想象一下,你刚刚训练完一个机器学习模型,就像培养了一个学生经过了漫长的学习过程。现在到了最关键的时刻——考试。但这不是普通的考试,而是一场全方位的"体检",要从各个角度检验这个"学生"的真实水平。
网页版:https://ickggyoy.gensparkspace.com/
视频版:https://www.youtube.com/watch?v=Noe5_kvyZ7c
音频版:https://notebooklm.google.com/notebook/2dd29366-0bb6-432d-a1c7-82bd70365d62/audio
这就是模型评估的精髓所在。就像医生不会仅凭一个指标就判断病人的健康状况一样,我们也不能仅仅依靠单一指标来评判模型的好坏。每个评估指标就像是一台专门的检测设备,从不同的维度窥探模型的"内心世界"。
分类模型的四重奏:准确率的大家庭
在机器学习的世界里,分类任务就像是让模型做选择题。而评估这些选择的对错,我们有一套精妙的工具组合。
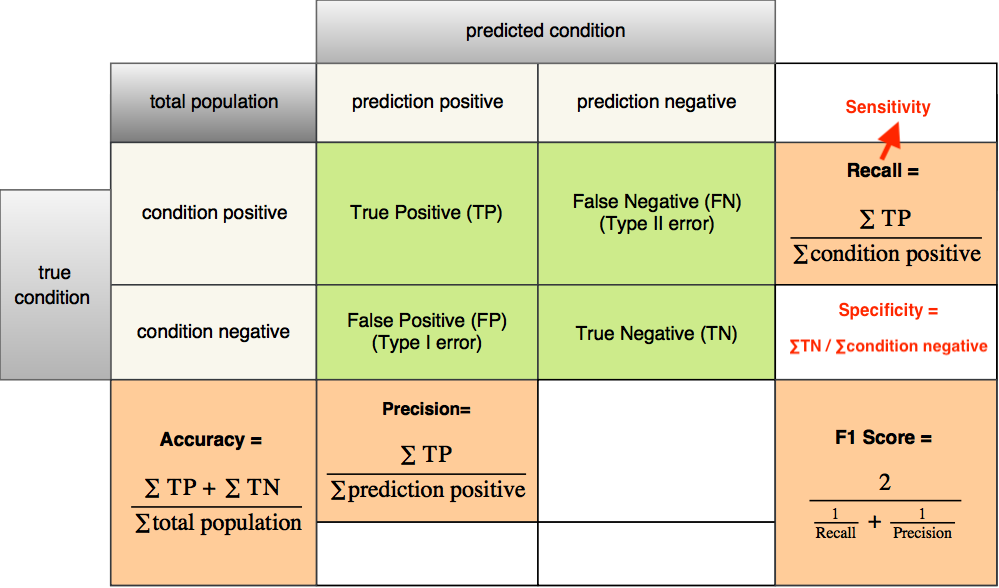
准确率(Accuracy),这是最直观的指标,就像是考试的总体得分。根据Google机器学习速成课程的说明,准确率告诉我们模型总共答对了多少道题。但这个看似完美的指标却有一个致命弱点——当数据不平衡时,它就像是一个会说谎的体重秤。
想象一个场景:如果你要检测罕见疾病,在1000个人中只有10个病人。一个"聪明"的模型可能选择把所有人都判断为健康,这样就能获得99%的准确率,但却完全失去了实际意义。
这时候,**精确率(Precision)和召回率(Recall)**就像是两个更加细心的检察官。精确率问的是:"在所有被判断为阳性的案例中,真正阳性的比例是多少?"而召回率则关心:"在所有真正的阳性案例中,被正确识别出来的比例是多少?"
