引言
欢迎阅读这篇关于多模态融合技术的深度探索博客!随着人工智能技术的飞速发展,多模态融合已成为推动AI能力边界拓展的关键技术领域。本文将带您深入了解多模态融合机制、视觉-语言对齐技术、跨模态嵌入、图像理解链路以及虚实融合等前沿技术,并探讨迷你多模态理解评测平台的最新进展。
我们精心制作了一个多模态融合技术前沿探索网页,提供更丰富的视觉体验和交互功能。该网页支持导出PDF格式,方便您保存和分享。
1. 多模态融合机制:打破信息孤岛
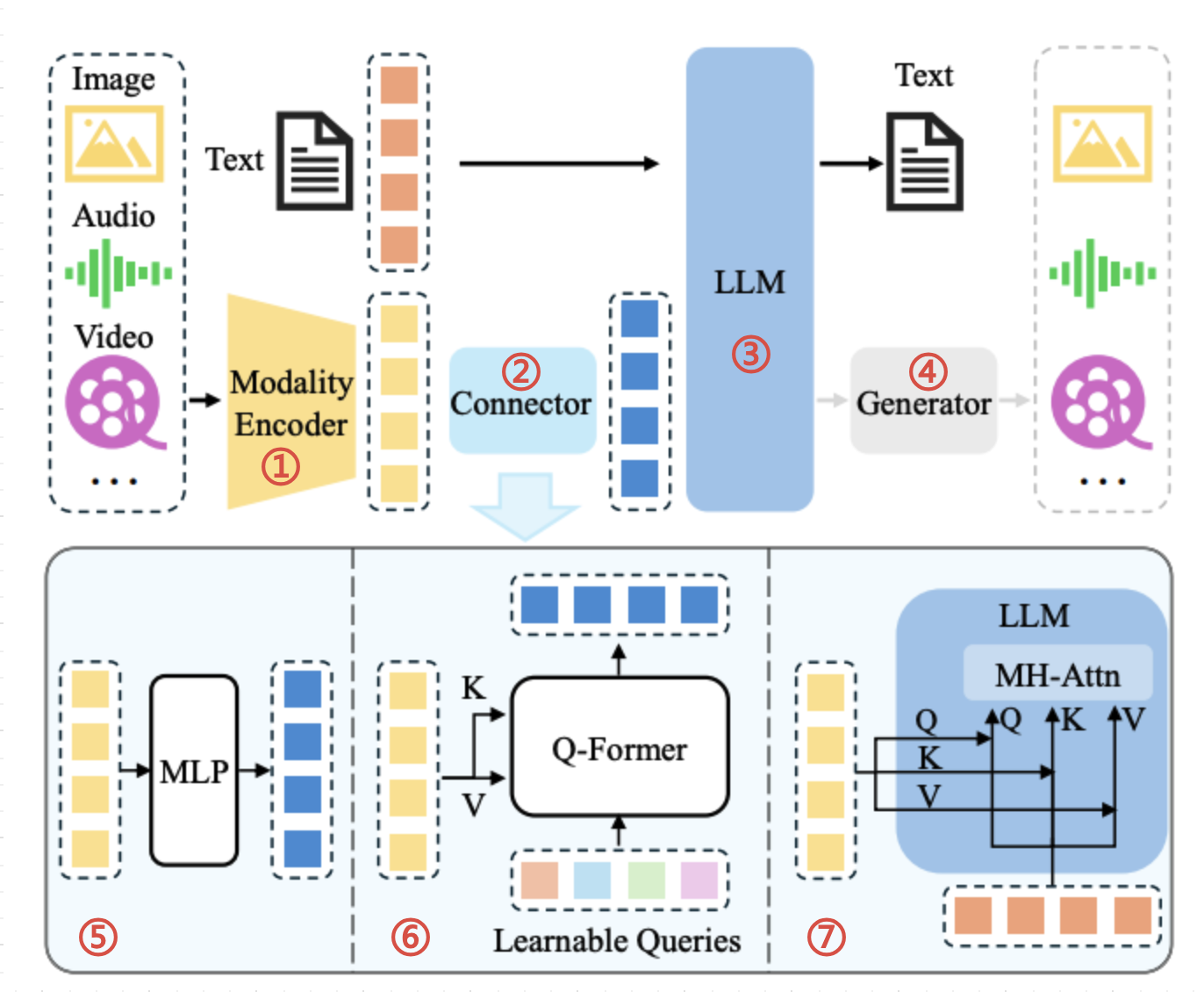
多模态融合是指同时处理和理解来自不同感知通道(如视觉、听觉、语言)的信息,并将其整合为一个统一的表示形式。根据最新研究,多模态融合机制可分为四大类:
1.1 基于特征的融合
这种方法直接在特征层面进行融合,常见操作包括:
- 特征连接:将不同模态的特征向量直接拼接
- 特征加权:根据不同场景对各模态特征赋予不同权重
- 元素级运算:通过加法、乘法等运算组合特征
基于特征的融合方法实现简单,但难以捕捉模态间的复杂交互关系。
1.2 基于对齐的融合
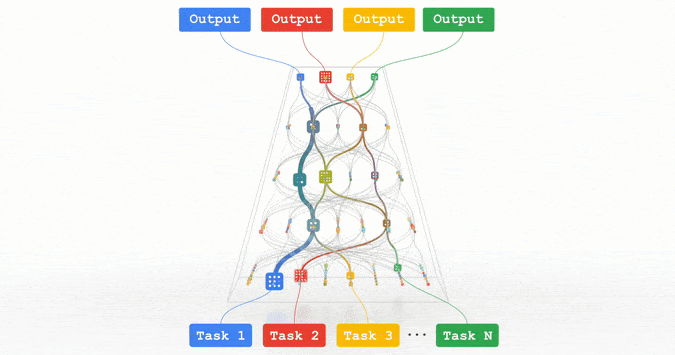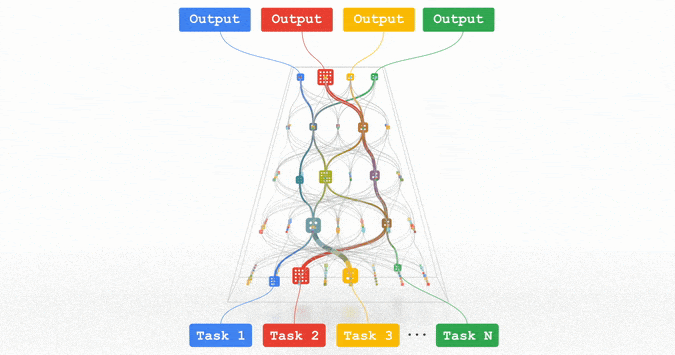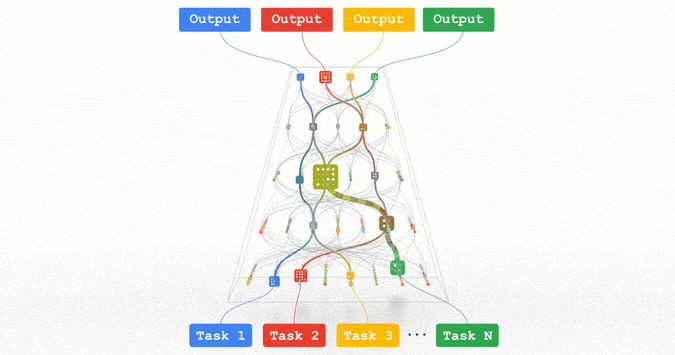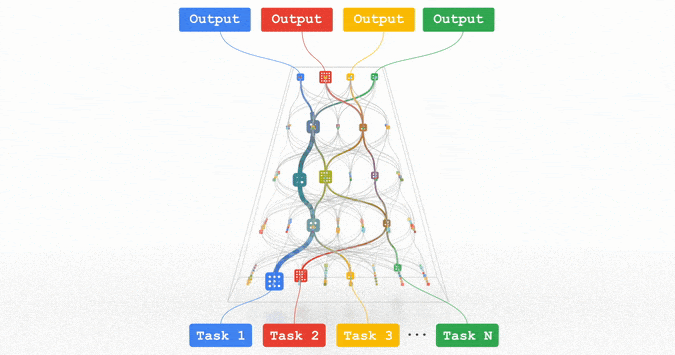
