最近有个朋友问我,"现在到底哪个开源大模型最厉害",这让我想起了几个月前参加一场AI开发者聚会时的场景。当时台下坐着的都是写代码写到凌晨的程序员们,大家讨论得最热烈的话题竟然不是最新的商业模型,而是那些可以自由使用、随意修改的开源模型。
视频版:https://www.youtube.com/watch?v=0EbM6VVBZOc

那一刻我忽然意识到,我们正在见证一场前所未有的技术民主化运动。
Meta的"405B炸弹":开源界的新王者
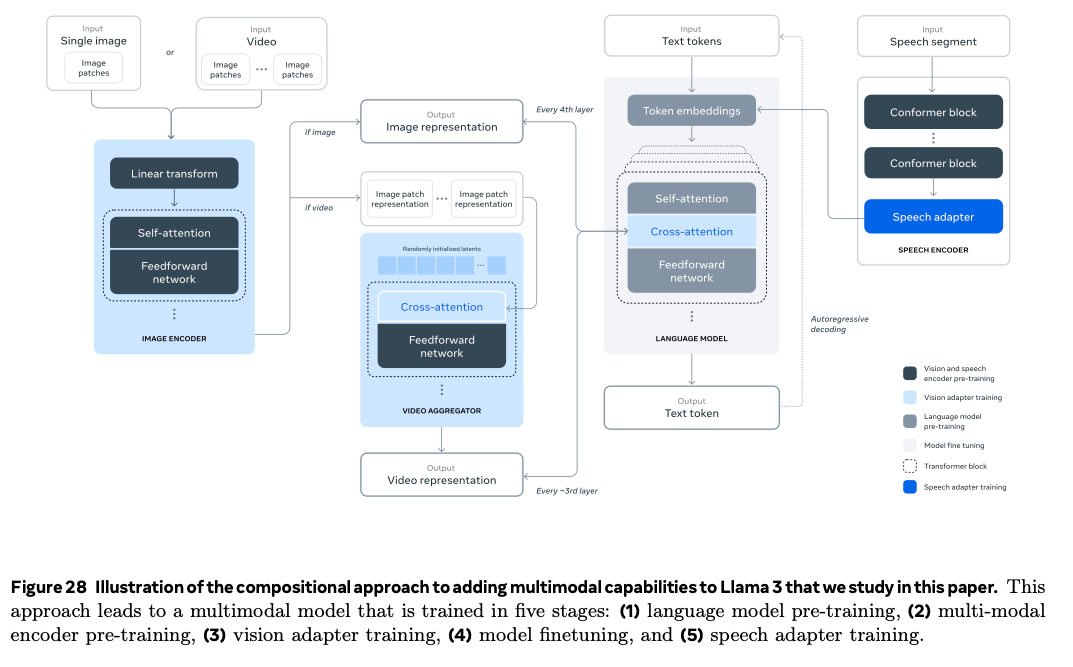
今年7月,Meta突然宣布开源LLaMA 3.1系列模型,其中包括一个拥有405B参数的巨无霸。当这个消息传出时,整个AI社区都沸腾了。
