网页版:https://gsthsqyp.gensparkspace.com
视频版:https://www.youtube.com/watch?v=tkOLjfD5MEk
音频版:https://notebooklm.google.com/notebook/fa03ad34-3e23-471f-abe9-1183cf3e6f1b/audio

目录
- 引言:LLM系统的微服务化挑战
- 服务网格架构概述
- 微服务化LLM系统的关键需求
- 服务网格在LLM系统中的应用架构
- 请求路由与流量管理
- 负载均衡策略
- 降级策略与容错机制
- 容灾管理与多云部署
- 弹性LLM服务集群实践案例
- 部署与运维最佳实践
- 总结与展望
引言:LLM系统的微服务化挑战
近年来,大型语言模型(LLM)在自然语言处理领域取得了突破性进展,企业纷纷将其应用于各种业务场景。然而,随着LLM应用规模的扩大,传统的单体架构已经无法满足高并发、高可用性和灵活部署的需求。微服务化架构成为必然选择,但这也带来了一系列挑战,包括服务间通信复杂性增加、分布式系统可靠性保障困难、以及多环境部署的一致性问题等。
在微服务化LLM系统中,模型服务、向量存储、推理引擎、API网关等组件需要协同工作,而这些服务间的调用关系和依赖性要求我们采用更加先进的架构设计模式。服务网格(Service Mesh)作为解决微服务通信问题的新一代基础设施层,为构建弹性LLM服务集群提供了理想解决方案。
服务网格架构概述
服务网格是一个专门用于处理服务间通信的基础设施层,通过在每个服务旁运行的轻量级网络代理(Sidecar Proxy)实现对微服务通信的统一管理。它将服务间通信的控制逻辑与业务逻辑分离,使开发者可以专注于业务功能实现,而将复杂的网络问题交给服务网格处理。

服务网格的核心组件
- 数据平面:由与应用服务并列部署的Sidecar代理组成,负责处理服务间的实际网络通信,如Envoy代理
- 控制平面:集中管理所有Sidecar代理,提供API接口、策略配置和服务发现等功能,如Istio的控制平面组件
- 配置存储:保存服务网格的配置数据,通常基于Kubernetes的自定义资源或专用的配置存储
- 可观测性工具:收集网络通信的指标、日志和链路追踪数据,支持系统监控和故障排查
服务网格提供了流量管理、安全通信、指标收集和策略执行等核心功能,而这些正是构建现代LLM微服务系统所必需的。
微服务化LLM系统的关键需求
LLM系统相比传统微服务应用有其独特的需求:
- 计算资源密集型:LLM推理需要大量计算资源,特别是GPU资源,精确的负载均衡至关重要
- 延迟敏感:用户交互型LLM服务对延迟有较高要求,服务路由需要考虑延迟因素
