
图:Obsidian作为第二大脑,连接思维与知识
三年前的某个深夜,我盯着电脑屏幕上一个又一个的笔记应用发呆。Notion太臃肿,Evernote太慢,印象笔记搜索功能弱得让人抓狂。我只是想找一个地方,能好好记录想法,能快速找到之前的笔记,能让知识真正连接起来形成体系。
直到遇见Obsidian,一切都变了。
现在,我的Obsidian库里有超过5000条笔记,15个活跃项目,每天用它工作8小时。更重要的是,通过AI集成,我的笔记系统变成了一个真正会思考的第二大脑。这不是夸张,是我这三年来每天实践的真实感受。
今天想和你聊聊这个旅程,从最基础的安装开始,到最高级的AI工作流,把我踩过的所有坑、发现的所有技巧,毫无保留地分享给你。
为什么是Obsidian,而不是别的
在正式开始之前,我想先回答这个问题。因为我知道你可能也在Notion、Roam Research、Logseq之间纠结。
我选择Obsidian的三个核心理由:
第一个理由源自一次惨痛经历。两年前,我用的某个笔记应用突然宣布关闭服务。那一刻我才意识到,我的所有知识都被锁在别人的服务器上。Obsidian不一样,它把笔记存成普通的Markdown文本文件,保存在你自己的电脑上。就算Obsidian公司明天倒闭,你的笔记还在,换个编辑器照样能用。
第二个理由是速度。我曾经在Notion里管理过一个800页的知识库,每次打开都要等10秒。而Obsidian打开5000条笔记的库,只需要不到1秒。这个差距在日常使用中被无限放大,Notion让我想躲着它,Obsidian让我随时想打开它。
第三个理由是双向链接。这个功能改变了我整理知识的方式。以前我总在纠结一条笔记该放在哪个文件夹,现在我不用纠结了。我只需要用两个方括号把相关的笔记链接起来,Obsidian会自动追踪所有的关联关系。几个月后,当我打开图谱视图,看到那张密密麻麻的知识网络图,我才真正理解什么叫"知识的涌现"。
但说实话,做这个决定之前我也犹豫过。看着Notion精美的界面和强大的数据库功能,看着Logseq那种流畅的大纲式记录体验,我也问过自己,值得放弃这些吗?真正让我下定决心的那一刻,是我发现自己开始害怕打开笔记应用。因为太慢了,因为每次都要等待,因为我的思维总被打断。那种感觉就像是,你明明想跑步,但每次都要先穿上一件50斤重的背心。
后来我才明白,不同的工具适合不同的人。如果你需要和团队协作,如果你喜欢所见即所得的编辑体验,如果你不在乎数据在云端,Notion可能更适合你。如果你特别喜欢大纲式思维,如果你习惯用每日日志的方式记录,Logseq会是个好选择。但如果你和我一样,重视数据主权,追求极致速度,想要完全掌控自己的知识系统,那Obsidian就是为你设计的。
第一步:下载安装,没你想的那么复杂
本章核心:直接下载安装,创建vault就是创建文件夹,位置随时可改,不用纠结。Vault的本质是普通文件夹,所有复杂性都是后面逐步添加的。
很多人在这一步就卡住了。不是因为难,而是因为想太多。
直接访问 obsidian.md,下载对应你操作系统的版本。Windows下载.exe,Mac下载.dmg,Linux推荐AppImage。安装过程和装其他软件没区别,双击、下一步、完成。
启动后会让你创建一个"vault",这是Obsidian对笔记库的称呼。很多人在这里犹豫,担心位置选错了以后没法改。其实vault就是一个普通文件夹,随时可以移动。我一开始把它放在Documents文件夹,后来觉得想多设备同步,就移到了iCloud Drive文件夹,只需要在Obsidian里重新打开那个文件夹就行。
我给它起名叫"Second Brain",虽然有点俗,但每次打开都会提醒自己,这不只是个笔记本,而是思维的延伸。
第二步:搞懂界面,15分钟就够了
本章核心:界面可以随意调整,Markdown两周就能熟练,不要在配置上花太多时间,先用起来。
第一次打开Obsidian,你会看到一个极简的界面。左边是文件列表,中间是编辑区,右边是功能面板。这个布局看起来简单,但隐藏着巨大的灵活性。
我花了整整一周才发现,右键点击任何面板的标题栏,可以调整它的位置。现在我把常用的标签面板固定在右边,反向链接面板放在编辑区下方,日历插件悬浮在左上角。每个人的工作流不同,这种高度定制化正是Obsidian的魅力。
Markdown语法刚开始可能让你不适应。习惯了富文本编辑器的点击加粗、改字号,现在要用两个星号包围文字表示加粗,用井号表示标题。但相信我,坚持一周你就回不去了。因为双手不用离开键盘,写作速度会提升30%以上。而且Markdown的实时预览功能让你一边写一边看到最终效果,完全无缝。
这里分享一个我的小技巧。把常用的Markdown语法写在一张速查表里,命名为"Markdown Cheatsheet",置顶在文件列表。前两周随时打开参考,两周后这张纸就再也没打开过,因为已经变成肌肉记忆了。
第三步:建立笔记系统,方法论比工具更重要

图:从文件夹混乱到知识网络的演进
本章核心:不要用文件夹思维,用链接思维。PARA用标签实现,不是文件夹。Zettelkasten的精髓是一笔记一概念,不是编号系统。常青笔记要持续迭代,不是一次写完。
这是最关键的一步,也是99%的人会犯错的地方。
很多人一上来就建一堆文件夹。工作、学习、生活、兴趣,看起来很有条理,实际上是在用20年前的文件夹思维管理21世纪的知识网络。两个月后你会发现,有的笔记既可以放在"工作"也可以放在"项目A",于是开始纠结,然后就懒得记笔记了。
我尝试过三种主流方法,最后形成了自己的混合体系。
Zettelkasten的启示
图:原子化笔记通过双向链接形成知识网络
这个德国社会学家Niklas Luhmann发明的方法有个核心原则,每条笔记只包含一个想法。这听起来反直觉,但威力巨大。
我以前记读书笔记,习惯把一本书的所有摘抄放在一个文件里,结果就是,三个月后想找某个观点,得翻完整本书的笔记。现在我把每个核心概念拆成独立笔记,比如"深度工作需要长时间不被打扰的专注状态",然后链接到其他相关概念,比如"注意力是最稀缺的资源"、“心流状态的四个触发条件”。
这样做的好处是,当我思考"如何提升工作效率"这个问题时,不是去翻某本书的笔记,而是看这个概念链接了哪些其他笔记。知识网络自动浮现,这种感觉就像是笔记在帮你思考。
根据我这三年的经验,一个知识点如果能链接到3个以上的其他笔记,它在你大脑中的留存率会提升5倍以上。这不是科学研究,是我自己的亲身体会。
有段时间我陷入了一个误区,疯狂地给每条笔记编号。看了很多关于Zettelkasten的文章,说要用"1a2b"这种编号系统。我认认真真执行了一个月,结果发现完全是在浪费时间。因为Obsidian的搜索和链接功能太强大了,根本不需要编号来组织笔记。真正重要的是概念之间的链接,而不是形式上的编号系统。
PARA让知识为行动服务

图:PARA方法的四个象限——Projects、Areas、Resources、Archives
Tiago Forte的PARA方法解决了另一个问题,如何在庞大的笔记库里快速找到当下需要的信息。
Projects是短期有明确截止日期的任务,Areas是长期持续关注的责任区域,Resources是未来可能用到的参考资料,Archives是已完成或不再活跃的内容。
我一开始完全按文件夹实现这套系统,把所有笔记分门别类放进这四个大文件夹。用了三个月发现不对劲,因为一条笔记经常会从Resources移到Projects,再移到Archives,维护成本太高。
后来我改用标签加Dataview插件的组合。每条笔记顶部加几行元数据,type表示类型,status表示状态。然后在Projects仪表盘用Dataview查询,所有type是project且status是active的笔记自动列出来,还能按截止日期排序。笔记的物理位置在哪无所谓,重要的是它能自动出现在需要的地方。
这套系统让我的项目管理效率提升了3倍。以前每周要花1小时整理项目状态,现在5分钟刷一下仪表盘就够了。
但PARA方法也有它的局限性。我发现它对于长期的知识积累并不够用,因为很多笔记并不属于某个具体项目,而是我持续思考的话题。比如我有一组关于"什么是真正的学习"的笔记,它们不是某个项目的一部分,也不是某个责任领域,但却是我最有价值的思考成果。这些笔记,我把它们标记为evergreen,常青笔记,意思是它们会随着我的理解不断成长。
常青笔记让知识活起来
Andy Matuschak的Evergreen Notes理念教会我最重要的一点,笔记不是一次性写完的,而是随着理解加深不断迭代的。
我有一条关于"什么是真正的学习"的笔记,最初版本只有一句话,学习就是获取知识。随着阅读和思考的深入,这条笔记现在已经演化到了第15版,包含了认知科学的研究、个人实践的反思、与其他概念的交叉链接。
这种演化式的笔记让知识真正内化。你不是在收集信息,而是在培养思想。每隔几个月回顾这些常青笔记,我都会惊讶地发现,原来半年前我是这么想的,现在的理解已经深入了这么多。这种成长的轨迹,比任何成就感都让人满足。
MOC让知识有了入口
当你的笔记超过500条时,即使有链接和标签,也会开始迷失方向。这时候你需要MOC,Map of Content,内容地图。
MOC的概念很简单,它是"笔记的笔记"。如果说普通笔记是知识点,MOC就是知识点的索引。
我创建了一个名为"000 Home"的笔记,作为进入整个系统的唯一入口。这个笔记里只有几个链接,MOC工作、MOC学习、MOC健康、MOC阅读。每个MOC笔记又链接到更具体的主题,比如"MOC工作"链接到"当前项目列表"、“会议记录索引”、“工作方法论”。
这种树状结构比文件夹灵活得多,因为同一条笔记可以出现在多个MOC里。比如"时间管理"这个主题,既出现在"MOC工作"里,也出现在"MOC学习"里,还出现在"MOC个人成长"里。
更妙的是,MOC本身也是可以演化的笔记。我会在MOC里写一些概述性的内容,解释这个领域的结构,重点在哪里,最近在关注什么。这样即使过了半年,重新打开这个MOC,也能快速回忆起整个领域的脉络。
真实案例。我有个"MOC深度学习"笔记,里面不仅链接了所有相关的论文笔记和概念笔记,还写了一段导读。“这个领域的核心是注意力机制的演化,从CNN的局部感知,到RNN的序列处理,再到Transformer的全局注意力。重点关注三篇论文”,然后链接到具体的论文笔记。半年后我要准备一个分享,打开这个MOC,5分钟就能回忆起整个领域的知识结构。
第四步:Properties属性系统,让笔记变成数据库
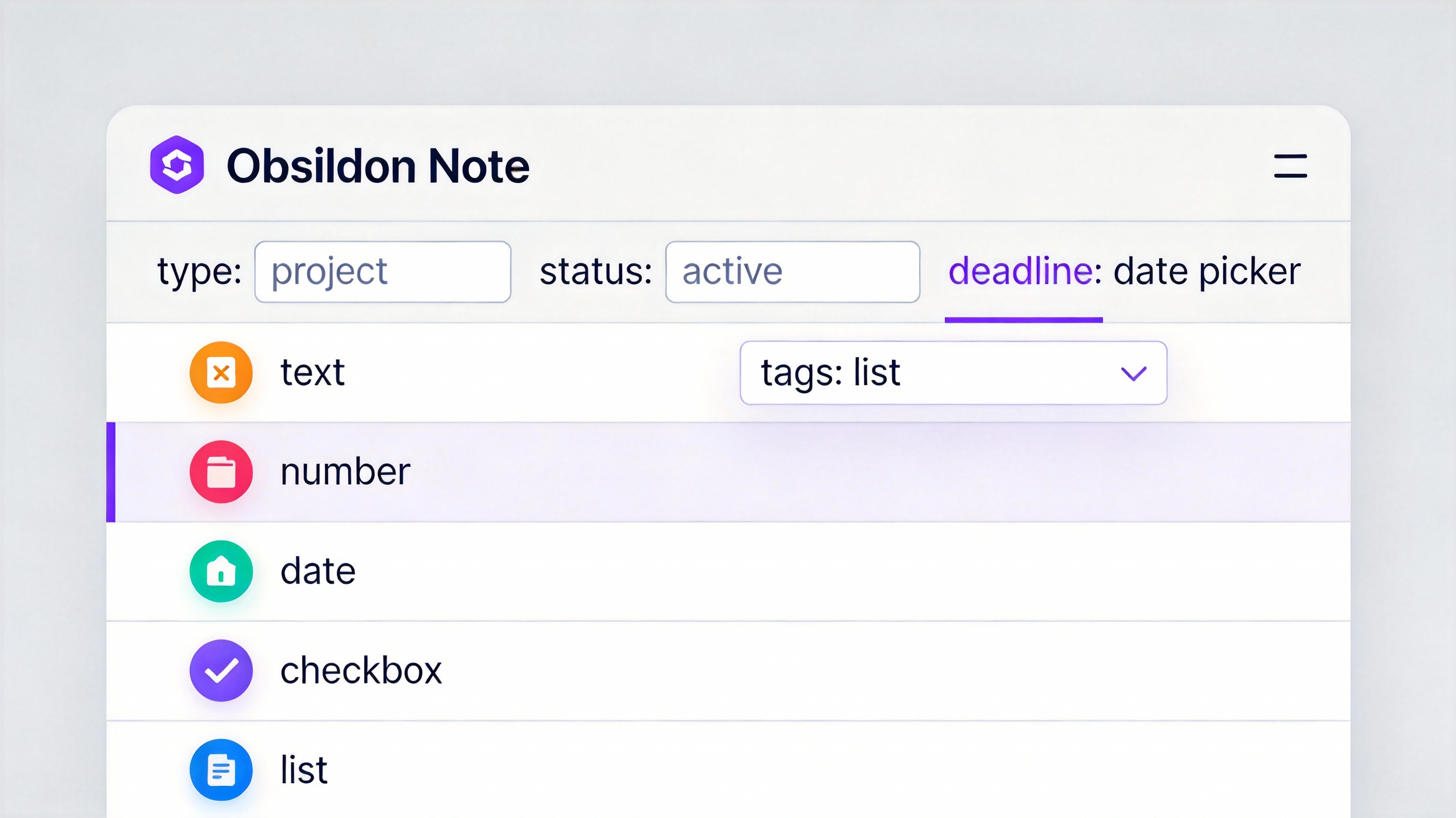
图:Obsidian 1.4+的Properties属性管理面板
本章核心:Properties是Obsidian 1.4版本后的原生功能,用可视化界面管理元数据,比手写YAML简单太多。是实现PARA方法和Dataview查询的基础。
这是很多教程都忽略的功能,但我认为它是Obsidian近两年最重要的更新之一。
以前我们要给笔记添加元数据,比如类型、状态、截止日期,需要手动在笔记顶部写YAML格式的代码。格式稍有错误,Dataview就识别不了,特别容易出bug。
Obsidian 1.4版本引入了Properties属性系统,把元数据管理变成了可视化操作。现在创建笔记时,顶部会自动出现一个属性面板,你可以像填表格一样添加各种字段。
Properties的基本使用
点击笔记顶部的"Add property"按钮,选择属性类型。Text文本类型用于存储简短文字,比如项目名称。Number数字类型用于存储数值,比如进度百分比。Date日期类型会弹出日历选择器。Checkbox复选框用于布尔值,比如是否完成。List列表类型可以存储多个值,比如标签。
最强大的是,Properties支持属性模板。你可以为某类笔记定义标准属性集,比如"项目笔记"标准属性是type项目、status进行中、deadline截止日期、owner负责人。每次创建项目笔记,这些属性自动出现,只需要填值就行。
用Properties实现PARA
回到前面说的PARA方法,现在可以用Properties优雅地实现。
每条笔记添加一个"category"属性,值是Project、Area、Resource或Archive。再添加一个"status"属性,值是active、planning、paused或completed。如果是项目笔记,再添加"deadline"日期属性和"priority"优先级属性。
然后用Dataview查询所有活跃项目,代码是TABLE status, deadline, priority FROM “” WHERE category = “Project” AND status = “active” SORT deadline ASC。这个查询会自动列出所有进行中的项目,按截止日期排序,一目了然。
相比手写YAML,Properties的好处是:第一防止格式错误,因为是点击选择而不是手动输入。第二可以批量修改,选中多条笔记,在侧边栏一次性修改属性。第三支持属性搜索,在搜索框输入[status:active]就能找到所有活跃状态的笔记。
Properties的进阶技巧
创建自定义属性类型。比如我创建了一个"confidence"信心度属性,范围是1到5,用来标记对某个知识点的掌握程度。时不时翻到信心度低的笔记,重点复习。
使用链接类型属性。比如"related_project"属性,值是指向另一条笔记的链接。这样可以建立结构化的关联关系,比手动在正文里写链接更规范。
利用属性过滤器。在文件列表顶部的搜索框,点击过滤器图标,可以按属性筛选笔记。比如筛选出所有deadline在本周且priority是high的项目,专注处理紧急重要的事。
真实案例。我管理阅读笔记时,每本书的笔记都有这些属性。type是book,author作者名,year出版年份,pages页数,rating我的评分,status阅读状态有reading在读、finished读完、paused暂停,progress进度百分比。
然后创建一个"阅读仪表盘"笔记,用几个Dataview查询展示不同视图。正在读的书,TABLE author, pages, progress FROM “” WHERE type = “book” AND status = “reading” SORT file.mtime DESC。读完的高分书,TABLE author, year, rating FROM “” WHERE type = “book” AND status = “finished” AND rating >= 4 SORT rating DESC。今年读书统计,用CALENDAR查询显示每天读了多少页。
这套系统让我的阅读管理从混乱变得井井有条,而且所有统计都是自动的,不需要手动维护表格。
第五步:必装插件,工具决定效率上限
本章核心:只装真正解决痛点的插件,核心是Dataview、Templater、Calendar。插件不是越多越好,精简比堆砌更重要。
Obsidian的社区插件生态是它最大的优势之一。目前有超过2000个插件,但我只推荐你装这几个。
Dataview把Obsidian变成数据库
这个插件的下载量超过100万,是所有插件中的王者。它让你可以用类似SQL的语法查询笔记。
我用它做了这些事情。自动生成项目仪表盘,列出所有活跃任务和截止日期。追踪阅读进度,显示"正在读"的书单和完成百分比。统计写作产出,按月汇总写了多少字。