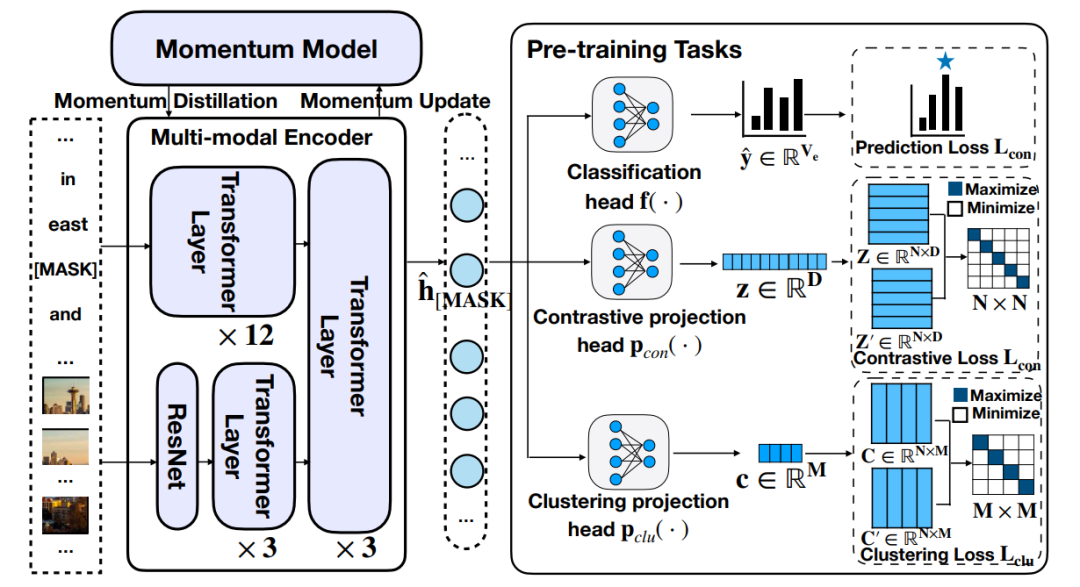
对齐融合方法建立不同模态之间的语义对应关系,主要包括:
- 注意力机制对齐:使用交叉注意力计算模态间的相关性
- 语义空间映射:将不同模态映射到共享的语义空间
- 协同表示学习:通过联合优化目标同时学习多模态表示
ICLR 2024会议中提出的多项创新方法显著提高了模态对齐的精度和效率,如IMProv模型能够从多模态提示中学习复杂视觉任务。
1.3 基于对比学习的融合
对比学习融合通过构建正负样本对,在表示空间中拉近相关模态的距离,推开无关模态的距离。这种方法的核心是设计合适的对比损失函数,如InfoNCE、MoCo等。
1.4 基于生成的融合
生成式融合利用生成模型将一种模态的信息转换到另一种模态,包括:
- 条件生成:以一种模态为条件生成另一种模态
- 循环一致性:通过双向转换确保语义一致性
- 扩散模型:基于噪声逐步生成目标模态信息
最新研究表明,基于扩散模型的多模态融合在图像生成、跨模态翻译等任务上取得了突破性进展。
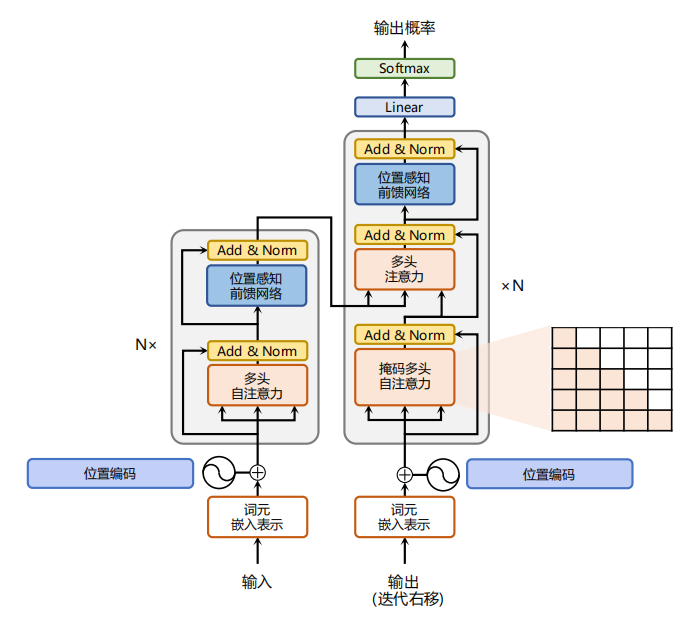
2. 视觉-语言对齐技术:让AI理解图像的"言外之意"