- 资源成本高昂:LLM系统运行成本高,需要优化资源利用率和弹性伸缩能力
- 多模型适配:通常需要支持多种LLM模型和版本,请求需根据不同模型能力进行智能路由
- 服务质量差异化:不同用户、场景可能需要不同服务质量(QoS)保障
- 安全与隐私:处理敏感数据时需要严格的隔离和加密措施
这些需求使得传统微服务架构很难直接应用于LLM系统,需要借助服务网格等现代架构模式进行优化设计。
服务网格在LLM系统中的应用架构
在LLM微服务系统中,我们可以构建一个基于服务网格的分层架构:
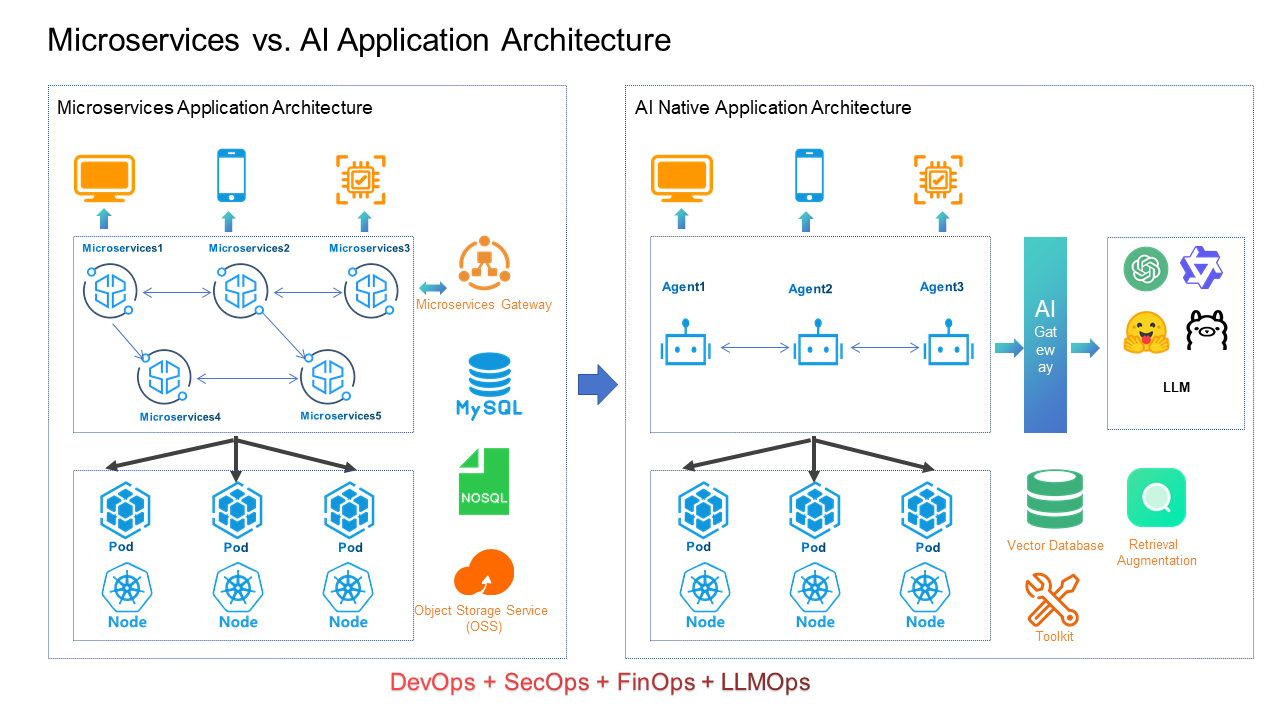
架构分层
- 接入层:API网关、认证授权、请求验证
- 编排层:任务分发、工作流管理、请求转换
- 模型服务层:LLM模型实例、推理服务
- 增强服务层:向量数据库、知识库、外部工具
- 基础设施层:计算资源管理、存储、网络
服务网格在各层的应用
在上述架构中,服务网格主要负责:
- 接入层:流量入口控制、SSL终结、认证授权
- 编排层与模型服务层之间:智能路由、负载均衡、熔断降级
- 模型服务层内部:多模型间的流量分配、资源隔离
- 增强服务层:一致性保障、超时控制
- 跨层通信:安全加密、访问控制、可观测性
通过服务网格将这些通信相关的功能从业务代码中抽离出来,实现了"关注点分离",同时提供了丰富的网络控制能力。
请求路由与流量管理
在LLM系统中,请求路由是一个关键环节,因为不同的请求可能需要不同的模型能力和资源配置。服务网格提供了强大的流量管理能力,能够根据多种因素进行智能路由决策。
基于内容的路由
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: llm-routing
spec:
hosts:
- llm-service
http:
- match:
- headers:
model-type:
exact: "gpt-4"
route:
- destination:
host: gpt4-service
subset: v1
- match:
- headers:
prompt-complexity:
exact: "high"
route:
- destination:
host: high-capacity-llm
- route:
- destination:
host: default-llm-service
这种路由配置可以根据请求头、URL路径、查询参数等内容特征将请求路由到最合适的LLM服务实例。
高级流量管理策略
-
金丝雀发布:新模型版本逐步替换旧版本,控制风险