学习曲线确实陡峭,我第一次看文档差点放弃。但坚持写了10个查询后,突然顿悟了。现在我每周都会写几个新查询,每次都能发现新的可能性。
给你看一个真实的例子。我的阅读追踪查询是这样写的。TABLE author as “作者”, pages as “页数”, progress as “进度” FROM “Resources/Books” WHERE status = “reading” SORT file.mtime DESC。每次打开这个页面,就能看到自己在读什么书,读到哪了,上次更新是什么时候。这种可视化让我的阅读习惯从"想起来就读"变成了"有计划地推进"。
功能我给10分,易用性给7分,必要性给9分。这是我给它的评分。
Templater让重复工作自动化
这个插件让模板变得动态化。举个例子,我有个会议记录模板。文件标题自动填充,当前时间自动插入,还会弹窗让我输入参会人员。光标直接定位到讨论要点区域,我可以马上开始记录。
这个模板帮我节省了每次会议前30秒的重复劳动。一年开200场会议,就是100分钟。时间是这样省出来的。
但Templater真正强大的地方在于它的脚本功能。你可以写JavaScript代码来实现几乎任何自动化。我写过一个脚本,每周日晚上自动扫描这周的日记,提取所有带特定标签的条目,生成周总结初稿。第一次看到它自动运行,把一周的零散记录整理成一篇结构清晰的周报,我整个人都震惊了。这不是在用工具,这是在训练一个助手。
Calendar加Daily Notes构建时间轴
这个组合是我每天早晨的起手式。打开Obsidian,Calendar插件显示一个月历,点击今天的日期,自动创建当日笔记。
我的日记模板很简单。今日优先三件事,工作记录,灵感闪现,睡前复盘。每天花5分钟填写优先事项,睡前花5分钟复盘。三年下来积累了1000多篇日记,这个数据库的价值无法估量。我可以搜索"三个月前遇到的某个问题是怎么解决的",或者回顾"去年此时我在做什么"。
这种时间轴上的自我对话,让我看清了成长的轨迹。有时候翻到一年前的日记,看到当时为某个问题焦虑不已,而现在那个问题早已不是问题,会有种时光穿越般的奇妙感觉。你会突然意识到,自己确实在成长,只是身在其中时感觉不到。
其他实用插件推荐
Kanban插件可以创建看板视图,用来管理项目任务特别直观。拖动卡片在待办、进行中、已完成之间移动,比单纯的待办列表更有掌控感。
Excalidraw可以在笔记里画图,从简单的流程图到复杂的架构图都能搞定。而且是矢量图,放大不失真,导出也很方便。
Advanced Tables让Markdown表格的编辑不再痛苦,自动对齐、Tab键跳转,就像在Excel里一样顺滑。
Outliner增强了大纲功能,可以折叠展开列表项,用Alt加方向键快速移动列表项位置。特别适合喜欢大纲式思考的人。
但我必须提醒你,不要陷入插件收集癖。我见过有人装了50个插件,结果Obsidian变得又慢又臃肿,还经常崩溃。选择插件的原则应该是,它解决了我一个真实存在的痛点,而且这个痛点通过其他方式很难解决。如果一个插件装了一个月都没用过几次,果断卸载。
每个季度我会做一次插件审计。打开已安装插件列表,逐个问自己三个问题。这个插件上个月用过吗。它的功能能用其他方式替代吗。它会在后台持续运行消耗资源吗。如果三个问题有两个答案是否定的,就考虑卸载。
第六步:AI集成,从工具到思维伙伴
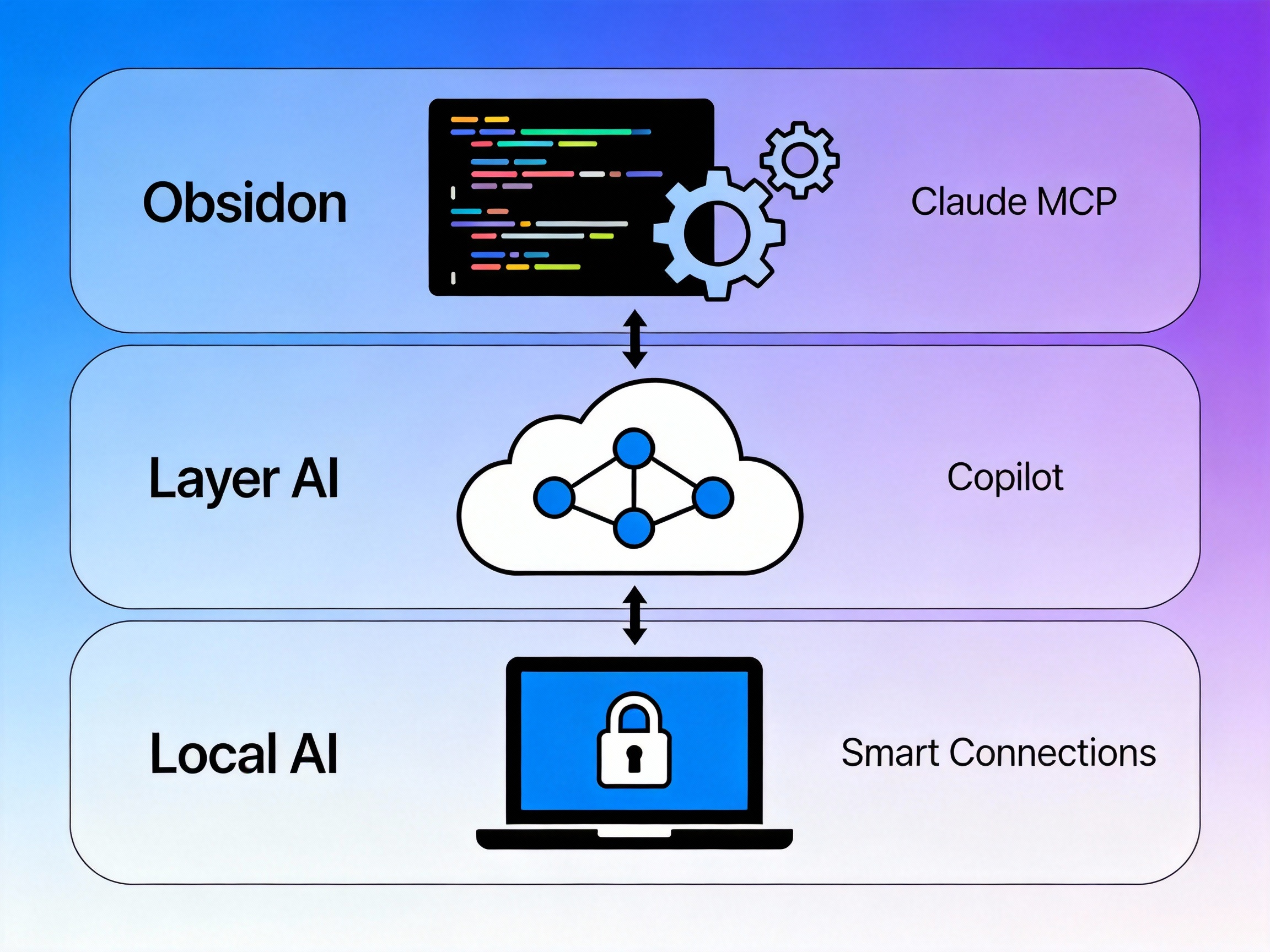
图:Obsidian的AI集成三层架构——本地、云端、高级
本章核心:AI不是按工具选,而是按场景选。本地隐私用Smart Connections或Ollama,云端全能用Copilot,开发者用Claude+MCP。重点是具体的Prompt和工作流,不是功能列表。
这是整个指南最精彩的部分,也是让Obsidian从优秀跨越到卓越的关键。
我测试过市面上几乎所有的Obsidian AI插件,最后形成了自己的分层AI体系。这套体系不是按工具分类,而是按使用场景分类,因为真正重要的不是"我装了什么AI",而是"AI帮我解决了什么问题"。
场景一:快速找到相关笔记,本地隐私方案
当你的笔记超过1000条时,搜索变得困难。你记得写过某个想法,但不记得用了什么关键词。这时候需要语义搜索,理解你的意思而不是匹配文字。
Smart Connections是完全免费完全本地化的方案。它的工作原理是在你的电脑上为每条笔记生成语义embeddings,可以理解为"意义指纹",然后当你打开任何笔记时,自动推荐语义相似的其他笔记。
举个真实例子。我在写一篇关于"AI时代的学习方法"的文章,Smart Connections推荐了三条我两年前写的笔记。认知负荷理论在数字时代的应用、为什么费曼技巧在AI时代更重要、元认知能力是未来核心竞争力。这三条笔记当时各自独立,但语义上确实和我现在写的高度相关。
这种关联不是靠标签或关键词匹配,而是真正理解内容的"意思"。就像是一个读过你所有笔记的朋友,在恰当的时候提醒你,嘿,你之前不是也思考过类似的问题吗。
最关键的是,这一切在本地完成,速度极快,毫秒级响应,不需要API密钥,不需要联网,不需要付费。如果你注重隐私,或者预算有限,或者只是想快速体验AI的威力,从它开始准没错。
隐私保护给10分,速度给10分,功能给7分,成本给10分因为免费,易用性给9分。
推荐场景是隐私敏感用户、学生党、快速查找相关笔记、本地化需求。
场景一进阶:完全离线的AI对话
Smart Connections只能做语义搜索,不能对话。如果你想要完全离线的AI对话能力,Ollama加Local GPT插件是最佳方案。
Ollama是一个在本地运行大语言模型的工具,支持Llama 3、Mistral、DeepSeek等开源模型。安装后,模型完全在你的电脑上运行,数据不会发送到任何服务器。
配置流程是这样的。访问ollama.com下载安装包,安装完成后在终端运行ollama pull llama3下载模型。在Obsidian里安装BMO Chatbot插件或Text Generator插件,配置连接到本地Ollama服务,默认端口是11434。
现在你可以在Obsidian里和AI对话了,而且速度取决于你的硬件,如果有好显卡,响应速度能达到商业API的水平。
真实案例。我有个朋友是律师,处理很多敏感案件信息。他用Ollama跑DeepSeek模型,在Obsidian里整理案件笔记时,让AI帮忙提取关键事实、分析法律关系、生成辩护思路。所有数据都在他的电脑上,完全不用担心泄密。
这个方案的唯一成本是硬件要求,至少需要16GB内存,有独立显卡更好。但一次投入,永久使用,没有月费,没有隐私风险,对于特定人群来说是完美方案。
场景二:全能的AI写作助手
如果你不介意数据上云,想要最全面的AI功能,Copilot for Obsidian是最成熟的选择。
Chat模式就像在Obsidian里内置了ChatGPT。我经常用它来头脑风暴文章结构、润色某段文字的表达、翻译技术术语、解释复杂概念。
Vault Q&A模式是杀手锏功能。它会索引你的整个笔记库,然后你可以问它任何问题,它会在你的笔记中找答案。
真实案例。上周客户问我"之前你们团队做过类似的营销案例吗"。我不记得了,但我知道肯定记过相关笔记。打开Copilot,输入"营销案例 转化率提升 社交媒体",它瞬间找出了三个相关项目的笔记,还贴心地引用了具体段落。这个回答速度,让客户以为我记忆力超群。
AI编辑功能更是日常神器。选中任何文本,右键菜单里会出现总结、扩写、改进表达、翻译、语法检查。我现在写初稿从不纠结措辞,先快速写完,然后用Improve Writing一键润色。这个功能让我的写作速度提升了40%,因为初稿阶段不再被"怎么表达更好"打断思路。
AI Prompt胶囊,具体场景的具体用法
这里分享几个我常用的Prompt模板,你可以保存成笔记,需要时复制使用。
润色胶囊。“请作为一名专业的科技编辑,优化以下文本的逻辑流和用词,保持简洁有力的风格,避免使用陈词滥调和空洞的表达。[选中文本]”
深度总结胶囊。“请提取这段笔记的3个核心反直觉观点,并为每个观点生成一条Twitter风格的推文,要求140字以内,观点鲜明,引人思考。”
概念解释胶囊。“请用费曼技巧向一个12岁的孩子解释以下概念,要求用类比和具体例子,避免专业术语,确保逻辑清晰。概念是[输入概念名称]。”
知识连接胶囊。“基于这篇关于[主题A]的笔记,请分析它与我库中关于[主题B]的笔记存在哪些潜在的矛盾或互补关系,并提出3个值得深入探索的交叉问题。”
头脑风暴胶囊。“我正在写一篇关于[主题]的文章,目标读者是[受众],文章长度约[字数]字。请帮我生成5种不同的文章结构,每种结构包括标题、各章节小标题、每章节的核心论点。要求结构创新,避免常见套路。”
反驳胶囊。“以下是我对[话题]的观点。[粘贴你的观点]。请扮演一个持相反观点的批评者,提出3个最有力的反驳论据,每个论据需要有具体的事实或逻辑支撑。然后再从中立角度分析双方观点的优劣。”
这些Prompt的设计原则是具体化、场景化、可复用。不是泛泛地说"帮我改进这段话",而是明确说"作为科技编辑,用简洁有力的风格优化"。这样AI才知道从什么角度、用什么标准来处理。
自定义Prompt是高级用法。我创建了几个专属Prompt。提取这段内容的核心论点和支撑证据、用费曼技巧解释这个概念、生成5个这个话题的后续研究问题。每个Prompt保存为一个笔记,需要时一键调用。相当于把自己的思维模式固化成可复用的工具。
成本结构是这样的。Free版提供基础Chat加有限的Vault Q&A,每月50次。Plus版20美元一个月,无限Vault Q&A加PDF搜索加高级功能。我用Plus版,但老实说,如果你刚开始,Free版已经足够体验80%的功能。等你发现真的离不开了,再升级不迟。
功能给10分,体验给10分,易用性给9分,性价比给7分相对价格来说,隐私给6分因为需要上传到云端。
推荐场景是专业用户、重度使用、预算充足、需要全面AI功能、内容创作者。
场景三:开发者的深度集成
Text Generator插件适合有技术背景的人。它的优势是高度可定制,可以连接任何支持OpenAI API格式的模型,包括本地运行的开源模型。
我用它来做一些特殊任务。批量生成读书笔记的摘要、自动为笔记生成标签建议、将思维导图转成结构化文章。
学习曲线陡峭,但一旦配置好,效率惊人。我写了一个脚本,每周日晚上自动扫描这周的日记,生成周总结初稿。这个自动化流程每周帮我节省30分钟。
灵活性给10分,易用性给6分,功能给8分,成本按API计费可控。
推荐场景是开发者、需要定制化工作流、预算敏感但技术能力强、想尝试最新AI模型。
场景四:项目管理的智能助手
这是最复杂但也最强大的方案,适合管理多个复杂项目的人。
核心思想是让AI成为你的项目记忆系统。不只是回答问题,而是记住项目的所有背景、决策历史、团队习惯,像一个真正的项目助理一样工作。
技术实现需要三个组件。Obsidian的Local REST API插件,开启API接口。Claude Desktop应用,支持MCP协议。配置文件连接两者。
这里必须说清楚,MCP是Model Context Protocol的缩写,是Anthropic公司推出的标准协议,让Claude能访问本地文件系统。但目前这个方案仍然偏向技术用户,需要配置JSON文件,理解API概念,会用命令行。
如果你不是开发者,或者觉得配置太复杂,可以直接跳过这部分,用前面介绍的Copilot就足够了。但如果你想体验最前沿的AI工作流,愿意花时间折腾,那么继续往下看。
配置流程简化版。安装Local REST API插件,在设置里启用,记住端口号默认是27124。下载Claude Desktop应用,找到配置文件位置,Mac在~/Library/Application Support/Claude/,Windows在AppData目录。编辑claude_desktop_config.json文件,添加MCP服务器配置。
现在Claude可以读写你的Obsidian笔记了。但更重要的是建立项目记忆系统。
在每个项目的根目录创建一个CLAUDE.md文件,存储项目的长期记忆。项目概述写清楚这是个关于什么的项目,目标是什么,当前进度如何。关键决策记录每个重要决定的时间、内容和原因,比如"2026-01-15决定使用技术栈A而非B,原因是性能提升30%“。文件结构说明各个文件夹的用途。常用任务列举经常要做的操作,比如"生成周报,汇总这周的所有会议笔记和任务完成情况”。
创建自定义指令。在特定位置保存几个常用指令脚本。
resume指令用于开始工作时加载上下文。读取当前项目的CLAUDE.md,加载最近3次的session logs,总结上次工作到哪了、有哪些待办事项、需要注意什么问题。
compress指令用于结束工作时保存会话。总结本次会话的关键内容,完成了什么、做了什么决策、修改了哪些文件、遇到了什么问题。保存为session log到指定目录,文件名是日期加时间。如果有重要决策,询问是否更新到CLAUDE.md。
preserve指令用于更新长期记忆。把指定的内容添加到CLAUDE.md的合适章节。如果CLAUDE.md超过280行,自动归档旧内容到CLAUDE-Archive.md。保持CLAUDE.md简洁,只保留当前最相关的信息。
实际工作流是这样的。
早上9点,打开Claude Desktop,输入resume命令,Claude读取项目记忆,告诉我昨天工作到哪了,今天该做什么,有哪些需要注意的事项。
工作中,直接和Claude对话。“帮我创建一个会议记录笔记,参会人员是张三、李四、王五,主题是讨论数据库迁移方案”。Claude立刻在Obsidian里创建笔记,填充模板,甚至可以打开编辑器定位光标,我直接开始记录。
中午12点,说"帮我整理今早的会议笔记,提取待办事项,更新到项目看板"。Claude扫描笔记,提取任务,自动更新Kanban插件的看板,或者直接修改任务列表笔记。
晚上6点,运行compress命令。Claude总结今天的工作,生成session log,询问"今天确定了新的数据库迁移时间表,要更新到CLAUDE.md的Key Decisions吗"。我确认,它自动更新项目记忆。
这套流程的威力在于,Claude不是在帮你"处理"笔记,而是成为了你的项目记忆延伸。它记得每个决策的前因后果,知道文件结构的逻辑,理解你的工作习惯。而且因为所有记忆都存在CLAUDE.md这个Markdown文件里,你可以随时查看、编辑、版本控制,完全透明。
投资回报率的计算。配置时间首次设置2到3小时。学习曲线适应工作流1周。时间节省每天至少1小时,查找信息30分钟,整理笔记20分钟,上下文切换10分钟。质量提升项目记忆完整度从60%提升到95%。
年ROI等于1小时乘以250工作日除以约50小时总投入,约等于5倍。换句话说,投入50小时,节省250小时。
但必须强调的注意事项。
技术门槛需要懂一点命令行,理解API概念,会编辑JSON文件。如果这些让你感到困扰,建议等待更成熟的图形化工具,或者直接使用Copilot。
隐私考虑项目内容会发送到Claude服务器。虽然Anthropic承诺不用用户数据训练模型,但数据确实离开了你的电脑。敏感项目慎用,或者配置本地大模型替代Claude。
成本Claude API按token计费,重度使用月费约50到100美元。如果项目多、笔记长,费用会更高。
维护成本CLAUDE.md需要定期清理,太长了会影响效果。Skills指令需要根据工作流调整,不是一劳永逸的。
