想象一下,如果告诉1950年代的科学家们,有一天机器能够像人类一样识别图片、理解语言、甚至创作文章,他们会怎么想?这听起来就像是科幻小说里的情节。但是,这个看似不可能的梦想,却在短短几十年间变成了现实。这个故事的主角,就是深度学习。
网页版:https://fzppunnu.gensparkspace.com
视频版:https://www.youtube.com/watch?v=7ZdUCrwYlnY
音频版:https://notebooklm.google.com/notebook/45435836-3261-4af5-a6ec-6d3c4b177b2f/audio
一切从一个简单的想法开始
故事要从1943年说起。那时候,计算机还没有诞生,但有两位神经生理学家McCulloch和数学家Pitts却在思考一个有趣的问题:能不能用数学来模拟大脑神经元的工作方式?他们提出了第一个人工神经元模型,就像是在黑暗中点亮的第一根火柴。
这个简单的数学模型包含了几个基本元素:接收输入信号,对信号进行加权处理,然后决定是否"激发"输出。听起来很简单,但这个想法却埋下了人工智能革命的种子。
1957年,康奈尔大学的心理学家Frank Rosenblatt把这个想法向前推进了一大步。他发明了"感知机"(Perceptron),这是第一个能够学习的神经网络。Rosenblatt甚至预言,感知机将来能够"走路、说话、看东西、写字、自我复制,并且意识到自己的存在"。
但现实往往比梦想更复杂。1969年,MIT的数学家Marvin Minsky和Seymour Papert在他们的著作中指出了感知机的局限性——它只能解决线性可分的问题。这就像是给这个刚刚萌芽的领域泼了一盆冷水,AI研究进入了第一个"寒冬"。
多层的魔力:突破线性的枷锁
幸运的是,科学家们并没有放弃。1980年代,多层感知机(MLP)的出现打破了僵局。通过在输入层和输出层之间添加"隐藏层",神经网络获得了处理非线性问题的能力。这就像是给一个只会直线思考的人突然开启了立体思维。
但是,多层网络带来了新的挑战:如何训练这些复杂的网络?答案来自一个看似简单但实际上非常巧妙的算法——反向传播(Backpropagation)。
反向传播:让机器"反思"的艺术
反向传播算法的核心思想其实很像我们人类学习的过程。当我们犯错时,我们会反思:"哪一步出了问题?怎样调整才能做得更好?"反向传播算法让神经网络也能进行这样的"反思"。
算法的工作原理是这样的:首先,网络根据当前的参数做出预测;然后计算预测结果与真实答案之间的差距(这叫做"损失");接着,算法会从输出层开始,一层一层地往回计算每个参数对最终错误的"贡献";最后,根据这些"贡献"来调整参数,让网络在下次遇到类似问题时能够做得更好。
这个过程就像是在一个巨大的山地中寻找最低点。每次调整参数,就是朝着山谷的方向迈出一小步。虽然单步很小,但经过成千上万次的调整,网络最终能够找到一个相对较好的解决方案。