route: - destination: host: llm-service-v1 weight: 80 - destination: host: llm-service-v2 weight: 20 -
请求分片:将不同类型的请求分配到专用服务实例
route: - destination: host: text-completion-llm match: - headers: task-type: "completion" - destination: host: text-embedding-llm match: - headers: task-type: "embedding" -
流量镜像:将生产流量复制到测试环境,验证新模型行为
route: - destination: host: production-llm mirror: host: test-llm mirrorPercentage: value: 100.0
这些高级流量策略可以帮助LLM服务实现平滑升级、场景特化和性能验证。
负载均衡策略
LLM服务的计算资源消耗很大,合理的负载均衡策略对于优化资源利用率和提高系统吞吐量至关重要。服务网格提供了多种负载均衡算法,可以根据LLM系统的特点进行选择和配置。
智能负载均衡算法
-
加权轮询(Weighted Round Robin):根据服务器能力分配不同权重
apiVersion: networking.istio.io/v1beta1 kind: DestinationRule metadata: name: llm-service spec: host: llm-service trafficPolicy: loadBalancer: simple: ROUND_ROBIN subsets: - name: gpu-a100 labels: gpu: a100 trafficPolicy: loadBalancer: simple: ROUND_ROBIN weight: 3 - name: gpu-t4 labels: gpu: t4 trafficPolicy: loadBalancer: simple: ROUND_ROBIN weight: 1 -
最少连接(Least Connection):将请求发送到当前连接数最少的实例
trafficPolicy: loadBalancer: simple: LEAST_CONN -
延迟感知(Latency Aware):根据服务响应时间动态调整权重
-
KV缓存亲和性(KV Cache Affinity):将同一用户的请求路由到同一服务实例,利用LLM的KV缓存提高性能
trafficPolicy: loadBalancer: consistentHash: httpHeaderName: "x-user-id"