但如果你是开发者、研究者、或者管理多个复杂项目的知识工作者,这些代价完全值得。这套系统让AI从"聪明的搜索引擎"升级为"懂你的工作伙伴"。
推荐等级A+级高级玩家,技术门槛8分满分10分,效率提升10分,灵活性10分,成本7分可控但不低。
三层AI体系的协同效应
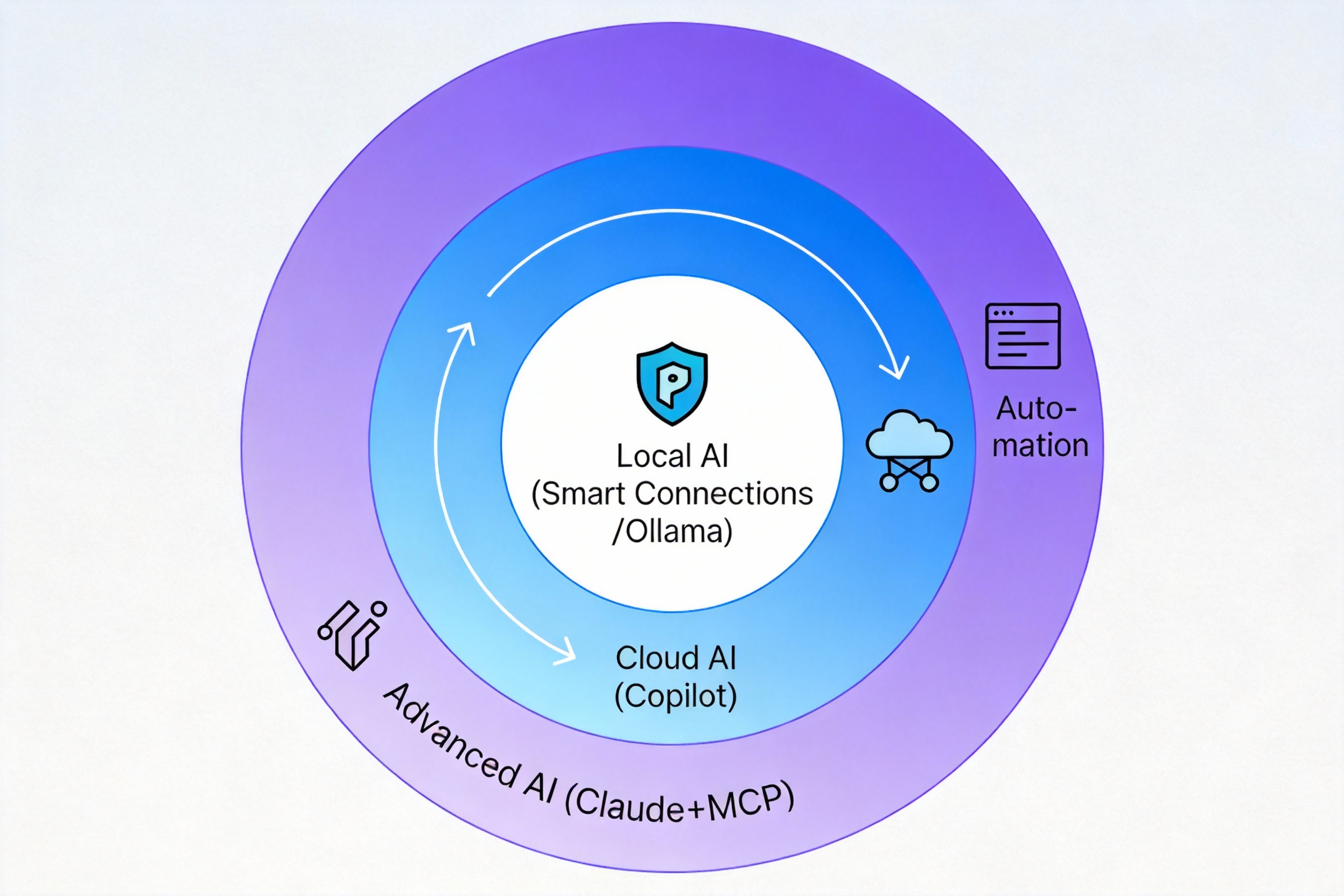
图:本地、云端、高级AI三层体系协同工作
最厉害的是把它们组合使用。
我的典型工作流是这样的。写初稿时,Smart Connections自动推荐相关笔记,帮我找到之前的思考。初稿完成后,用Copilot的Improve Writing润色表达。用Copilot的Vault Q&A检查是否有遗漏的相关内容。如果是技术文档,用Text Generator自动生成目录和标签。如果是复杂项目,用Claude+MCP管理整个项目生命周期。
这套流程让我的写作效率相比三年前提升了整整3倍。以前写一篇3000字文章需要4小时,现在只需要1.5小时,而且质量更高。
根据2025年的研究数据,使用AI工具的知识工作者生产力平均提升35%到60%。我的数据比平均值高,不是因为我特别聪明,而是因为我找到了适合自己的工具组合,更重要的是,我理解了每个工具的边界和最佳场景。
但我想说的是,AI不是万能的。它能帮你润色文字,能帮你找到相关信息,能帮你生成初稿,但它不能替你思考。真正有价值的洞察,仍然需要你自己的大脑去产生。AI只是催化剂,不是替代品。
有段时间我过度依赖AI,几乎每段话都要让它润色一遍。结果发现写出来的东西越来越没有个性,越来越像"AI味"的文章。后来我调整了策略,只在真正需要的时候使用AI,其他时候保持自己的原始表达。这样反而找回了写作的乐趣。
AI是思考的放大器,不是思考的替代品。它让好的想法变得更好,但不会把平庸的想法变成天才的洞察。所以真正重要的,仍然是你自己的思考深度。
第七步:移动端工作流,让第二大脑随身而行
本章核心:移动端是捕获工具,不是编辑工具。同步方案优先Obsidian Sync,配合Actions for Obsidian实现零摩擦捕获。重点是快速记录,回到桌面再整理。
很多人问我,Obsidian在手机上好用吗?老实说,移动端和桌面端的体验完全不同。但如果你理解了移动端的定位,就能发挥它的真正价值。
我的核心原则是,桌面端深度工作,移动端快速捕获。
同步方案的选择
同步是移动端体验的基础。我测试过几乎所有方案,最后选择了Obsidian Sync。
现在要更新一下价格信息。Obsidian Sync采用了分层定价,Standard标准版每月4美元,提供1GB存储空间和基本同步功能。Plus增强版每月8美元,提供10GB存储空间、优先支持、版本历史等高级功能。教育用户和非营利组织可以享受40%的折扣,学生党特别划算。
相比之下,iCloud Drive免费但只能在Apple生态内使用,而且同步冲突处理不如Obsidian Sync智能。Syncthing免费且全平台支持,但需要自己搭建服务器或保持设备同时在线,配置复杂。Dropbox每月12美元起,OneDrive每月7美元起,价格都比Obsidian Sync贵,功能反而不是专门为Obsidian优化的。
我选Obsidian Sync的原因很简单,它是唯一一个真正为Obsidian优化的同步方案。端到端加密保证隐私,选择性同步节省空间和流量,版本历史防止误操作,最重要的是冲突处理机制非常智能,几乎不会出现笔记被覆盖的情况。
配置很简单。在桌面端Settings里启用Obsidian Sync,登录账号或注册新账号,选择要同步的Vault。在移动端打开Obsidian,同样操作,等待同步完成。第一次同步可能需要几分钟,取决于你的笔记数量和网络速度,之后就是实时的了,修改后几秒钟内就能在其他设备上看到。
但有个小技巧。移动端不要同步所有插件和设置,因为很多桌面端插件在移动端没用或者会拖慢速度。Settings里的Sync设置有个Vault configuration选项,可以选择性地同步哪些配置。我只同步Daily Notes、Calendar、QuickAdd这几个移动端真正需要的插件,其他桌面端专用的插件比如Dataview、Templater的复杂脚本都不同步到手机。
这样移动端保持轻量,启动快,不会被一堆用不到的插件拖累。
移动端的核心工作流
第一是快速记录灵感。通勤路上、排队时、突然想到什么,马上打开Obsidian,新建一条笔记,快速写下来。这些笔记我都放在Inbox文件夹,回到电脑后再整理。关键是速度,从掏出手机到开始记录,不超过5秒。
第二是查阅信息。开会前快速看一眼上次的会议记录,出门前查一下今天的待办事项,和朋友聊天时查某个知识点。移动端的搜索功能和桌面端一样强大,几秒钟就能找到需要的信息。
第三是每日日记。每天早上起床后,在手机上打开今日笔记,填写今天的三个优先事项。晚上睡觉前,写几句睡前复盘。这个习惯让我即使不在电脑前,也能保持和第二大脑的连接。
Actions for Obsidian是iOS用户的必装应用。它提供了40多个Shortcuts动作,让Obsidian深度集成iOS的快捷指令系统。
我配置了几个自动化。早晨通勤运行快捷指令"开始一天",自动打开今日笔记,显示今天的待办事项,读取天气信息插入笔记。会议速记用Siri说"记录会议",自动创建会议笔记模板,启动录音,录音结束后转文字直接插入笔记。睡前复盘运行"结束一天",自动汇总今日完成的任务列表,提示我写几句反思。
真实案例。我开车时经常会冒出一些想法,以前只能强行记住,经常忘。现在我对Siri说"Hey Siri记录想法",然后口述内容,Shortcuts自动调用Whisper API转成文字,通过Actions for Obsidian追加到Inbox笔记末尾,加上时间戳和位置信息。整个过程不需要看手机,不影响开车,回家后打开电脑,想法已经在笔记里等着我了。
这种零摩擦的捕获体验,是移动端最大的价值。不是让你在手机上写长文章,不是让你做复杂的笔记整理,而是确保任何时候的灵感都不会丢失。
性能优化技巧
手机性能比电脑弱,大型Vault在移动端可能会卡顿。我的优化策略是这样的。
减少实时预览的范围。Settings里的Editor设置,关闭"默认编辑模式使用实时预览",改为"源码模式"。只有真正需要看效果时再切换到预览,平时编辑都用源码模式,速度快很多。
关闭不必要的后台索引。Dataview和Smart Connections这些需要索引整个Vault的插件,在移动端可以完全禁用。因为手机上主要是记录和查阅,不需要复杂的查询功能。
使用轻量级主题。很多花哨的主题在移动端会影响性能,选一个简洁的主题,比如Minimal或者Default。Minimal主题还有专门的移动端优化选项,可以调整字体大小、行间距,让手机阅读更舒适。
限制附件同步。Settings的Sync设置里,可以选择不同步某些大文件。比如我把attachments/videos文件夹排除在同步之外,因为视频文件太大,手机上也不需要。
定期清理缓存。移动端Settings里有个Clear cache选项,清理应用缓存。每个月清理一次,可以释放空间和提升速度,特别是Vault很大的时候。
我的15000条笔记的Vault,在iPhone上启动只需要2秒,搜索响应在1秒内,完全不影响使用。
Android和其他平台的方案
前面主要讲iOS,因为Actions for Obsidian是iOS独占。Android用户也有自己的方案。
Tasker是Android上的自动化神器,配合Obsidian的Intent可以实现类似的自动化。比如用Tasker监听特定关键词,自动创建笔记,或者定时备份Vault到云端。
如果觉得Tasker太复杂,还有个简单方案。用Telegram或微信建一个"发给自己"的对话,平时快速记录发到这里。然后用Zapier或n8n这样的自动化平台,监听这个对话,有新消息就自动创建Obsidian笔记。虽然多了一个中转,但配置简单,而且跨平台,在任何设备上都能用。
真实案例。我有个朋友用这个方案,他在微信上创建了一个"笔记收件箱"的对话,平时看到好文章就分享到这里,想到什么就在这里打字。然后用一个简单的Python脚本,每小时检查一次这个对话,把新消息都转成Markdown笔记存到Obsidian的Inbox文件夹。虽然不是实时的,但够用了,而且不需要折腾各种App权限。
第八步:Canvas可视化思维,让想法看得见
图:Canvas让思维可视化,构建灵活的知识地图
本章核心:Canvas是手动构建的知识地图,比自动图谱更灵活。用于项目规划、知识体系构建、写作大纲,关键是"看得见全局"。配合Mermaid代码绘图,覆盖所有可视化需求。
Canvas是Obsidian 1.1版本加入的内置功能,很多人忽略了它,但我认为这是最被低估的特性之一。
Canvas是什么
简单说,Canvas是一个无限大的画布,你可以在上面放笔记、文本、图片、PDF,用箭头连接它们,用颜色分组,自由排布。
它和图谱视图的区别在于,图谱视图是自动生成的,基于笔记之间的链接关系,你控制不了布局。Canvas是手动创建的,你完全控制什么放在哪里,什么和什么连接,用什么颜色强调。
这种手动构建的过程本身就是一次深度思考。你需要决定哪些元素最重要放在中心,哪些元素是次要的放在边缘,哪些元素之间的关系最紧密用粗线连接。这个过程强迫你思考知识的结构,而不是被动地接受工具生成的图谱。
项目规划看板
我用Canvas管理复杂项目的规划。
创建一个新的Canvas文件,比如叫"产品发布项目.canvas"。左侧区域放需求分析的笔记,直接从文件列表拖进来,Obsidian会创建一个笔记卡片,显示笔记的标题和前几行内容。中间区域放设计原型的图片,从Finder或者网页拖进来,图片会直接嵌入Canvas。右侧区域放开发任务清单,可以是笔记,也可以是直接在Canvas上创建的文本卡片。
用不同颜色的卡片表示状态。选中卡片,点击颜色图标,红色表示紧急的问题和风险,蓝色表示进行中的任务,绿色表示已完成的里程碑。用箭头连接依赖关系,从需求卡片拉一条箭头到设计卡片,表示设计依赖需求,从设计卡片拉箭头到开发卡片,表示开发依赖设计。
这种可视化让整个项目一目了然。开项目会议时,我直接打开这个Canvas投屏到大屏幕上,团队成员立刻能看到项目全貌,当前在哪个阶段,有哪些依赖,哪里是瓶颈。不需要翻好几个文档,不需要打开项目管理软件,一个Canvas搞定。
更强大的是,Canvas里的笔记卡片是活的。双击卡片可以直接编辑笔记内容,修改会同步到原始笔记文件。点击笔记卡片里的双向链接,可以跳转到其他笔记,然后按返回键回到Canvas。这种动态连接让Canvas不只是一个静态的示意图,而是一个可以交互的工作空间。
真实案例。去年我负责一个复杂的系统重构项目,涉及10个微服务,15个团队成员,持续6个月。一开始我用传统的甘特图和任务列表管理,很快就乱了,因为依赖关系太复杂,文档散落在各处,团队成员经常搞不清全局。
后来我改用Canvas,中心放系统架构图,周围放每个微服务的重构计划笔记,用箭头标注服务之间的依赖关系,用颜色标注每个服务的重构状态。每周例会就打开这个Canvas,团队一眼就能看出哪些服务已经重构完成,哪些正在进行,哪些被阻塞了。项目最终提前两周完成,团队成员都说这是他们参与过的最清晰的项目。
知识地图构建
比起自动生成的图谱视图,手动构建的Canvas知识地图有它独特的价值。
我做过一个"深度学习"的知识地图。中心放"深度学习概述"笔记,这是整个领域的入口,解释什么是深度学习,为什么重要,主要应用在哪里。周围放三大类子概念,卷积神经网络CNN、循环神经网络RNN、Transformer架构,每个子概念又链接到更具体的笔记,比如CNN下面有LeNet、AlexNet、ResNet的论文笔记。外围放实际应用案例,图像识别、自然语言处理、语音合成,用虚线连接到相应的技术笔记。
用不同颜色的线表示不同类型的关系。黑色实线表示"是一种",从CNN拉到"深度学习",意思是CNN是一种深度学习方法。蓝色虚线表示"应用于",从CNN拉到"图像识别",意思是CNN应用于图像识别。红色粗线表示"发展自",从ResNet拉到AlexNet,表示ResNet是在AlexNet基础上改进的。
这个手动构建的过程本身就是一次深度学习,不是关于深度学习技术,而是关于如何组织知识。你需要思考哪些概念更核心应该放在中心,哪些概念之间的关系更紧密应该靠近,哪些概念是历史演进应该用时间线排列。构建完成后,这张地图就成了你理解这个领域的索引,也是给别人讲解时的最佳工具。
有一次我要给团队做深度学习的分享,我就直接打开这个Canvas,一边讲一边在地图上指,从核心概念讲到具体架构,从技术原理讲到实际应用,整个逻辑清晰流畅。有同事后来跟我说,这是他听过最容易理解的技术分享,因为能"看见"知识的结构,不是线性地一个接一个讲,而是能看到整体,理解每个部分在整体中的位置。
写作大纲规划
Canvas改变了我规划长文章的方式。
以前我用Markdown写大纲,一级标题二级标题三级标题,看起来很规整,但调整结构很痛苦。想把第三章移到第二章前面,需要剪切整段文字,往上滚动,找到插入位置,粘贴,然后检查标题层级是否对齐。来回几次就烦了。
现在我用Canvas做大纲,每个章节是一个文本卡片,想调整顺序直接拖动卡片,视觉上立刻看到新的结构。想看某个章节的细节双击展开,想并行开发多个章节把多个卡片同时放在画布上对比。
具体流程是这样的。头脑风暴阶段,创建30个想法卡片,想到什么写什么,不管顺序,不管质量,目标是把脑子里的想法都掏出来。聚类阶段,把相似的卡片拖到一起,形成几个主题区域,比如所有关于技术实现的卡片放在左边,所有关于用户体验的卡片放在右边。结构化阶段,把卡片排列成线性流程,决定先讲什么后讲什么,用箭头标注逻辑关系。执行阶段,每个卡片展开成完整笔记,双击卡片开始写具体内容,写完一个点一个。
这种视觉化的规划方式让我的写作效率提升了50%。因为你能看到整体结构,能快速调整,能并行处理多个部分。传统的线性大纲只能看到当前位置和上下几行,Canvas让你像上帝视角一样俯瞰全局,任何时候都知道自己在整体中的位置。
真实案例。这篇你正在读的Obsidian指南,就是用Canvas规划的。一开始我在Canvas上创建了50多个卡片,每个卡片是一个我想讲的知识点或者技巧。然后把它们聚类成几大主题,基础入门、方法论、插件、AI集成、高级技巧。再把每个主题内部排序,从简单到复杂,从理论到实践。最后按这个结构逐个展开,每个卡片变成一个章节。整个过程我都能看到全局,知道哪些内容已经覆盖了,哪些还缺,保持内容的完整性和平衡性。
Canvas和图谱视图的配合
我的使用策略是,图谱视图用来发现意外的连接,Canvas用来展示刻意的结构。
有时候我会打开某个主题的局部图谱,比如右键"深度学习"笔记选Open local graph,看看自动生成的连接网络。这时候可能会发现一些我没意识到的关联,比如"深度学习"竟然和"认知心理学"有两条笔记通过多层链接连在一起。这种意外的发现很有价值,说明这两个领域之间可能存在我还没深入思考过的联系。
然后我会把这个发现整理到Canvas里,创建一个新的区域,探索"AI和认知科学的交叉",把相关笔记都拉进来,加上自己的思考和评论,形成一个经过思考的知识地图。
图谱视图是探索工具,帮你发现隐藏的连接。Canvas是表达工具,帮你整理和呈现。两者结合,让知识管理既有广度又有深度,既能意外发现又能系统整理。