要知道,405B参数意味着什么?这是目前可以公开获取的最大开源模型,它的规模已经接近GPT-4的水平。更令人惊喜的是,LLaMA 3.1不仅提供了405B的旗舰版本,还有更实用的8B和70B版本,就像是给不同配置的电脑都准备了合适的"大脑"。
最让开发者兴奋的是它的128K上下文窗口。想象一下,你可以一次性让模型读完一本中篇小说,然后和它讨论里面的每一个细节。这种长上下文能力在实际应用中的价值,简直就像是给AI装上了长期记忆。
根据AWS的官方数据,LLaMA 3.1在多项基准测试中都表现出色,特别是在数学推理和代码生成方面,已经达到了商业模型的竞争水平。
Mistral Large 2:小而美的法式优雅

如果说LLaMA 3.1是力量型选手,那么来自法国的Mistral Large 2就是技巧型选手了。这个只有123B参数的模型,却能在很多任务上与405B的大哥们分庭抗礼。

这让我想起了欧洲汽车和美国汽车的区别。美国车追求马力,欧洲车讲究效率和精致。Mistral Large 2就像一辆精工细作的德系车,虽然排量不是最大的,但每一个参数都被调教得恰到好处。
技术报告显示,Mistral Large 2在编程任务上的表现尤其出色,在HumanEval编程基准上达到了92%的成绩。更重要的是,它的128K上下文窗口和对80多种编程语言的支持,让它成为了开发者最喜爱的工具之一。
有趣的是,Mistral团队特别强调了"single-node inference"的概念,意思是你可以在单台机器上运行这个模型,而不需要分布式部署。这对于个人开发者来说,简直就是福音。
ChatGLM-4:国产之光的崛起
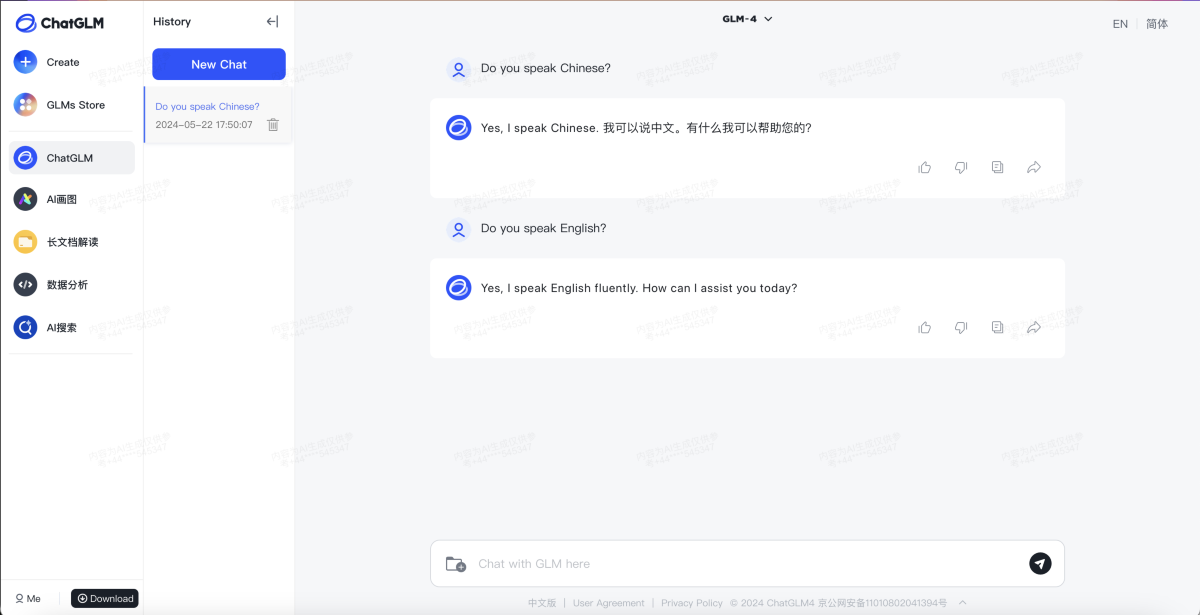