根据Medium上的深入分析,这两个指标就像是天平的两端——提高精确率往往会降低召回率,反之亦然。这种矛盾关系在现实世界中随处可见:垃圾邮件过滤器如果过于严格(高精确率),可能会把重要邮件误判为垃圾邮件(低召回率)。
F1分数就是这场博弈的调解员,它是精确率和召回率的调和平均数。这个聪明的指标不允许任何一方"独大"——只有当精确率和召回率都表现良好时,F1分数才会给出高分。
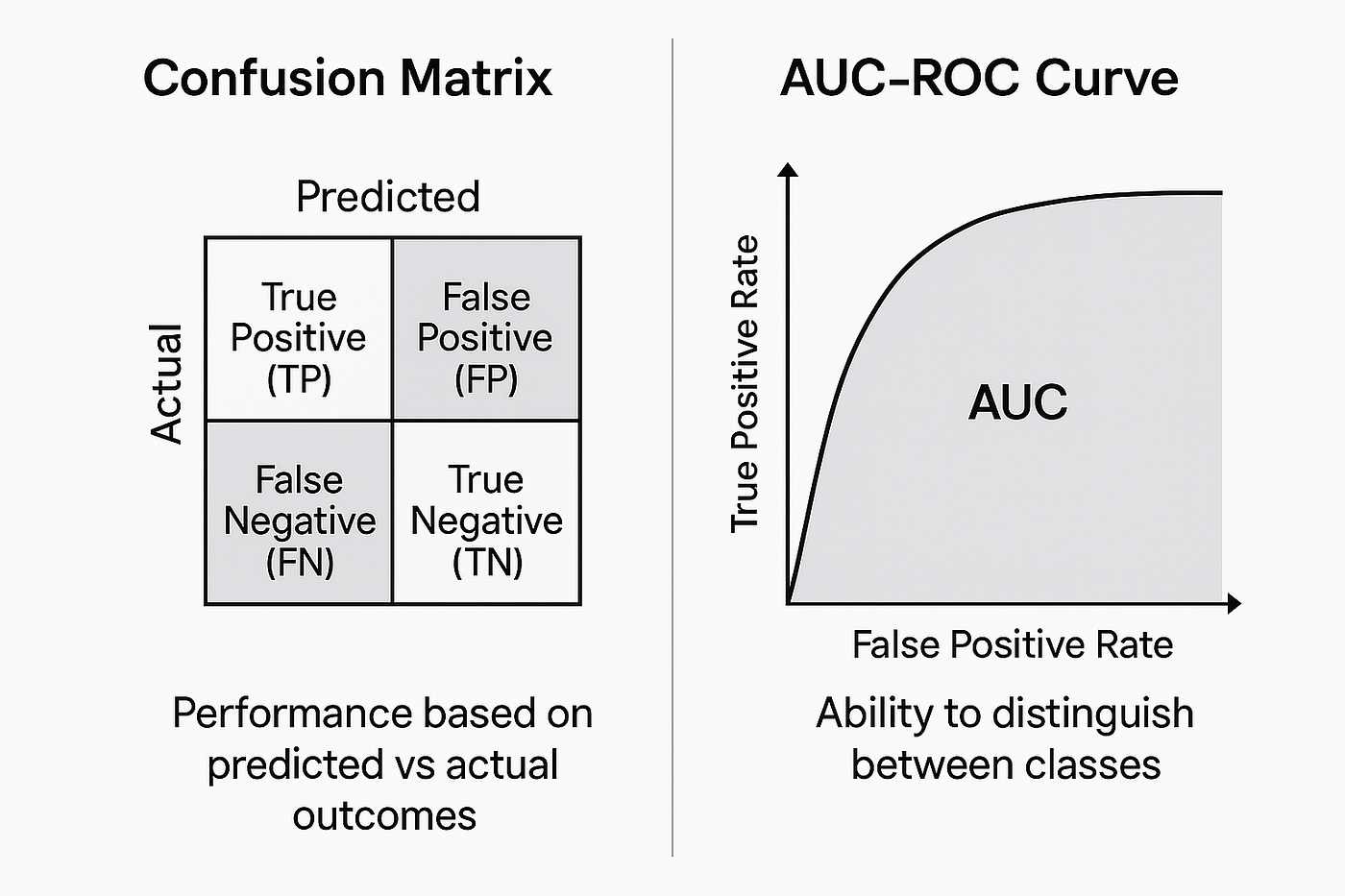
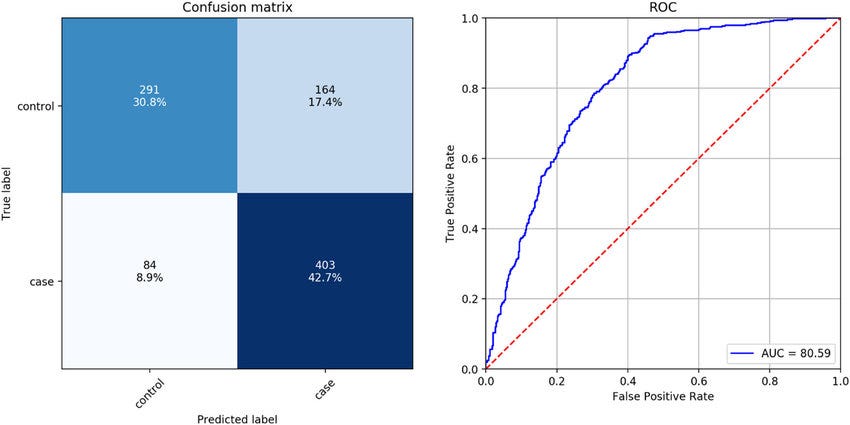
混淆矩阵:模型内心的镜子
如果说前面这些指标是单一的数字,那么**混淆矩阵(Confusion Matrix)**就是一面能够反映模型内心世界的镜子。它不仅告诉我们模型做对了什么,更重要的是,它揭示了模型是如何犯错的。
在这个2×2的表格中,每一个格子都讲述着不同的故事:真正例(TP)是模型的得意之作,假正例(FP)是模型的"过度自信",假负例(FN)是模型的"遗漏之失",而真负例(TN)则是模型的"理智克制"。
通过观察混淆矩阵,我们能够洞察模型的"性格特点"。如果模型在假正例上表现较差,说明它容易"草木皆兵";如果假负例较多,则表明它过于"保守谨慎"。
