想象一下,你正在和朋友玩"20个问题"的游戏。你的朋友心中想着一个动物,而你需要通过不超过20个是非问题来猜出答案。每一个问题都像是在庞大的可能性空间中画下一道分界线:"它是哺乳动物吗?" "它会飞吗?" "它生活在水中吗?" 这个看似简单的游戏,其实就蕴含着决策树算法的核心思想。
网页版: https://ygypgtgq.gensparkspace.com/
视频版:https://www.youtube.com/watch?v=TYDh6DiLv5E
音频版:https://notebooklm.google.com/notebook/181b8a41-bc8a-465d-9887-ebf9e822b991/audio
在机器学习的世界里,决策树就像一个经验丰富的侦探,通过一系列精心设计的问题,逐步缩小嫌疑范围,最终锁定真相。但更神奇的是,当这些"侦探"们团结起来,形成一个强大的团队时,他们解决问题的能力会呈指数级增长。这就是我们今天要探讨的故事——从单一的决策树到强大的集成方法的演进之路。
三位不同性格的"侦探":ID3、C4.5与CART
在决策树的发展历程中,有三位具有代表性的"侦探",他们各有不同的问话风格和思维方式。
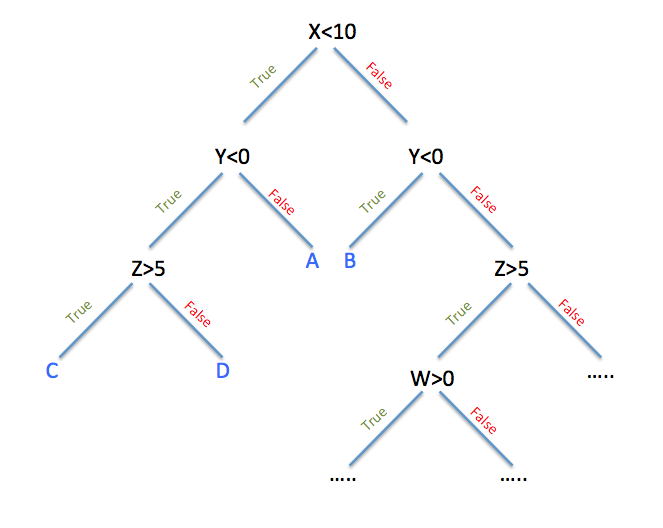
ID3:那个直白的年长侦探
ID3(Iterative Dichotomiser 3)就像一位经验丰富但思维方式相对简单的老侦探。他最大的特点是直截了当——总是选择能够带来最大信息增益的问题来提问。
当ID3面对一堆混乱的数据时,他会问自己:"哪个问题能让我最快地理清思路?" 他使用信息熵这个数学工具来衡量混乱程度。想象一个装满不同颜色球的袋子,如果袋子里全是红球,那么混乱度为0(完全有序);如果红球和蓝球各占一半,那混乱度最大。ID3就是要找到那个能最大程度减少混乱的问题。
但ID3也有自己的局限性。他只能处理离散的特征(比如颜色、类别),面对连续的数值(比如身高、体重)时就显得束手无策。而且,他对于缺失数据也没有很好的处理方式,就像一个不够灵活的老派侦探。
C4.5:进化后的全能侦探
C4.5是ID3的继承者,可以说是一个全面升级的版本。如果说ID3是一位经验丰富但略显古板的老侦探,那么C4.5就是一位既有经验又懂得变通的资深探员。
C4.5最大的改进在于引入了"增益率"的概念。原来的ID3在面对某些问题时会出现偏见,比如过分偏爱那些有很多分支的特征。就像一个侦探如果总是问非常细节的问题,虽然每个问题都能得到明确答案,但可能偏离了解决问题的主线。
更重要的是,C4.5学会了处理连续数值。当面对"年龄"这样的连续特征时,C4.5会灵活地找到最佳分割点,比如"年龄是否大于30",将连续问题转化为离散判断。同时,C4.5还具备了处理缺失数据的能力,不会因为某些信息的缺失而无所适从。
CART:那个精确的完美主义者