深度学习的三大"助推器"
尽管有了反向传播算法,神经网络在很长一段时间内仍然没有展现出惊人的能力。直到2010年代,三个关键因素的汇聚才引发了深度学习的真正革命。
大数据:喂饱"饥饿"的算法
传统的机器学习算法在数据量较小时表现不错,但深度神经网络就像是一个永远吃不饱的"大胃王"。它们需要海量的数据才能发挥真正的威力。
2010年,ImageNet数据集的出现改变了一切。这个包含超过1400万张标注图片的数据集,为计算机视觉研究提供了前所未有的"食物"。正如ImageNet的创始人李飞飞教授所说:"在人工智能的食物链中,数据是阳光。"
GPU:意外的"加速器"
第二个关键因素来自一个意想不到的地方——游戏显卡。GPU(图形处理单元)原本是为了渲染游戏图形而设计的,但研究人员发现,GPU的并行计算能力正好适合深度学习的矩阵运算。
这就像是发现锤子不仅能敲钉子,还能用来雕刻艺术品。NVIDIA公司的CUDA平台让研究人员能够轻松地利用GPU进行深度学习计算,训练速度提升了几十倍甚至上百倍。
算法创新:小改进,大影响
第三个因素是看似微小但影响巨大的算法创新。其中最重要的是ReLU(修正线性单元)激活函数的广泛应用。
传统的激活函数如sigmoid和tanh在网络较深时会出现"梯度消失"问题,就像信号在长距离传输中逐渐减弱。而ReLU函数简单到让人惊讶:f(x) = max(0, x),但这个简单的函数却有效地解决了梯度消失问题,让网络能够训练得更深、更快。
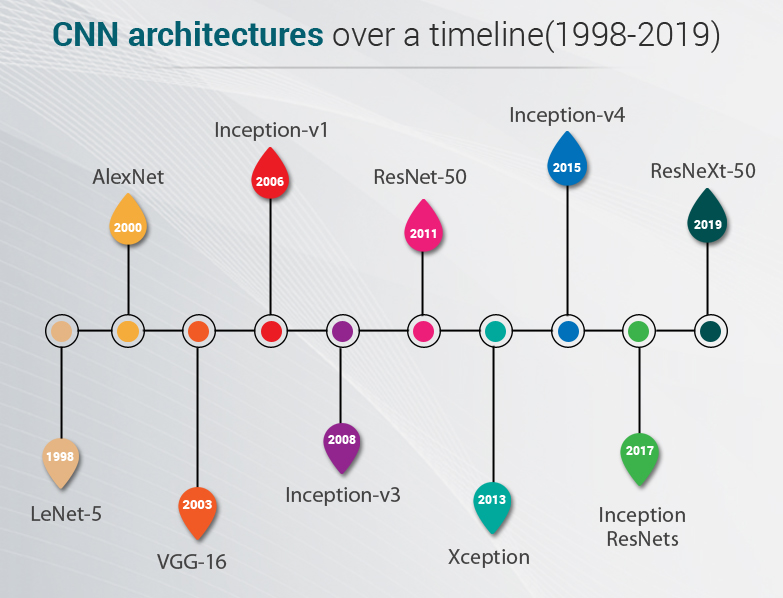
2012年:深度学习的"成人礼"
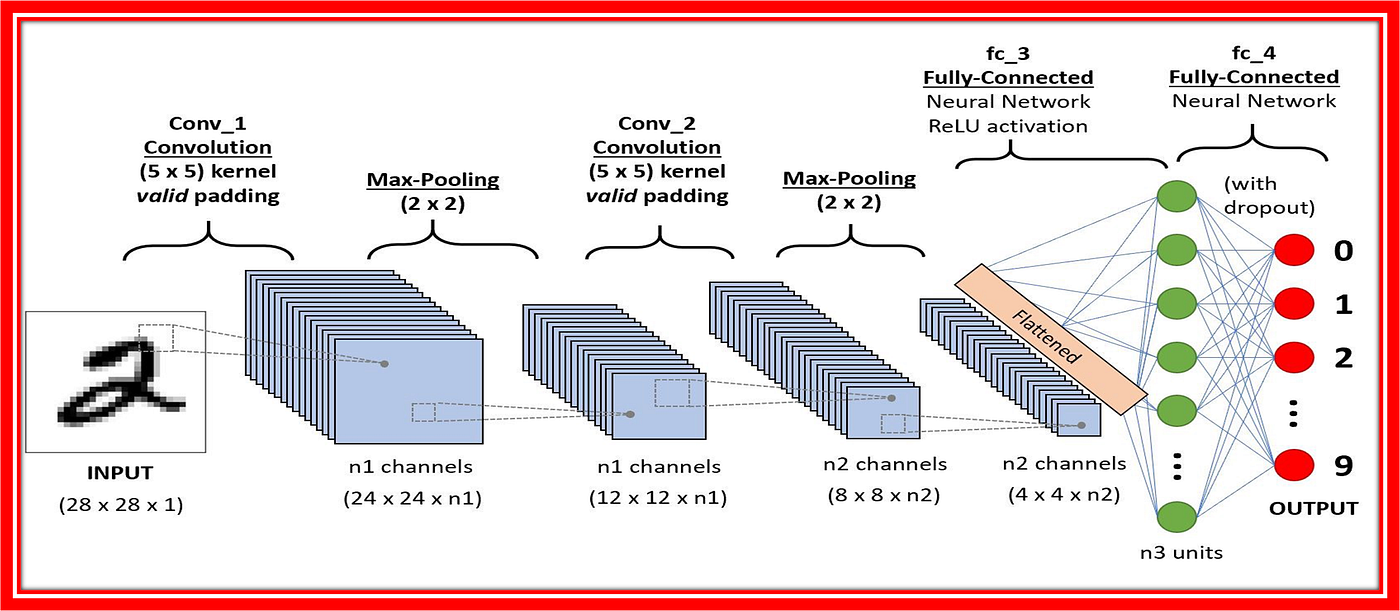
所有这些因素在2012年汇聚在一起,创造了深度学习历史上最重要的时刻之一。在ImageNet大规模视觉识别挑战赛(ILSVRC)上,Geoffrey Hinton的学生Alex Krizhevsky带来了一个名为AlexNet的卷积神经网络。

AlexNet的表现让所有人震惊。它的错误率比第二名低了10个百分点以上,这在机器学习竞赛中是一个巨大的差距。更重要的是,AlexNet证明了深度学习不是实验室里的玩具,而是能够解决实际问题的强大工具。
根据原始论文,AlexNet包含了几个关键创新:使用ReLU激活函数、采用Dropout防止过拟合、利用GPU并行训练、以及数据增强技术。这些创新看似简单,但它们的组合产生了1+1>2的效果。
模型演进:站在巨人的肩膀上
AlexNet的成功打开了深度学习研究的闸门。接下来的几年里,研究人员不断推出更强大的模型,每一个都在前人的基础上更进一步。
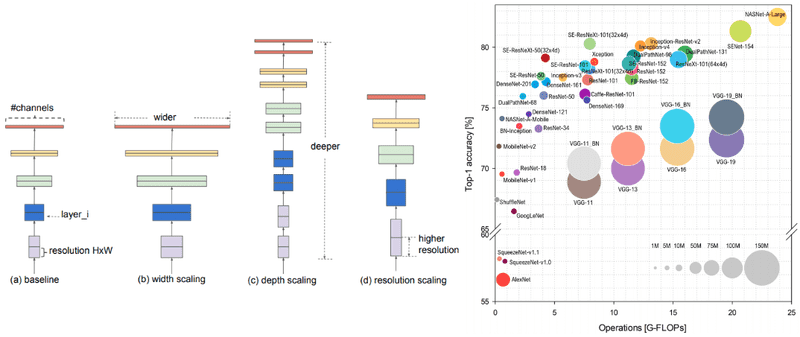
VGG:更深就是更好?