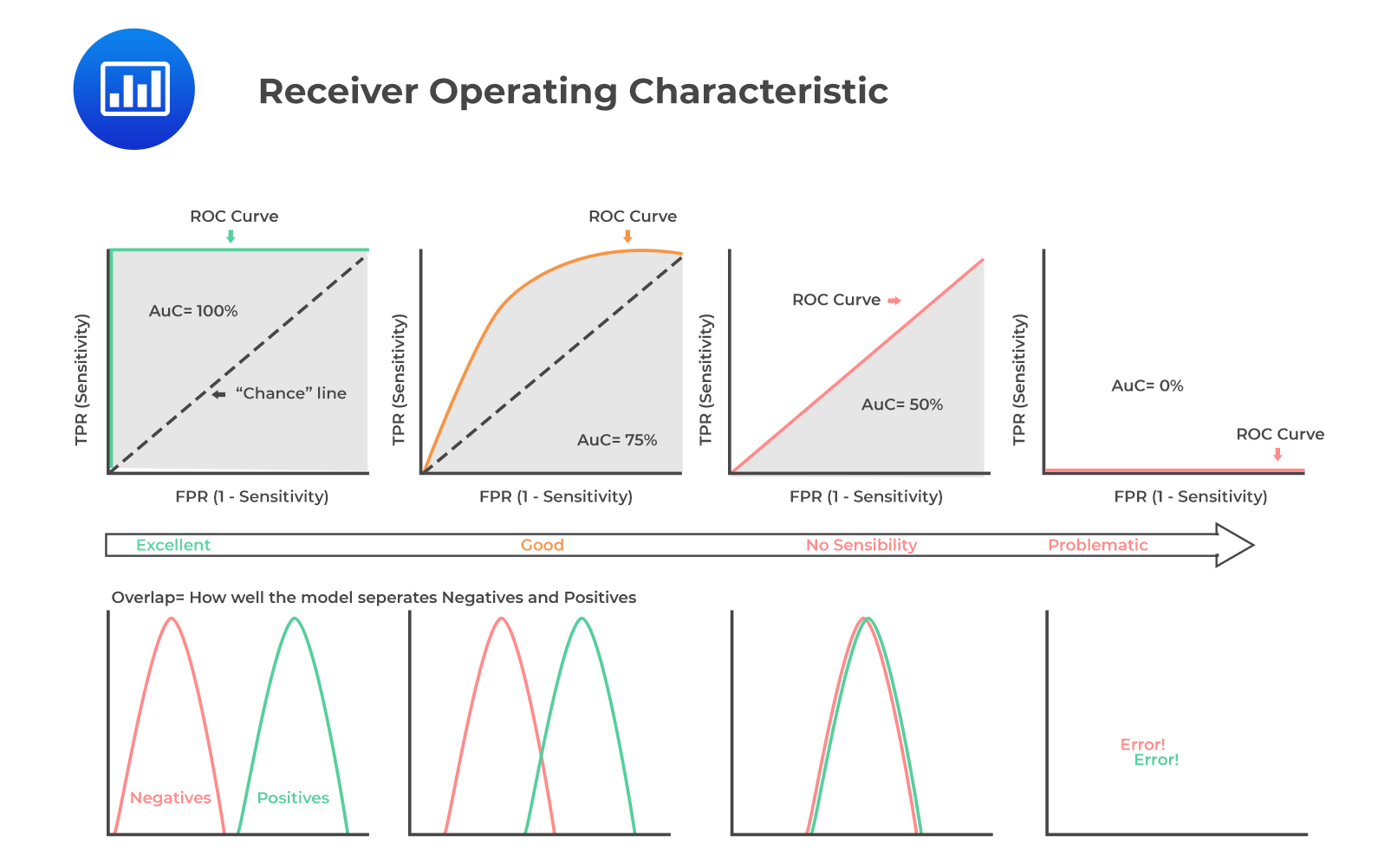
ROC曲线:模型的全景画像
**ROC曲线(Receiver Operating Characteristic Curve)**是一个来自二战雷达检测的概念,现在它成为了评估二分类模型的利器。根据Google机器学习文档的详细解释,这条曲线描绘了在所有可能的分类阈值下,真正例率和假正例率之间的关系。
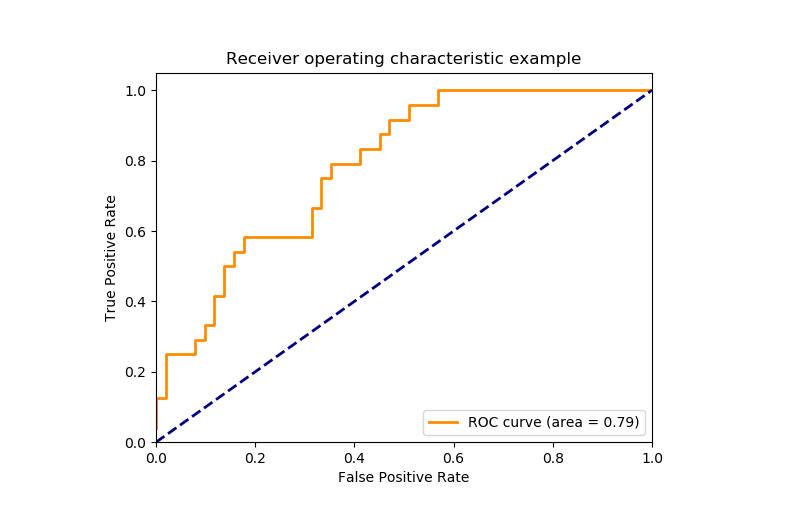
想象你是一个调节收音机的人,ROC曲线就像是在不同频率下收听到的信号质量图表。完美的模型就像是找到了完美的频率,能够清晰地接收到所有真实信号,同时完全屏蔽噪音。
**AUC值(Area Under the Curve)**则是这条曲线下面的面积,它有一个特别有趣的解释:给定一个随机的正样本和一个随机的负样本,AUC表示模型将正样本排在负样本前面的概率。一个AUC为0.8的模型,意味着在80%的情况下,它能够正确地区分正负样本的相对顺序。
回归指标:连续世界的测量尺
