想象一下,当你还是小孩的时候,第一次学习骑自行车的场景。你不断尝试,摔倒,再爬起来,直到最终掌握平衡的技巧。这个过程中,没有人手把手教你每一个动作的细节,而是通过无数次的试错,你的大脑逐渐学会了如何协调身体、如何保持平衡。
视频版:https://www.youtube.com/watch?v=M-GP5oUJj58
这就是强化学习(Reinforcement Learning,简称RL)的精髓所在——通过与环境的交互,在试错中学习,最终找到最优的决策策略。
从AlphaGo说起:AI的里程碑时刻
2016年3月,围棋界发生了一件震撼世界的事情。DeepMind开发的AlphaGo击败了世界围棋冠军李世石,这不仅仅是一场比赛的胜利,更标志着人工智能在复杂决策问题上的重大突破。
围棋被认为是人类最复杂的棋类游戏之一,其可能的棋局数量超过了宇宙中原子的数量。传统的计算机程序无法通过暴力搜索来解决这个问题。但AlphaGo通过强化学习,学会了如何评估棋局、如何选择下一步最优的走法。
更令人惊奇的是,AlphaGo Zero完全从零开始,仅通过自我对弈就超越了原版AlphaGo的水平。这展示了强化学习的真正威力:不需要人类专家的指导,智能体可以通过自主探索发现最优策略。
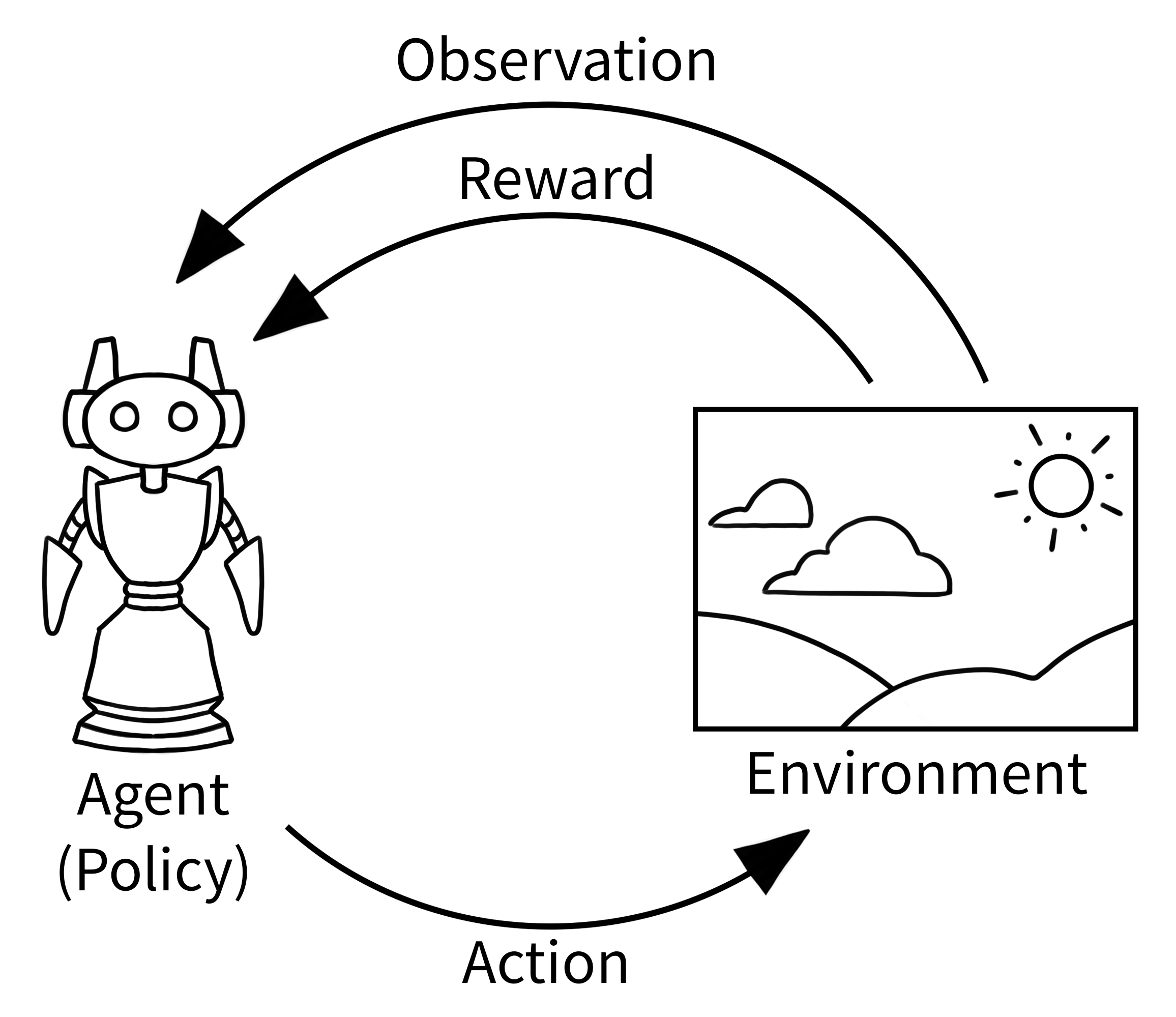
强化学习的核心世界:Agent与Environment的永恒对话
智能体(Agent):决策的主角
在强化学习的世界里,智能体就像是一个初入社会的新人。它需要在复杂的环境中做出各种决定,每个决定都会带来不同的后果。智能体可能是游戏中的角色、自动驾驶汽车的控制系统,或者是学习走路的机器人。
智能体的"智慧"体现在它能够从经验中学习。就像我们人类一样,智能体会记住哪些行为带来了好的结果,哪些行为应该避免。这种学习能力让它能够在面对新情况时做出更好的决策。
环境(Environment):智能体的训练场
环境是智能体的整个世界。在CartPole游戏中,环境包括小车的位置、速度,以及杆子的角度和角速度。在围棋中,环境就是19×19的棋盘和当前的棋局状态。
环境的特点是它会根据智能体的动作发生变化,并给出相应的反馈。这种反馈机制是强化学习的核心驱动力。
状态(State):当下的快照
状态就像是某个时刻环境的快照。在迷宫游戏中,状态可能是"在第3行第5列的位置";在股票交易中,状态可能包括当前股价、交易量、技术指标等信息。
状态信息的质量直接影响智能体决策的好坏。如果状态信息不完整或者有噪声,智能体就像是在雾中开车,很难做出最优决策。
动作(Action):改变世界的力量
动作是智能体影响环境的唯一方式。在CartPole中,动作只有两个:向左推车或向右推车。在复杂的机器人控制中,动作可能包括每个关节的转动角度和力矩。
动作空间的设计是一门艺术。太简单的动作空间可能限制智能体的表现力,太复杂的动作空间又会让学习变得困难。