2014年,牛津大学的Visual Geometry Group(VGG)团队提出了VGG网络。他们的理念很简单:既然深度有用,那就让网络更深一些。VGG-16和VGG-19分别有16层和19层,比AlexNet的8层深了不少。
VGG的另一个贡献是证明了使用较小的卷积核(3×3)能够取得更好的效果。这就像是用小画笔能够画出更精细的画作。
ResNet:解决"深度"的烦恼
但是,当网络越来越深时,一个意想不到的问题出现了:性能开始下降。这不是因为过拟合,而是因为深层网络难以训练。微软研究院的何恺明团队在2015年提出了一个巧妙的解决方案——残差网络(ResNet)。
ResNet的核心想法是"跳跃连接"(skip connection)。与其让每一层都从零开始学习,不如让它们学习在原有基础上的"改进"。这就像是爬楼梯时有扶手一样,让信息能够更容易地在深层网络中传播。
这个简单的想法产生了惊人的效果。ResNet能够训练超过1000层的网络,而且性能随着深度的增加而持续提升。
Transformer:注意力的力量
2017年,谷歌的研究团队发表了一篇题为"Attention Is All You Need"的论文,提出了Transformer架构。这个模型最初是为自然语言处理设计的,但它的影响远远超出了这个领域。
Transformer的核心是"自注意力机制"(self-attention)。这个机制让模型能够同时关注输入序列中的所有位置,就像是一个能够同时看到全局和细节的"全景相机"。
更重要的是,Transformer的并行性让它能够更好地利用现代GPU的计算能力。这为后来的大语言模型如GPT系列和BERT奠定了基础。
迁移学习:站在巨人的肩膀上
随着这些强大模型的出现,研究人员发现了一个有趣的现象:在大数据集上训练的模型学到的特征,可以被"转移"到其他相关任务上。这就是迁移学习的思想。
想象一下,一个学会了识别各种动物的模型,已经掌握了识别毛发、眼睛、爪子等基本特征。当我们想让它识别一种新的动物时,不需要从零开始,只需要在它已有的知识基础上进行"微调"就可以了。
这个发现具有革命性的意义。它意味着即使是资源有限的研究团队,也能够利用大公司训练的预训练模型来解决自己的问题。这极大地民主化了AI技术的应用。
涌现能力:意外的"智慧火花"
但深度学习最神秘的现象可能是"涌现能力"(emergent abilities)。当模型规模达到某个临界点时,它们会突然展现出一些训练时并未明确教授的能力。
比如,当语言模型足够大时,它们会突然学会进行数学推理、代码编程,甚至是创意写作。这些能力的出现往往是突然的、不可预测的,就像是在某个临界点上突然"开窍"了。
这个现象让研究人员既兴奋又困惑。为什么会出现涌现能力?它们是真正的"智能"表现,还是复杂计算的副产品?这些问题至今仍然没有完全的答案。
从实验室到改变世界
深度学习的故事还在继续书写。从2012年AlexNet的突破,到2022年ChatGPT引发的AI热潮,这项技术已经从实验室走进了我们的日常生活。
今天,深度学习技术在图像识别、语音处理、自然语言理解、自动驾驶、医疗诊断等领域都有着广泛的应用。每一次技术突破,都在推动着人类社会向前发展。
未来:下一个突破在哪里?
回顾深度学习的发展历程,我们可以看到技术进步往往来自于意想不到的地方。谁能想到游戏显卡会成为AI革命的催化剂?谁能预料到一个简单的ReLU函数会带来如此巨大的影响?
正如ImageNet竞赛的历史告诉我们的,每一个看似微小的改进,都可能是下一个重大突破的种子。也许下一个改变世界的AI技术,正在某个研究生的实验室里萌芽。
深度学习的故事教会了我们一个重要的道理:科学的进步往往不是一蹴而就的,而是在无数次尝试、失败和改进中逐步实现的。每一个参与其中的研究者,都在为人类智能的延伸贡献着自己的力量。
这个故事还远未结束。在未来的某一天,当我们回望今天的AI技术时,也许会发现,我们现在认为最先进的模型,只不过是通往真正人工智能道路上的一个小小里程碑。但正是这些看似微小的进步,构成了人类探索智能奥秘的宏伟篇章。