从分类任务转向回归任务,就像是从做选择题转向了数学计算题。这时候,我们需要全新的评估工具。
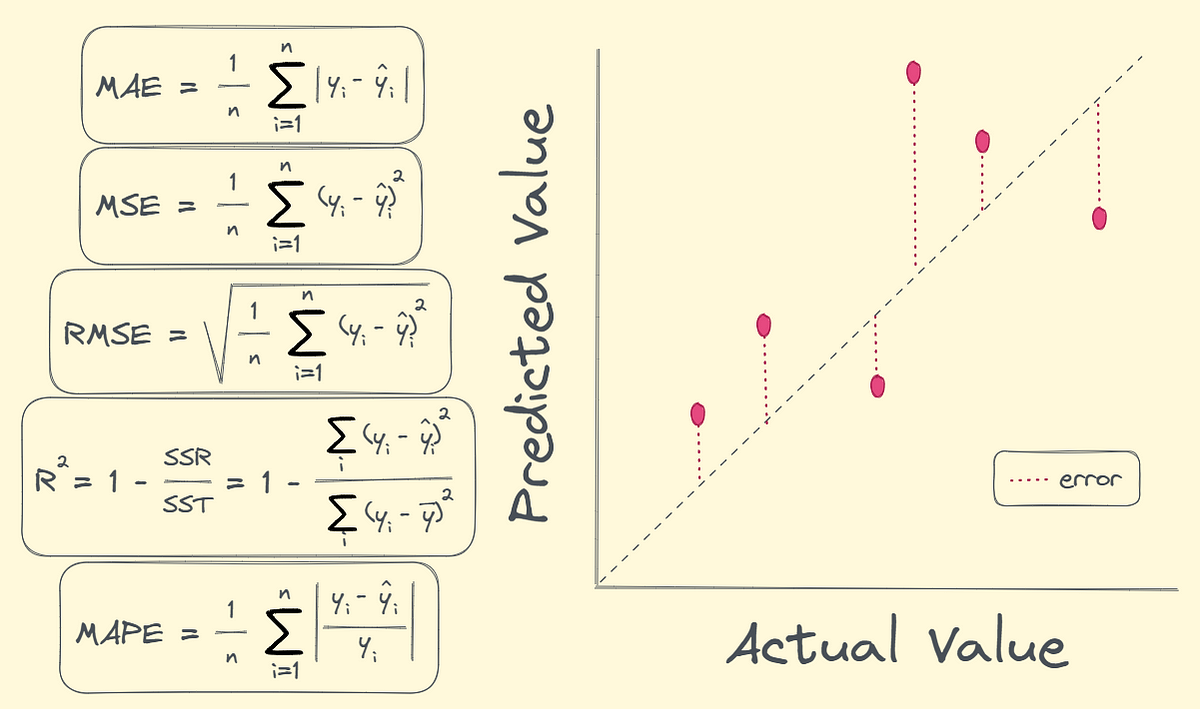
**均方误差(MSE)**是回归评估的经典指标,它计算预测值与真实值之间差异的平方的平均值。根据Medium上关于回归指标的详细分析,MSE的平方特性使得它对大误差特别敏感,就像是一个严厉的老师,对大错误给予加倍的惩罚。
**均方根误差(RMSE)**是MSE的平方根,它把误差单位拉回到与原始数据相同的量级。如果我们预测房价,RMSE会告诉我们平均每套房子的预测误差是多少万元,而不是像MSE那样给出"平方万元"这样难以理解的单位。
**平均绝对误差(MAE)**则是一个更加"宽容"的指标,它不会因为个别的大误差而过度惩罚模型。MAE就像是一个平和的老师,对所有错误一视同仁。在房价预测的例子中,如果有几套豪宅的预测出现了巨大偏差,MAE不会像RMSE那样被这些异常值"带偏"。

**决定系数(R²)**是回归分析中的明星指标,它回答了一个关键问题:"模型解释了多少数据的变异性?"R²的值在0到1之间,1表示模型完美地解释了所有变异,0表示模型的预测能力还不如简单地用平均值来预测。
交叉验证:模型能力的全面考核