CART(Classification and Regression Trees)则是三者中最为精确和灵活的一位。如果前两位是专门处理分类问题的侦探,那么CART就是一个既能分类又能做数值预测的全能型选手。
CART有一个独特的特点:无论面对什么问题,他总是倾向于给出二分的答案。就像一个习惯了"是"或"不是"思维方式的人,CART总是将复杂问题简化为最基本的二元选择。这种方式让决策过程更加清晰和易于理解。
在处理分类问题时,CART使用基尼不纯度作为评判标准。基尼不纯度可以理解为"随机选择两个样本,它们属于不同类别的概率"。这个指标比信息熵计算更简单,在实际应用中往往更加高效。
但CART最令人印象深刻的能力是它的"后悔"机制——剪枝。CART会先毫无保留地生长到最大程度,然后冷静地回顾自己的决策,将那些过于复杂、容易导致过拟合的分支剪掉。这就像一个完美主义者先做到极致,再精益求精地优化。

信息的价值:如何问出最有价值的问题
决策树的核心在于如何选择最有价值的问题。这就像一个游戏节目的主持人,需要设计出最能区分参赛者的问题。
信息增益:ID3的选择标准
信息增益的计算基于信息熵的概念。设想你有一个班级,其中60%的学生喜欢数学,40%的学生不喜欢。这个班级的信息熵就是:
H(S) = -0.6 × log₂(0.6) – 0.4 × log₂(0.4) ≈ 0.971
现在你想通过一个问题来更好地理解学生的偏好。假设你问"你是否是理科生?",结果发现理科生中80%喜欢数学,文科生中只有20%喜欢数学。这个问题的价值就是原始熵减去加权后的熵,这就是信息增益。
基尼不纯度:CART的判断依据
基尼不纯度提供了另一种衡量混乱程度的方法。对于同样的班级,基尼不纯度为:
Gini = 1 – (0.6² + 0.4²) = 1 – (0.36 + 0.16) = 0.48
基尼不纯度的直观含义是:如果随机选择班级中的两个学生,他们对数学态度不同的概率。数值越小,说明群体越纯净。
这两种方法在实际应用中往往得出相似的结果,但基尼不纯度的计算更简单,这就是为什么许多现代算法(如随机森林)更倾向于使用它的原因。
过拟合的烦恼与剪枝的智慧
决策树有一个天生的"毛病"——它们太过于认真了。就像一个过分细致的学生,会记住教科书上的每一个细节,包括那些可能是印刷错误的地方。在机器学习中,这被称为过拟合。
想象一个学习开车的人,如果他把驾校练习场的每一个细节都牢记在心——比如第三个路障左边有个小石子,第五个路障右边的线有点歪——那么当他在真实道路上驾驶时,这些过于具体的"经验"不仅没用,反而可能成为负担。
剪枝:决策树的"减肥"计划
为了解决这个问题,研究者们开发了剪枝技术。剪枝就像给决策树进行"减肥",去除那些过于细节化、对整体性能贡献不大的分支。
剪枝分为两种:预剪枝和后剪枝。预剪枝就像在树生长过程中就进行控制,比如限制树的最大深度,或者要求每个叶子节点至少包含一定数量的样本。后剪枝则是让树先充分生长,再回过头来精简,这正是CART所采用的策略。