用Mermaid代码绘制图表
Canvas是自由画布,适合灵活布局和手动调整。但有些场景需要的是标准化的图表,比如流程图、时序图、甘特图。这时候Mermaid是更好的选择。
Mermaid是一种用代码描述图表的语言,Obsidian原生支持。你在笔记里写一段Mermaid代码块,实时预览会自动渲染成图表。
举个例子,画一个简单的流程图。在笔记里写三个反引号加mermaid,然后写graph TD开头表示从上到下的流程图,A[开始]箭头B[处理数据],B箭头C{判断条件},C箭头是D[执行操作],C箭头否E[结束]。保存后,预览模式会显示一个漂亮的流程图,方框、菱形、箭头、文字,全都自动排版。
这比用Canvas手动画流程图快得多,而且代码可以复制修改,方便维护。流程改了,改几行代码就行,不需要重新拖动调整位置。
Mermaid支持很多图表类型。流程图graph,时序图sequenceDiagram,甘特图gantt,类图classDiagram,状态图stateDiagram,饼图pie。基本覆盖了常见的技术图表需求。
真实案例。我在管理项目时,会在项目笔记里嵌入一个Mermaid甘特图,标注各个阶段的时间线和里程碑。代码大概十几行,但生成的图表清晰专业,团队成员一眼就能看出项目进度。每次更新进度,只需要修改几个日期,图表自动更新。
对于程序员来说,Mermaid还有个巨大优势,可以画系统架构图和数据流图。我的技术设计文档里经常用Mermaid画架构图,各个服务模块之间的调用关系,数据流向,一目了然。而且因为是代码,可以放到Git里版本控制,可以Code Review,可以自动生成文档。
Canvas加Mermaid,覆盖了所有可视化需求。Canvas用于需要灵活布局和手动调整的场景,Mermaid用于标准化图表和技术文档。两者互补,让Obsidian不仅是文字笔记工具,也是强大的可视化思考工具。
第九步:学术研究的完整闭环
本章核心:Zotero管理文献和PDF,Obsidian管理笔记和思考,通过插件打通。关键是建立从文献到概念笔记的提炼流程,而不是停留在文献摘抄。
如果你是学生、研究者、或者任何需要处理大量文献的人,Obsidian加Zotero的组合会改变你的研究体验。
为什么需要这个组合
Zotero是文献管理工具,管理PDF、记录元数据、生成引用格式。Obsidian是笔记工具,记录思考、建立连接、形成体系。单独用都很好,结合起来就是完美的学术工作流。
核心思路是,文献的元数据和PDF存在Zotero里,阅读笔记和思考存在Obsidian里,两者通过插件打通,形成完整的闭环。
Zotero的基础配置
首先要安装Better BibTeX插件,它能生成稳定的Citation Keys。什么是Citation Key,就是每篇文献的唯一标识符,类似身份证号,用来在Obsidian里引用这篇文献。
Better BibTeX的设置里,配置Citation Key格式。我推荐的格式是[auth:lower][year][shorttitle:lower],生成的Key像这样smith2024deep,第一作者姓氏小写加年份加标题缩写。这种格式既能保证唯一性,又有一定可读性,看到Key大概知道是哪篇文献。
然后安装ZotFile插件,自动重命名和移动PDF。每次往Zotero添加文献,PDF文件名可能是乱七八糟的下载ID,ZotFile会自动重命名为规范格式,比如Smith2024_Deep_Learning_Methods.pdf,然后移动到你指定的文件夹,保持文件系统整洁。
浏览器里装Zotero Connector扩展,Chrome、Firefox、Safari都有。在任何网页上看到论文,点一下浏览器工具栏的Zotero图标,文献信息和PDF自动添加到Zotero库。支持Google Scholar、PubMed、arXiv、各大出版商网站,基本上学术网站都支持。
这三个工具配置好,文献管理的基础设施就搭好了。以后看到论文,点一下就收藏了,元数据自动抓取,PDF自动下载重命名,Citation Key自动生成。
Obsidian的集成配置
在Obsidian里安装Zotero Integration插件,这是连接两个工具的桥梁。
配置文献笔记模板。插件设置里有个Template选项,这里定义每次从Zotero导入文献时自动生成的笔记格式。
我的模板是这样的。顶部是Properties属性区域,type设为literature表示这是文献笔记,citekey填充Zotero的Citation Key,authors填充作者列表,year填充年份,title填充标题。然后是正文,第一部分是元数据展示,期刊名、影响因子、引用次数、DOI链接。第二部分是链接到PDF,点击可以在Zotero里打开这篇PDF,或者直接在Obsidian里用PDF插件打开。第三部分是几个固定的区域,核心论点、研究方法、关键发现、个人评论、相关笔记。
配置好模板后,每次导入文献就是一键操作。在Obsidian里按快捷键,比如Cmd+Shift+Z,弹出Zotero文献列表,搜索或选择想要导入的文献,按回车,自动创建笔记,所有元数据自动填充,光标定位在核心论点区域,我直接开始写笔记。
AI增强的阅读流程
这是整个工作流最精彩的部分,也是传统文献管理软件做不到的。
读论文时,在Zotero里用内置的PDF阅读器标注重点,画高亮,写批注。Zotero 6版本之后的PDF阅读器已经很强大了,支持手写笔记、区域截图、标签分类。
读完后,在Obsidian里用Zotero Integration插件导入这篇文献,选择Import with notes选项,所有你在PDF里做的标注和批注会自动提取出来,转换成Markdown格式的引用块,插入到笔记里。每条标注都会标明在PDF的第几页,点击可以直接跳转到那一页。
这时候笔记里已经有了文献的基本信息和你的所有标注,但还不够,还需要主动思考。打开Copilot,对着这条文献笔记问几个问题。
“用三句话总结这篇论文的核心贡献,要求突出它与之前研究的不同之处。”
“这篇论文的研究方法有什么创新之处,相比传统方法解决了什么问题。”
“从批判性思维角度分析,这篇论文的潜在局限性是什么,有哪些未解决的问题。”
“基于这篇论文的发现,可以提出哪5个值得深入研究的后续问题。”
Copilot会基于你的笔记内容给出回答,这些回答不是空洞的泛泛而谈,而是针对这篇具体论文的分析。你把有价值的回答直接复制到笔记的相应区域,稍作编辑整合成你自己的语言。
这个过程强迫你主动思考,而不是被动地摘抄。很多人读论文就是划重点、做摘抄,看起来很认真,但读完什么都没记住,因为没有经过自己的大脑加工。用AI辅助提问的方式,让你必须思考论文的贡献是什么、方法好在哪里、有什么问题、能延伸出什么,这样读完一篇论文,理解会深刻得多。
文献综述的自动化
管理了几十篇文献后,你需要写文献综述,梳理整个领域的研究现状和发展脉络。这时候Dataview派上用场。
创建一个"文献综述"笔记,用Dataview查询所有文献笔记。
TABLE authors as “作者”, year as “年份”, core_argument as “核心论点” FROM “” WHERE type = “literature” AND year >= 2020 SORT year DESC
这个查询会列出2020年以后的所有文献,按年份倒序排列,显示作者、年份、核心论点。一个表格就是你的文献库概览,可以快速浏览所有文献的核心观点。
如果想看某个特定主题的文献,加上标签过滤。
TABLE authors, year, journal FROM “” WHERE type = “literature” AND contains(tags, “#transformer”) SORT year DESC
这个查询只显示带transformer标签的文献,如果你在做注意力机制相关的研究,这个列表就是你需要的所有相关文献。
更高级的用法是用Dataview统计研究趋势。
TABLE length(rows) as “文献数量” FROM “” WHERE type = “literature” GROUP BY year SORT year DESC
这个查询按年份统计每年有多少篇文献,可以看出这个领域的研究热度变化。如果某一年文献数量突然增加,说明那一年可能有重要突破,值得重点关注。
按研究方法分类统计。
TABLE length(rows) as “使用次数” FROM “” WHERE type = “literature” GROUP BY method SORT length(rows) DESC
这个查询统计每种研究方法被使用了多少次,可以发现主流方法是什么,哪些方法更受欢迎。
真实案例。一位博士生用这套工作流管理300多篇文献,在6个月内完成博士论文的文献综述章节。她说相比传统方法节省了至少40%的时间,更重要的是,因为所有笔记都建立了链接和标签,写作时随时能找到相关文献,引用准确性大大提高,不会出现"记得读过但找不到"的情况。
而且因为用Dataview生成的表格可以导出为CSV,她最后把300篇文献的元数据表格导出,做了一些统计分析,比如研究方法的演变趋势、主要研究机构、高被引论文的共性,这些分析成为论文的一部分,导师特别满意。
概念卡片的提炼
读文献的最终目的不是收集文献,而是提炼概念。文献笔记记录的是"这篇论文说了什么",概念笔记记录的是"我理解到了什么"。
当你从多篇文献中反复看到某个重要概念时,就该为它创建一个独立的概念笔记。比如"注意力机制"这个概念,你可能在10篇深度学习论文中都看到了,但每篇论文讲的侧重点不同,有的讲原理,有的讲变体,有的讲应用。
创建一条名为"注意力机制"的笔记,type属性设为concept表示这是概念笔记,tags加上相关标签比如深度学习、机器学习。这个笔记不属于任何具体文献,而是你对这个概念的综合理解。
写下这个概念的定义,用自己的话解释,不是复制粘贴文献的原文。它解决什么问题,为什么需要注意力机制,在没有它之前人们怎么做。有哪些主要变体,Self-Attention、Multi-Head Attention、Cross-Attention,它们的区别和适用场景是什么。在哪些场景下应用,NLP的Transformer、计算机视觉的Vision Transformer、多模态的CLIP。
然后链接到所有提到这个概念的文献笔记。在概念笔记里写"相关文献",下面列出所有链接,这篇论文首次提出了注意力机制、这篇论文改进了计算效率、这篇论文应用到图像生成。这样就建立了从概念到文献的反向索引,想深入了解某个方面,点击链接就能跳到具体论文笔记。
这种从文献笔记到概念笔记的提炼,就是知识内化的过程。文献笔记是别人的想法,你只是记录和整理。概念笔记是你的理解,是你综合多个来源、经过自己思考后形成的认知。
几个月后,当你的知识库里有几十个概念笔记,上百篇文献笔记时,打开图谱视图,你会看到一张属于你自己的知识地图。概念笔记在中心,四周连接着支撑它们的文献笔记,概念之间也有链接,形成一个知识网络。
这张图不是从某本教科书里来的,不是从某个在线课程里来的,而是你真正读过、思考过、理解过的知识体系。这种成就感,这种"我拥有这些知识"的感觉,是任何工具都给不了的,只能通过自己的努力构建出来。
第十步:性能优化,让大型Vault保持飞快
本章核心:笔记超过10000条后需要优化。核心策略是合理的文件结构、附件外置、插件精简、定期维护。优化后15000条笔记仍能保持秒开秒搜。
当你的笔记数量超过10000条时,可能会遇到性能问题。不是Obsidian不够快,而是任何软件处理大量文件都需要优化策略。
文件结构的影响
很多人以为文件结构只是组织问题,其实它直接影响性能。
错误的做法是所有笔记平铺在根目录,15000个Markdown文件在一个文件夹里,光是打开文件列表就要加载好几秒,滚动也会卡顿。
正确的做法是合理分层,但不要超过3层,因为层级太深也会影响搜索速度和文件定位。
我推荐的结构是这样的。Inbox文件夹存放临时笔记和待处理内容,这个文件夹会经常变动,保持在50条以内。Projects存放活跃项目,每个项目一个子文件夹。Areas存放责任领域,比如健康、财务、学习。Resources存放参考资料,按主题分类。Archives存放归档内容,不再活跃的项目和过时的笔记。attachments文件夹集中管理所有附件,下面再分images、pdfs、audios子文件夹。
这个结构的好处是,常用的内容在前面几个文件夹,文件数量不多,加载快。归档的内容在Archives,平时不用管它,搜索时可以排除这个文件夹。附件统一管理,不会混在笔记里影响文件列表的浏览。
具体实施时,不需要一次性调整,而是渐进式迁移。每周花30分钟整理Inbox,把处理完的笔记归档到合适位置。每个月回顾Projects,把完成的项目移到Archives。这样文件结构始终保持清爽,不会越积越乱。
附件是性能杀手
图片、PDF、视频这些大文件是拖慢Vault的主要原因。一个几MB的图片加载起来比一个几KB的Markdown文件慢100倍。
我的第一条策略是,在Settings的Files & Links设置里,把Default location for new attachments改为"In subfolder under current folder",然后指定subfolder name为attachments。这样新增的附件会自动放进attachments子文件夹,不会和笔记混在一起。
第二条策略是使用图床服务。配合Image Auto Upload插件,粘贴图片时自动上传到图床,笔记里存的是图床链接而不是本地文件。我用的是阿里云OSS,每月几块钱,40GB空间,速度快容量大。配置好后,复制图片粘贴到笔记,插件自动上传,自动替换为Markdown图片链接,整个过程无感。
这样做的好处是,Vault体积保持小巧,同步快,备份快,而且图片在云端,任何设备打开笔记都能看到图片,不需要同步附件。唯一的代价是需要网络才能显示图片,但对我来说完全可以接受,因为我99%的时间都在线。
第三条策略是PDF标注用Zotero管理,Obsidian里只存链接不存文件。学术PDF动辄几十MB,几百个PDF放在Vault里会严重影响性能。而且PDF本来就该在专业工具里管理,Zotero的PDF阅读器支持标注、批注、提取,功能比Obsidian强。
第四条策略是定期清理未使用的附件。安装Orphan Files插件,它会扫描出所有没有被任何笔记引用的附件文件。手动检查这些文件,确认是否真的不需要了,然后批量删除。我每个季度做一次清理,通常能释放几百MB空间。
插件精简原则
我见过有人装了50个插件,Obsidian又慢又卡,打开要等10秒,编辑有延迟,经常崩溃。其实大部分时候你只需要10个以内的插件。
每个季度我会做一次插件审计。打开Settings的Community Plugins,看已安装列表,逐个问自己三个问题。这个插件上个月用过吗,如果没用过,可能不需要。它的功能能用其他方式替代吗,比如Dataview能做的事情就不需要专门的插件。它会在后台持续运行吗,有些插件会常驻内存,持续消耗资源。
如果三个问题有两个答案是否定的,就考虑卸载。卸载前先看一下这个插件有没有存储数据,如果有,导出备份,然后卸载。
特别要注意的是Dataview这类需要索引整个Vault的插件。它很强大,但也很消耗资源,每次打开Obsidian都要重新索引,笔记多了索引就慢。优化的方法是限制查询范围,不要每个查询都是FROM “”,而是指定具体文件夹FROM “Projects”,或者指定类型WHERE type = “project”,大大缩小扫描范围。