视觉-语言对齐(Visual-Language Alignment)是使AI系统理解图像内容并建立与语言的联系的关键技术。当下主流的视觉-语言对齐技术主要有:
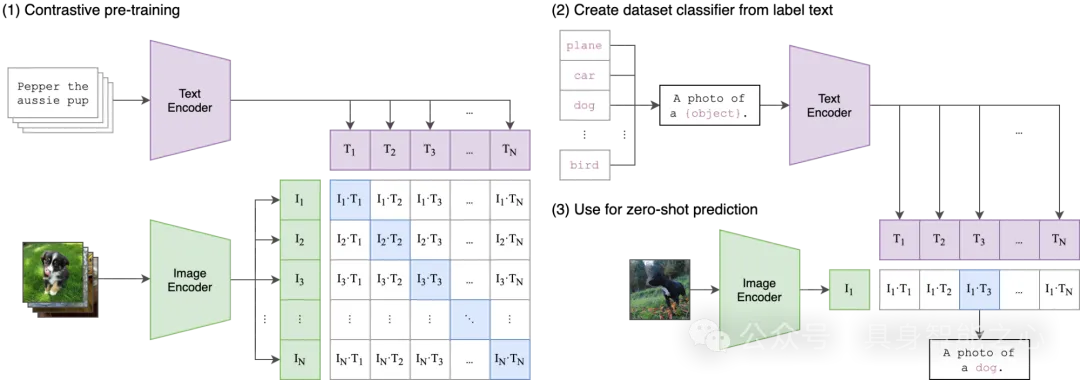
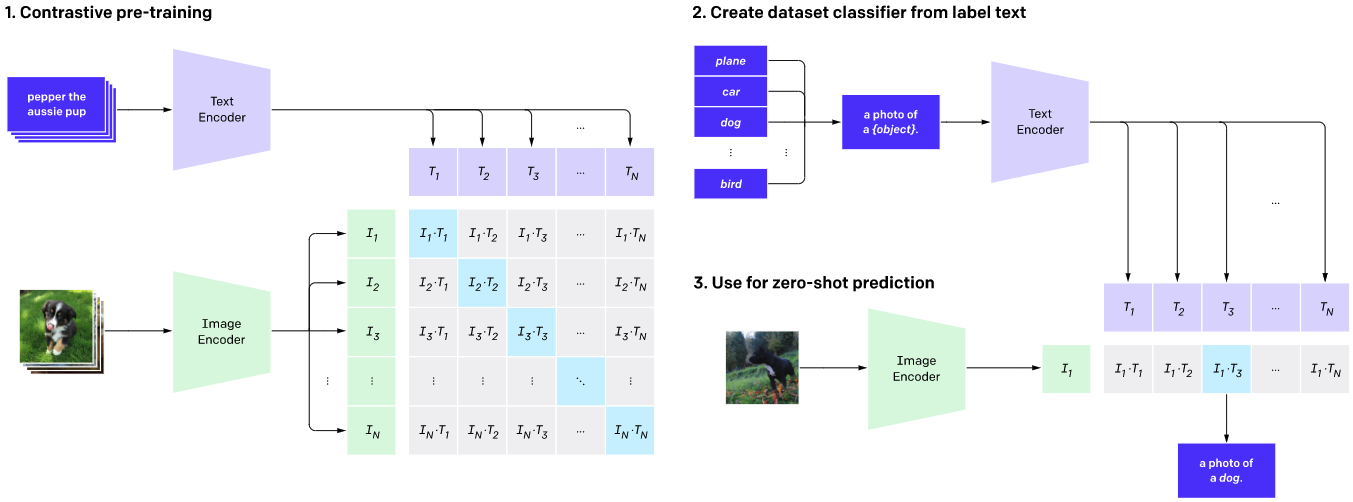
2.1 对比学习对齐
以CLIP(Contrastive Language-Image Pre-training)为代表的对比学习模型,通过大规模的图文对训练,学习将图像和文本映射到同一语义空间。CLIP模型采用双塔结构,分别编码图像和文本,通过最大化正确图文对的相似度,最小化错误图文对的相似度,实现对齐。

CLIP模型的创新之处在于:
- 使用4亿图文对进行训练,规模远超之前的模型
- 采用简单而有效的对比学习方法
- 展示了强大的零样本迁移能力
2.2 自回归对齐
自回归对齐方法将图像视为语言模型的前缀,让模型学习在给定图像的条件下生成相应的文本。这种方法的代表是BLIP、Flamingo等模型,它们通常采用编码器-解码器架构,其中编码器处理图像,解码器生成文本。
2.3 基于注意力的对齐
注意力对齐机制通过交叉注意力层,实现图像特征和文本特征之间的动态交互。这种方法的优势在于能够捕捉细粒度的视觉-语言对应关系,例如将图像中的特定区域与文本中的特定词语关联起来。
