想象一下,有一个智能体,就像一个初来乍到的孩子,对这个世界一无所知。它只知道要在这个复杂的环境中生存,并且每做一个决定都会得到反馈——有时是甜蜜的奖励,有时是苦涩的惩罚。这就是强化学习的世界,一个让机器通过试错来学习最优策略的奇妙领域。
网页版:https://roytgmnk.gensparkspace.com/
视频版:https://www.youtube.com/watch?v=1mkyN80FS2w
与此同时,在另一个维度里,机器正在学习理解人类最复杂的创造——语言。它们从单词的向量表示开始,逐渐学会识别情感、理解语法,甚至能够进行流畅的对话。这就是自然语言处理的魅力所在,一个让机器具备语言智能的神奇世界。
智能体的奇幻冒险:强化学习基础概念
马尔可夫决策过程:时空中的决策框架
在强化学习的世界里,一切都围绕着一个核心框架展开——马尔可夫决策过程(MDP)。这个框架就像是为智能体提供了一张详细的世界地图,包含了状态空间、动作空间、奖励函数和状态转移概率。

马尔可夫性质保证了"未来只依赖于现在,而不依赖于过去"——这个看似简单的假设为整个强化学习理论奠定了数学基础。在这个框架下,智能体的每一个决策都基于当前状态,而不需要记住之前所有的历史轨迹。
贝尔曼方程:价值的递归之美
贝尔曼方程是强化学习中最优美的数学表达之一。它揭示了一个深刻的道理:当前状态的价值等于即时奖励加上未来状态价值的期望。
V(s) = E[r + γV(s’)]
这个等式背后蕴含着动态规划的智慧——复杂问题可以分解为子问题,而每个子问题的最优解构成了整体的最优解。这种递归结构让我们能够通过迭代的方式逐步逼近最优价值函数。
Q-Learning:无模型学习的突破
当智能体不知道环境的具体模型时,Q-Learning算法提供了一条出路。这个算法的巧妙之处在于它直接学习动作-价值函数Q(s,a),而不需要明确知道状态转移概率。

更新规则简洁而有力:
Q(s,a) ← Q(s,a) + α[r + γ max Q(s’,a’) – Q(s,a)]
这个公式体现了强化学习的精髓——通过经验不断修正对世界的认知,最终找到最优策略。
深度强化学习:神经网络的力量觉醒
深度Q网络:突破维度诅咒
当状态空间变得庞大时,传统的表格方法就显得力不从心了。深度Q网络(DQN)的出现标志着强化学习进入了深度学习时代。
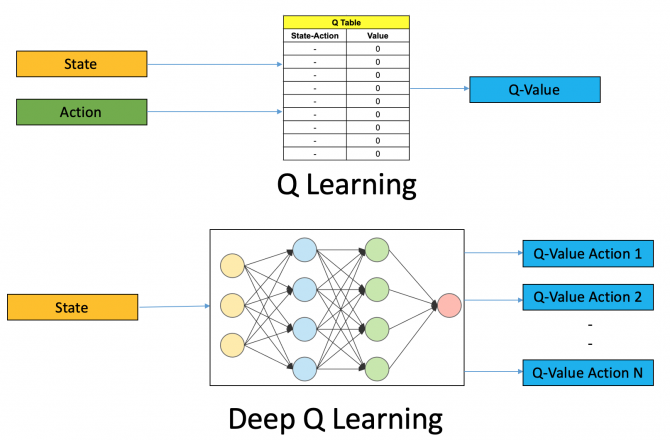
DQN的创新在于用神经网络来近似Q函数,这样就能处理高维的状态空间。经验回放机制让智能体能够从过去的经验中反复学习,而目标网络的设计则保证了训练的稳定性。这些技术的结合让DQN在Atari游戏上取得了超越人类的表现,开启了深度强化学习的黄金时代。
策略梯度方法:直接优化的艺术
与基于价值的方法不同,策略梯度方法采用了更直接的路径——直接优化策略函数。这种方法特别适合处理连续动作空间的问题。
REINFORCE算法是策略梯度家族的经典代表,它通过蒙特卡洛方法估计策略梯度:
∇θ J(θ) = E[∇θ log π(a|s) A(s,a)]
这个优雅的公式告诉我们:如果某个动作带来了正向的优势,就增加该动作的概率;如果带来了负向的优势,就减少该动作的概率。
