在人工智能快速发展的今天,我们面临着一个有趣的悖论:AI系统变得越来越聪明,但我们却越来越不理解它们是如何工作的。就像那个著名的笑话说的,"我的神经网络能识别猫,但我不知道它是怎么做到的,甚至连它自己也不知道。"
网页版:https://www.genspark.ai/api/page_private?id=hknqngpn
视频版:https://www.youtube.com/watch?v=Ar_QlW2-FEs
这种情况在2016年达到了一个转折点。当时,一家知名科技公司的AI招聘系统被发现存在性别偏见,会自动降低包含"女性"相关词汇简历的评分。这个事件就像一记警钟,让整个AI界意识到,我们不能再对这些"黑盒"视而不见了。
为什么我们需要"透明"的AI
想象一下,你去看医生,医生告诉你需要做手术,但当你问"为什么"时,他只是神秘地说:"相信我,我是专业的。"你会怎么想?同样的道理,当AI系统在做关乎我们生活的重要决策时——比如决定是否批准贷款、诊断疾病或者控制自动驾驶汽车——我们有权知道这些决策是基于什么做出的。

模型可解释性不仅仅是一个技术问题,更是关乎信任、公平和责任的社会问题。IBM的研究表明,缺乏透明度是阻碍AI技术在关键领域应用的主要障碍之一。
LIME:AI的"局部翻译官"
LIME(Local Interpretable Model-agnostic Explanations)就像是给AI模型配备了一个贴身翻译。它不试图解释整个模型(那太复杂了),而是专注于解释特定预测的原因。
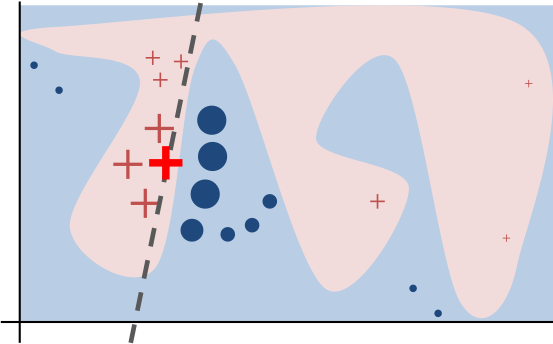
LIME的工作方式非常巧妙。假设你在一座复杂的山地中迷路了,虽然整个地形千变万化,但在你当前位置的小范围内,地形可以用一个简单的斜坡来描述。LIME正是采用了这种"局部线性化"的思路。
具体来说,LIME会在需要解释的样本周围生成很多"邻居"样本,观察模型对这些邻居的预测结果,然后用一个简单的线性模型来拟合这个局部区域的行为。就像马尔科·里贝罗在原始论文中描述的那样,这种方法让我们能够用人类能理解的简单规则来解释复杂模型的局部行为。
LIME在图像分类中的应用

在图像分类任务中,LIME会将图像分割成超像素块,然后通过遮挡不同的区域来观察模型预测的变化。这就像是玩"猜猜我遮住了什么"的游戏,通过遮挡不同部分来发现哪些区域对预测最重要。
比如,当解释一个猫咪分类器时,LIME可能会发现模型主要关注猫的眼睛和耳朵,而背景中的沙发对预测几乎没有影响。这种直观的可视化让普通用户也能理解模型的"思路"。
SHAP:基于博弈论的公平分配
如果说LIME是局部的"显微镜",那么SHAP(SHapley Additive exPlanations)就是全局的"望远镜"。SHAP基于诺贝尔经济学奖得主劳埃德·沙普利的博弈论研究,解决的是一个本质问题:在多人合作的游戏中,如何公平地分配收益?
在机器学习的语境下,我们可以把每个特征想象成一个"玩家",而模型的预测结果就是所有"玩家"合作产生的"收益"。SHAP要回答的问题是:每个特征对最终预测到底贡献了多少?