LLM专用负载均衡优化
对于LLM系统,还可以实现一些特殊的负载均衡策略:
- GPU内存感知:根据GPU内存使用情况进行路由,避免内存溢出
- 推理队列长度感知:将请求路由到队列较短的实例
- 资源效率优先:优先使用已加载模型的实例,减少冷启动开销
- 批处理亲和:将可批处理的请求路由到同一实例,提高GPU利用率
通过自定义负载均衡策略,可以更好地适应LLM服务的资源使用特点,提高系统整体效率。
降级策略与容错机制
LLM系统处理错误和过载情况的能力对于提供稳定可靠的服务至关重要。服务网格提供了多种降级策略和容错机制,可以帮助LLM系统在面对异常情况时保持基本功能。
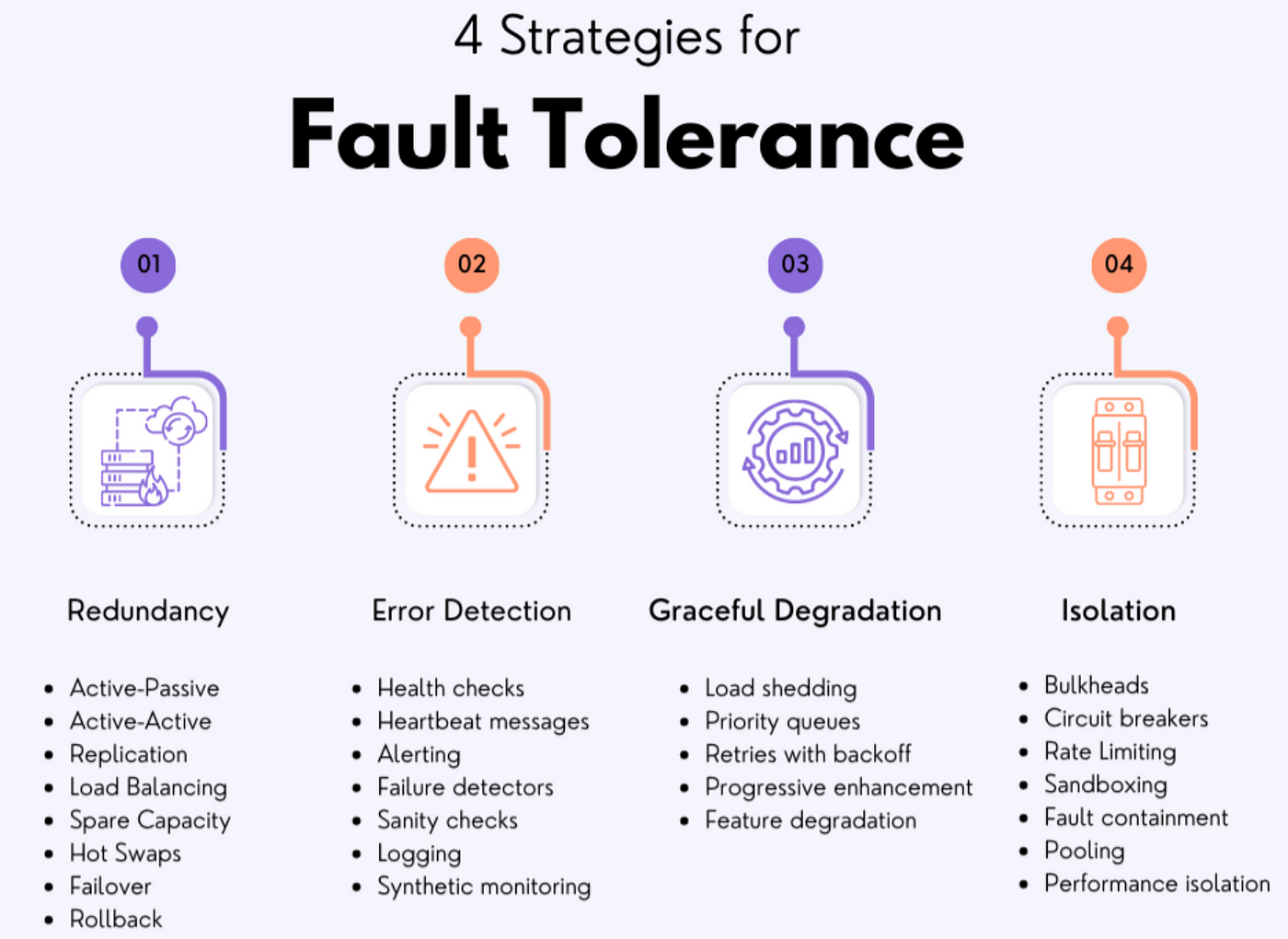
熔断器模式
熔断器可以检测到服务不健康状态,并暂时切断对该服务的请求,防止级联故障:
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: llm-circuit-breaker
spec:
host: llm-service
trafficPolicy:
connectionPool:
tcp:
maxConnections: 100
connectTimeout: 30ms
http:
http1MaxPendingRequests: 1
maxRequestsPerConnection: 10
outlierDetection:
consecutiveErrors: 5
interval: 5s
baseEjectionTime: 30s
maxEjectionPercent: 50
超时控制
为不同类型的LLM请求设置适当的超时值,避免长时间阻塞:
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: llm-timeouts
spec:
hosts:
- llm-service
http:
- route:
- destination:
host: llm-service
timeout: 15s
重试策略
对于可重试的请求,配置适当的重试策略:
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: llm-retry
spec:
hosts:
- llm-service
http:
- route:
- destination:
host: llm-service
retries:
attempts: 3
perTryTimeout: 2s