代表模型如ALIGNVLM,它通过ALIGN模块将视觉特征映射到大型语言模型的嵌入空间,显著提高了多模态理解能力。
3. 跨模态嵌入:搭建信息桥梁
跨模态嵌入技术旨在创建一个统一的表示空间,使不同模态的数据可以被映射和比较。这种技术为多模态理解和跨模态搜索等应用提供了基础。
3.1 联合嵌入学习
联合嵌入学习通过同时优化多个模态的嵌入表示,使相关内容在嵌入空间中接近。这种方法的核心是设计合适的损失函数,如三元组损失、排序损失等。
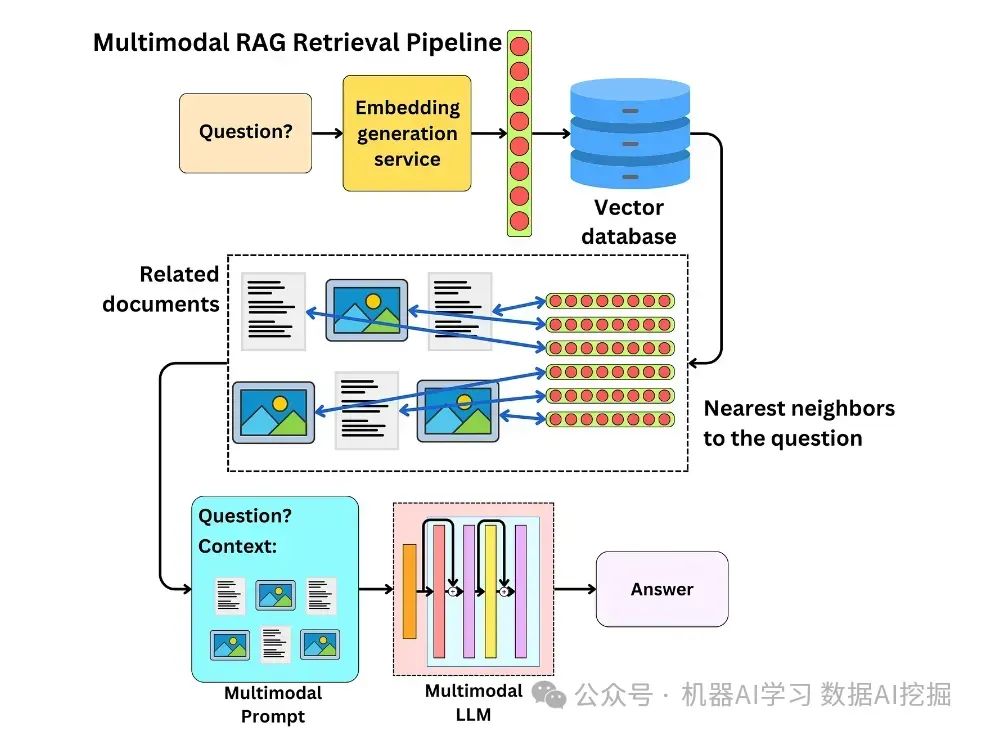
3.2 ImageBind:统一多模态嵌入
ImageBind是一种革命性的多模态嵌入模型,能够将六种不同模态(图像、文本、音频、深度、热成像、IMU数据)映射到统一的嵌入空间。这使得模型可以实现任意模态间的零样本迁移,如仅使用图像和文本训练的模型可以实现音频到图像的检索。
3.3 跨模态嵌入的应用
跨模态嵌入技术已广泛应用于:
- 跨模态检索:以一种模态作为查询,检索另一模态的相关内容
- 多模态推荐系统:融合用户在不同模态上的偏好进行推荐
- 医疗诊断:结合影像和临床文本数据进行疾病诊断
- 辅助创作:通过文字描述生成相应的图像或音频
4. 图像理解链路:AI如何"看懂"图像