在这场开源大模型的竞赛中,中国团队也不甘示弱。智谱AI推出的ChatGLM-4系列,被誉为"国产最强大模型之一",这可不是吹牛。
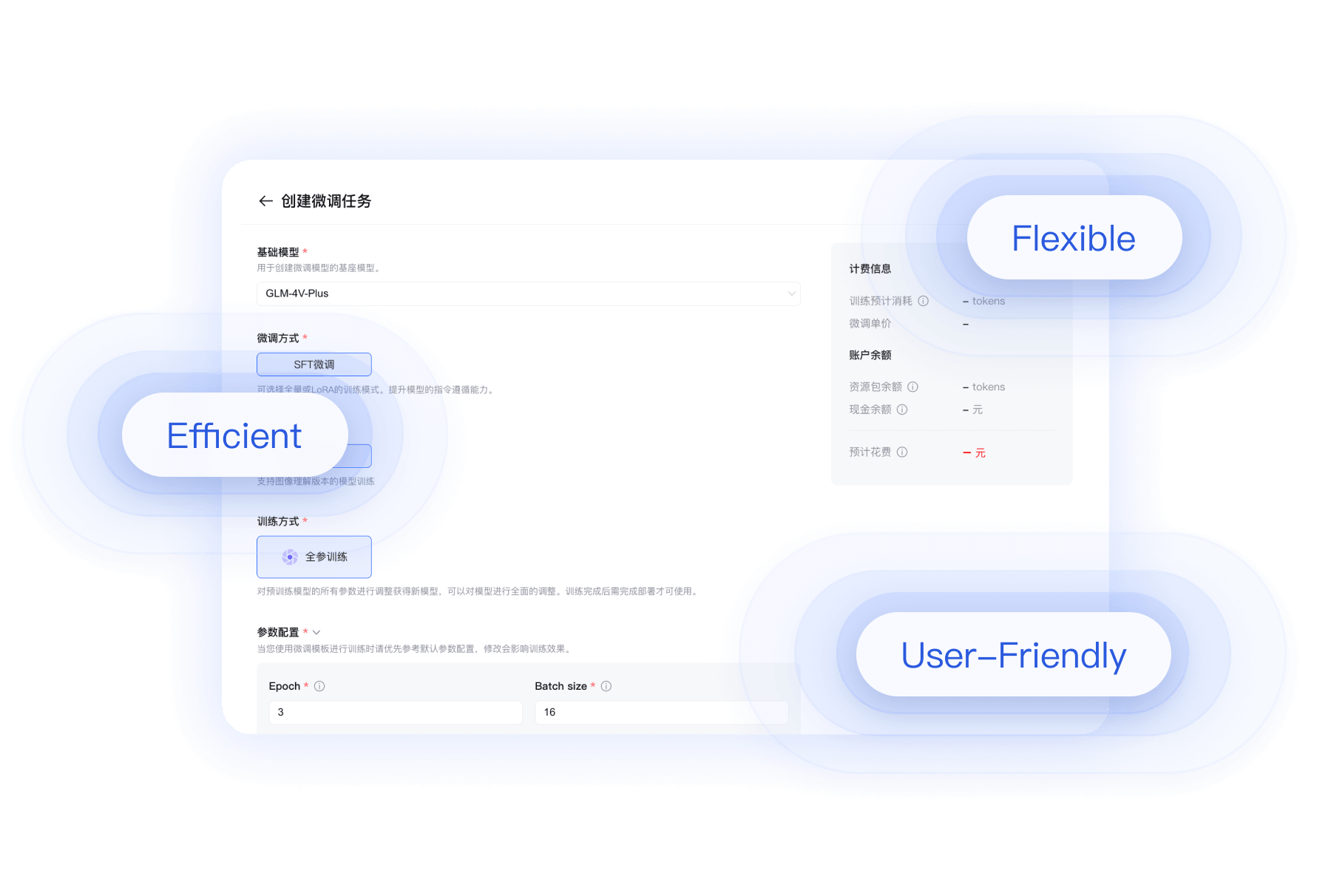
根据最新的评测数据,GLM-4在中文理解和生成方面的表现已经接近甚至超越了GPT-4 Turbo。特别是在AlignBench的八个维度评测中,GLM-4都表现出色,这说明它不仅仅是参数规模的堆叠,而是真正在模型架构和训练方法上有所创新。
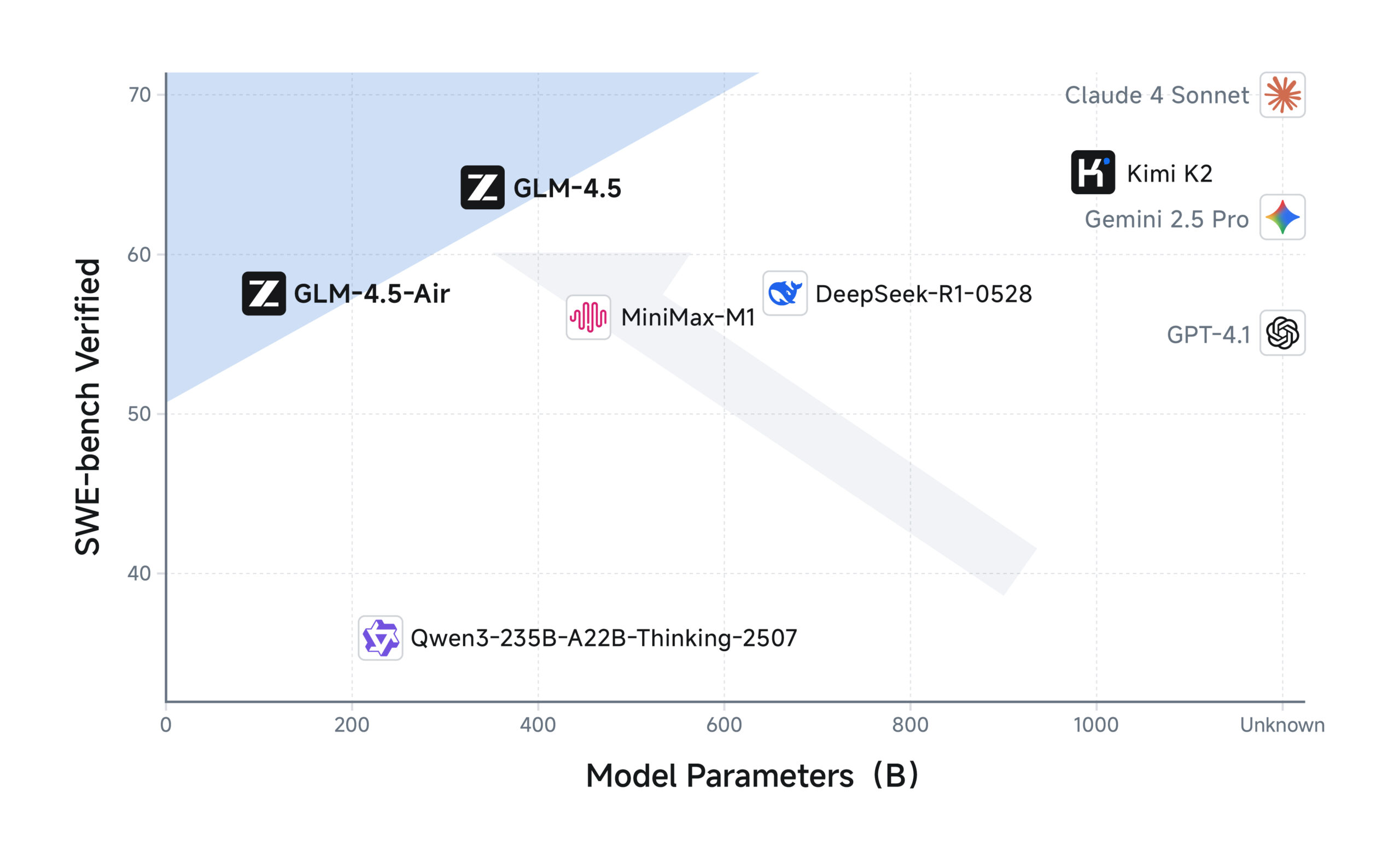
最让人印象深刻的是它在MMLU(大规模多任务语言理解)基准上的表现,达到了88.5的高分,这个成绩已经可以和国际顶尖模型并驾齐驱了。更重要的是,ChatGLM-4对中文的深度理解让它在处理中文任务时有着天然的优势。
Yi系列:零一万物的野心