retryOn: connect-failure,refused-stream,unavailable
LLM系统的降级模式
在LLM系统中,可以实现多级降级策略:
-
模型回退:从高级模型降级到基础模型
apiVersion: networking.istio.io/v1beta1 kind: DestinationRule metadata: name: llm-fallback spec: host: llm-service trafficPolicy: outlierDetection: consecutiveErrors: 5 subsets: - name: primary-model labels: version: gpt4 - name: fallback-model labels: version: mistral-7b -
功能降级:关闭非核心功能,保留基本问答能力
-
批处理降级:从实时处理降级到批处理模式
-
缓存响应:对于常见问题返回缓存的答案,减轻模型负担
通过多层次的降级策略,LLM系统可以在各种故障情况下保持核心功能可用,提高系统整体可靠性。
容灾管理与多云部署
为了实现高可用性和地理冗余,现代LLM系统通常采用多云或混合云部署。服务网格提供了跨集群、跨区域和跨云的通信能力,支持构建全球分布式的LLM服务。

多集群服务网格
Istio等服务网格支持跨多个Kubernetes集群部署,实现统一的流量管理和安全策略:
apiVersion: install.istio.io/v1alpha1
kind: IstioOperator
spec:
values:
global:
meshID: llm-mesh
multiCluster:
clusterName: cluster1
network: network1
区域感知路由
根据用户地理位置将请求路由到最近的LLM服务实例:
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: geo-routing
spec:
hosts:
- llm-global-service
http:
- match:
- headers:
region:
exact: "asia-east"
route:
- destination:
host: llm-service.asia-cluster
- match:
- headers:
region:
exact: "eu-west"
route:
- destination:
host: llm-service.europe-cluster
- route:
- destination:
host: llm-service.default-cluster