SHAP的数学优雅性
SHAP的数学基础确保了一个重要性质:分配给各特征的重要性分数之和等于模型预测值与基线预测值的差。这种可加性让SHAP解释具有良好的一致性和完整性,就像一个完美的会计系统,每一分钱都能对账。

瀑布图是SHAP最受欢迎的可视化方式之一。它从基线预测开始,逐步添加每个特征的贡献,最终到达实际预测值。就像搭积木一样,每个特征都是一块积木,有些向上推(正贡献),有些向下拉(负贡献),最终构成了完整的预测结果。
特征重要性的视觉盛宴
特征重要性分析就像是为AI模型的"大脑"绘制思维导图。通过各种精美的可视化技术,我们可以将抽象的数值转化为直观易懂的图表。
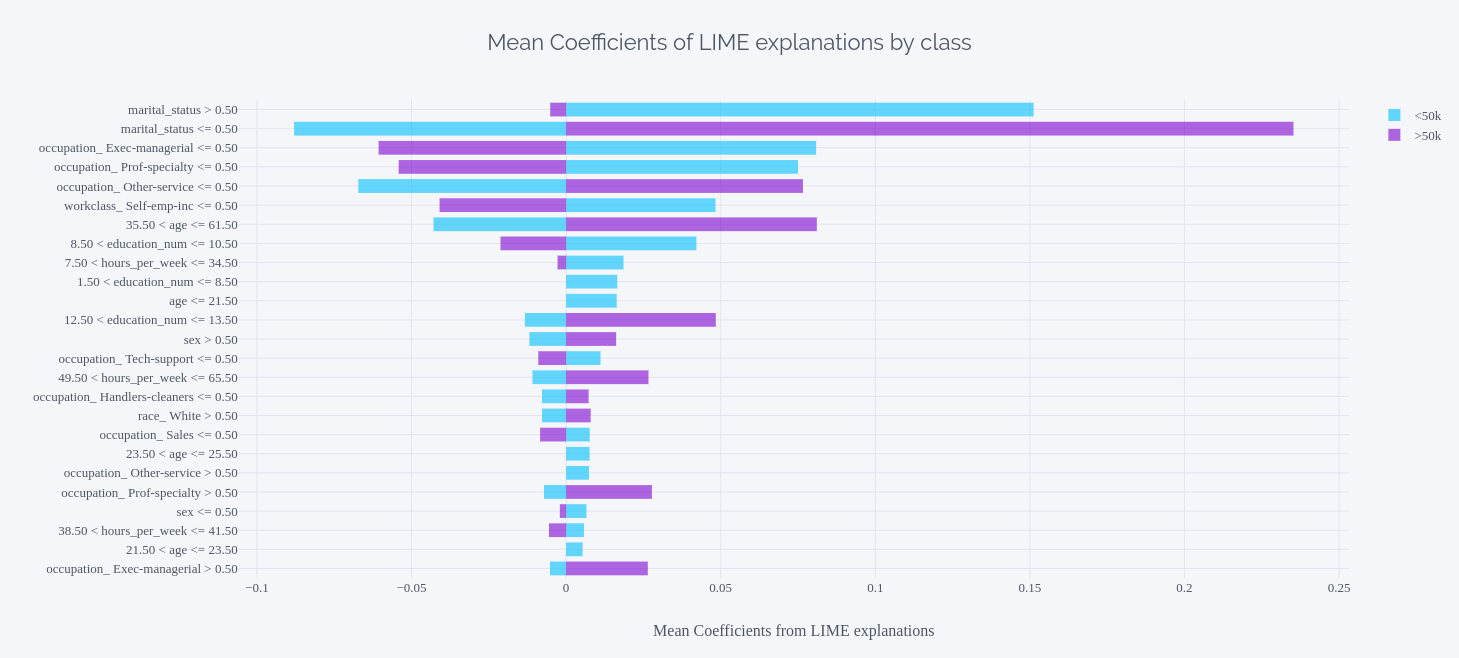
小提琴图是另一种优雅的可视化方式,它不仅显示了每个特征的重要性排序,还揭示了特征值与SHAP值之间的复杂关系。通过观察小提琴图的形状分布,我们可以发现特征是如何以非线性方式影响预测的。
深度学习中的特征可视化