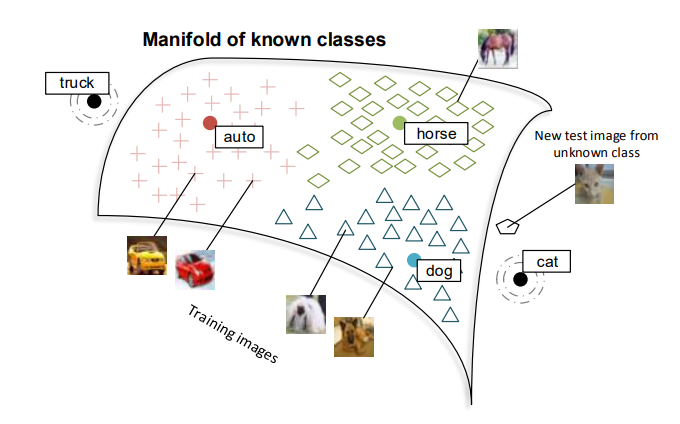
图像理解链路是AI系统从接收图像到生成理解结果的完整处理流程。现代图像理解链路通常包括以下阶段:
4.1 视觉编码阶段
这一阶段使用视觉编码器(如CNN、ViT)将图像转化为高维特征表示。最新的视觉编码器如SWIN Transformer在处理不同尺度的视觉信息方面表现出色,能够捕捉从局部到全局的视觉特征。
4.2 特征提取与处理
在这一阶段,系统从特征中识别出关键元素和信息,如物体、属性、关系等。先进的模型如书生·万象采用向量链接技术,连接各领域专用解码器,支持检测、分割等多种任务。
4.3 多模态融合与推理
这一阶段将视觉特征与其他模态信息(如文本)进行融合,并基于融合信息进行高级推理和理解。GLM-4V-Flash等模型创新性地简化了图像分析流程,支持用户通过简单的URL上传获取详细的图像描述。
4.4 思维链(Chain of Thought)
最新的图像理解模型引入了"思维链"(Chain of Thought)机制,让模型能够逐步推理。这种方法使模型能够像人类一样分解复杂问题,提高了推理透明度和准确性。
5. 虚实融合:数字孪生技术的创新应用

虚实融合是指将现实世界与数字世界无缝连接的技术,而数字孪生则是其中的关键应用形式。
5.1 数字孪生技术概述
