想象一下,在2018年的某个普通日子里,OpenAI的研究人员们正围坐在办公室里,盯着屏幕上那个只有1.17亿参数的小家伙——GPT-1。彼时的它就像一个刚学会说话的孩子,虽然词汇量有限,但已经展现出了令人惊喜的语言天赋。谁能想到,这个"小不点"会在短短几年内成长为今天我们熟知的AI巨人。
网页版:https://www.genspark.ai/api/page_private?id=zdddltxd
视频版:https://www.youtube.com/watch?v=fAK9kmdIv4w

这就是GPT家族的成长故事——一个关于技术突破、规模扩张和智能涌现的传奇。从GPT-1的初次亮相到GPT-5的呼之欲出,每一代模型都在告诉我们:有时候,奇迹就是在一次次的参数堆叠和架构优化中悄然诞生的。
第一章:小试牛刀的GPT-1(2018年)
一个简单却革命性的想法
2018年,当时的AI领域还在为各种复杂的任务训练专门的模型。想要做情感分析?训练一个专用模型。想要做问答系统?再训练另一个。这种"一任务一模型"的做法让研究人员们疲于奔命。
就在这时,OpenAI提出了一个看似简单却极其革命性的想法:为什么不先让模型学会理解语言本身,然后再针对具体任务进行微调呢?
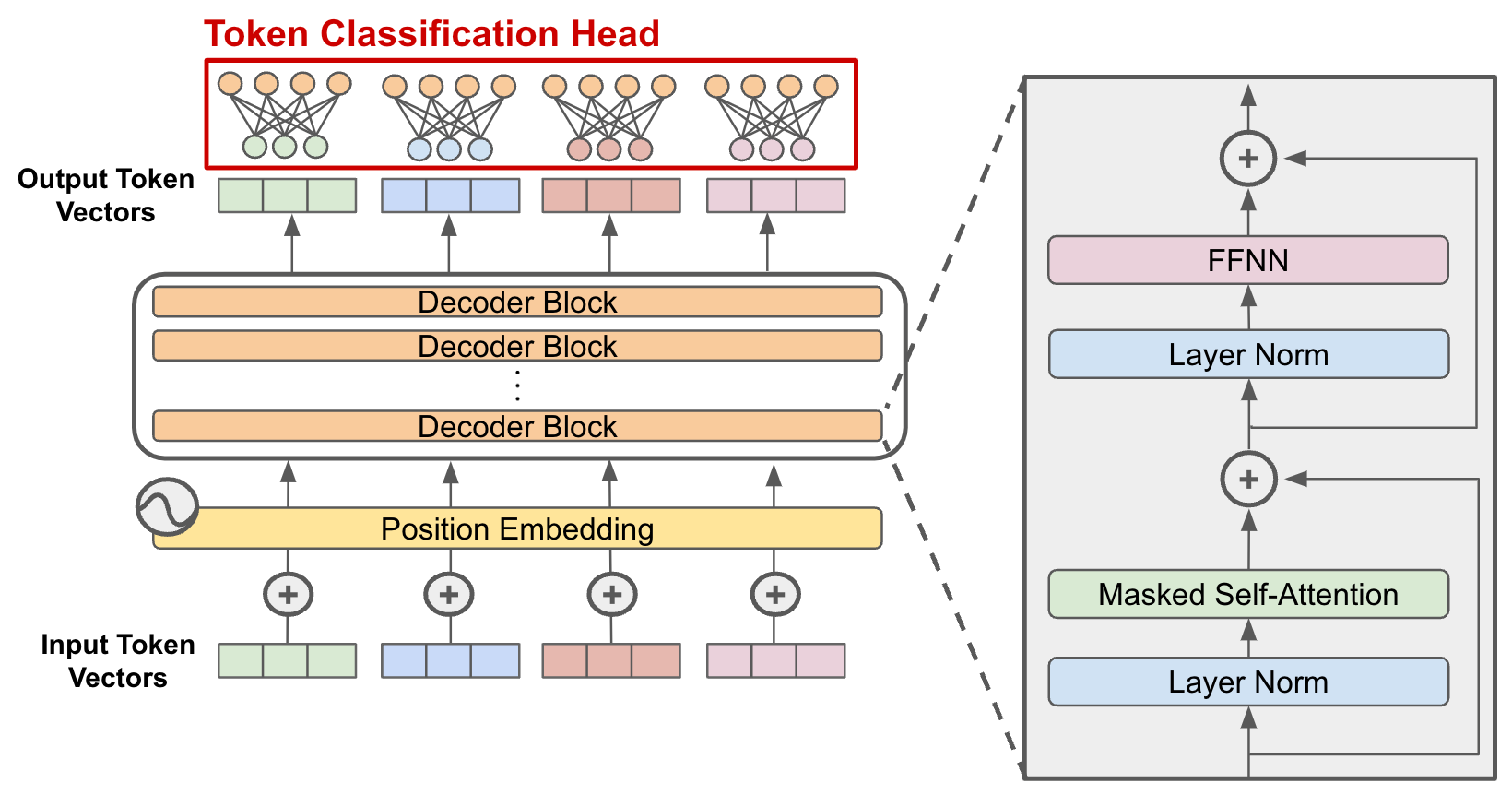
技术突破:Decoder-only架构的诞生
GPT-1采用了一个关键的架构决策:Decoder-only Transformer。与原始的Transformer模型不同,GPT-1抛弃了编码器部分,只保留解码器。这个看似简化的设计却蕴含着深刻的洞察。
根据技术文档,GPT-1的核心规格包括:
- 12层Transformer解码器
- 12个注意力头
- 768维的词嵌入
- 3072维的前馈网络
这个117M参数的模型在BookCorpus数据集上进行预训练,该数据集包含超过7000本未出版的书籍。选择书籍作为训练数据并非偶然——书籍提供了长篇连续的文本,让模型能够学习复杂的长程依赖关系。
令人惊喜的表现
GPT-1的表现让研究界为之一振。在GLUE基准测试的12个任务中,它在9个任务上超越了当时的专用模型。更令人兴奋的是,它展现出了早期的zero-shot学习能力——即使没有针对特定任务进行训练,也能给出合理的答案。
第二章:野心勃勃的GPT-2(2019年)
规模的力量
如果说GPT-1是一次试探性的尝试,那么GPT-2就是一次大胆的赌注。OpenAI将参数量从117M暴增到1.5B——整整增长了13倍。
但更重要的不仅仅是规模的扩大,而是训练策略的根本性转变。GPT-2提出了一个令人震撼的观点:语言模型就是无监督的多任务学习器。
WebText:更丰富的学习材料