Actor-Critic方法:最佳拍档的协作
Actor-Critic方法结合了策略梯度和价值函数的优势。Actor负责选择动作,Critic负责评估动作的好坏,两者相互配合,共同提升学习效率。
这种设计的巧妙之处在于利用了bootstrap的思想——用当前的价值函数估计来指导策略的更新,从而减少了方差,提高了学习速度。
多智能体强化学习:群体智慧的涌现
当多个智能体同时在环境中学习和交互时,情况变得更加复杂和有趣。多智能体强化学习(MARL)研究如何在这种动态博弈环境中找到均衡策略。
每个智能体不仅要适应环境,还要适应其他智能体的策略变化。这种相互适应的过程可能导致复杂的动态行为,有时甚至会出现涌现的集体智慧。
语言的魔法:自然语言处理的奇妙世界
文本分类:机器的理解之旅
文本分类是自然语言处理最基础也是最重要的任务之一。从简单的垃圾邮件过滤到复杂的情感分析,机器正在学习理解文本背后的含义。
在这个过程中,机器需要处理语言的歧义性、上下文依赖性和语义的多层次性。每一篇文档都是一个多维的语义空间中的点,而分类的任务就是找到合适的决策边界来区分不同的类别。
命名实体识别:从文本中提取知识
命名实体识别(NER)就像是给文本做"实体标注"的工作。机器需要从连续的文本流中识别出人名、地名、机构名等具有特定语义的片段。
这项任务的挑战在于实体的边界识别和类型判断。同一个词在不同的上下文中可能代表不同类型的实体,这要求模型具备强大的上下文理解能力。
词嵌入:将语言映射到几何空间
词嵌入技术将自然语言处理推向了一个新的高度。Word2Vec、GloVe和FastText等方法将词汇映射到连续的向量空间中,使得语义相近的词在几何空间中也相互接近。
这种映射的奇妙之处在于它捕捉到了语言的线性结构:king – man + woman ≈ queen。这个简单的向量运算蕴含着深刻的语义关系,展现了分布式表示的强大表达能力。
序列建模的革命:从RNN到Transformer
循环神经网络:记忆的力量
RNN、LSTM和GRU等循环神经网络架构为序列建模奠定了基础。这些网络通过隐状态来维护对历史信息的记忆,使得模型能够处理可变长度的序列。
LSTM通过门控机制解决了传统RNN的梯度消失问题,而GRU则提供了更简洁但同样有效的设计。这些创新让机器第一次具备了处理长序列的能力。
Transformer:注意力革命
Transformer架构的出现彻底改变了自然语言处理的格局。"Attention is All You Need"这篇论文的标题道出了其核心思想——抛弃循环结构,完全基于注意力机制来建模序列关系。
多头注意力机制让模型能够同时关注序列中的多个位置,而位置编码则补充了模型对位置信息的感知能力。这种设计不仅提高了建模能力,还使得计算可以高度并行化。
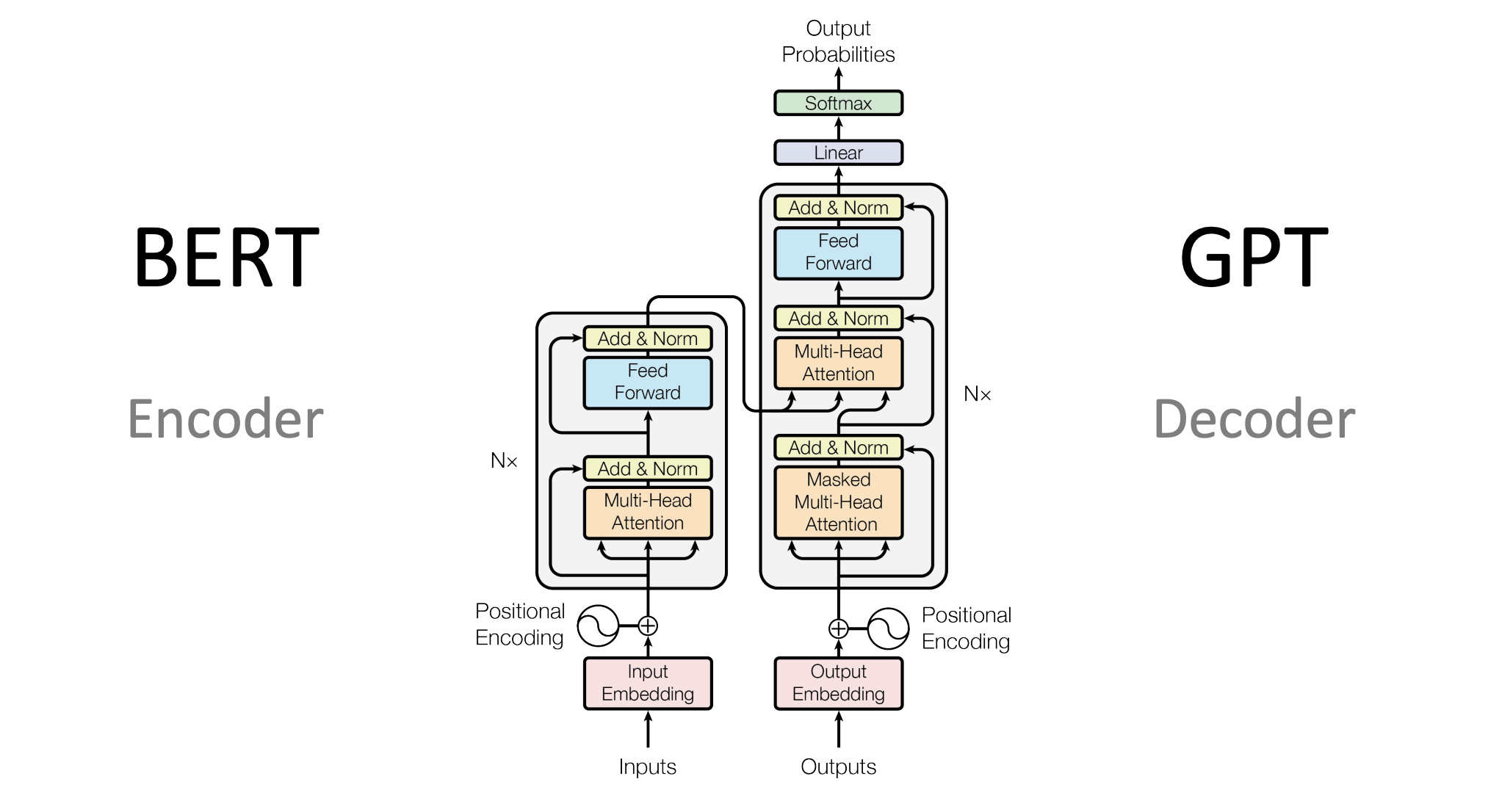
BERT:双向编码的突破
BERT采用了双向编码的设计,通过掩码语言模型的预训练任务让模型同时利用左右两侧的上下文信息。这种设计让BERT在理解任务上表现出色,特别适合需要深度语义理解的场景。