数字孪生(Digital Twin)是对物理实体或过程的虚拟表示,通过数据连接确保物理状态和虚拟状态的实时同步。它允许在虚拟环境中分析、模拟和优化物理系统,为决策提供支持。

5.2 数字孪生的发展阶段
数字孪生技术的发展可分为五个阶段:
- 以虚仿实:单向复制物理实体
- 实虚互动:建立双向交互机制
- 虚实融合:实现深度融合和协同
- 虚实共生:虚拟与现实相互影响和塑造
- 虚实一体:物理与数字世界的边界变得模糊
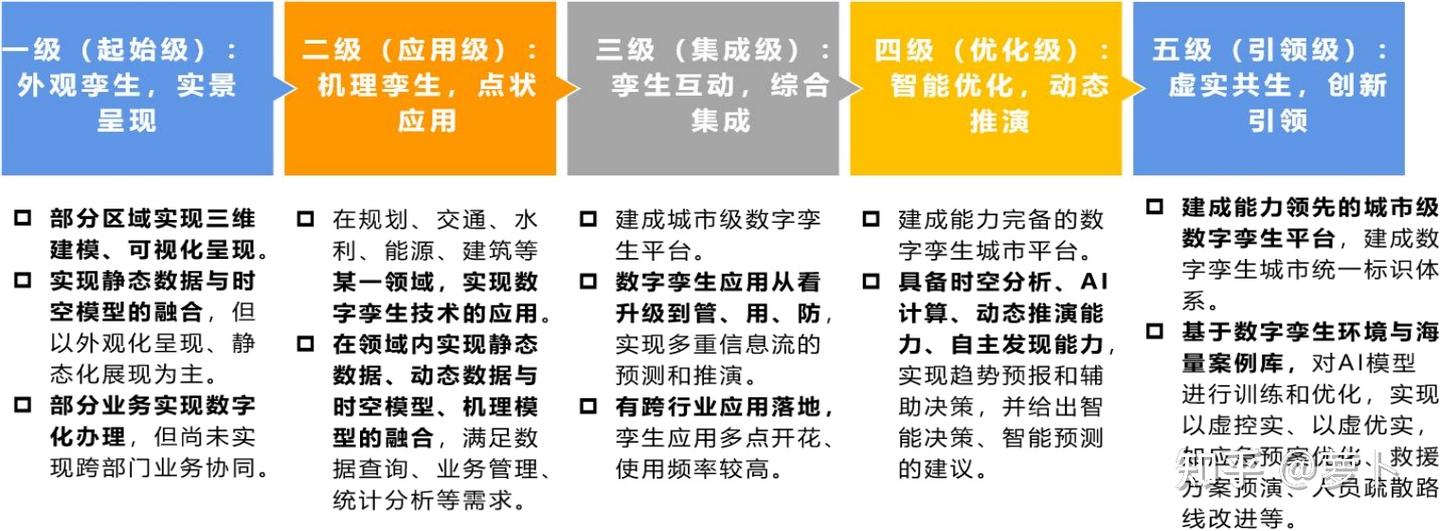
5.3 虚实融合的应用场景
虚实融合和数字孪生技术已广泛应用于多个领域:
- 智慧城市:建立城市数字孪生平台,助力城市规划、管理和应急响应
- 工业制造:实现生产线的仿真、监控和优化,提高生产效率和产品质量
- 医疗健康:创建患者或器官的数字孪生模型,用于诊断、治疗规划和医学教育
- 能源管理:模拟和优化能源系统,提高能源利用效率
- 交通物流:优化交通流量和物流路径,减少拥堵和能源消耗
6. 迷你多模态理解评测平台:AI能力的"试金石"

评测平台是衡量多模态AI模型性能的重要工具,提供了客观、全面的评估体系。
6.1 MMBench:全方位能力评测体系
MMBench是由上海AI实验室的OpenCompass团队开发的全面多模态评测平台。它采用能力导向的评估方法,不是按任务评估模型,而是从感知到认知能力逐级细分评估,覆盖20项细粒度能力。