01.AI(零一万物)推出的Yi系列模型,虽然在国际知名度上不如前面几位,但在中文大模型基准测评中的表现却让人刮目相看。
Yi-1.5-34B-Chat这个名字可能听起来有些拗口,但它的实力却不容小觑。根据GitHub上的技术报告,Yi-1.5相比前代模型在编程、数学、推理和指令遵循能力上都有了显著提升。
有意思的是,在Reddit的LocalLLaMA社区中,Yi-1.5-34B一度成为30B参数级别中排名最高的开源模型。虽然后来有用户反馈说实际使用体验可能因任务而异,但这也说明了不同模型都有自己的特色和适用场景。
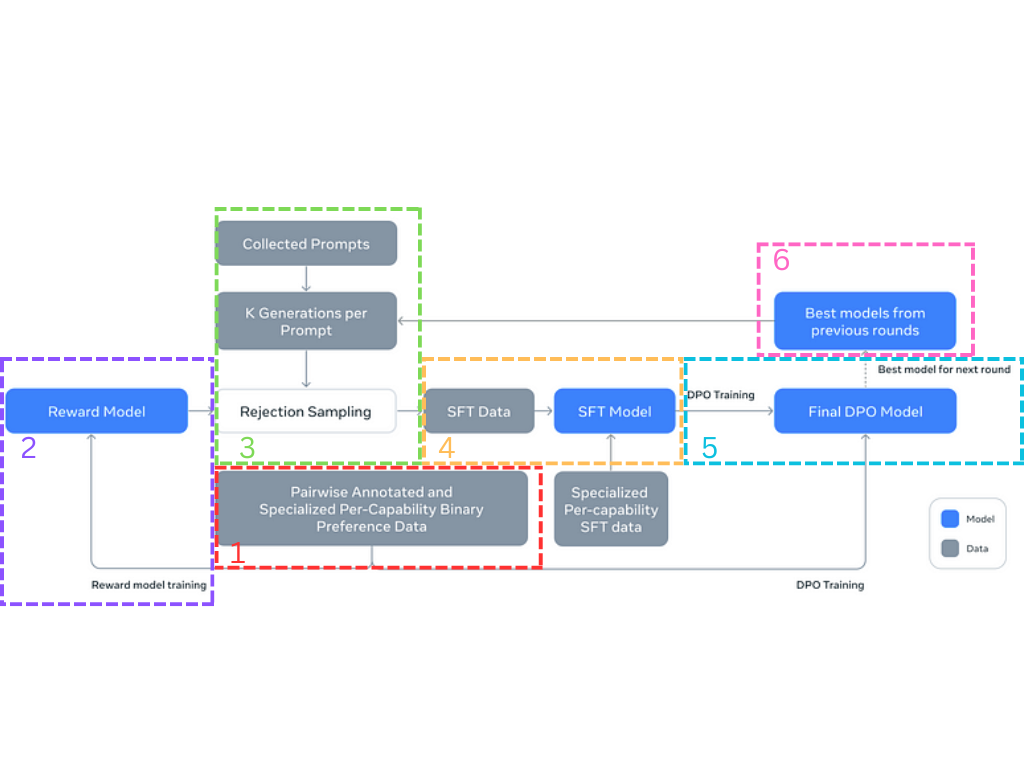
本地部署的两大神器:让AI住进你的电脑
有了这些优秀的开源模型,下一个问题就是:怎么把它们"请"到自己的电脑里?