灾备切换策略
在主要区域发生故障时,自动切换到备用区域:
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: dr-failover
spec:
host: llm-service
trafficPolicy:
loadBalancer:
localityLbSetting:
enabled: true
failover:
- from: us-east
to: us-west
- from: us-west
to: eu-west
多云混合部署实践
在实际应用中,可以根据不同LLM服务的特点选择合适的部署方式:
- GPU密集型推理服务:部署在专有云或自建数据中心,利用专用GPU资源
- CPU推理优化模型:部署在公有云,利用弹性计算资源
- 高频访问模型:多区域部署,提供低延迟访问
- 数据敏感模型:部署在符合数据合规要求的区域
多云混合部署策略需要服务网格提供统一的管控平面,实现跨环境的服务发现、流量管理和安全通信。
弹性LLM服务集群实践案例
下面通过一个具体案例,展示如何利用服务网格构建弹性LLM服务集群。
系统架构
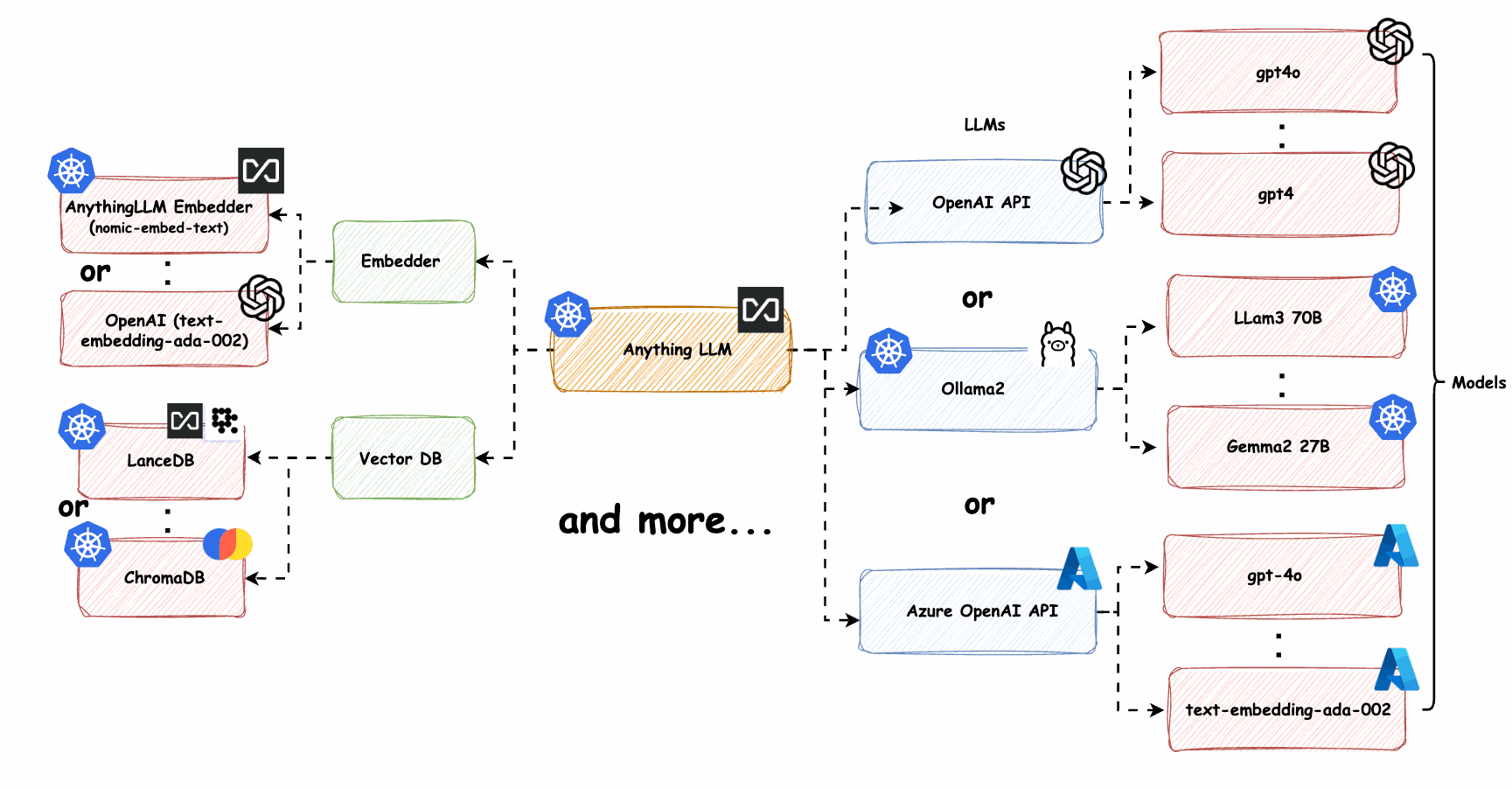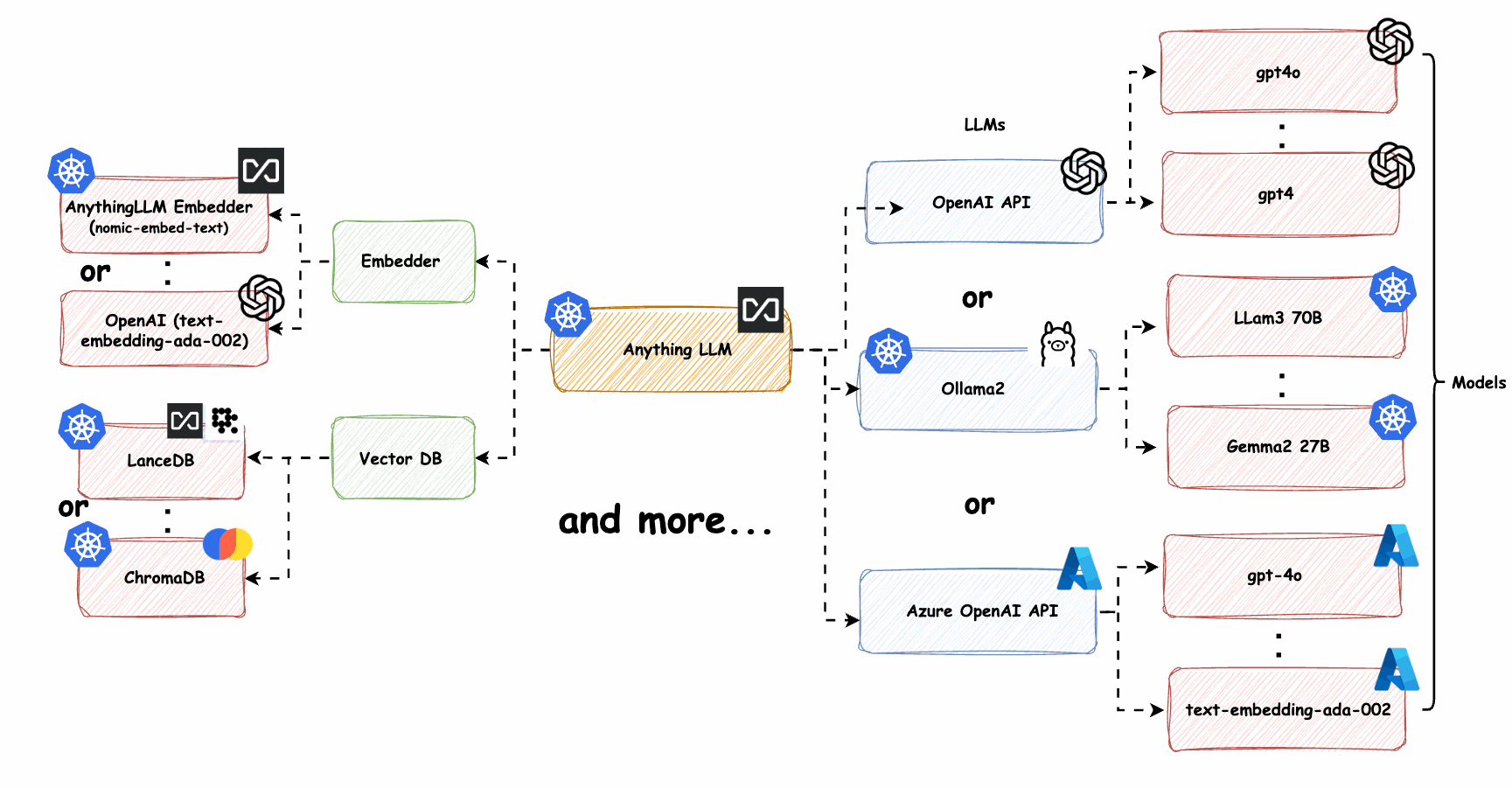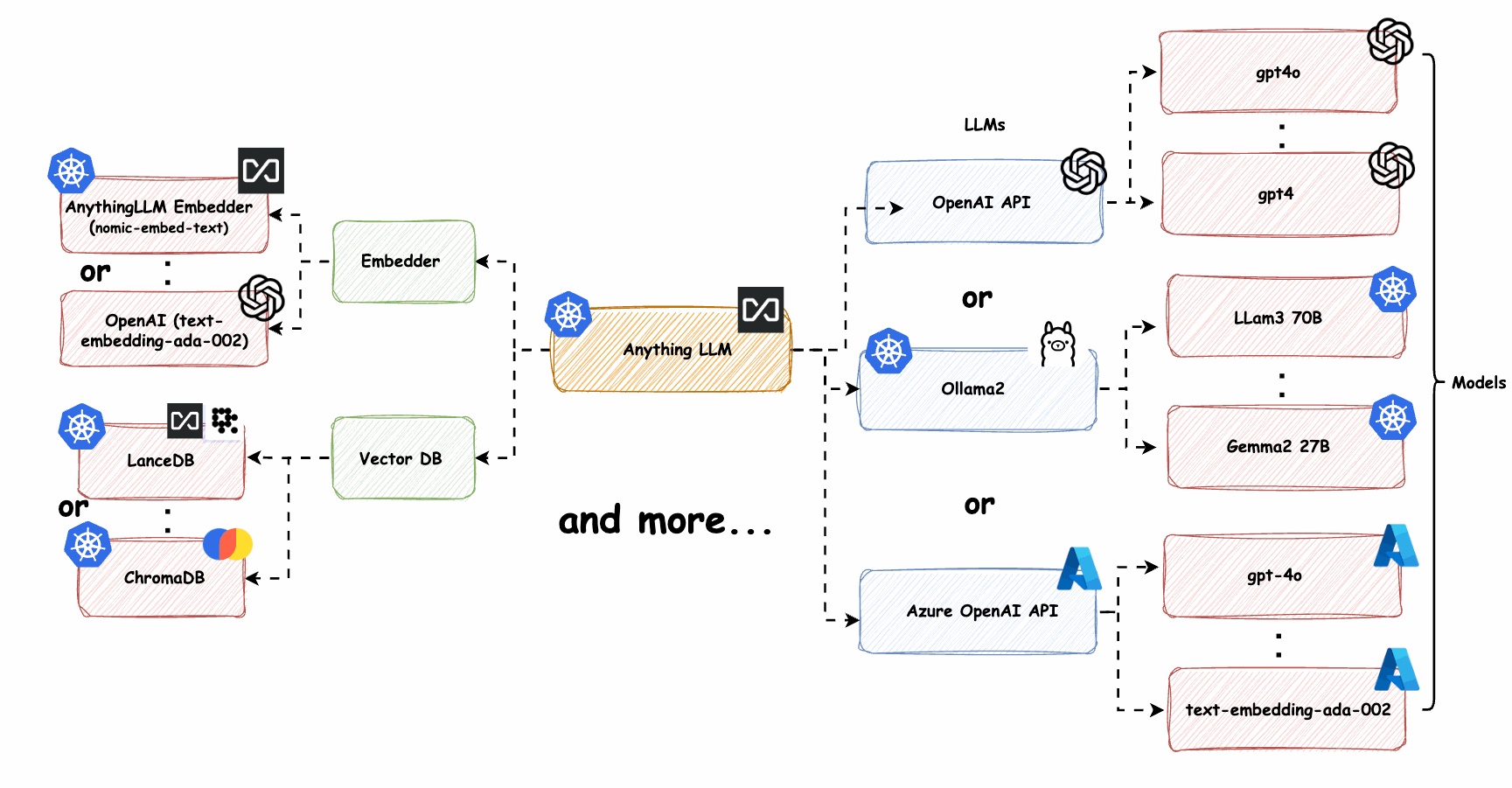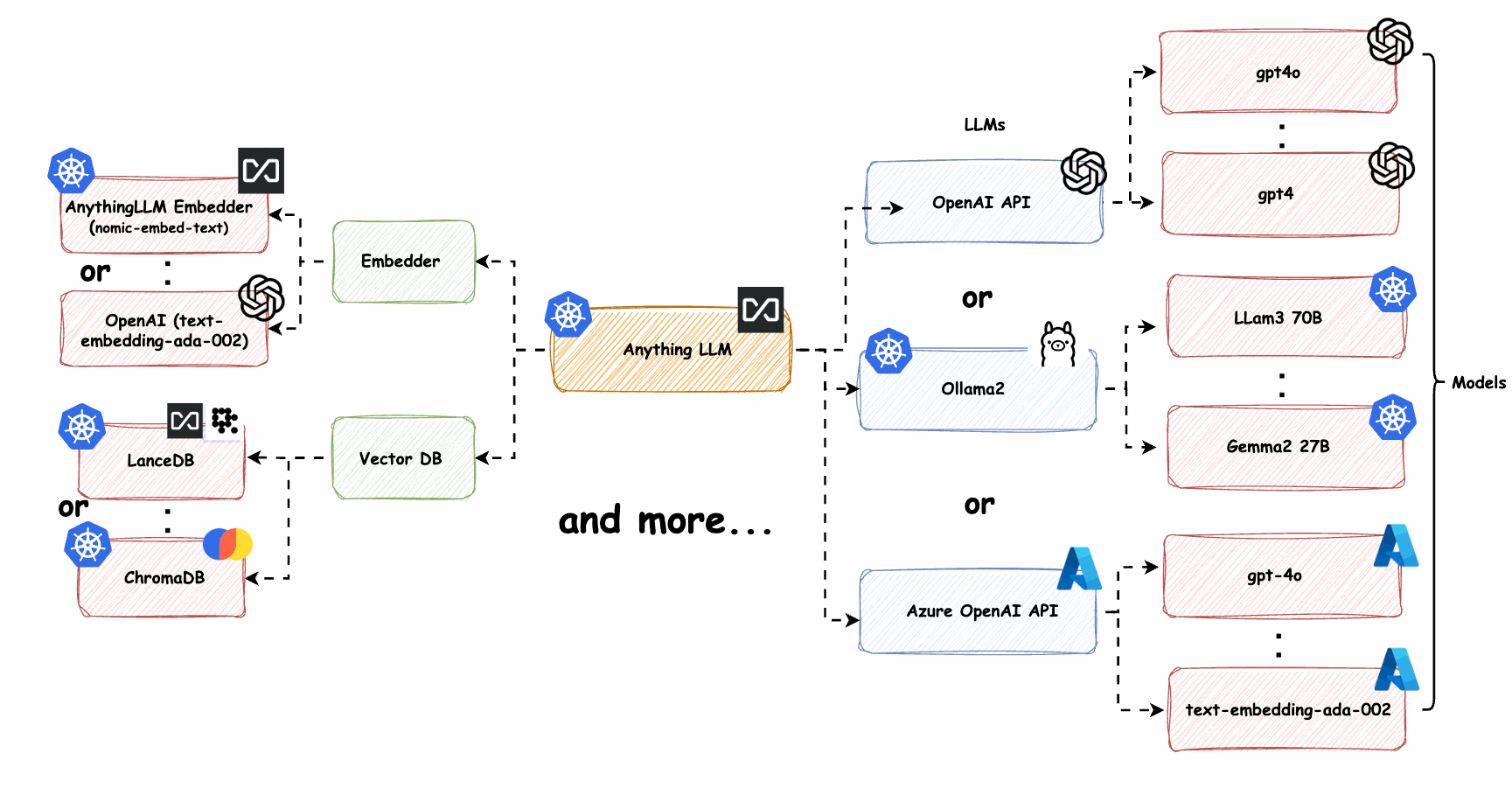
系统包含以下组件:
- API网关:处理外部请求,认证授权
- 流量控制器:基于Istio实现的流量管理层
- LLM服务集群:部署在多个区域的不同规模LLM模型
- 向量索引服务:提供RAG(检索增强生成)能力
- 上下文管理:维护会话状态和上下文信息
- 监控告警:系统健康状态监控
关键配置实现
1. 自动伸缩
基于请求量和资源利用率自动扩缩服务实例:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: llm-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: llm-service
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
- type: Pods
pods:
metric:
name: inference_queue_length
target:
type: AverageValue
averageValue: 5
2. 流量分流策略
根据请求特征和用户级别进行精细流量分配:
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: llm-traffic-splitting
spec:
hosts:
- llm.example.com
http:
- match:
- headers:
user-tier:
exact: "premium"
route:
- destination:
host: premium-llm-service
subset: high-priority
- match:
- headers:
request-type:
exact: "batch"
route:
- destination:
host: batch-llm-service
- route:
- destination:
host: standard-llm-service
weight: 100
3. 服务质量差异化
为不同优先级的请求提供差异化服务质量:
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: llm-qos
spec:
host: llm-service
subsets:
- name: high-priority
labels:
priority: high
trafficPolicy:
connectionPool:
http:
http1MaxPendingRequests: 50
maxRequestsPerConnection: 20
outlierDetection:
consecutiveErrors: 7
- name: standard
labels:
priority: standard
trafficPolicy:
connectionPool:
http:
http1MaxPendingRequests: 20
maxRequestsPerConnection: 10
outlierDetection:
consecutiveErrors: 5
4. 多级故障应对策略
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: llm-fault-handling
spec:
hosts:
- llm-service
http:
- route:
- destination:
host: primary-llm
weight: 95
- destination:
host: backup-llm
weight: 5
retries:
attempts: 3
perTryTimeout: 2s
retryOn: connect-failure,refused-stream,5xx
fault:
delay:
percentage:
value: 0.1
fixedDelay: 5s
通过这些配置,弹性LLM服务集群可以实现高可用、自动伸缩和差异化服务,为用户提供稳定可靠的LLM服务体验。
部署与运维最佳实践
构建和运维微服务化LLM系统需要遵循一系列最佳实践,确保系统的可靠性、可维护性和安全性。
GitOps流程
采用GitOps方式管理服务网格配置,实现配置的版本控制和自动部署:
- 将所有服务网格配置存储在Git仓库
- 使用ArgoCD或Flux等工具实现配置的自动同步
- 通过Pull Request进行配置变更审核
- 自动化测试验证配置变更的有效性
监控与可观测性
构建全面的监控体系,实时了解系统状态:
- 服务级别指标:请求成功率、延迟、吞吐量
- LLM特定指标:推理时间、令牌处理速度、批处理效率
- 资源利用指标:GPU/CPU利用率、内存使用、网络流量
- 业务指标:用户满意度、完成率、错误率
服务网格可以自动收集请求级别的指标,结合Prometheus、Grafana等工具构建可视化监控面板。
版本管理与升级
LLM模型和服务的版本管理策略:
- 语义化版本号:使用明确的版本号标识模型和服务版本
- 蓝绿部署:准备完整的新版本环境,快速切换流量
- 金丝雀发布:逐步增加新版本流量比例,监控指标
- 回滚机制:在发现问题时快速恢复到稳定版本
服务网格可以通过流量控制策略实现这些高级部署模式,确保升级过程平稳可控。
安全实践
保护LLM系统的安全性和数据隐私:
- 服务间mTLS加密:所有微服务间通信全程加密
- 身份验证:基于JWT或SPIFFE的服务身份验证
- 授权控制:细粒度的访问控制策略
- 网络隔离:限制服务间的通信路径
- 审计日志:记录关键操作和访问信息
服务网格的安全功能可以与云原生安全工具集成,构建深度防御体系。
总结与展望
服务网格架构为构建微服务化LLM系统提供了强大的技术基础,解决了请求路由、负载均衡、降级策略和容灾管理等关键挑战。通过服务网格,企业可以构建支持多云混合部署的弹性LLM服务集群,实现高可用、高性能和高弹性的AI服务能力。
未来,随着LLM技术的进一步发展和服务网格生态的成熟,我们可以期待以下趋势:
- 自适应路由算法:基于实时性能数据和用户体验的智能路由决策
- 资源感知调度:更精细的资源感知调度和负载均衡
- 多模态支持:适应多模态AI模型的特殊需求
- 边缘计算集成:将LLM能力扩展到边缘节点,支持低延迟场景
- 自治运维:基于AIOps实现服务网格和LLM系统的自我调优
通过持续创新和实践,服务网格架构将继续发挥关键作用,支持企业构建更加强大和灵活的LLM服务体系。