后剪枝的过程就像一个艺术家雕刻雕像:先用粗糙的工具勾勒出大致轮廓,再用精细的工具慢慢修饰细节。CART会计算每个子树的复杂度成本,如果移除某个子树后整体性能没有明显下降,就果断地将其剪掉。
从孤军奋战到团队协作:集成学习的诞生
虽然单个决策树已经相当强大,但真正的突破来自于一个简单而深刻的想法:为什么不让多个决策树一起工作呢?就像俗话说的"三个臭皮匠,顶个诸葛亮",多个普通的决策树组合起来,往往能产生惊人的效果。
这个想法催生了集成学习方法,其中最著名的两大家族就是Bagging(自举聚集)和Boosting(提升方法)。
Bagging:民主投票的智慧
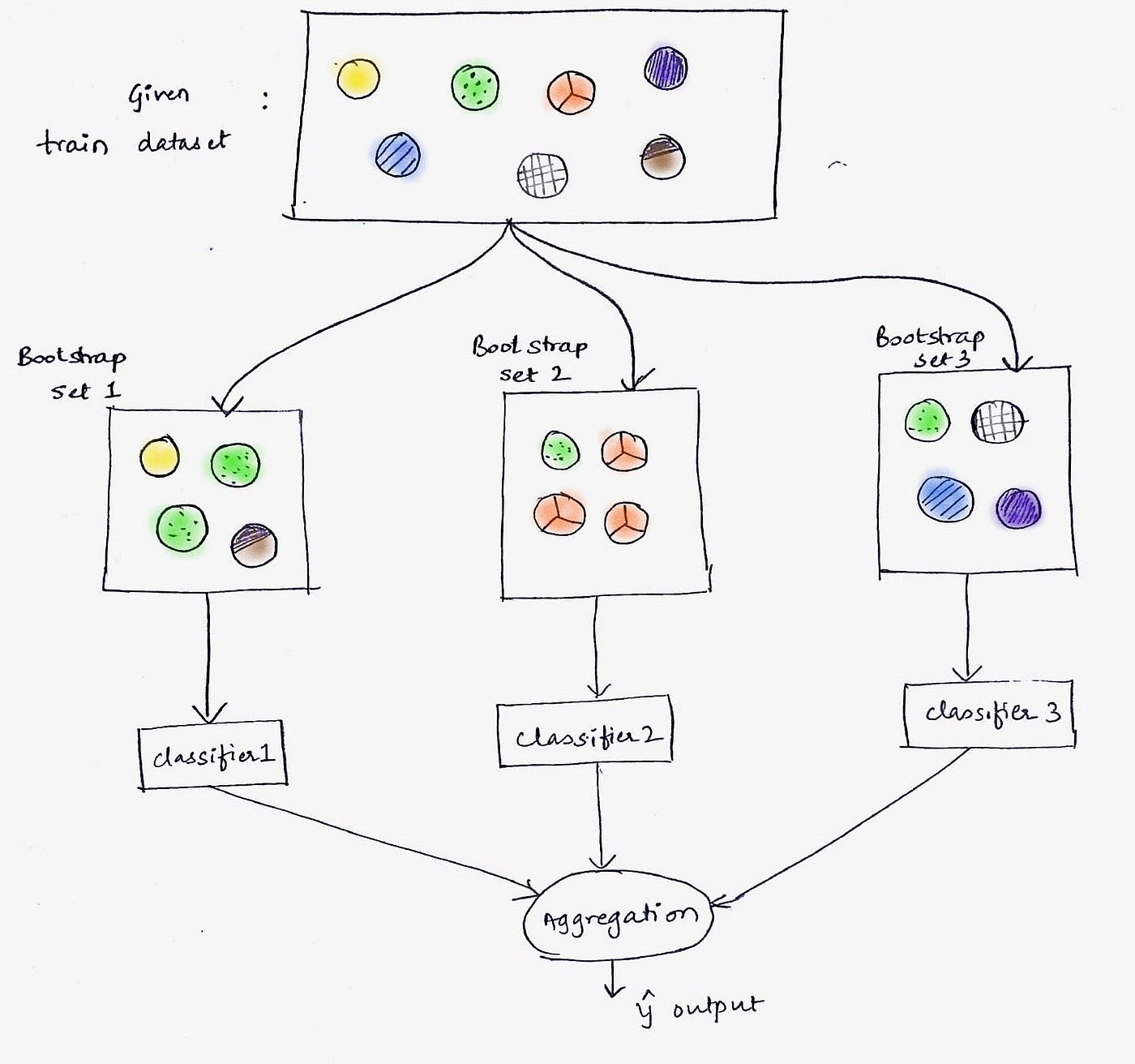
Bagging的思想非常朴素:既然一个人的判断可能有偏差,那么我们让多个人独立判断,然后通过投票来决定最终结果。这就像陪审团制度——每个陪审员独立思考,最后通过投票达成共识。
随机森林:最成功的民主实验
随机森林是Bagging思想最成功的实现之一。它的工作原理就像组织一场大规模的民意调查:
首先,从原始数据集中随机抽取若干个子集(允许重复抽样),就像从总人口中随机选择多个样本群体。然后,为每个子集训练一个决策树,但这里有个巧妙的设计——每个树在选择分裂特征时,只能从所有特征的一个随机子集中选择。
这个设计非常关键。想象一个调查中,如果所有调查员都倾向于问同样的问题,那么即使样本不同,得出的结论也可能高度相似。随机森林通过限制每个树可以考虑的特征,确保了树与树之间的多样性。
当需要做预测时,随机森林会询问所有的树,然后采用多数投票(分类问题)或平均值(回归问题)作为最终答案。这种方法的威力在于:即使个别树可能出错,但只要大多数树的判断是正确的,最终结果就是可靠的。
根据机器学习理论,随机森林主要解决的是方差问题。单个决策树容易过拟合,表现不稳定,但多个树的平均结果会更加稳定可靠。这就像投资组合的道理——单一股票风险很大,但分散投资的组合风险相对较小。
Boosting:从错误中学习的艺术
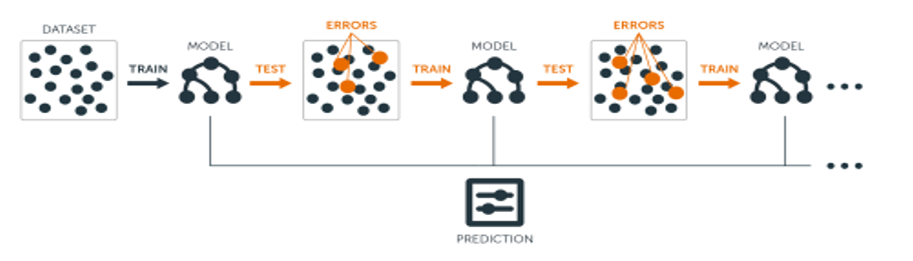
如果说Bagging是民主投票,那么Boosting就更像是一个不断进步的学习过程。Boosting的核心思想是:让后面的学习者专门关注前面学习者犯错的地方。
AdaBoost:自适应的提升大师
AdaBoost(Adaptive Boosting)是Boosting家族的开山鼻祖,它的工作方式就像一个严格但智慧的老师。
想象一个班级在学习一个复杂的数学概念。第一个学生(弱学习器)尝试解决所有问题,但肯定会犯一些错误。AdaBoost这位老师会特别关注这些错误,在下一轮学习中,会增加错误题目的权重,让第二个学生更多地关注这些难题。