Ollama:让AI变得触手可及

Ollama可能是目前最受欢迎的本地部署工具了。如果把部署大模型比作做菜,那么Ollama就像是一台全自动的料理机,你只需要告诉它你想要什么,剩下的它都帮你搞定。
我第一次使用Ollama的时候,真的被它的简单程度震惊了。只需要一行命令ollama run llama3.1,就能在几分钟内启动一个本地的大模型服务。这种体验就像是从繁琐的手工劳动一下子跳到了自动化时代。

根据官方文档,Ollama支持几乎所有主流的开源模型,包括我们刚才提到的LLaMA、Mistral、DeepSeek等等。更重要的是,它会自动处理模型的下载、量化和内存管理,让你可以专注于应用开发而不是底层技术。
vLLM:生产级的性能怪兽
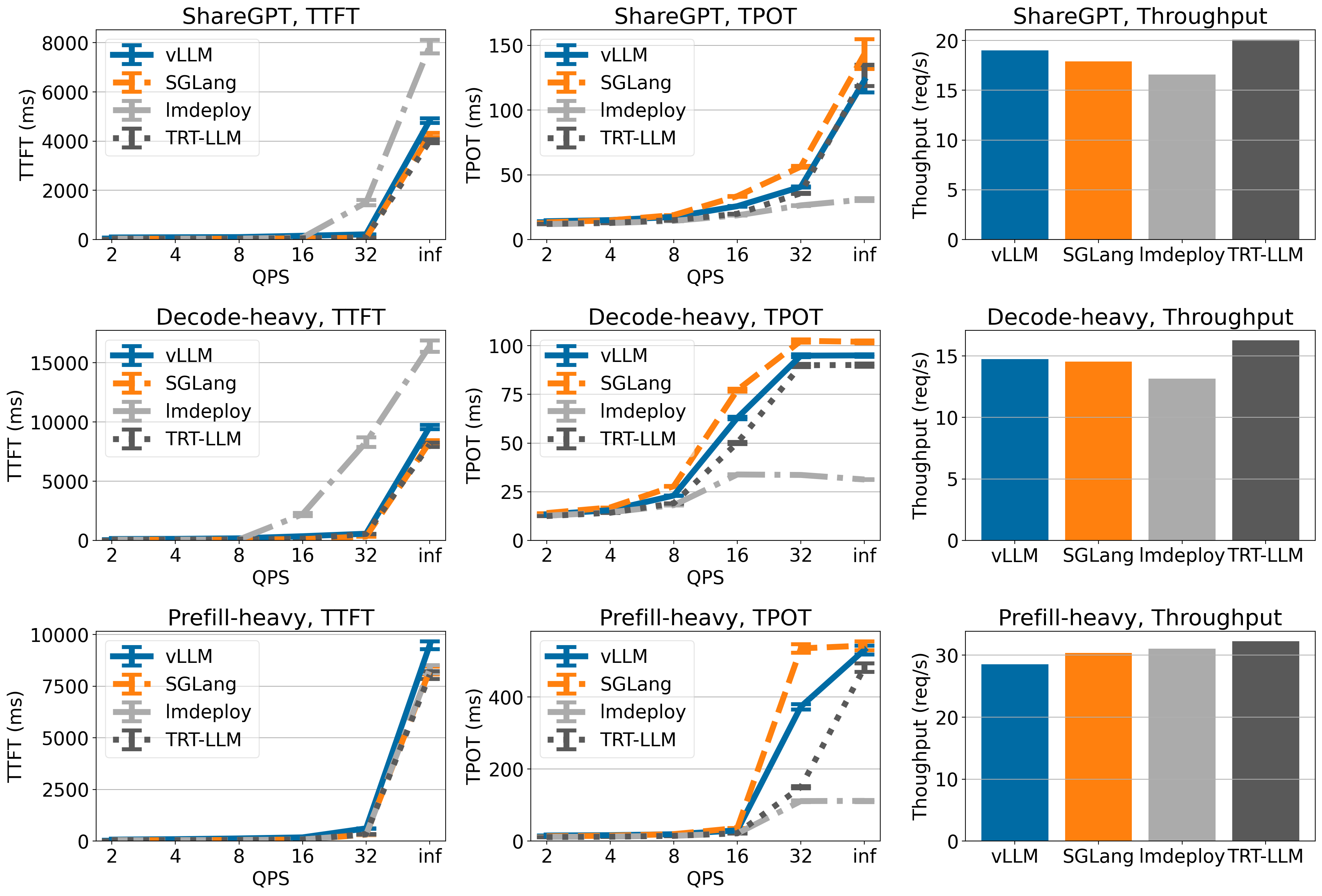
如果说Ollama是为了易用性而生,那么vLLM就是为了极致性能而来。这是一个专门为大语言模型推理优化的高性能引擎。

vLLM的设计哲学很有趣:它不追求功能的全面,而是专注于把一件事做到极致。在最近的性能测试中,vLLM在处理Qwen2.5模型时相比传统方法有23%的性能提升,这对于需要大量推理的生产环境来说意义重大。
特别是当你需要同时处理多个请求时,vLLM的优势就更明显了。它采用了一种叫做"PagedAttention"的技术,可以像操作系统管理内存一样高效地管理GPU显存,让你能用更少的硬件资源处理更多的请求。
实操指南:5分钟上手Ollama
让我为你演示一下如何快速上手Ollama。首先,看看这个来自Tech With Tim的详细教程:

这个视频已经有超过50万的观看量,可见Ollama的受欢迎程度。整个安装过程非常简单:
- 访问Ollama官网下载安装包
- 安装完成后,打开终端输入
ollama run llama3.1 - 等待几分钟下载完成,就可以开始对话了
这里还有一个来自IBM Technology的快速入门视频:

性能大比拼:数字背后的真相
说了这么多,可能你会好奇:这些模型到底谁更厉害?
根据最新的基准测试数据,在MMLU(多任务语言理解)测试中:
- LLaMA 3.1 405B: 88.6分