MMBench的核心特点包括:
- 圆形评估策略:通过循环位移选项的方式,确保评估结果更可靠
- 基于LLM的答案提取:使用ChatGPT从模型自由格式输出中提取答案
- 多语言支持:提供英文和中文版本,方便评估模型的多语言能力
- 开源透明:通过GitHub开源评测代码和数据,保证评测过程的透明度
6.2 MUGE:中文多模态评测先驱
MUGE(牧歌,Multimodal Understanding and Generation Evaluation)是业界首个大规模中文多模态评测基准,由达摩院联合浙江大学、阿里云天池平台联合发布。它提供了跨模态理解和生成的评测任务集合,为中文多模态模型的发展提供了重要参考。
6.3 LVLM-eHub:视觉-语言模型综合评测
LVLM-eHub是一个综合评估大型视觉-语言模型的基准平台,包括13个代表性的大型视觉-语言模型(如InstructBLIP和LLaVA),通过定量能力评估和在线竞技场平台进行全面评测。
该平台的创新之处在于结合了客观评测和人类主观评价,为模型开发者提供了全面的反馈信息。
7. 多模态技术发展趋势与未来展望
随着技术的不断进步,多模态融合领域正朝着以下方向发展:
7.1 模型架构创新
- 统一模型框架:构建能够同时处理多种模态的统一架构,如FLAVA、ImageBind等
- 高效参数共享:通过适当的参数共享,在保持性能的同时减少计算资源需求
- 低资源模态适应:开发能够有效处理低资源模态数据的方法和技术
7.2 自监督学习进步
- 跨模态对比学习:进一步改进跨模态对比学习方法,减少对标注数据的依赖
- 生成式自监督:利用生成任务作为自监督信号,提高表示学习的效果
- 多任务自监督:设计多样化的预训练任务,学习更通用的表示
7.3 应用场景拓展
- 医疗健康:结合医学影像、临床文本和生物信号进行更精准的诊断和治疗
- 智能制造:融合视觉、声音和传感器数据进行质量控制和预测性维护
- 智慧城市:整合多源数据进行城市规划、流量预测和环境监测
结语
多模态融合技术代表了人工智能领域的前沿发展方向,它通过打破不同模态信息的壁垒,让AI系统能够更全面地感知和理解世界。从多模态融合机制到视觉-语言对齐,从跨模态嵌入到虚实融合,这些技术正在不断突破和创新,为AI赋能更多应用场景。
随着迷你多模态理解评测平台的完善,我们对多模态模型的能力有了更客观、全面的评估标准,这将进一步促进多模态融合技术的发展和进步。未来,多模态融合技术将继续朝着更高效、更智能、更普适的方向发展,为人类社会创造更多价值。
多模态融合技术,听起来就像是未来世界的黑科技啊!期待它在现实中的应用带来更多惊喜~