奖励(Reward):学习的指南针
奖励是环境给智能体的即时反馈,它告诉智能体"这个动作好不好"。在游戏中,奖励可能是得分;在机器人行走中,奖励可能与行走速度和稳定性相关。
奖励函数的设计至关重要。一个设计不当的奖励函数可能导致智能体学到意想不到的行为。比如,如果只奖励机器人前进的距离而不考虑稳定性,机器人可能会学会快速前进但经常摔倒的"策略"。
马尔可夫决策过程:强化学习的数学基础
强化学习的理论基础是马尔可夫决策过程(Markov Decision Process, MDP)。MDP提供了一个数学框架来形式化顺序决策问题。
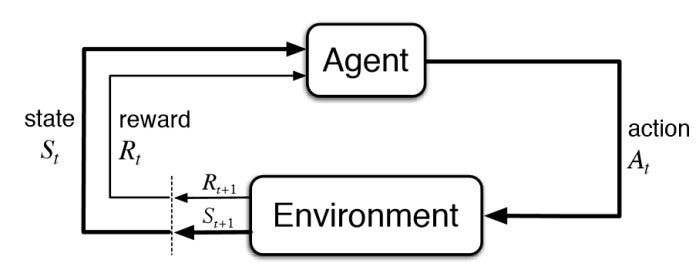
MDP的核心是马尔可夫性质:未来只依赖于现在,而不依赖于过去的历史。用数学语言表达就是:
P(s_{t+1} | s_t, a_t, s_{t-1}, a_{t-1}, …) = P(s_{t+1} | s_t, a_t)
这个性质大大简化了问题的复杂性,使得我们可以用相对简单的算法来解决复杂的决策问题。
策略(Policy):行为的艺术
策略定义了智能体在每个状态下应该采取什么动作。策略可以是确定性的(在给定状态下总是选择同一个动作)或随机性的(在给定状态下按概率分布选择动作)。
找到最优策略是强化学习的终极目标。最优策略能够最大化智能体在长期内获得的累积奖励。
价值函数(Value Function):未来收益的预测
价值函数评估某个状态或状态-动作对的"价值",即从这个状态开始,按照某个策略行动能够获得的期望累积奖励。
状态价值函数V(s)告诉我们"在状态s有多好",而动作价值函数Q(s,a)告诉我们"在状态s采取动作a有多好"。这些函数是智能体做决策的重要依据。
Gymnasium:强化学习的实验室
Gymnasium(原OpenAI Gym)为强化学习研究提供了标准化的环境接口。它就像是一个虚拟的实验室,研究者可以在其中测试各种算法。
CartPole:平衡的艺术
CartPole是最经典的强化学习环境之一。智能体需要控制一个小车左右移动,使得车上的杆子保持竖直不倒。这个看似简单的任务实际上需要精确的控制策略。
import gymnasium as gym
# 创建CartPole环境
env = gym.make("CartPole-v1", render_mode="human")
# 重置环境
observation, info = env.reset()
for _ in range(1000):
# 选择动作(这里是随机选择)
action = env.action_space.sample()
# 执行动作
observation, reward, terminated, truncated, info = env.step(action)
if terminated or truncated:
env.reset()
env.close()