单纯依靠训练集和测试集来评估模型,就像是让学生只做一套试卷就决定他们的学术水平。**交叉验证(Cross Validation)**提供了一种更加公平和全面的评估方式。

K折交叉验证是最常用的方法,它将数据分成K个子集,轮流使用其中K-1个子集进行训练,剩下的1个子集进行测试。这个过程重复K次,每个子集都有机会扮演测试集的角色。就像是让学生做K套不同的试卷,然后取平均分数作为最终评价。

根据机器学习掌握网站的详细解释,**留一法交叉验证(LOOCV)**是K折交叉验证的极端情况,其中K等于样本总数。这意味着每次只留下一个样本作为测试集,其余所有样本用于训练。虽然这种方法能够最大程度地利用数据,但计算成本也是最高的。
交叉验证不仅能够给出更可靠的性能评估,还能帮助我们检测模型的稳定性。如果一个模型在不同的数据子集上表现差异很大,说明它可能对数据的变化过于敏感。
学习曲线:模型成长的轨迹
**学习曲线(Learning Curves)**是理解模型行为最直观的工具之一。根据Towards Data Science的深入分析,学习曲线通过绘制训练集和验证集上的性能随训练样本数量或训练轮数的变化,为我们提供了模型"成长过程"的可视化记录。
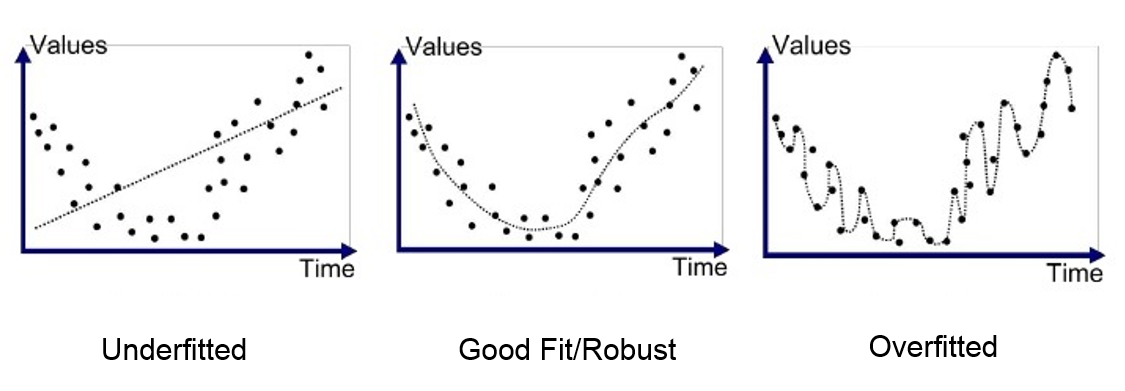