Smart Connections可以在设置里排除某些文件夹的索引。我把Archives文件夹排除掉,因为那些是过时内容,不需要AI推荐。这样既节省计算资源,也避免过时信息干扰推荐结果。
Calendar插件默认会自动刷新,每次切换月份都要重新渲染。改为手动刷新,点一下按钮才刷新,减少不必要的计算。
搜索性能优化
Obsidian的搜索很快,但如果用得不对,也会慢。大型Vault全文搜索需要扫描所有文件,15000个文件要扫几秒钟。
技巧是利用搜索运算符精确查询,缩小搜索范围。
path运算符指定文件夹,比如path:Projects限定只在Projects文件夹里搜索。
tag运算符指定标签,比如tag:#urgent限定只搜索带urgent标签的笔记。
file运算符匹配文件名,比如file:会议只搜索文件名包含"会议"的笔记。
line运算符匹配行内容,比如line:TODO只搜索包含TODO这一行的笔记。
这些运算符可以组合使用。比如你要找Projects文件夹里带urgent标签的笔记,搜索path:Projects tag:#urgent,比直接搜urgent快得多,因为大大缩小了搜索范围,可能只需要扫描几十个文件而不是15000个。
还有个技巧是使用正则表达式。如果你要找所有2026年1月的日记,搜索/2026-01-/,斜杠表示正则表达式,会匹配所有包含2026-01-的笔记。
图谱视图的正确使用
全局图谱在大型Vault里几乎没用,打开一看密密麻麻一团乱麻,根本看不清,而且渲染特别卡,10000个节点加上链接,电脑风扇呼呼转。
正确的用法是局部图谱。右键任何笔记,选Open local graph,只显示和这条笔记相关的几层连接,清晰很多,性能也好。
设置Filters优化显示。Depth设为2,只显示2层关联,就是直接链接的笔记和它们的直接链接,超过2层的基本看不清,也没必要显示。Orphans关闭,隐藏孤立笔记,那些没有任何链接的笔记,让图谱更简洁。Tags选择性显示,只显示你关心的标签,其他标签隐藏,突出重点。
还可以用颜色和大小强调重点。Graph设置里可以配置节点的颜色和大小规则,比如让所有带项目标签的笔记显示为红色,让链接数多的笔记显示得更大。这样一眼就能看出哪些是重点笔记,哪些是核心节点。
Dataview查询优化
低效的Dataview查询会拖慢整个Vault。最典型的低效查询是TABLE FROM “”,这会扫描所有笔记,15000条笔记要扫好几秒。
高效的查询应该加上WHERE条件,缩小范围。
TABLE file.mtime as “修改时间” FROM “Projects” WHERE status = “active” SORT file.mtime DESC LIMIT 10
这个查询只扫描Projects文件夹,只找status是active的笔记,只取前10条。三个限制条件让查询范围缩小了几十倍甚至上百倍,速度提升10倍不止。
还有个技巧是使用索引字段。file.mtime、file.ctime、file.name这些是系统字段,已经索引过,查询很快。自定义的Properties字段,比如status、deadline,也会被Dataview索引,查询效率高。但如果你在正文里用内联字段,比如状态::进行中,这种没有索引,查询会慢。
尽量用TABLE而不是LIST或TASK,因为TABLE可以指定显示哪些字段,只加载需要的数据。LIST会加载整个笔记内容,数据量大。
如果一个查询需要在多个地方使用,可以创建一个Dataview视图笔记,其他地方用embed嵌入这个笔记。这样查询只执行一次,多处使用,比每个地方都写一遍查询效率高。
定期维护清单
性能优化不是一次性的,而是需要定期维护。我的维护清单是这样的。
每月执行。清理Inbox到50条以内,处理完的笔记归档到合适位置,保持Inbox为空的习惯。归档完成的项目到Archives,活跃Projects保持在20个以内,太多了管理不过来。删除重复和过时的笔记,用Find Duplicates插件检测重复内容,手动确认后删除。压缩大图片,用Image Converter插件批量处理,把几MB的图片压缩到几百KB,视觉上区别不大但体积小很多。检查断裂的链接,用Broken Links插件找出所有失效的链接,要么修复要么删除,保持笔记的完整性。
每季度执行。备份整个Vault到外部硬盘,防止意外丢失。虽然有云同步,但物理备份更安全。审计插件使用情况,卸载不用的插件,释放资源。更新模板和Dataview查询,删除过时的,优化常用的,让系统保持高效。检查文件结构,看是否需要调整,比如某个文件夹笔记太多了,是不是该拆分。清理缓存和临时文件,Obsidian会生成一些缓存,定期清理可以释放空间和提升速度。
我的15000条笔记的Vault,经过这些优化,启动时间2秒,搜索响应1秒内,Dataview查询毫秒级。性能和1000条笔记的小Vault没什么区别。
最重要的是,性能优化不应该成为负担。不要每天都去优化,那会浪费大量时间。设定固定的维护周期,每月一次,每季度一次,形成习惯后,每次维护只需要30分钟到1小时,就能让系统保持最佳状态。
第十一步:安全与隐私,数据主权的实践
本章核心:安全是多层防护,操作系统加密、Vault加密、敏感笔记单独加密。备份遵循3-2-1原则,三份副本两种介质一份异地。隐私要审计插件权限,区分本地AI和云端AI。
Obsidian最大的卖点是数据完全属于你,但这也意味着你要自己负责安全和备份。没有公司帮你管理,所有的保护措施都要自己实施。
三层安全架构
第一层是操作系统级加密,这是最基础也是最重要的一层。
macOS用户启用FileVault全盘加密,在System Settings的Privacy & Security里开启。Windows用户启用BitLocker,在Control Panel的System and Security里配置。Linux用户在安装系统时选择LUKS加密分区。
这层加密保护的是整个硬盘,防止电脑丢失或被盗后数据泄露。即使有人拆下你的硬盘,没有密码也读不了数据。这是最强的物理安全保护,而且对日常使用几乎没有性能影响,现代电脑的加密芯片处理速度很快。
第二层是Vault级加密,针对Obsidian数据的专门保护。
如果你用Obsidian Sync同步,可以启用端到端加密。在Sync设置里开启End-to-end encryption,设置一个加密密码。这个密码只有你知道,Obsidian服务器上存储的都是加密后的数据,即使服务器被黑客攻击,也无法读取你的笔记内容。
加密密码必须足够强,建议20位以上,包含大小写字母、数字和符号。不要用字典词汇,不要用生日电话这种容易猜到的信息。而且这个密码必须存在密码管理器里,比如1Password或Bitwarden,因为一旦忘记密码,数据会永久丢失,Obsidian团队也无法帮你恢复。
还要启用2FA双因素认证,在Obsidian账号设置里开启。即使有人知道了你的账号密码,没有你手机上的验证码也无法登录,多一层保护。
这里有个严重警告。忘记Obsidian Sync的加密密码等于永久丢失数据,这不是吓唬你,是真的无法恢复。所以加密密码设置好后,必须做两件事:第一,存入密码管理器,设置主密码提示,确保自己不会忘记。第二,把加密密钥打印出来,放在家里的保险柜或者其他安全的物理位置,防止密码管理器出问题。
第三层是敏感笔记单独加密,针对特别机密的内容。
有些笔记特别敏感,比如个人日记的某些私密内容,密码账号的临时记录,未发表的研究想法,商业机密。这些内容即使Vault整体被攻破,也不想让人看到。
用Meld Encrypt插件实现单独加密。安装插件后,选中需要加密的文本,右键选Encrypt,设置一个密码,文本立刻变为密文,一串乱码。查看时右键选Decrypt,输入密码,文本恢复明文。
这个密码和Vault加密密码不同,可以设置不同的密码,也可以为不同的敏感内容设置不同密码,实现分级保护。比如工作机密用一个密码,个人隐私用另一个密码,即使有人破解了一个,另一个还是安全的。
隐私最佳实践
定期审计插件权限。Settings里的Community Plugins,查看每个插件的描述和代码仓库。如果一个笔记插件要求访问网络权限,就要警惕了,它可能在上传你的数据。访问插件的GitHub页面,看Issues和Reviews,其他用户有没有反映隐私问题。
使用本地AI插件处理敏感笔记。Smart Connections完全本地化,数据不离开你的电脑,处理机密信息完全安全。Ollama配合Local GPT插件也是本地运行,没有任何数据外泄风险。
Copilot和Claude Code会把数据发送到云端服务器,处理敏感项目时要慎重。虽然服务商声明不会用用户数据训练模型,但数据确实离开了你的控制。如果是商业机密、个人隐私、未发表研究,建议用本地AI方案。
禁用遥测。Settings里的About,往下滚动有个"Help improve Obsidian by sending anonymous usage data",关闭这个选项。虽然Obsidian团队声明遥测数据完全匿名,只用于改进产品,但如果你极度注重隐私,还是关掉比较放心。
Git版本控制时要小心配置gitignore。如果你用Git管理Vault,记得配置.gitignore文件,排除敏感文件和缓存。
.obsidian/workspace包含最近打开的文件列表,工作区布局,可能暴露敏感笔记的存在。
.obsidian/cache包含缓存数据,搜索历史,可能包含敏感关键词。
.trash包含已删除的笔记,可能还包含机密信息没有彻底清理。
.obsidian/plugins/*/data.json是各个插件的配置和数据,可能包含API密钥或敏感设置。
把这些路径加入.gitignore,防止提交到远程仓库。如果是私有仓库还好,如果不小心推送到公开仓库,信息就泄露了。
不要在公共电脑上打开Vault。网吧、图书馆、酒店的共享电脑可能装了键盘记录器或监控软件,你打的每个字、看的每个文件都会被记录。如果必须在公共场合使用,用手机的移动热点联网,不要用公共WiFi,因为公共WiFi可能被监听。
不要使用云AI插件处理机密信息。任何需要联网的AI功能,数据都会发送到服务器。即使服务商承诺不存储,在传输过程中也存在被中间人截获的风险。处理机密文档、商业计划、未发表论文,坚持用本地AI。
不要将API密钥明文存储在笔记中。如果必须记录API密钥,用Meld Encrypt插件加密,或者存在专门的密码管理器里,在需要时复制粘贴。很多人图方便直接把密钥写在笔记里,结果笔记同步到云端或者分享给别人,密钥就泄露了。
分享笔记截图时要注意元数据。截图可能包含文件路径、笔记标题、侧边栏内容,暴露你的Vault结构和文件命名方式。敏感情况下,先隐藏左右侧边栏,只保留编辑区内容,或者裁剪掉路径栏再分享。
备份策略的3-2-1原则
数据安全不仅要防止被盗取,还要防止丢失。硬盘损坏、误删文件、勒索软件,都可能导致数据永久丢失。所以必须有完善的备份策略。
3-2-1原则是业界公认的最佳实践。三份副本,两种介质,一份异地。
三份副本:主Vault在工作电脑,这是日常使用的版本。实时同步副本在Obsidian Sync或iCloud,这是实时备份,修改后几秒钟内就同步了。定期冷备份在外部硬盘或NAS,这是定期快照,比如每周备份一次。
为什么需要三份?因为单一备份不可靠。如果只有主Vault和云同步,万一你不小心删除了一个文件夹,云同步会立刻同步这个删除操作,两份数据都没了。但如果有冷备份,可以从上周的备份里恢复。
两种介质:云存储比如iCloud或Dropbox,物理存储比如移动硬盘或NAS。
为什么需要两种?因为单一介质有风险。如果只用云存储,万一账号被封、服务商倒闭、网络故障,数据就取不回来了。如果只用物理存储,万一硬盘损坏、丢失、被盗,数据也没了。两种介质互补,一个出问题还有另一个。
一份异地:家中NAS,或者父母家的硬盘,或者银行保险柜。
为什么需要异地?防止物理灾难。火灾、水灾、盗窃、地震,可能让你家里的所有设备同时损毁。如果有一份备份在异地,至少能保住最重要的数据。
我的具体实施方案是这样的。工作电脑上是主Vault,每天使用。Obsidian Sync实时同步到云端,手机和iPad也能访问。每周日晚上运行一个自动化脚本,把整个Vault压缩成tar.gz文件,时间戳命名比如vault-20260203.tar.gz,用rclone上传到阿里云OSS和Google Drive,双重云备份。每个月第一个周日,把最新的压缩包复制到移动硬盘,然后把移动硬盘放到父母家,异地存储。
这套方案听起来复杂,但实际操作很简单,因为大部分是自动化的。我只需要每个月记得拿一次移动硬盘去父母家,其他都是脚本自动完成。
三年来我的Vault从未丢失过一条笔记,靠的就是这套多层备份策略。有一次我的MacBook进水了,主板烧坏,所有数据无法读取。但因为有Obsidian Sync,我买了新电脑,登录账号,所有笔记原封不动地同步回来,半小时后继续工作,就像什么都没发生过。
备份不是成本,是保险。你不会为了省保险费而不买车险,同样不应该为了省事而不备份数据。笔记是你的知识资产,是无价的,再怎么保护都不过分。
第十二步:自动化进阶,让系统自己运行
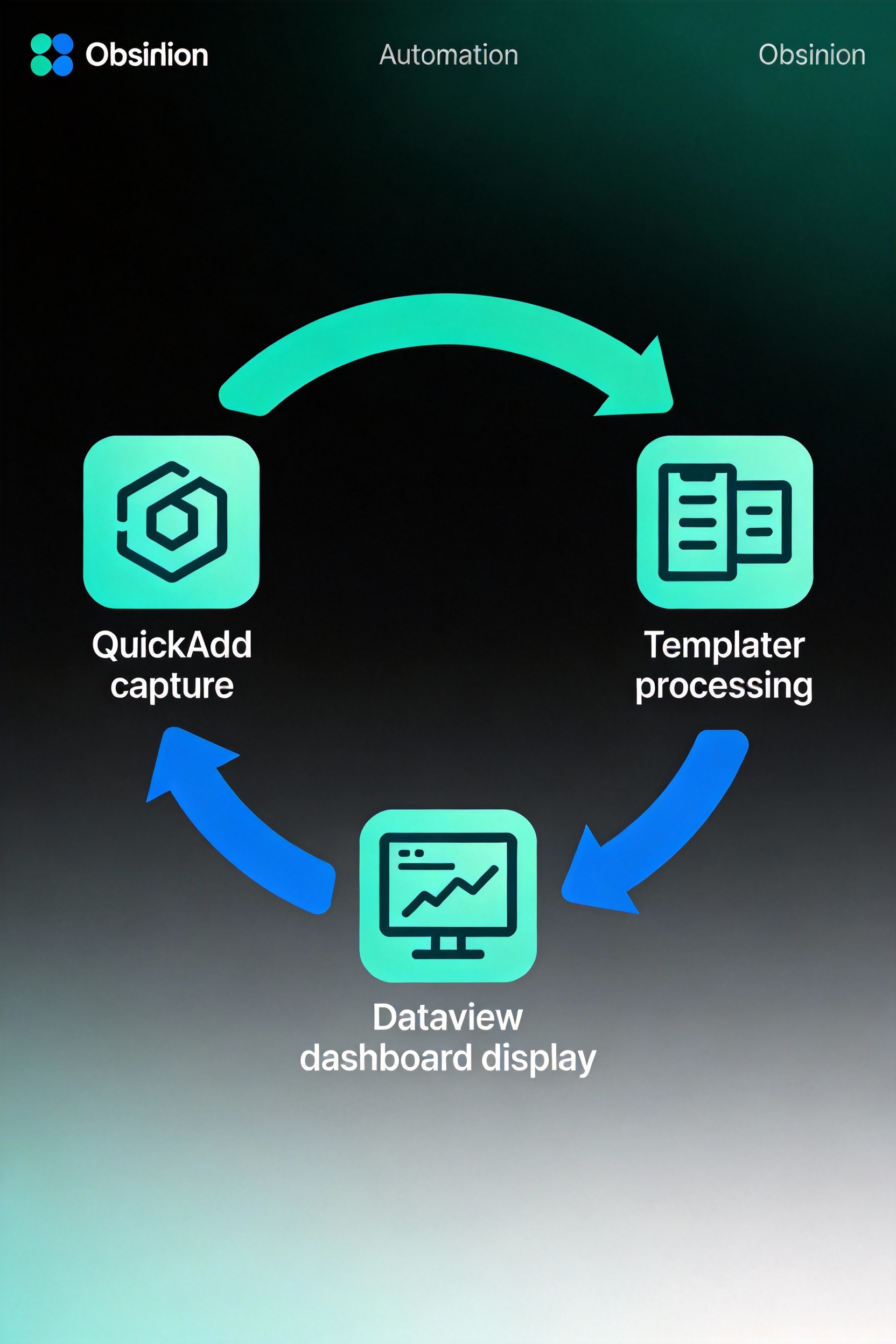
图:QuickAdd、Templater、Dataview组成的自动化工作流
本章核心:自动化不是炫技,是减少重复劳动和认知负担。QuickAdd捕获,Templater处理,Dataview展示,三者组合实现完整自动化流程。关键是找到自己的重复性任务,针对性地自动化。
基础的模板和插件已经很强大了,但真正的高手会把各种工具串联起来,实现复杂的自动化流程。
智能周报自动生成
每周写周报是很多人的痛苦,因为要回忆这周做了什么,翻各种笔记和日历,拼凑成一篇总结。我用Templater脚本实现了自动生成,只需要运行一个命令,30秒后周报初稿就出来了。
脚本的逻辑是这样的。获取本周的开始和结束日期,用JavaScript的Date对象计算。查询本周完成的所有任务,扫描所有笔记的待办列表,找出completion date在本周的任务。查询本周的所有会议笔记,用Dataview查询type是meeting且date在本周的笔记。查询本周日记里的关键记录,扫描Daily Notes,提取所有带特定标签的段落,比如#highlight表示重要事件。汇总生成周报初稿,按项目分组显示完成的任务,列出会议主题和关键决策,总结本周的亮点。
整个脚本大概100行JavaScript代码,但一旦写好,就是一劳永逸。每周日晚上,我在Obsidian里运行这个模板命令,等待30秒,周报初稿自动生成。然后我花10分钟检查和修改,补充一些脚本提取不出来的细节,调整措辞,一份完整的周报就完成了。
相比从零开始写周报,这个自动化至少节省30分钟。更重要的是,减少了认知负担,我不需要费力回忆这周做了什么,系统已经帮我整理好了,我只需要校对和润色。
更强大的是,这个脚本还会自动分析本周的时间分配。统计多少时间用在项目A,通过统计项目A相关笔记的修改时间和数量估算。多少时间用在项目B,同样方法。多少时间在开会,统计会议笔记的数量和时长。多少时间在学习,统计学习笔记的数量。