对于深度学习模型,特征可视化技术能够帮助我们理解卷积神经网络学到了什么样的"眼睛"。通过优化输入图像来最大化特定神经元的激活,我们可以生成该神经元"最喜欢看到"的图案。
这些可视化结果常常令人惊叹。低层神经元可能学会了检测简单的边缘和纹理,而高层神经元则能识别复杂的物体部件,甚至完整的物体。这种层次化的特征学习过程揭示了深度学习模型的内在工作机制。
优化算法:AI训练的"导航系统"
如果说模型架构是AI的"身体",那么优化算法就是训练过程中的"大脑"。它们决定了模型如何从随机的参数逐渐学习到有用的知识。
SGD:稳重的老将
随机梯度下降(SGD)是优化算法中的"元老级"人物。虽然它看起来简单——每次只根据当前的梯度方向前进一步——但这种简单性也是它的力量所在。
SGD就像一个谨慎的登山者,严格按照当前位置的坡度指示选择前进方向。虽然可能会在路上遇到一些波折,但最终往往能找到真正的山顶。
Momentum:有记忆的探险者
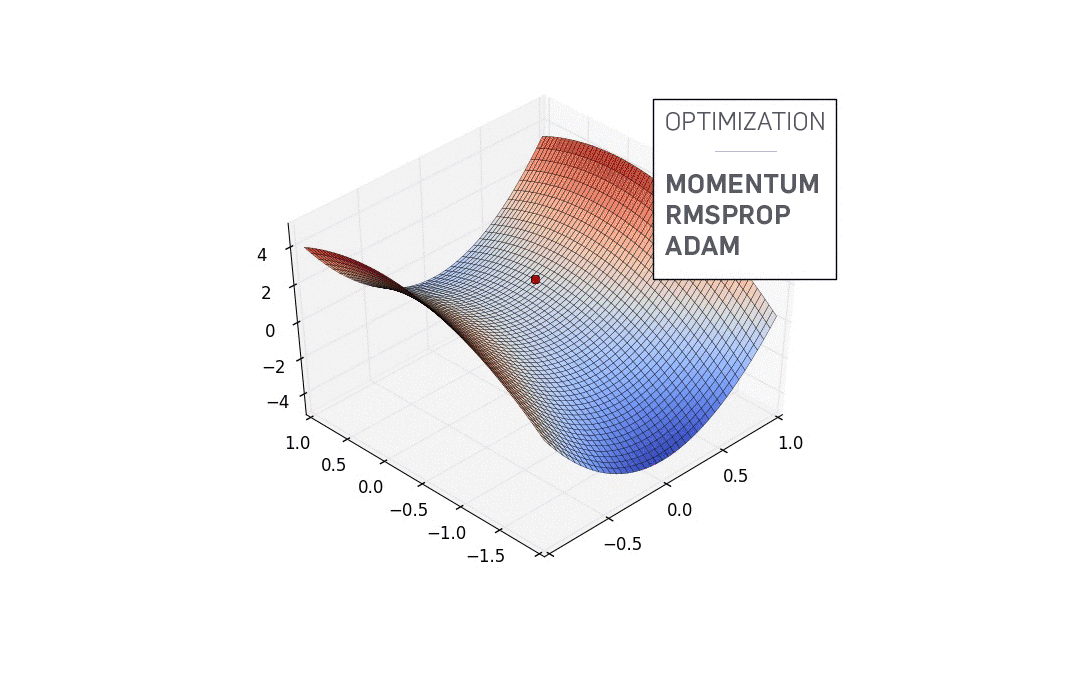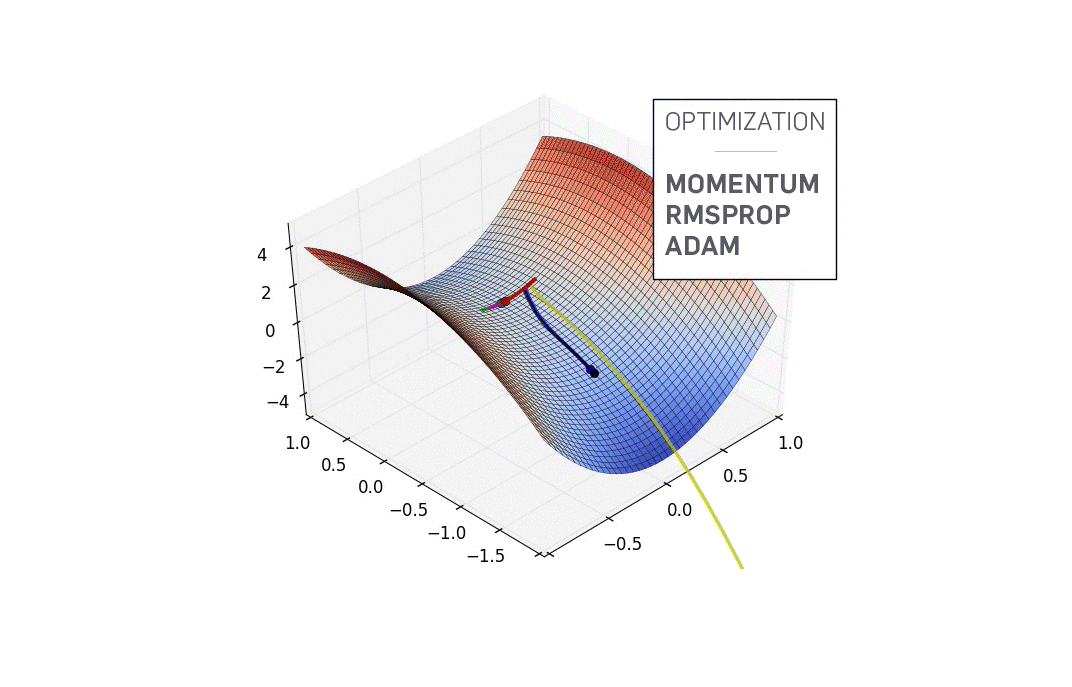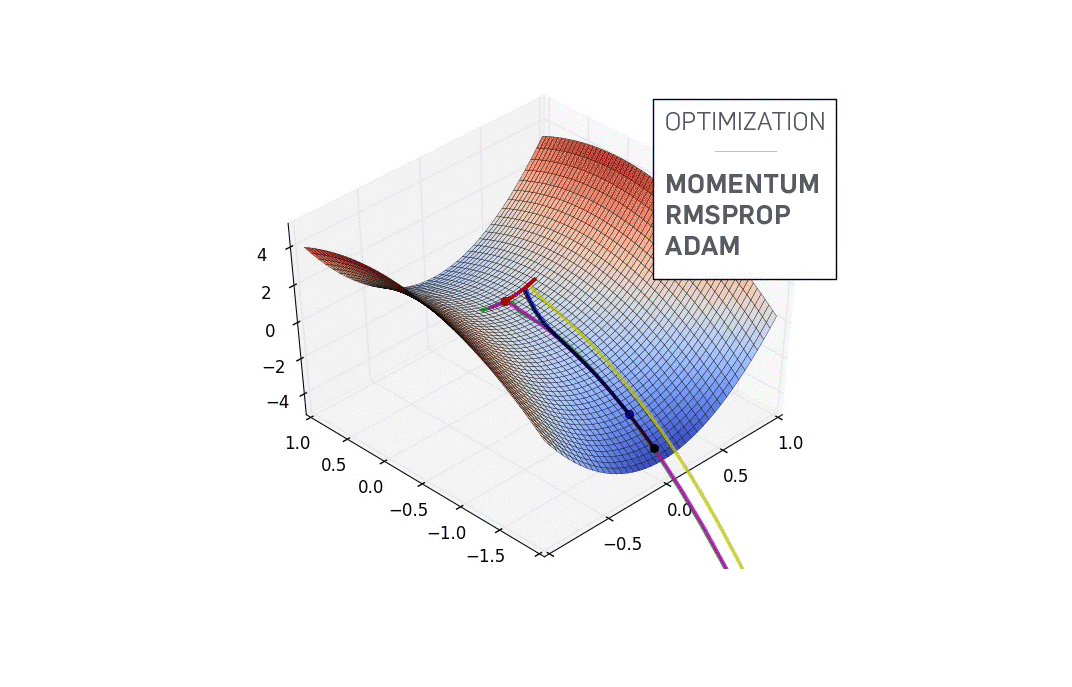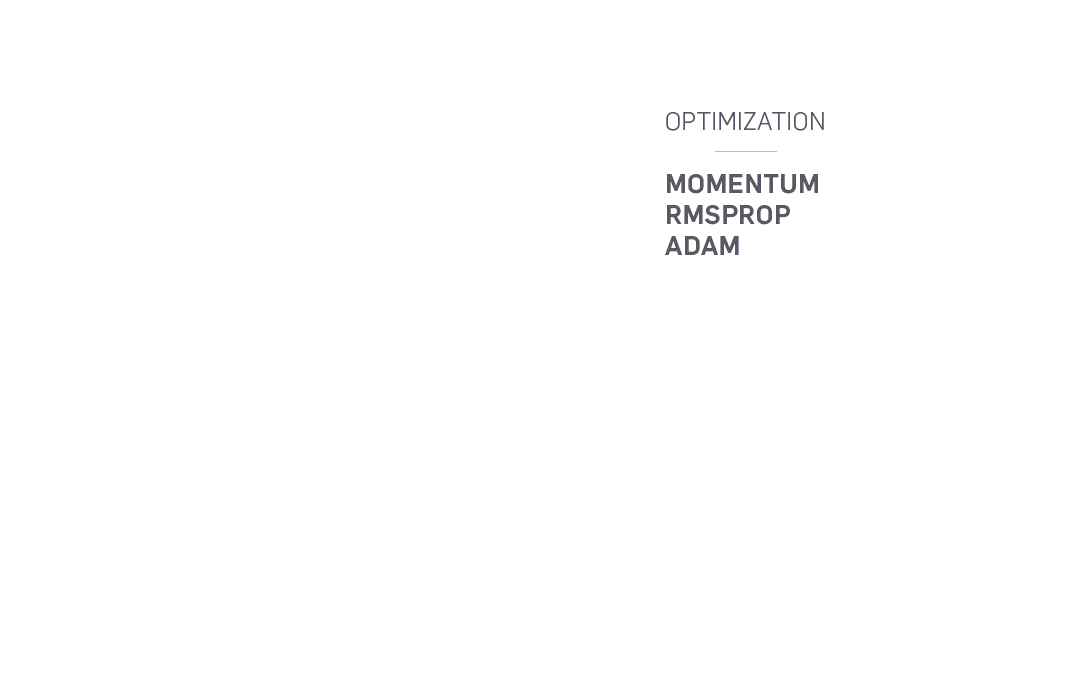
SGD配合动量(Momentum)的组合就像给登山者配备了"记忆"。普通的SGD每次都是"失忆"的,完全不记得之前走过的路。而加入动量后,算法会记住之前的移动方向,在遇到噪声或小障碍时能够保持前进的惯性。
这种"惯性"特别有用,尤其是在面对狭长山谷地形时。想象你在一个U型峡谷中寻找出路,普通SGD会在两侧峭壁间来回震荡,而带动量的SGD则能保持沿着谷底前进的方向。
Adam:智能的全能选手
Adam(Adaptive Moment Estimation)可以说是深度学习优化算法中的"瑞士军刀"。它巧妙地结合了动量和自适应学习率的优势,既有"记忆"能力,又具备"自适应"特性。