为了支撑更大的模型,OpenAI构建了全新的WebText数据集。这个包含40GB文本的数据集来源于Reddit上的高质量内容,为模型提供了更加多样化和丰富的语言环境。
有趣的是,研究人员特意从数据集中移除了Wikipedia内容,以避免与常用测试集的重叠。这种严谨的实验设计体现了他们对科学研究的尊重。
Zero-shot学习的惊艳表现
GPT-2最令人印象深刻的能力是其zero-shot学习表现。想象一下,一个从未见过翻译任务的模型,仅仅通过理解"将以下英文翻译成法文"这样的指令,就能完成翻译工作。
研究表明,GPT-2在多个语言建模数据集上创造了新的记录,特别是在需要理解长程依赖关系的LAMBADA数据集上表现突出。
第三章:震撼登场的GPT-3(2020年)
参数爆炸:175B的智能涌现
2020年,当GPT-3带着其175B参数震撼登场时,整个AI社区都被它展现出的能力震惊了。这不仅仅是数量上的增长,更是质的飞跃。
In-Context Learning:学习方式的革命
GPT-3引入了一个全新的概念:In-Context Learning(上下文学习)。这意味着模型不需要更新参数就能"学会"新任务,只需要在提示中给出几个例子。
这种能力的实现得益于GPT-3庞大的规模:
- 96层Transformer
- 96个注意力头
- 12,888维的词嵌入
- 2048个token的上下文窗口
多样化的训练数据
GPT-3的训练数据来源更加多样化,包括Common Crawl、WebText2、Books1、Books2和Wikipedia,总计超过570GB的文本数据。研究人员采用了巧妙的采样策略,让高质量数据集被更频繁地采样,确保模型接触到更多结构化、连贯的文本。
Few-shot学习的奇迹
GPT-3在few-shot学习方面的表现令人叹为观止。给它几个数学题的例子,它就能解决新的数学问题;给它几个翻译样本,它就能进行语言转换;甚至可以生成代码、写作文章、创作诗歌。
第四章:多模态巨人GPT-4(2023年)
视觉的力量
2023年GPT-4的发布标志着大语言模型进入了多模态时代。GPT-4不仅能理解文本,还能"看见"图像,这为AI应用开辟了全新的可能性。

架构优化和效率提升
虽然OpenAI没有公布GPT-4的确切参数数量,但研究显示它在参数效率方面有了显著提升。通过稀疏性技术和更精细的架构设计,GPT-4在不成比例增加参数的情况下实现了性能飞跃。
更可靠,更安全
GPT-4在减少幻觉和偏见方面取得了重要进展。通过更好的训练策略和安全对齐技术,它能够提供更加准确和可靠的回答。
第五章:Chain-of-Thought推理的革命
让AI学会"思考"
