分处理任务转移到用户设备端执行
- 差分隐私:为模型参数添加随机噪声,保护个体数据隐私
- 安全多方计算:在不泄露原始数据的情况下进行多方数据计算
3. 访问控制与审计机制
- 基于角色的访问控制:根据用户角色分配不同的数据访问权限
- 操作日志记录:记录所有对敏感数据的访问和操作
- 定期安全审计:定期检查系统日志,发现潜在安全风险
实时性优化策略
1. 分布式索引与检索
为了提高大规模多模态数据的检索效率,系统采用分布式索引架构:
- 分片索引:将索引分散到多个节点,支持并行检索
- 倒排索引:针对文本部分建立高效的倒排索引结构
- 近似最近邻搜索:使用HNSW、FAISS等算法加速向量相似度检索
# 使用FAISS进行高效向量检索示例代码
import numpy as np
import faiss
def build_faiss_index(vectors, dimension=512):
"""构建FAISS索引"""
# 向量数量
n = vectors.shape[0]
# 创建索引
# 使用HNSW算法,在M=16的图上搜索
index = faiss.IndexHNSWFlat(dimension, 16)
# 添加向量到索引
index.add(vectors)
return index
def search_similar_items(index, query_vector, k=5):
"""在索引中搜索最相似的k个向量"""
# 确保查询向量是二维的
if query_vector.ndim == 1:
query_vector = query_vector.reshape(1, -1)
# 搜索最近的k个向量
distances, indices = index.search(query_vector, k)