这个过程不断重复:每一轮都会产生一个新的学习器,专门针对前面所有学习器的弱点进行改进。最终,所有学习器的组合效果会远超任何单个学习器。
AdaBoost的数学原理基于一个重要观察:即使每个弱学习器只比随机猜测稍微好一点,通过适当的加权组合,也能得到任意高精度的强学习器。这个理论结果在当时引起了机器学习界的轰动。
梯度提升:更加灵活的改进者
梯度提升(Gradient Boosting)将Boosting的思想推向了新的高度。如果说AdaBoost是通过调整样本权重来关注错误,那么梯度提升则是直接让新的学习器去拟合前面所有学习器的残差(预测值与真实值的差异)。
这就像一个精益求精的工匠:第一次雕刻后,仔细观察作品与理想形象的差距,然后专门针对这些差距进行第二次精修。每一次修正都让作品更接近完美。
从数学角度看,梯度提升是在函数空间中进行梯度下降优化,这使得它能够适用于各种不同的损失函数,不仅可以做分类,还能做回归、排序等各种任务。
现代集成学习的王者:XGBoost与LightGBM
在梯度提升的基础上,研究者们开发出了更加强大和高效的算法,其中最著名的就是XGBoost和LightGBM。
XGBoost:工程优化的典范
XGBoost(eXtreme Gradient Boosting)不仅是算法上的改进,更是工程实现的典范。它就像将一辆普通汽车改造成了一级方程式赛车——在保持核心功能的同时,在速度、效率和可靠性上都有了质的飞跃。
XGBoost的创新主要体现在几个方面:
首先是正则化的引入。传统的梯度提升容易过拟合,XGBoost通过在目标函数中加入正则化项,就像给高速行驶的汽车装上了更好的制动系统,既保证了性能,又避免了失控。
其次是并行计算的优化。虽然boosting本身是序列化的(必须等前一个模型完成才能训练下一个),但XGBoost巧妙地在特征选择和分割点查找阶段引入了并行计算,大大提升了训练速度。
最重要的是缺失值的自动处理。在真实世界的数据中,缺失值几乎是不可避免的。XGBoost能够自动学习缺失值的最佳处理方式,不需要预先进行复杂的数据预处理。
LightGBM:速度与精度的完美平衡
LightGBM(Light Gradient Boosting Machine)则在XGBoost的基础上进一步优化,特别是在处理大规模数据时表现卓越。
LightGBM最大的创新是GOSS(Gradient-based One-Side Sampling)技术。这个技术基于一个聪明的观察:在梯度提升中,梯度较大的样本对模型训练的贡献更大。因此,LightGBM会保留所有梯度较大的样本,只对梯度较小的样本进行随机采样。这就像在学习过程中重点关注难题,对简单题目适当放松要求,从而大大提高了训练效率。
另一个重要改进是EFB(Exclusive Feature Bundling)技术,它能够将相互排斥的特征打包在一起,减少特征数量,进一步提升训练速度。