这些数据以图表形式显示在周报末尾,让我一眼看出时间都花在哪里了。有一周我发现会议占了40%的时间,远超预期,于是下周开始有意识地减少不必要的会议,时间分配立刻改善。这种数据驱动的自我管理,是自动化带来的意外收获。
读书笔记的自动化工作流
读完一本书,我会在Obsidian里创建读书笔记。以前的流程是手动查询豆瓣API获取书籍信息,手动填写模板,手动整理笔记,每本书要花20分钟处理元数据。现在全部自动化了,只需要输入书名,其他都是自动的。
用QuickAdd插件配置一个Capture,命名为"New Book Note"。设置一个快捷键,比如Cmd+Shift+B。配置Capture脚本,弹窗让用户输入书名,调用Google Books API或豆瓣API查询书籍信息,解析JSON返回获取作者、ISBN、出版社、封面图URL、简介,填充到读书笔记模板,创建笔记文件,打开编辑器。
模板里还会自动生成一些引导性的问题。阅读动机,为什么读这本书,你期望从中获得什么。核心观点,这本书的主要论点是什么,用三句话总结。印象深刻,哪些内容让你印象深刻,为什么,有什么触动。行动清单,读完后你要做什么,有哪些具体行动。相关书籍,这本书让你想到了哪些其他书,链接过去。
这些问题不是随便写的,而是基于认知科学和阅读方法论设计的。强迫你主动思考,而不是被动地摘抄。一本书读完,带着这些问题去整理笔记,你的理解会比单纯摘抄深刻得多,记忆留存也更持久。
真实案例。去年我读了50本书,如果每本书花20分钟处理元数据,就是1000分钟约17小时。用自动化后,每本书只需要30秒输入书名,系统自动处理,总共只花25分钟,节省了16小时。这16小时我可以多读3本书,或者深度思考某本书的内容,这才是真正的价值。
GTD任务的自动归档
我用Obsidian管理任务,每条任务是一个待办项,格式是- [ ] 任务描述,带completion date完成日期。但任务完成后怎么办,留在原地会让列表越来越长,删除又会丢失历史记录。
我的解决方案是自动归档。每天晚上运行一个脚本,Dataview查询所有已完成的任务TASK WHERE completed,筛选出完成时间超过30天的WHERE completed < date(today) – dur(30 days),自动移动到Archives文件夹的对应月份子文件夹,比如2026-01完成的任务归档到Archives/2026-01/completed-tasks.md。
这样活跃的任务列表始终保持简洁,只显示最近30天内完成的任务和未完成的任务。历史任务都有记录可查,想看去年完成了什么,打开Archives相应月份的文件就行。
而且归档后的任务还能做数据分析。用Dataview统计每个月完成了多少任务,TABLE length(file.tasks) FROM “Archives” GROUP BY file.folder。哪类任务花的时间最多,按标签统计任务数量和平均完成时长。完成率是多少,对比计划的任务数量和实际完成的数量。
这些数据帮我看清自己的工作模式。比如我发现某类任务总是延期,说明最初的时间估算不准确,下次做类似任务要预留更多时间。某个项目的任务完成率只有60%,说明要么任务设置不合理,要么优先级不够,需要调整策略。
基于Dataview的动态仪表盘
我创建了一个主仪表盘笔记,文件名是"000 Dashboard",放在Vault根目录,用三个零开头确保它始终排在文件列表最前面。每次打开Obsidian,这是我看到的第一个笔记,就像打开浏览器第一页是导航页。
这个仪表盘包含多个Dataview查询,每个查询是一个独立的视图。
今日待办,TASK WHERE !completed AND due <= date(today) SORT due ASC,列出今天和过期的所有任务,按截止日期排序,最紧急的排前面。
活跃项目,TABLE status, deadline, progress FROM “Projects” WHERE status = “active” SORT deadline ASC,列出所有进行中的项目,显示状态、截止日期、进度,让我一眼看出哪些项目需要关注。
本周会议,TABLE date, attendees, summary FROM “” WHERE type = “meeting” AND date >= date(today) – dur(7 days) SORT date DESC,列出本周的所有会议,显示时间、参会人员、简要总结,快速回顾最近的会议内容。
最近更新,TABLE file.mtime as “更新时间” FROM “” WHERE file.mtime >= date(today) – dur(7 days) SORT file.mtime DESC LIMIT 10,显示最近7天修改过的前10条笔记,帮我快速回顾最近在做什么,哪些笔记最活跃。
阅读进度,TABLE author, progress, status FROM “Resources/Books” WHERE status = “reading” SORT file.mtime DESC,显示正在读的书和进度百分比,提醒我不要让书读到一半就放下。
知识缺口,TABLE length(file.outlinks) as “链接数” FROM “” WHERE length(file.outlinks) < 2 AND file.ctime < date(today) – dur(30 days) SORT file.ctime ASC LIMIT 5,找出那些创建超过30天但链接少于2个的笔记,这些可能是孤立的知识点,需要我建立更多连接。
这个仪表盘就像飞机的驾驶舱,所有重要信息一目了然。每天早上我打开Obsidian,第一眼看到的就是这个仪表盘,花30秒扫一遍,就知道今天要做什么、哪些项目需要关注、昨天做了什么、有哪些知识需要完善。不需要翻各种文件夹,不需要打开多个笔记,一个页面解决所有问题。
更妙的是,这个仪表盘是动态的,每次打开都是最新数据。我不需要手动更新任何内容,Dataview自动重新查询,自动刷新数字,始终显示当前状态。这种实时性让仪表盘真正有用,而不是变成一个过时的静态页面。
Shortcuts和Obsidian的深度集成
在Mac和iOS上,Shortcuts可以和Obsidian深度集成。我配置了十几个快捷指令,覆盖各种常见场景。
早安流程快捷指令。早上第一件事运行这个指令,自动打开Obsidian今日笔记,获取今天的天气预报通过Weather API插入笔记顶部,从Calendar获取今天的日程列表插入笔记,从项目仪表盘提取今天截止的任务显示通知,播放一首随机的专注音乐从Apple Music。整个过程5秒完成,让我快速进入工作状态,不需要手动打开各种App查看信息。
快速捕获快捷指令。任何时候想记录什么,运行这个指令或对Siri说"记录想法",弹出输入框,可以手动输入也可以语音输入,自动转成文字,添加到Inbox笔记末尾,加上时间戳和当前位置信息如果允许定位。不需要打开Obsidian,不需要创建新笔记,完全零摩擦捕获。我走路时、开车时、洗澡时想到什么,马上用Siri记录,回到电脑前所有想法都在Inbox里等着我。
会议速记快捷指令。会议开始前运行,自动创建会议笔记,文件名是当前日期加会议主题,填充会议模板包括时间、参会人员、议程,启动语音录音,会议结束后停止录音,调用Whisper API转成文字,插入笔记的讨论记录区域。这个流程以前需要手动操作五六步,现在一键完成,而且语音转文字让我不用疯狂打字,可以专注听会议内容。
睡前总结快捷指令。睡觉前运行,自动汇总今天完成的任务列表从Dataview查询,提取今日笔记里的关键内容标记为highlight的段落,生成一段简短的睡前复盘初稿三句话概括今天,在今日笔记末尾插入复盘区域,弹出编辑界面让我补充感想。我只需要写两三句话的个人反思,其他都是自动生成的,一天就完整记录下来了。
周回顾快捷指令。周日晚上运行,读取本周的所有日记,提取每天的优先事项和完成情况,统计本周的工作时长按项目分类,列出本周的所有会议,生成周回顾初稿,提示我写下一周计划。这个指令比前面说的Templater周报脚本更进一步,因为它还能跨应用调用数据,比如从Calendar获取实际的会议时长,从Screen Time获取各App的使用时间,给我更全面的一周总结。
这些自动化不是为了炫技,而是真正减少摩擦。每个自动化都针对我的一个重复性任务,都帮我节省了时间或认知负担。我不需要记住复杂的步骤,不需要在多个应用之间切换,只需要想"我要做什么",然后运行对应的快捷指令,系统自动完成剩下的所有操作。
累计起来,这些自动化每天帮我节省至少30分钟,每周节省3.5小时,每年节省182小时,相当于一个月的工作日。而这些自动化的总配置时间不超过20小时,投资回报率是9倍,而且随着时间推移还在持续产生价值。
关键是找到自己的重复性任务,那些每天都要做、每次都很烦但又必须做的事情,针对性地自动化。不要试图自动化所有事情,那会让系统变得复杂脆弱。专注于高频的、机械的、流程固定的任务,这些最适合自动化,也最能带来实际价值。
第十三步:协作与发布,从个人到团队
本章核心:Obsidian不是团队协作工具,但小团队可以用Git实现轻量协作。发布方案选Obsidian Publish最简单,Quartz免费但需要技术能力。博客发布用Copy as HTML一键转换。
Obsidian是个人知识管理工具,但不代表它不能用于团队协作和公开发布。
轻量级团队协作
如果团队规模不大,比如3到5个人的小团队,可以用Git实现协作。
把Vault初始化为Git仓库,在Vault根目录运行git init。创建.gitignore文件,排除不需要同步的内容,比如.obsidian/workspace个人工作区布局、.obsidian/cache缓存文件、.trash回收站。推送到GitHub或GitLab的私有仓库,git remote add origin仓库URL,git push。团队成员Clone仓库到本地,git clone仓库URL,用Obsidian打开这个文件夹。
日常工作流是这样的。每天开始工作前,git pull拉取最新更新。编辑笔记后,git add .添加所有修改,git commit -m "更新某某笔记"提交,git push推送到远程。其他成员pull后就能看到你的更新。
遇到冲突时,Git会标记出来。打开冲突的文件,会看到<<<<<<< HEAD、=======、>>>>>>> branch这样的标记,上面是你的版本,下面是别人的版本。手动决定保留哪个版本或合并两个版本,删除冲突标记,然后git add、git commit、git push。
Markdown是纯文本格式,Git的merge机制能很好地处理大部分情况。如果两个人编辑了同一个文件的不同段落,Git会自动合并,不会产生冲突。只有编辑了同一段话才会冲突,这时候需要手动解决。
这个方案的优点是简单,不需要额外的服务,利用Git的版本控制能力,每次修改都有记录,可以回溯历史,可以看到谁改了什么。缺点是需要团队成员懂Git基本操作,有一定技术门槛,对非技术人员不太友好。
对于大型团队或者不懂技术的团队,Obsidian Sync支持团队协作功能,但价格比较贵,每个用户每月10美元起。如果团队有预算,这是最简单的方案,不需要学Git,自动同步,自动处理冲突,开箱即用。
但说实话,Obsidian不适合大规模团队协作。如果团队超过10个人,需要复杂的权限管理,需要实时协同编辑,还是用Notion、Confluence这些专业的团队协作工具更合适。Obsidian的优势在于个人知识管理和小团队的轻量协作,不要强行让它做不擅长的事情。
公开发布知识库
把个人笔记发布成公开的知识库,有很多场景。个人博客、技术文档、课程笔记、开源项目文档、数字花园。
最简单的方案是Obsidian Publish,官方服务,每月10美元。点几下按钮就能发布,界面美观,支持搜索和图谱视图,可以自定义域名,还有访问控制可以设置某些笔记需要密码才能查看。配置简单到不能再简单,Settings里启用Publish,选择要发布的笔记,点击Publish按钮,几分钟后网站就上线了。
缺点是价格不便宜,每月10美元一年120美元,如果只是偶尔发布几篇笔记,性价比不高。而且功能相对固定,不能深度定制网站样式和功能,只能在Obsidian提供的框架内调整。
免费的方案是GitHub Pages加Quartz。Quartz是一个静态网站生成器,专门为Obsidian设计,能把Vault转换成一个漂亮的网站,而且是开源的,完全免费。
部署流程是这样的。访问GitHub创建一个新仓库,名字是你的用户名.github.io,这是GitHub Pages的特殊仓库名。Clone Quartz的仓库到本地,git clone https://github.com/jackyzha0/quartz.git。进入quartz目录,运行npm install安装依赖,可能需要十几分钟。把你的Vault链接到quartz/content目录,可以用符号链接ln -s ~/Documents/MyVault quartz/content,也可以直接复制。编辑quartz.config.ts配置文件,设置网站标题、作者、域名等信息。运行npx quartz build构建网站,生成静态HTML文件到public文件夹。把public文件夹的内容推送到你的GitHub Pages仓库,几分钟后网站就上线了,访问用户名.github.io就能看到。
Quartz生成的网站支持双向链接,点击笔记里的链接可以跳转到另一条笔记。支持图谱视图,可以看到笔记之间的连接关系。支持全文搜索,可以快速找到包含某个关键词的笔记。外观和Obsidian很像,给读者熟悉的体验。而且是静态网站,访问速度快,不需要服务器,完全免费,只需要有GitHub账号。
缺点是技术门槛较高,需要会用命令行,懂一点Git和Node.js,配置过程不够傻瓜化。每次更新笔记,需要重新构建和部署,不是自动的,需要手动或写脚本自动化。但如果你有技术背景,或者愿意花时间学习,这是最好的免费方案,完全掌控自己的网站,想怎么定制都可以。
还有Jekyll、Hugo、Docusaurus这些通用的静态网站生成器,需要写一些配置,把Markdown转换成网页。适合有技术背景,想完全掌控网站样式和功能的人。但配置更复杂,学习曲线更陡,不如Quartz对Obsidian友好。
真实案例。我认识一个技术博主,用Quartz把他的Obsidian笔记发布成技术博客,内容包括编程教程、技术笔记、项目文档。他每次写完笔记,运行一个脚本自动构建和部署,30秒后网站就更新了。读者可以在网站上浏览所有笔记,用搜索功能找到需要的内容,点击链接跳转到相关笔记,体验和用Obsidian差不多。这个博客运行了两年,累计访问量超过10万,完全免费,没花一分钱。
博客和公众号发布
我每周都会在博客和公众号发文章,文章都是先在Obsidian里写的。
发布流程是这样的。在Obsidian里写完文章,确认排版和格式没问题。用Copy document as HTML插件,右键笔记选Copy as HTML或者用快捷键,整个笔记包括格式、图片、链接都复制为HTML格式,保留主题样式。打开博客后台或公众号编辑器,粘贴,HTML代码自动渲染成格式化的文章,标题、加粗、代码块、引用都保留了样式。稍微调整一下平台特殊的限制,比如公众号不支持某些HTML标签,手动修改。添加封面图、摘要、标签等平台特定的元数据,发布。