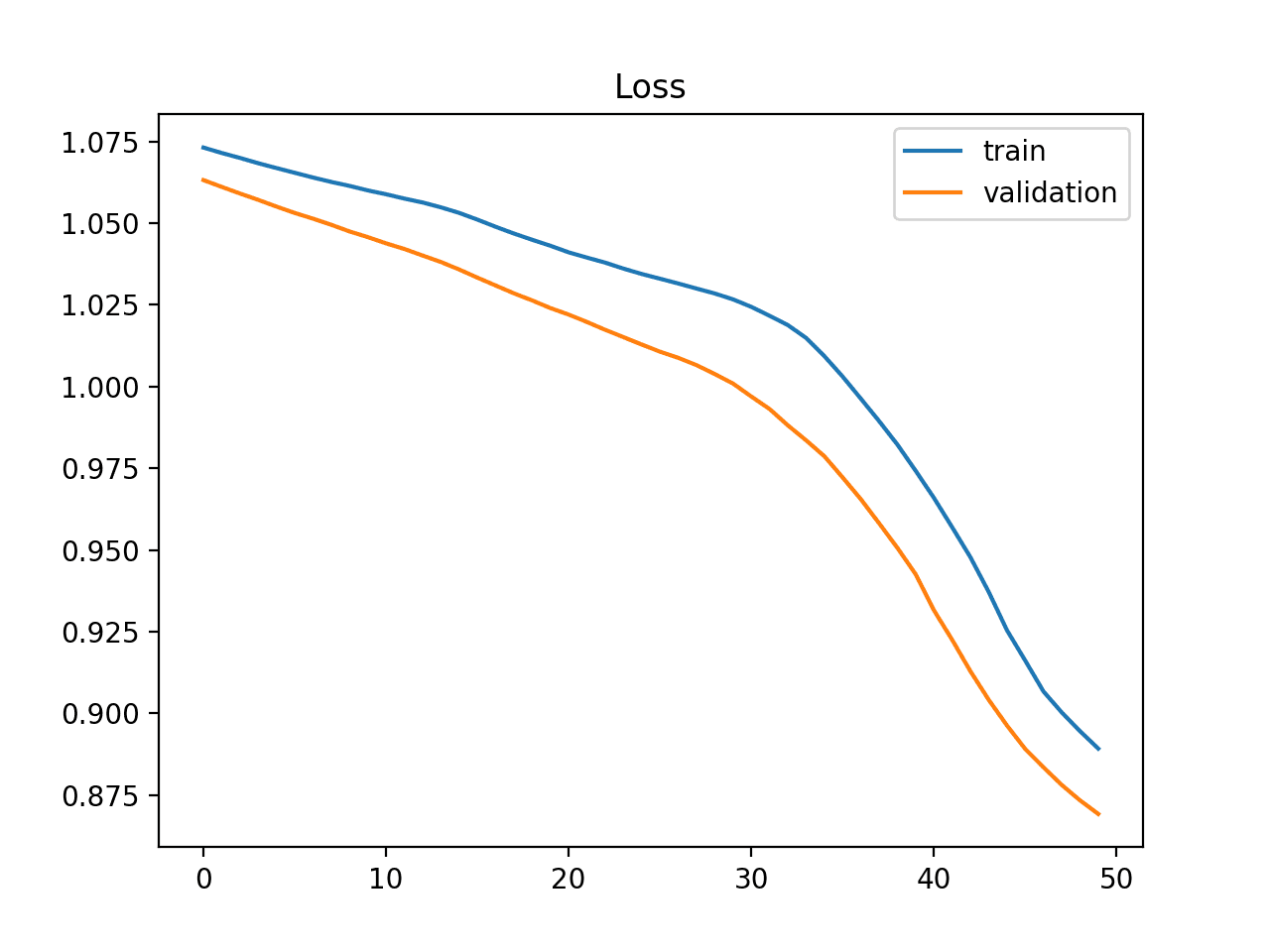
一个**欠拟合(Underfitting)**的模型就像是一个理解能力有限的学生,无论给他多少学习材料,成绩都无法显著提升。在学习曲线上,这表现为训练误差和验证误差都居高不下,且两者之间的差距很小。
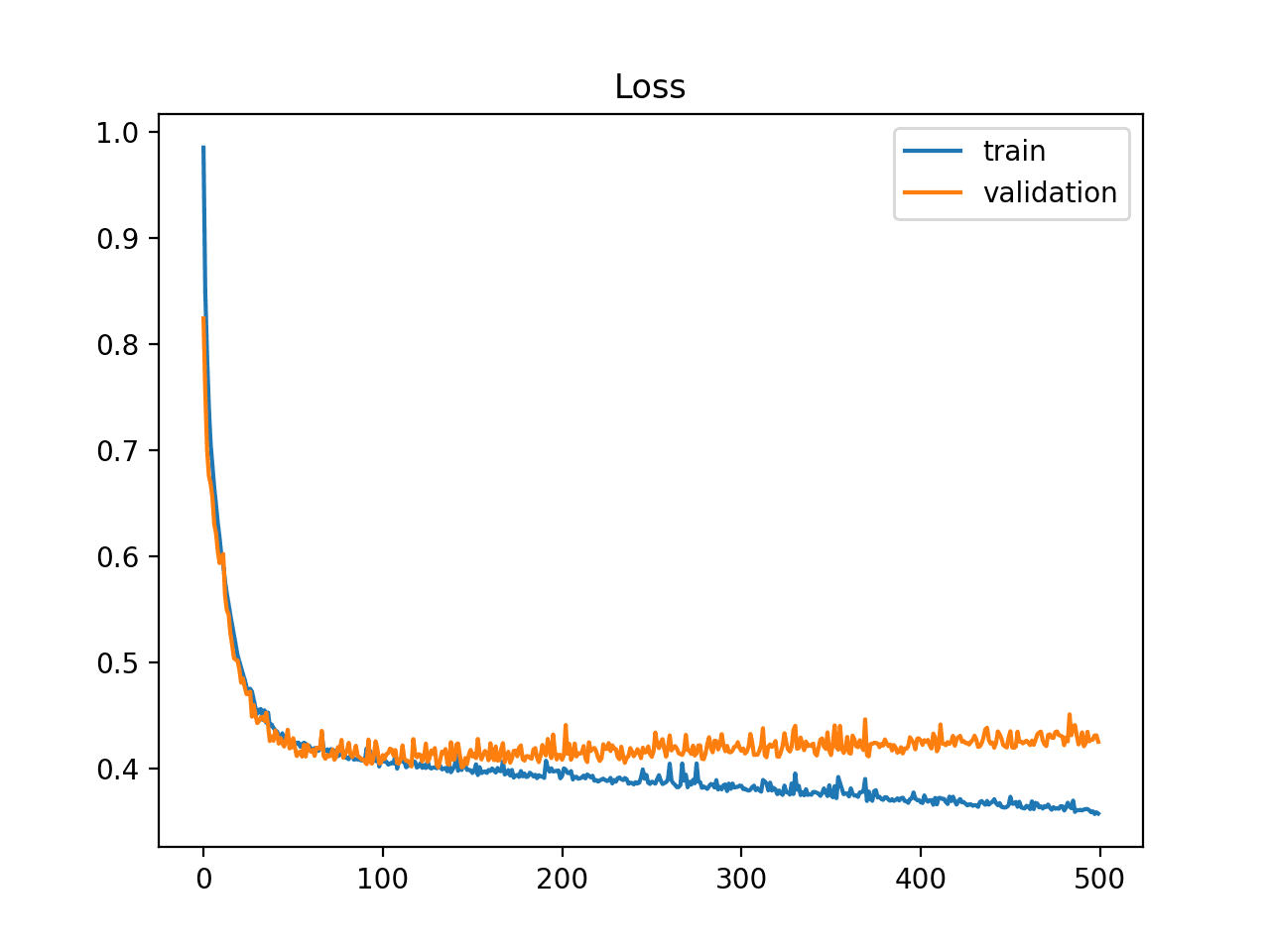
**过拟合(Overfitting)**的模型则像是一个只会死记硬背的学生,在熟悉的材料上表现完美,但面对新问题时就束手无策。学习曲线会显示训练误差很低,但验证误差明显较高,两者之间存在明显的"鸿沟"。
而一个良好拟合的模型学习曲线显示,随着训练数据的增加,训练误差和验证误差都逐渐降低,最终趋于稳定,且两者之间的差距保持在合理范围内。

验证曲线:超参数的指南针
**验证曲线(Validation Curves)**专门用于超参数调优,它绘制的是模型性能随某个超参数变化的情况。这就像是在寻找最佳的学习方法——太简单的方法可能无法充分挖掘潜力,太复杂的方法又可能导致过度学习。