在GPT系列的发展过程中,一个重要的突破是Chain-of-Thought(CoT)推理的出现。研究表明,通过引导模型展示中间推理步骤,可以显著提升其在复杂任务上的表现。
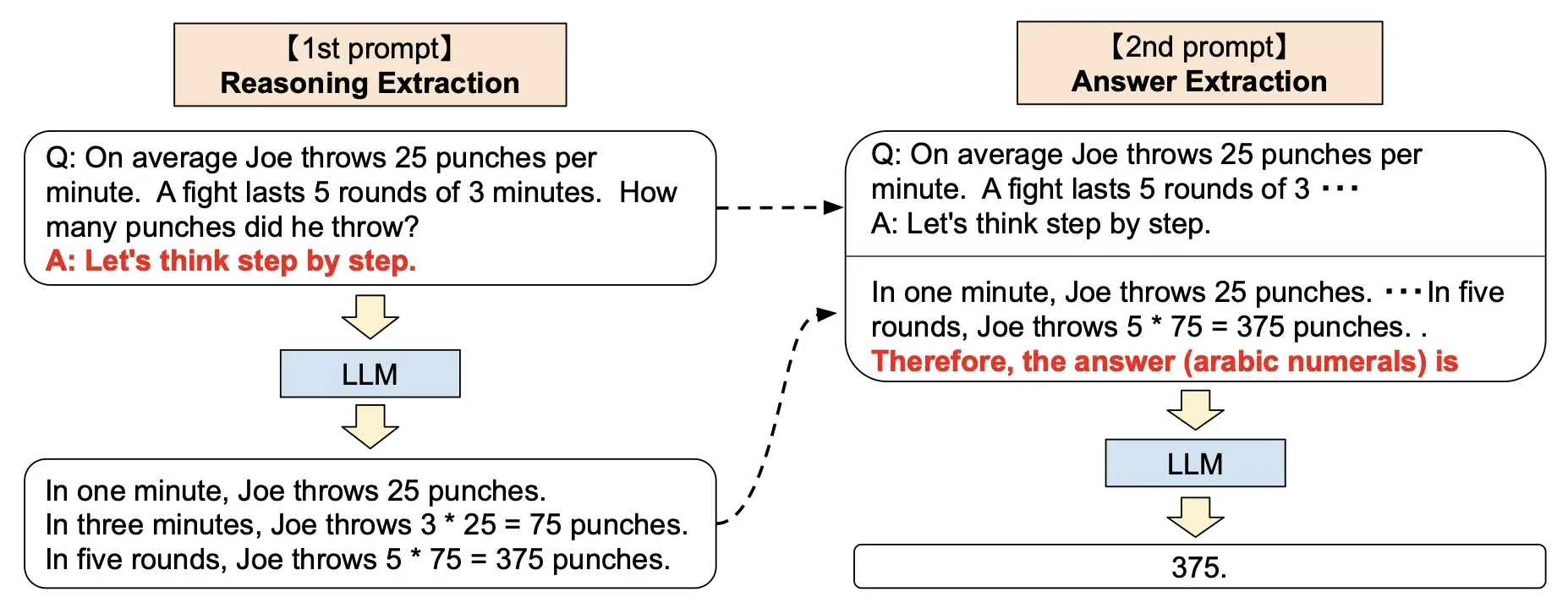
Zero-shot CoT的神奇魔法
更令人惊讶的是Zero-shot CoT的发现。研究人员发现,仅仅在提示中加入"让我们一步步思考"这样的话,就能激发模型的推理能力。这个简单得近乎魔法的技巧体现了大语言模型中蕴含的潜在能力。
第六章:未来的召唤——GPT-5及beyond
涌现能力的预期
随着模型规模的不断扩大,研究人员观察到了一个有趣的现象:某些能力似乎在达到特定规模后突然"涌现"出来。这些涌现能力包括复杂推理、代码生成、甚至是创造性思维。
技术挑战与机遇
GPT-5的发展面临着诸多挑战:计算资源的限制、训练数据的质量和多样性、模型的可解释性和安全性等。但每一个挑战都可能催生新的技术突破。
环境与伦理考量
随着模型规模的增长,计算资源的消耗和环境影响也成为重要考量。如何在追求性能的同时保持可持续发展,是整个行业需要思考的问题。
尾声:从小不点到巨人的启示
回顾GPT家族从117M参数的小不点成长为千亿级参数巨人的历程,我们看到的不仅仅是技术的进步,更是人类对智能本质理解的深化。
每一代GPT都在告诉我们:智能不是一蹴而就的,而是在不断的学习、优化和突破中逐渐涌现的。从GPT-1的初次尝试,到GPT-2的zero-shot惊喜,从GPT-3的few-shot奇迹,到GPT-4的多模态突破,每一步都是人类向着通用人工智能迈进的坚实脚印。
这个故事还远没有结束。当我们站在GPT-5的门槛上,回望来时的路,不禁要问:下一个突破会在哪里?下一个涌现能力又会是什么?
也许答案就在不远的将来,在某个普通的日子里,当研究人员们再次围坐在屏幕前,见证着新一代模型展现出前所未有的能力时,我们会再次感叹:原来,智能的边界远比我们想象的更加广阔。
技术要点回顾
架构演进:
- GPT-1: 12层, 117M参数, Decoder-only架构奠基
- GPT-2: 48层, 1.5B参数, Zero-shot学习突破
- GPT-3: 96层, 175B参数, In-context learning革命
- GPT-4: 多模态能力, 参数效率优化
学习范式:
- Zero-shot: 无示例学习
- Few-shot: 少样本学习
- Chain-of-Thought: 思维链推理
数据集进化:
- BookCorpus → WebText → 多样化语料库 → 多模态数据
这就是GPT家族的成长故事——一个关于好奇心、创新精神和不懈追求的技术传奇。在这个快速发展的AI时代,我们都是这个故事的见证者和参与者。