FrozenLake:不确定性中的决策
FrozenLake环境模拟了在结冰湖面上的行走。智能体需要从起点走到终点,但要避免掉入冰窟窿。环境的不确定性(有时智能体可能滑向意想不到的方向)让这个问题变得更加有趣。
算法的进化:从Q-Learning到Deep Q-Networks
Q-Learning:价值学习的先驱
Q-Learning是最经典的强化学习算法之一。它通过学习动作价值函数Q(s,a)来找到最优策略。Q-Learning的更新规则简洁而优雅:
Q(s,a) ← Q(s,a) + α[r + γ max Q(s’,a’) – Q(s,a)]
这个公式看起来简单,但蕴含着深刻的学习机制。它告诉智能体如何根据即时奖励和未来的最大期望价值来调整自己的价值估计。
Deep Q-Networks:深度学习的力量
当状态空间变得非常大时,传统的表格型Q-Learning就不够用了。Deep Q-Networks (DQN)使用深度神经网络来近似Q函数,能够处理高维状态空间,如图像输入。
DQN的成功应用包括在Atari游戏中达到人类水平的表现,这标志着深度强化学习时代的到来。
Policy Gradient:直接学习策略
与价值学习方法不同,策略梯度方法直接学习策略本身。它通过梯度上升来优化策略参数:
∇θ J(θ) = E[∇θ log π(a|s,θ) Q(s,a)]
这种方法的优势在于可以学习随机策略,并且能够处理连续动作空间。
机器人学习走路:从仿真到现实
强化学习在机器人领域的应用令人瞩目。Figure AI的人形机器人通过端到端的神经网络学会了自然的步行。这个过程完全在仿真环境中进行,然后迁移到真实的机器人上。
机器人学习走路的过程就像人类婴儿学步一样,需要无数次的尝试和失败。但与人类不同的是,机器人可以在仿真环境中快速进行大量的尝试,大大缩短了学习时间。
未来的挑战与机遇
强化学习仍然面临许多挑战:
样本效率:当前的强化学习算法通常需要大量的样本才能学到好的策略。如何提高样本效率是一个重要的研究方向。
安全性:在现实应用中,智能体的探索行为可能带来危险。如何在保证安全的前提下进行有效探索是一个关键问题。
泛化能力:如何让智能体学到的策略能够泛化到新的环境和任务中,仍然是一个开放的问题。
解释性:深度强化学习模型往往是黑盒的,如何提高模型的可解释性对于许多应用场景都很重要。
尽管存在这些挑战,强化学习的前景依然光明。从游戏AI到自动驾驶,从机器人控制到资源优化,强化学习正在各个领域展现其强大的潜力。
正如AlphaGo向我们展示的那样,当机器学会了自主学习和决策,它们就能够在复杂的环境中找到人类从未想过的解决方案。这不仅仅是技术的进步,更是对智能本质的深度探索。
在这个AI快速发展的时代,理解强化学习的核心概念不仅有助于我们把握技术发展的脉搏,更能让我们从全新的角度思考学习、决策和智能的本质。毕竟,在某种程度上,我们每个人都是在生活这个复杂环境中不断学习和优化策略的"智能体"。