BERT的预训练-微调范式也开创了新的训练模式:在大规模无标注数据上预训练通用的语言表示,然后在具体任务上进行微调。这种方式大大降低了下游任务的数据需求。
GPT:生成式建模的力量
与BERT不同,GPT系列模型采用了单向的自回归建模方式。通过预测下一个词的任务,GPT学会了强大的文本生成能力。
GPT的成功证明了一个重要的观点:足够大的模型在足够多的数据上训练,能够涌现出令人惊讶的能力。从GPT-1到GPT-3再到最新的大语言模型,我们见证了规模定律的神奇力量。
序列到序列学习:机器翻译的艺术
Seq2Seq模型的基本架构
序列到序列(Seq2Seq)模型为机器翻译和对话生成等任务提供了统一的框架。编码器将输入序列编码为固定长度的向量表示,解码器则从这个表示中生成目标序列。
这种编码器-解码器的架构优雅地解决了变长序列到变长序列的映射问题。然而,固定长度的中间表示成为了信息的瓶颈,限制了模型处理长序列的能力。
注意力机制:突破信息瓶颈
注意力机制的引入解决了Seq2Seq模型的信息瓶颈问题。解码器不再只依赖于固定的上下文向量,而是可以动态地关注编码器的所有隐状态。
这种机制让模型能够在生成每个词时自适应地选择相关的输入信息,大大提高了长序列建模的效果。注意力权重的可视化也为模型的决策过程提供了很好的可解释性。
实践应用:理论到现实的桥梁
PyTorch与TensorFlow实现
在实际应用中,PyTorch和TensorFlow为我们提供了强大的深度学习框架。这些框架不仅提供了丰富的神经网络组件,还包含了高效的自动微分系统和分布式训练支持。
从简单的多层感知机到复杂的Transformer架构,这些框架让研究者和工程师能够快速实现和验证自己的想法。自动微分让我们从繁琐的梯度计算中解脱出来,专注于模型设计和算法创新。
真实场景的挑战
将理论转化为实际应用并不是一帆风顺的过程。数据的噪声和偏差、模型的泛化能力、计算资源的限制——这些都是需要在实践中不断解决的问题。
在强化学习中,环境的复杂性和奖励函数的设计往往决定了算法的成败。而在自然语言处理中,语言的多样性和上下文的复杂性则考验着模型的理解能力。
前沿发展:未来的可能性
多模态学习的融合
未来的AI系统将不再局限于单一模态的数据,而是能够同时处理文本、图像、音频等多种信息。这种多模态学习能力将让机器更好地理解和交互于现实世界。
持续学习与元学习
如何让AI系统能够持续学习新知识而不遗忘旧知识,如何让模型能够快速适应新任务——这些都是当前研究的热点问题。元学习的理念为解决这些问题提供了新的思路。
可解释性与安全性
随着AI系统变得越来越强大,我们也需要更好地理解和控制这些系统。可解释性研究试图打开"黑箱",让我们理解模型的决策过程;而AI安全研究则关注如何确保AI系统的可靠性和安全性。
在这个人工智能快速发展的时代,强化学习和自然语言处理正在重塑我们对智能的理解。从智能体的试错学习到语言模型的涌现能力,从简单的分类任务到复杂的多模态理解——每一个突破都在推动着我们向通用人工智能的目标迈进。
这不仅仅是技术的演进,更是人类智慧的延伸和放大。在这个充满可能性的未来里,我们有理由相信,机器将成为人类最好的伙伴,共同探索这个宇宙的奥秘。