偏差与方差:集成学习的理论基础
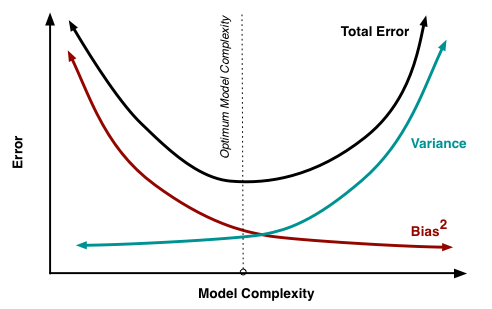
理解集成学习的威力,需要从偏差-方差权衡的角度来分析。这是机器学习中最重要的理论框架之一。
偏差(Bias)反映的是模型的预测值与真实值之间的差距。高偏差意味着模型过于简单,无法捕捉数据的复杂性,就像用直线去拟合曲线。
方差(Variance)反映的是模型对训练数据变化的敏感程度。高方差意味着模型过于复杂,对训练数据的微小变化都会产生截然不同的结果,就像一个过于敏感的人。
在这个框架下,Bagging和Boosting呈现出不同的特点:
Bagging主要解决方差问题。通过训练多个独立的模型并求平均,可以有效降低预测的方差,使结果更加稳定。随机森林就是这一思想的典型应用——每个决策树可能都有较高的方差,但它们的平均结果会更加稳定。
Boosting主要解决偏差问题。通过序列化地训练模型,每个新模型都专门针对前面模型的错误进行改进,可以逐步降低整体的偏差。AdaBoost和梯度提升都是这一思想的体现。
现代的高级算法如XGBoost和LightGBM,则通过各种技术手段在偏差和方差之间找到了更好的平衡点,这也是它们能够在各种竞赛和实际应用中取得优异表现的重要原因。
实战中的智慧:特征重要性与超参数调优
集成方法不仅在预测准确性上表现卓越,还提供了丰富的模型解释信息。其中最有价值的就是特征重要性分析。
特征重要性:找出真正的关键因素
在随机森林中,特征重要性的计算基于每个特征在所有树中的平均重要性。当某个特征被用来分裂节点时,会计算分裂前后不纯度的减少量,所有这些减少量的平均值就是该特征的重要性得分。
这就像在一个复杂的案件中,通过统计每个线索在破案过程中的贡献度,最终确定哪些线索是关键的,哪些是次要的。
在实际应用中,特征重要性分析常常能够提供意想不到的洞察。比如在预测客户流失的模型中,可能会发现客户的登录频率比收入水平更重要;在医疗诊断中,可能会发现某个看似不重要的指标实际上具有很强的预测能力。
超参数调优:寻找最佳配置
集成方法虽然强大,但也引入了更多的超参数需要调优。这就像调节一个复杂的乐器——需要精心调节每个部件,才能奏出美妙的音乐。
对于随机森林,主要的超参数包括:
- 树的数量(n_estimators):通常越多越好,但会增加计算成本
- 每次分裂考虑的特征数量(max_features):一般取特征总数的平方根
- 树的最大深度(max_depth):控制过拟合的重要参数
对于XGBoost,参数更加丰富:
- 学习率(learning_rate):控制每个树的贡献度
- 正则化参数(reg_alpha, reg_lambda):控制过拟合
- 子采样比例(subsample):增加模型的泛化能力
现代的自动化机器学习工具已经能够智能地进行超参数搜索,但理解每个参数的作用仍然是非常重要的,这能帮助我们更好地诊断和改进模型。