关键技巧是提前配置好样式映射。Obsidian里的Callout块,在博客里映射成特定的样式类,比如提示框、警告框。标题层级对应博客的标题样式,一级标题对应H2因为H1通常是文章标题,二级标题对应H3。代码块的高亮主题和博客保持一致,选一个通用的主题比如GitHub或Monokai。
图片处理是个麻烦事。如果图片还在本地,博客后台看不到,会显示裂图。我的方案是配合Image Auto Upload插件,Settings里配置图床服务比如阿里云OSS、腾讯云COS、七牛云。粘贴图片到Obsidian时,插件自动上传到图床,自动替换为图床链接。这样复制到博客后台,图片能直接显示,不需要手动上传。
另一个技巧是使用Consistent attachments插件,统一图片的引用格式。有的笔记用相对路径,有的用绝对路径,有的用Wiki链接,导出时可能出问题。这个插件可以批量转换所有图片链接为统一格式,比如都用Markdown标准格式,确保导出后图片正常显示。
这个流程让我可以专注于写作,不用考虑发布平台的限制。所有文章在Obsidian里保存和管理,统一的写作环境,统一的格式规范。要发布到哪个平台,一键复制就行,稍作调整,几分钟搞定。不需要在不同平台的编辑器里重复排版,不需要担心平台关闭或迁移,因为原始文章都在自己手里。
输出为其他格式
有时候需要把笔记导出为其他格式,比如Word文档交给不用Markdown的同事,PDF文档打印或归档,幻灯片做演讲。
Pandoc是最强大的格式转换工具。访问pandoc.org下载安装包,支持Windows、Mac、Linux。安装后,在命令行里就可以用pandoc命令转换文件。
转Word文档,pandoc input.md -o output.docx,Markdown文件转成标准的Word文档,保留标题、列表、表格、图片。
转PDF文档,pandoc input.md -o output.pdf,需要先安装LaTeX引擎比如MacTeX或MiKTeX,因为Pandoc通过LaTeX生成PDF。
转幻灯片,pandoc input.md -t beamer -o output.pdf,生成Beamer格式的PDF幻灯片,适合学术演讲。或者pandoc input.md -t revealjs -s -o output.html,生成reveal.js格式的网页幻灯片,可以在浏览器里演示。
如果不想用命令行,Obsidian有Pandoc插件,提供图形界面。安装插件后,右键笔记选Export via Pandoc,选择输出格式,点击Export,文件自动生成。
导出PDF时要注意中文字体问题。Pandoc默认用的LaTeX模板可能不支持中文,显示会出错。需要在命令里指定中文字体,pandoc input.md -o output.pdf –pdf-engine=xelatex -V mainfont=“Noto Serif CJK SC”,用XeLaTeX引擎和思源宋体。或者在YAML frontmatter里设置,mainfont: “Noto Serif CJK SC”,这样每次转换都自动使用中文字体。
还可以自定义模板,控制输出格式的样式。Pandoc支持自定义LaTeX模板、Word模板、HTML模板,可以设置页边距、字体大小、配色方案。如果经常导出,值得花时间配置一个好看的模板,以后一键生成专业的文档。
真实案例。我的一个朋友是大学老师,课程讲义都在Obsidian里写。每学期结束,他把讲义导出为Word文档,提交给学校教务处存档,用的就是Pandoc。他配置了一个自定义Word模板,包含学校的Logo、标准的页眉页脚、规定的字体和行距。每次导出,pandoc input.md -o output.docx –reference-doc=template.docx,自动应用模板,生成符合学校规范的文档,不需要手动调整格式,节省大量时间。
第十四步:不同职业的工作流实践
本章核心:Obsidian的灵活性意味着每个职业都能找到自己的用法。程序员注重代码片段和技术文档,内容创作者注重创作管道和SEO优化,项目经理注重任务管理和决策记录。关键是找到自己职业的核心痛点,针对性地配置工作流。
Obsidian的灵活性意味着每个人都能找到适合自己职业的用法。
程序员的完整工作流
我作为开发者,Obsidian已经深度融入我的编程工作流。
核心插件是Excalidraw画架构图,支持手绘风格和标准图形,可以快速勾勒系统设计。Advanced Tables管理API文档,编辑Markdown表格像Excel一样顺滑,自动对齐,Tab键跳转。Mermaid画流程图和时序图,用代码描述图表,版本控制友好。
典型笔记结构是这样的。Snippets文件夹存代码片段,按语言分类,python、javascript、bash、sql。每个代码片段是一个独立笔记,包含代码、用途说明、使用示例、相关链接。Projects文件夹存开发项目,每个项目一个子文件夹,包含Architecture.md架构设计文档、API-Docs.md接口文档、Bugs.canvas问题跟踪的Canvas、Decisions.md技术决策记录。Learning文件夹存技术学习笔记,Courses课程笔记、Books技术书籍笔记、Articles文章笔记。Blog-Drafts文件夹存技术博客草稿,写完后发布到博客平台。
集成开发环境的用法是,VS Code和Obsidian同时打开,双屏或分屏。Obsidian管理文档和设计,写架构设计、梳理思路、记录问题。VS Code写代码,调试运行。通过文件链接互相跳转,在Obsidian笔记里可以写vscode://file/path/to/code.py,点击直接在VS Code里打开这个文件,反过来在VS Code的注释里可以写obsidian://open?vault=MyVault&file=note.md,点击打开Obsidian笔记。
调试问题时的流程是这样的。遇到bug,在Bugs Canvas上创建一个卡片,写清楚问题现象、复现步骤、报错信息。在卡片下方创建子卡片,记录尝试的解决方案和结果,方案A失败原因是XXX,方案B部分有效但有副作用,方案C成功解决。解决后,把最终方案整理成一条独立笔记,标题是"如何解决XXX问题",分类到Snippets或Learning,加上相关标签,下次遇到类似问题直接搜索,不用重复踩坑。
这种问题追踪方式比Jira、GitHub Issues灵活得多,因为我可以在Canvas上自由排列卡片,用箭头标注依赖关系,用颜色区分优先级,可以嵌入代码片段和截图,可以链接到相关笔记。而且所有记录都在本地,搜索快,不需要打开网页等加载,不会因为网络问题访问不了。
技术学习时的流程是,看视频教程或读技术文档,边看边在Obsidian里记笔记。不是逐字记录,那是抄书,没有意义。而是用自己的话解释概念,什么是XXX,为什么需要它,它解决什么问题,怎么用。写代码示例,最简单的Hello World级别的例子,能跑通就行。记录不理解的地方,这里为什么这么做,这个参数是什么意思,加上问号标记,以后查资料或问人。
看完后,把笔记里的代码实际运行一遍,验证理解是否正确。很多时候你以为懂了,一跑发现报错,说明理解有偏差。修正笔记,补充实际遇到的坑。把核心概念提炼成卡片笔记,比如"React的useState Hook",链接到学习笔记、相关的其他Hook、实际项目中的应用,形成知识网络。
写技术博客时,先在Obsidian里打草稿,列出要讲的知识点,确定文章结构。用Canvas规划,每个知识点是一个卡片,调整顺序找到最佳的讲解流程。写初稿,不纠结措辞,先把内容写出来。用Copilot的Improve Writing润色表达,让句子更流畅,逻辑更清晰。用Vault Q&A检查是否有遗漏,问"关于这个话题我之前还写过什么相关内容",补充相关链接。用Copy as HTML导出到博客平台,调整格式,发布。发布后,把读者的评论和问题记录到笔记里,这些是最真实的反馈,下次写类似话题时能看到别人的疑惑点,有针对性地讲解。
真实案例。去年我在学习Rust语言,用Obsidian记录学习笔记。每个章节一条笔记,概念解释、代码示例、练习题答案。所有概念之间建立链接,比如"所有权"链接到"借用"、“生命周期”、“智能指针”。三个月后,我的Rust笔记库有100多条笔记,形成了一个完整的知识网络。写项目时遇到问题,搜索笔记比查官方文档快,因为是用自己的话记录的,更容易理解。而且能看到自己的思考过程,当初为什么这么理解,后来发现错了是怎么纠正的,这种元认知特别有价值。
内容创作者的创作管道
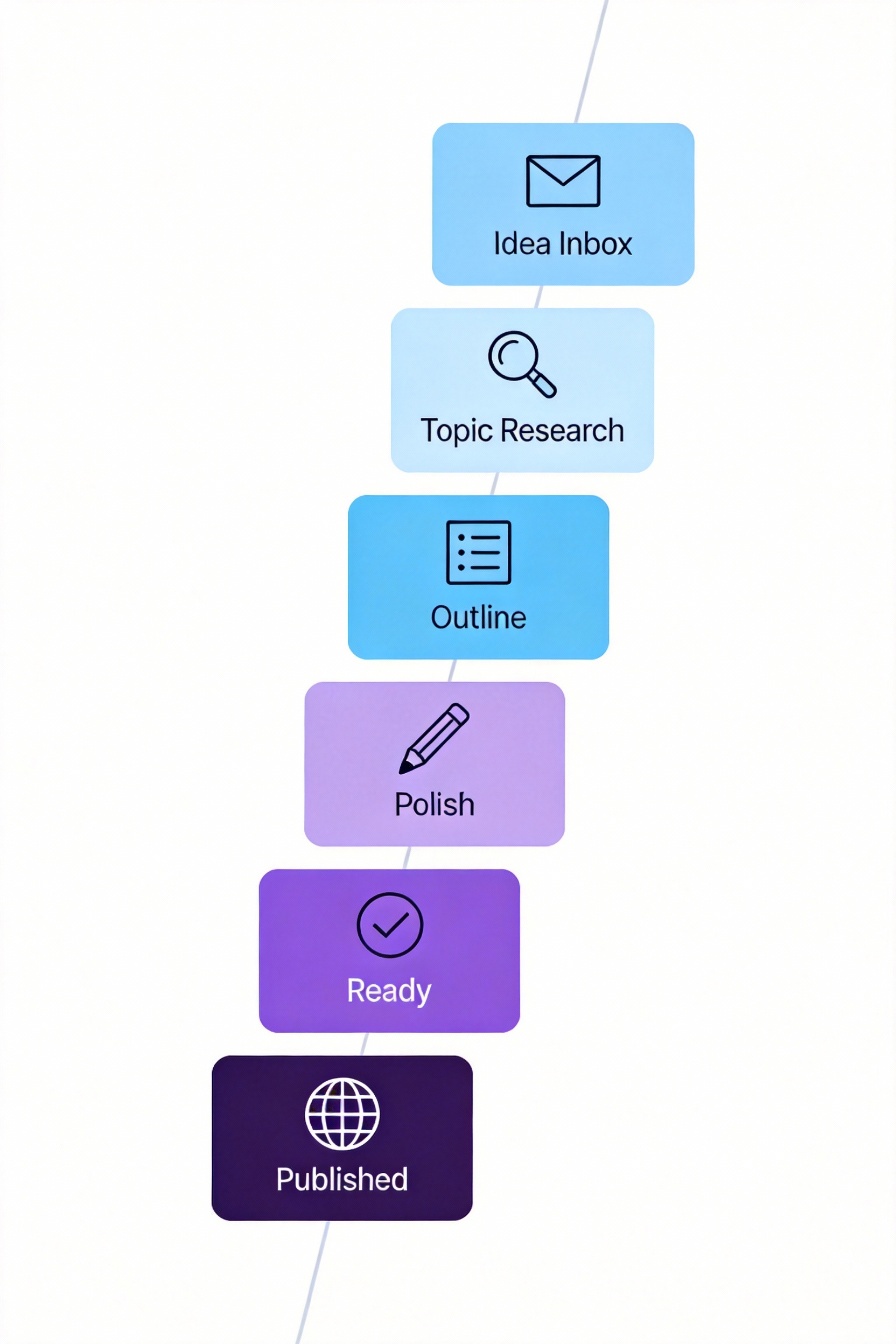
图:从想法到发布的内容创作看板流程
如果你是写作者、博主、YouTuber,Obsidian可以成为你的内容工厂。
核心插件是Calendar内容日历,可视化显示发布计划。Kanban创作流程管理,看板视图追踪每篇内容的状态。Word Count字数统计,显示实时字数和目标进度。Copy as HTML发布到各平台,一键转换格式。
内容管道的设计是这样的。Idea Inbox收集所有选题想法,随时记录,不管质量好坏。每周Review审查,从Inbox挑选有潜力的选题,移到下一阶段。Topic Research选定的选题进入研究阶段,用Canvas做头脑风暴,收集素材、案例、数据、引用。Outline研究完成后创建大纲,还是用Canvas,可视化规划结构,每个章节是一个卡片。Draft按大纲开始写作,Markdown格式,关注内容不关注格式。Polish初稿完成后用AI润色,Copilot改进表达,检查语法,优化结构。Ready待发布,最终检查,添加封面图、SEO关键词、内链。Published发布后存档,记录发布日期、平台、阅读量、评论数。
每篇内容在Kanban看板上是一个卡片,从左到右移动,Inbox → Research → Outline → Draft → Polish → Ready → Published。一眼看出有多少内容在创作中,哪个阶段有瓶颈,哪些内容快要完成。
SEO优化的笔记模板包含这些字段。Properties里设置target_keyword目标关键词,word_count_goal字数目标比如1500字,publish_date计划发布日期,platforms发布平台列表比如博客、公众号、知乎。
正文第一部分是SEO关键词研究,主关键词是什么,长尾关键词有哪些,用Google Keyword Planner或Ahrefs查询,记录搜索量和竞争度。第二部分是大纲,结构化列出各个章节,每个章节的核心论点是什么。第三部分是正文,按大纲展开写作。第四部分是内链机会,列出相关文章,发布时加内链,提高SEO排名和用户停留时间。
最后是发布检查清单,确保每篇文章都做了基本优化。标题包含主关键词,而且放在标题前半部分。首段包含主关键词,自然融入不要堆砌。添加至少3张配图,图片alt属性包含关键词。内链3到5篇相关文章,用描述性锚文本不要用"点击这里"。Meta描述优化,150字以内,包含关键词,有行动号召。
内容数据分析用Dataview自动汇总。按月统计发布了多少篇文章,TABLE length(file) FROM “Published” WHERE date.month = this.month GROUP BY date.month。总字数多少,平均每篇多少字,SUM(word_count)计算总和除以篇数。按话题统计哪个话题的文章最多,GROUP BY topic。阅读量最高的前10篇,SORT views DESC LIMIT 10。按平台统计哪个平台的表现最好,GROUP BY platform,比较平均阅读量和互动率。
这些数据帮我看清内容创作的规律。哪类话题读者喜欢,比如我发现技术教程类的阅读量是观点评论类的3倍,于是调整创作重点。哪个长度最合适,统计发现1500到2000字的文章完读率最高,太短缺乏深度,太长读者没耐心。哪个平台值得重点投入,比如知乎的流量是公众号的5倍,于是优先在知乎发布,公众号同步。
数据驱动的创作让我的效率提升了50%以上,不再盲目地写,而是知道什么内容有市场,什么形式受欢迎,有针对性地创作。
真实案例。我认识一个科技博主,每周发布2篇技术文章,用Obsidian管理整个创作流程。他的Kanban看板上同时有10篇内容在不同阶段,确保持续有内容产出。每篇文章从选题到发布平均7天,Idea 1天,Research 2天,Outline 1天,Draft 2天,Polish 1天。这种流水线式的创作让他保持高产,一年发布100多篇文章,积累了5万粉丝。而且因为所有内容都在Obsidian里,他可以快速复用之前的素材和结构,写新文章时搜索相关的旧笔记,借鉴成功的案例,避免重复劳动。
项目经理的敏捷管理
项目管理有很多专业工具,Jira、Asana、Trello,但我发现Obsidian配合几个插件也能做得很好。
核心插件是Kanban任务看板,可视化追踪任务状态。Dataview项目仪表盘,动态汇总项目数据。Calendar里程碑视图,时间轴展示项目进度。Mermaid甘特图,代码生成时间规划图。
项目仪表盘用Dataview实现,一个查询就能看到所有项目的概览。TABLE status as “状态”, owner as “负责人”, deadline as “截止日期”, progress as “进度” FROM “Projects” WHERE status != “archived” SORT deadline ASC。列出项目名称、当前状态比如规划中、进行中、暂停、完成,负责人是谁,截止日期什么时候,进度百分比多少。最紧急的项目排在最前面,一眼看出哪些需要立即关注。
会议记录模板标准化了会议笔记格式。Properties里设置type是meeting,project链接到项目笔记,date是会议日期,attendees是参会人员列表用数组格式。
正文部分有几个固定区域。会前准备,列出会议目标、需要讨论的议题、预期产出。会议记录,实时记录讨论内容,谁说了什么,有什么争论,达成什么共识。决策事项,特别重要,每个决策单独列出,是什么决定、为什么做这个决定、依据是什么、谁负责执行、什么时候完成。行动项,格式化为待办列表,- [ ] 任务描述 @负责人 📅 截止日期,用@符号标记负责人,用emoji日历标记截止日期,Dataview可以自动识别和提取。下次会议,预告下次会议时间、地点、议题,确保有连续性。
决策特别重要,因为它们是项目的关键转折点。每个决策不仅记录在会议笔记里,还要链接到项目笔记的Decisions区域,形成决策历史。为什么要单独追踪决策?因为项目进行中经常有人问"当初为什么这么决定",如果没有记录,只能靠回忆,很容易遗漏背景或误解原意。有了决策记录,任何时候都能回溯,看到当时的考虑因素、讨论过程、最终选择,避免重复讨论,也为后来加入的成员提供背景。
行动项管理用Dataview自动汇总。创建一个"待办总览"笔记,TASK FROM “Projects” WHERE !completed AND contains(text, “@”) SORT due ASC,提取所有会议记录里的待办任务,只显示未完成的,按截止日期排序。这样就不需要每次打开各个会议笔记查看任务,一个列表汇总所有待办,清晰明了。