通过观察验证曲线,我们能够找到那个"甜蜜点"——既不会因为模型过于简单而错失重要模式,也不会因为过于复杂而学到噪音。这个过程就像是调节收音机的音量,找到既清晰又不刺耳的最佳点。
不平衡数据的挑战
在现实世界中,我们经常面临数据不平衡的挑战。这时候,传统的准确率指标就显得力不从心。想象一个癌症检测系统,如果阳性样本只占总数的1%,一个简单地将所有样本都判断为阴性的模型就能获得99%的准确率,但这样的模型毫无实用价值。

在这种情况下,我们需要更加关注精确率-召回率曲线(PR Curve)。与ROC曲线相比,PR曲线在处理不平衡数据时表现更加稳定,能够更准确地反映模型在少数类上的表现。
模型选择的艺术
选择最佳模型不仅仅是比较数字的游戏,更是一门平衡各种需求的艺术。在医疗诊断场景中,我们可能更倾向于高召回率的模型,宁可多诊断一些假阳性,也不能漏掉真正的病患。而在垃圾邮件检测中,我们可能更看重精确率,因为误判重要邮件的代价更高。
**网格搜索(Grid Search)和随机搜索(Random Search)**是超参数优化的常用方法。网格搜索像是一个系统性的研究者,会尝试所有可能的参数组合;而随机搜索则更像是一个直觉敏锐的探索者,通过随机采样来寻找最优解。
近年来,贝叶斯优化等更高级的方法正在崭露头角,它们能够基于之前的试验结果智能地选择下一个要尝试的参数组合,大大提高了优化效率。
实践中的智慧
在实际项目中,模型评估不是一个孤立的步骤,而是一个持续的过程。我们需要在不同的业务场景下选择不同的评估策略。对于时间序列预测,我们可能需要考虑时间分割验证;对于推荐系统,我们可能更关注排序指标如NDCG。
而且,单一指标往往无法全面反映模型的价值。一个在准确率上稍逊的模型,如果在推理速度上有显著优势,在实际部署中可能更有价值。这就需要我们建立一个多目标评估框架,综合考虑准确性、效率、可解释性等多个维度。
最终,模型评估的目标不是找到在某个指标上表现最好的模型,而是找到最适合特定业务需求的模型。这需要我们不仅要掌握各种评估工具的使用方法,更要理解它们背后的原理和适用场景。只有这样,我们才能在机器学习的道路上走得更远,构建出真正有价值的智能系统。
通过深入理解这些评估指标和方法,我们就能够为模型进行全面而准确的"体检",确保它们在现实世界中发挥最大的价值。毕竟,一个经过精心评估和优化的模型,才是值得信赖的智能伙伴。