应用场景:从竞赛到产业
集成方法在各个领域都有广泛应用,特别是在处理结构化数据的问题上表现卓越。
在Kaggle等数据科学竞赛中,基于梯度提升的方法(XGBoost、LightGBM)几乎是必备武器。这些算法在处理中等规模的结构化数据时表现优异,往往能够在较少的特征工程工作下取得很好的效果。
在工业界,随机森林因其稳定性和可解释性而备受青睐。金融行业用它来进行信用评估,电商平台用它来进行推荐系统,医疗领域用它来辅助诊断。
Uber在其机器学习平台Michelangelo上大量使用梯度提升决策树来预测配送时间;Netflix使用随机森林来改进推荐算法;各大互联网公司都在使用这些方法来进行广告投放优化。
局限性与未来发展
尽管集成方法非常强大,但它们也有自己的局限性。
首先是模型复杂度和解释性的问题。虽然单个决策树很容易理解和可视化,但成百上千个树的组合就很难直观解释了。这在一些需要高度可解释性的领域(如医疗、金融)可能会成为问题。
其次是对数据质量的要求。集成方法虽然对噪声有一定的鲁棒性,但如果数据中存在系统性偏差或标签错误,这些问题会在所有子模型中重复出现。
在深度学习兴起的时代,集成方法在处理图像、文本等非结构化数据方面逐渐让位于神经网络。但在结构化数据的处理上,特别是在样本量相对较小、特征数量适中的场景下,集成方法仍然是最佳选择之一。
未来的发展方向可能包括:更好的自动化特征工程、与深度学习的结合、更高效的分布式训练算法、以及更好的模型解释性工具。
结语:从一棵树到一片森林的启示
决策树与集成方法的发展历程,实际上反映了人工智能发展的一个重要规律:从简单到复杂,从单一到多样,从独立到协作。
一棵决策树就像一个专家的判断,可能很准确,但也可能有盲点。一片森林则像一个专家团队,通过不同视角的综合,往往能够得出更可靠的结论。
这个过程也给我们很多启示。在解决复杂问题时,我们不应该过分依赖单一的方法或观点,而应该寻求多元化的视角和方法。正如随机森林通过引入随机性来增加多样性,我们在思考问题时也应该有意识地跳出固有思维模式,从不同角度审视问题。
Boosting方法教会我们的则是持续改进的重要性。每一次迭代都是在前一次的基础上改进,关注之前被忽视的问题。这种思维方式在很多领域都有价值——无论是个人成长还是产品开发,都可以采用这种渐进式改进的策略。
最终,从ID3到LightGBM的发展历程告诉我们,技术的进步往往不是革命性的突破,而是在坚实理论基础上的持续改进和工程优化。每一个小的改进都可能带来显著的整体提升,这正是科学研究和技术发展的魅力所在。
在这个数据驱动的时代,掌握决策树和集成方法不仅是技术能力的体现,更是一种思维方式的培养。当我们面对复杂的决策问题时,可以借鉴这些算法的智慧:系统地分析问题,寻找关键的区分特征,结合多种视角,持续改进判断。这样的思维方式,无论在技术工作还是日常生活中,都会帮助我们做出更好的决策。