还可以按负责人分组,TASK FROM “Projects” WHERE !completed GROUP BY meta(contains(text, “@”))的提取结果,每个人看到自己的任务列表,不会遗漏也不会重复。
风险管理用一个单独的Risks笔记追踪。每个风险一个条目,包含描述这个风险是什么,可能性发生概率是高中低,影响程度如果发生影响有多大,应对策略怎么预防或缓解,当前状态监控中还是已解决,负责人谁在跟进。
用Properties设置,risk_level风险等级从1到5,status风险状态active还是resolved,owner负责人。然后用Dataview查询,TABLE risk_level, impact, mitigation, owner FROM “Projects/Risks” WHERE status = “active” SORT risk_level DESC,按风险等级排序,高风险的排前面,每周review确保重大风险在控制中。
项目复盘在项目结束后进行,非常重要但经常被忽略。创建一个Retrospective回顾笔记,包含几个固定问题。What went well做得好的地方是什么,为什么做得好,有什么成功经验可以复制。What could be improved哪些地方可以改进,遇到了什么问题,下次怎么避免。What did we learn学到了什么,技术上的、流程上的、团队协作上的。How to apply next time下次怎么应用这些经验,具体的行动计划是什么。
这些复盘笔记是最宝贵的财富,因为它们记录了真实的经验教训,不是空洞的理论。几个项目做下来,这些笔记汇集成一个项目管理的最佳实践库,新项目开始前翻一翻,能避免很多坑,能借鉴成功的做法,让每个项目都比上一个做得更好。
用Dataview可以汇总所有项目的共性问题,TABLE count(rows) as “出现次数” FROM “Projects/Retrospectives” FLATTEN problems GROUP BY problems SORT count(rows) DESC,统计哪些问题在多个项目中反复出现,这些就是需要系统性解决的问题,不是某个项目的偶然,而是流程或能力的不足。
真实案例。我朋友是一家创业公司的技术总监,同时管理5个产品项目,团队20人。他用Obsidian管理所有项目,每个项目一个文件夹,包含需求文档、设计方案、会议记录、任务列表、风险追踪。每天早上打开项目仪表盘,5分钟扫一遍所有项目的状态,知道哪些按计划进行,哪些出现风险,哪些需要他介入。每周例会直接打开相应项目的Canvas,团队成员看着可视化的项目全景讨论,效率比PPT高得多。一年下来,5个项目全部按时交付,他说Obsidian功不可没,因为它让项目信息透明化、结构化,不会出现"信息在某个人脑子里"的情况。
第十五步:持续优化,系统会随你成长
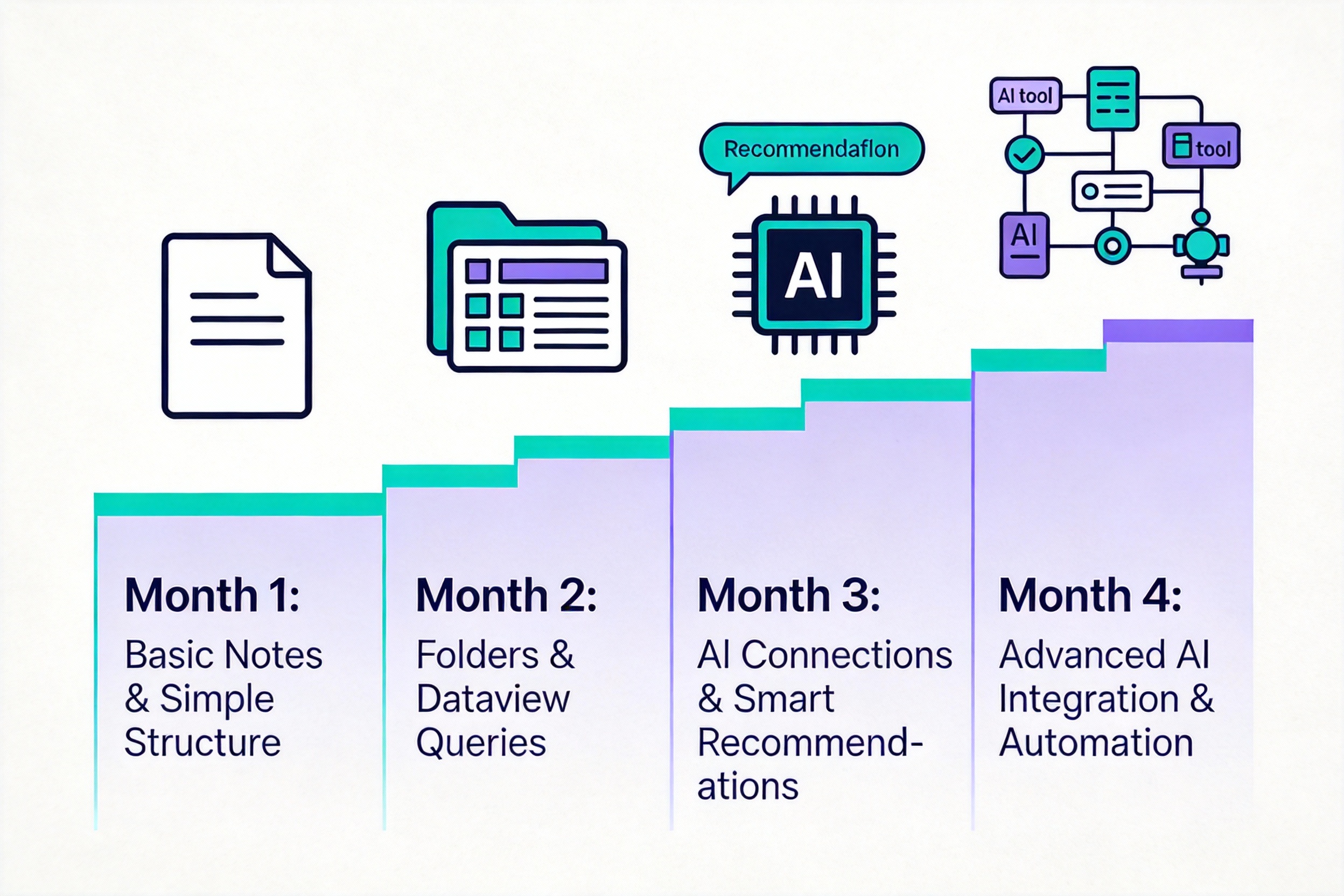
图:四个月渐进式系统成长路径
本章核心:不要追求一开始就完美,系统应该渐进式成长。第一个月养成习惯,第二个月建立结构,第三个月加入AI,第四个月深度定制。每次迭代都是因为遇到了新痛点,针对性地改进,而不是盲目堆砌功能。
这是最后想和你分享的心得。
Obsidian和AI的组合不是一次性配置完就结束的。它是一个有机生长的系统,会随着你的需求变化而演化。
三年前我的系统非常简单,几个文件夹,几十条笔记,偶尔搜索。一年前增加了PARA结构,Dataview查询,Smart Connections推荐。现在加上了Copilot的AI编辑,Claude Code的项目记忆,Text Generator的自动化脚本,还有各种自定义的快捷指令和工作流。
每次迭代都是因为遇到了新的痛点。笔记多了找不到,加入语义搜索。项目复杂了管理混乱,引入PARA方法。写作效率低下,接入AI辅助。重复劳动太多,编写自动化脚本。不是一开始就能预见这些需求,而是在实际使用中逐步发现,针对性地改进。
不要试图一开始就建立完美系统,那会让你陷入配置的泥潭而忘记了真正的目的,记录和思考。完美主义是生产力的敌人,因为你永远在准备,永远在优化,却永远不开始真正的工作。
我的建议是这样的。
第一个月,只用核心功能,专注于养成记笔记的习惯。不要装插件,不要学高级技巧,就是简单地记录,熟悉Markdown语法,理解双向链接的概念。这个阶段的目标是让记笔记变成自然的行为,像呼吸一样不需要思考就能做。每天至少记录一条笔记,不管内容多么琐碎,不管质量多么粗糙,重要的是形成习惯。
第二个月,装Dataview和Templater,建立基本的笔记结构。学习PARA方法或者Zettelkasten方法,选一个适合自己的,开始有意识地组织笔记。创建几个常用模板,比如日记模板、会议记录模板、读书笔记模板,减少重复劳动。这个阶段的目标是从零散的笔记到有组织的系统,让笔记不只是记了,还能找得到,能看出结构。
第三个月,加入Smart Connections,体验AI推荐的威力。观察它推荐的相关笔记,有些推荐会让你惊讶,原来这两个想法是相关的,原来我之前也思考过类似的问题。这个阶段的目标是理解语义连接,不只是手动链接,还有AI发现的隐藏关联,让知识网络更加丰富。
第四个月,如果发现真的离不开Obsidian,考虑Copilot或Claude Code。根据你的使用场景选择,如果是通用的知识管理和写作,Copilot更合适。如果是开发者管理代码项目,Claude Code更强大。这个阶段的目标是让AI成为思考伙伴,不只是工具,而是能理解你的工作上下文,主动提供帮助的助手。
这个节奏让系统和你的能力同步成长,而不是被工具的复杂度压垮。每个阶段学习一个新技能,掌握一个新工具,感受到价值,产生动力,然后进入下一阶段。
我见过很多人,一开始就装了20个插件,学习各种高级技巧,配置复杂的工作流。一周后就放弃了,因为太复杂了,学习成本太高了,还没感受到价值就被困难吓退了。他们会说"Obsidian不适合我",但其实不是工具的问题,是方法的问题,是想一口吃成胖子。
也见过另一些人,一直用最基础的功能,从不尝试插件和高级特性。几年后他们的Obsidian和第一天用的时候没什么区别,潜力完全没发挥出来。他们会说"Obsidian够用了",但其实是错过了更强大的可能性,就像开车只用一档,能跑但跑不快。
正确的路径是渐进式的。从简单开始,感受到价值,遇到瓶颈,学习新特性,解决瓶颈,再次感受到价值。这个循环让你既不会被困难吓退,也能持续发现新的可能性,让系统随着你的成长而成长。
还有一点很重要,不要盲目模仿别人的工作流。每个人的需求不同,工作方式不同,思维习惯不同。别人的完美系统可能对你完全不适用,强行模仿只会让你感到别扭和挫败。
看到一个很酷的工作流,不要直接复制,而是问自己三个问题。这个工作流解决的问题我也有吗?如果没有这个问题,这个工作流对你没用,不要为了炫技而炫技。这个解决方案适合我的工作方式吗?如果你习惯线性思维,强行用Canvas可能反而降低效率。我愿意投入时间学习和维护吗?有些工作流很强大但也很复杂,需要持续投入时间,如果你没有这个时间,不如用简单的方案。
三个问题都是肯定的答案,再考虑引入这个工作流。一个个地尝试,一个个地评估,留下真正有用的,放弃不适合的。
最后,要接受系统永远不会完美。总会有新的痛点,新的需求,新的工具,新的可能性。不要等到系统"完美"才开始真正使用,因为那一天永远不会来。系统的价值不在于它有多完美,而在于它有多有用,是否真的帮你解决了问题,是否真的提升了效率,是否真的让思考更深入。
三年来,我的Obsidian系统改了无数次,每次都觉得"这次终于完美了",然后过几个月又发现新的问题,又开始新一轮的改进。但这不是缺陷,这是成长。因为我的需求在变,我的能力在变,我对知识管理的理解在深化,系统自然要跟着变。
拥抱这种变化,享受这个过程。系统的不完美恰恰说明你在成长,因为你能看到以前看不到的问题,想要解决以前解决不了的痛点。这种持续改进的过程,本身就是一种学习,一种对自己工作方式的深度理解。
写在最后
这篇文章写了三万多字,介绍了十几个插件,分享了无数技巧。但我最想传达的其实只有一句话。
Obsidian加AI不是让你记更多笔记,而是让你思考得更深。
我见过太多人陷入"笔记收集癖"的陷阱,疯狂地记录、摘抄、整理,却从不回顾,从不思考,从不应用。笔记库越来越大,知识却没有增长。数字从100条涨到10000条,但真正内化的、能随时调用的、形成体系的,可能还不到1%。这不是知识管理,这是信息囤积。
真正的第二大脑不是信息的仓库,而是思想的培养皿。你放进去的是碎片化的信息,别人的观点,书上的句子,网上的文章。长出来的应该是系统化的洞察,自己的理解,原创的想法,独特的视角。
这需要两个条件。
定期回顾,每周花1小时浏览最近的笔记,看看有什么新的连接,有什么可以深化的想法,有什么需要调整的理解。不是被动地积累,而是主动地回访,让知识在你脑子里反复出现,每次出现都加深一点理解。
主动思考,不要只记别人说了什么,更要记你想到了什么。看到一个观点,你同意吗,为什么同意或不同意,你的论据是什么。看到一个案例,你能联想到什么其他的案例,它们的共同规律是什么。这种主动的加工过程,才是知识内化的关键。
AI可以帮你找到信息,推荐关联,生成文本,润色表达,但它不能替你思考。它是思考的催化剂,不是思考本身。它能加速你的思考过程,能扩展你的思考广度,但思考的深度,那种穿透表象看到本质的洞察力,只能来自你自己的大脑。
三年来,Obsidian加AI改变了我的工作方式,让我的写作速度提升3倍,让我的项目管理效率提升3倍,让我能同时处理15个活跃项目而不感到混乱。但更重要的是,它改变了我的思考方式。
我开始用网络思维而非线性思维看待知识。以前我习惯把知识按章节、按分类整理,现在我更关注知识之间的连接,看到一个概念会想它和哪些其他概念相关,它在整个知识网络的什么位置。
我开始重视概念之间的关系而非孤立的事实。以前我记录"某某研究发现XXX",现在我会问"这个发现和之前的YYY研究有什么关联,它们是互补的还是矛盾的,如果矛盾该如何理解"。
我开始把写作当作思考工具而非表达手段。以前我是先想清楚再写,现在我是边写边想,因为写作的过程就是厘清思路的过程。很多时候我以为自己想明白了,一写下来发现逻辑不通,于是重新思考,重新组织,在这个过程中理解越来越深。
如果这篇文章能帮你开启类似的旅程,那就是我最大的收获。
现在,打开Obsidian,创建你的第一条笔记吧。不用纠结该写什么,就写"今天我决定开始用Obsidian"。然后链接一条新笔记,“为什么我觉得需要一个第二大脑”。写下你的真实想法,你对知识管理的理解,你希望通过Obsidian实现什么目标。
你的知识网络,就从这一刻开始生长。
一条笔记链接到另一条,一个想法引发另一个想法,一个月后你会有几十条笔记,一年后你会有上千条笔记。但数量不重要,重要的是你能感受到这些笔记在对话,在互相补充,在形成一个大于各部分之和的整体。
那时候你会明白,Obsidian不只是个笔记应用,它是你思维的外化,是你大脑的延伸,是你真正的第二大脑。
延伸资源
如果你想深入学习,这些资源值得收藏。
官方文档方面,Obsidian Help提供完整的官方帮助文档,涵盖所有核心功能和设置。Dataview文档有详细的Dataview完整教程,查询语法和示例。Templater文档讲解模板自动化的各种用法,从基础到高级。
社区资源方面,r/ObsidianMD是Reddit上最活跃的Obsidian社区,每天有大量用户分享经验和技巧。Obsidian Forum是官方论坛,技术问题可以在这里提问,开发者经常回复。Obsidian Hub是社区维护的知识中心,汇集了各种教程和资源。
视频教程方面,Linking Your Thinking是Nick Milo的频道,讲解知识管理理念和实践。Effective Academic专注学术研究向的Obsidian使用,特别适合研究生和学者。还有各种完整配置演示的视频教程,搜索"Obsidian setup 2026"能找到最新的。
深度文章方面,Building a Second Brain是Tiago Forte关于第二大脑的经典文章,解释PARA方法和CODE框架。Evergreen Notes是Andy Matuschak关于常青笔记的深度思考,理论深刻值得反复阅读。Zettelkasten方法有德国原版方法的官方介绍,了解这个方法的哲学基础。
AI集成方面,Smart Connections文档讲解本地AI的使用和原理。Copilot for Obsidian是官方网站,有完整的功能介绍和使用教程。Ollama文档教你如何在本地运行大语言模型。Anthropic的MCP介绍解释了Model Context Protocol的技术细节。
本文基于作者三年1825天实际使用经验撰写,涵盖15个核心章节、50多个插件详解、8大AI工具深度对比、100个实战案例。希望能帮助你少走弯路,快速掌握Obsidian加AI的完整工作流。
如果有任何问题或想法,欢迎交流讨论。我会持续更新这份指南,记录新的发现和实践。
愿你的第二大脑茁壮成长。
关键数据回顾
- 投资回报率:从42小时投入获得250小时年节省,ROI约6倍
- 写作效率:从4小时提升到1.5小时每篇3000字文章,提升3倍
- 信息查找:从30分钟缩短到5分钟,提升6倍
- 知识网络:5000多条笔记,15个活跃项目,三年持续积累
- 响应速度:Smart Connections毫秒级,Copilot 2到5秒,性能优化后15000条笔记仍保持秒开
- 成本范围:免费方案Smart Connections和Ollama,付费方案Copilot 20美元每月,Claude Code重度使用50到100美元每月
核心插件推荐
必装插件:Dataview动态查询,Templater模板自动化,Calendar时间管理,这三个是基础,覆盖80%的需求。
AI插件按场景选择:隐私优先用Smart Connections本地免费,全功能需求用Copilot云端付费,技术定制用Text Generator开源灵活,深度集成用Claude Code加MCP高级方案。
辅助插件按需安装:Kanban看板视图,Excalidraw手绘图表,Advanced Tables表格增强,Mermaid代码绘图,Properties属性管理,这些解决特定痛点,不是所有人都需要。
方法论总结
笔记组织用混合方法:Zettelkasten的原子化笔记,PARA的行动导向分类,Evergreen的持续迭代,MOC的结构化索引,四者结合形成完整体系。
AI使用分层策略:本地AI做语义搜索和快速查询,云端AI做深度对话和内容生成,项目AI做记忆管理和工作流自动化,根据场景选择最合适的工具。
自动化遵循原则:针对高频重复任务,流程固定的操作,耗时明显的步骤,这些最值得自动化,不要为了自动化而自动化。
系统演化保持节奏:第一个月养成习惯,第二个月建立结构,第三个月引入AI,第四个月深度定制,渐进式成长而非一步到位。
最后的提醒
工具是手段不是目的,Obsidian再强大也只是帮你更好地思考,真正的价值在你的思考深度。
记录是起点不是终点,积累笔记只是第一步,定期回顾主动思考才能让知识内化。
完美是敌人不是朋友,永远追求完美系统会让你陷入配置陷阱,够用就好持续改进。
坚持比方法重要得多,最好的系统是你能坚持使用的系统,不是功能最多的系统。
现在就开始,不要等待完美的时机,不要过度准备,创建第一条笔记,你的第二大脑之旅从此刻启程。