- Mistral Large 2: 84.0分
- ChatGLM-4: 88.5分
- Yi-1.5-34B: 在30B级别中表现最佳
但是,基准测试只是一个参考。就像考试成绩不能完全代表一个学生的能力一样,真正的应用场景往往更加复杂和多样化。
比如,如果你主要处理中文任务,ChatGLM-4可能是更好的选择;如果你注重部署效率和资源消耗,Mistral Large 2会更合适;如果你需要处理复杂的多轮对话或长文档分析,LLaMA 3.1的大上下文窗口就显得很有价值。
社区的力量:开发者们的创意无限

最让我感动的是开源社区的创造力。在GitHub上,你能看到无数基于这些开源模型的创新项目:有人用LLaMA做了一个智能客服系统,有人用Mistral构建了代码审查工具,还有人用ChatGLM-4开发了中文写作助手。
这些项目的共同特点是:它们都是免费的、开源的,任何人都可以使用和改进。这就是开源精神的魅力所在——当技术不再被垄断,创新就会如雨后春笋般涌现。
开源精神的胜利
回想起那个开发者聚会,我忽然明白了为什么大家对开源模型如此热情。这不仅仅是技术的进步,更是一种价值观的体现。
在专有模型垄断的时代,AI技术就像是被关在象牙塔里的贵族,只有少数大公司能够享用。而开源模型的出现,就像是把这些技术从高台上请了下来,让每一个有想法的开发者都能够参与到AI革命中来。
今天,一个大学生可以用自己的笔记本电脑运行一个几十亿参数的大模型;一个小创业公司可以基于开源模型开发出媲美大厂产品的应用;一个研究者可以自由地修改和优化模型算法,推动整个领域的发展。
这种技术民主化的力量,正在重新定义AI的未来。而我们,正是这场革命的见证者和参与者。
当我写下这篇文章的时候,新的开源模型可能正在某个实验室里诞生,新的部署工具可能正在某个程序员的电脑上编译。这就是开源世界的魅力:它永远在进步,永远充满惊喜,永远向所有人敞开怀抱。
或许下一次开发者聚会上,我们讨论的又会是全新的模型和工具。但有一点我很确定:开源精神会继续照亮AI发展的道路,让技术真正成为改变世界的力量。
相关资源链接:
如果您对开源大模型感兴趣,建议关注相关社区动态,这个领域的发展速度非常快,新的突破几乎每个月都在发生。