Adam维护了两个移动平均:一阶矩估计(梯度的移动平均)和二阶矩估计(梯度平方的移动平均)。通过这两个"顾问",Adam能够为每个参数量身定制学习率,在不同的训练阶段和不同的参数维度上都能保持优秀表现。
AdamW:修正的完美主义者
虽然Adam很强大,但研究者们发现它在某些任务上的泛化性能不如传统的SGD+Momentum。这就像一个学霸在考试中表现优异,但在实际应用中却不如那些基础扎实的学生。
AdamW的关键创新在于将权重衰减(Weight Decay)从梯度更新中解耦出来。这种看似微小的改变就像给汽车调整了悬挂系统,虽然改动不大,但驾驶体验却有了质的提升。
学习率调度:掌握训练的节奏

如果说优化算法决定了"怎么走",那么学习率调度就决定了"走多快"。这就像驾驶汽车一样,在高速公路上可以开得快一些,在繁忙的市区就需要慢慢行驶。
余弦退火:优雅的波浪
余弦退火(Cosine Annealing)是近年来最受欢迎的学习率调度策略。它的曲线就像一个优雅的海浪,学习率从初始值开始,按照余弦函数的形状平滑地下降。
这种调度方式的美妙之处在于它的平衡性:训练初期保持相对较高的学习率来快速收敛,后期逐渐减小学习率来精细调整。就像一首音乐的节拍,开始时激昂有力,随后逐渐舒缓。
Warmup:训练前的热身
Warmup技术就像运动员在比赛前的热身运动。神经网络在训练初期的参数是随机初始化的,如果一开始就用很大的学习率,就像让一个刚睡醒的人立即进行剧烈运动,很容易"拉伤"。
Warmup阶段会从一个很小的学习率开始,线性增长到目标学习率。这个过程让模型有时间逐渐"苏醒",避免训练初期的剧烈震荡。
3D损失地形:训练过程的壮丽景观

想象一下,如果我们能够将高维的损失函数投影到三维空间中,会看到怎样的景象?损失地形可视化技术让这个科幻般的想象变成了现实。
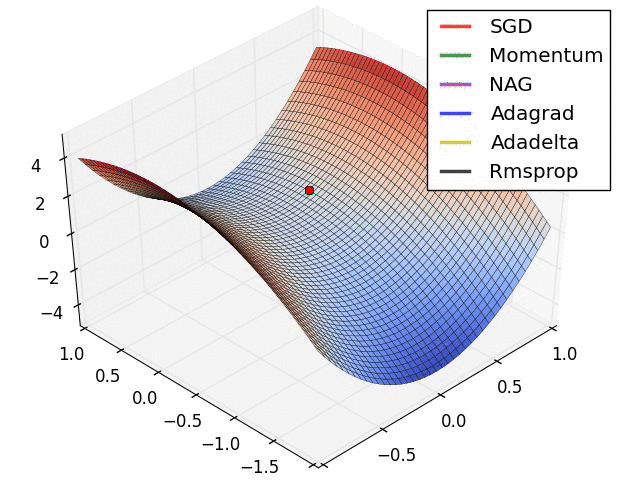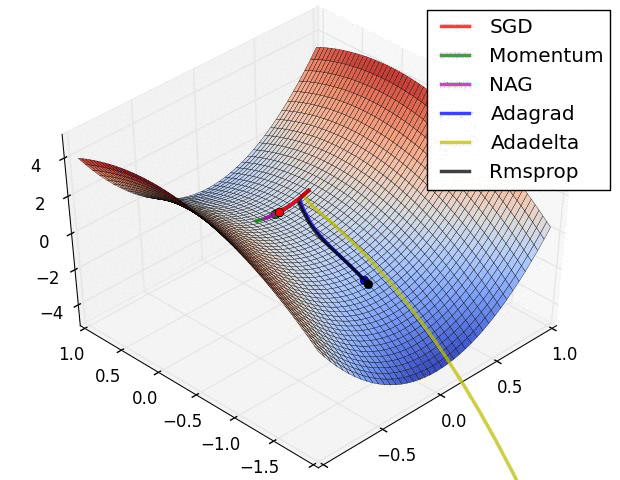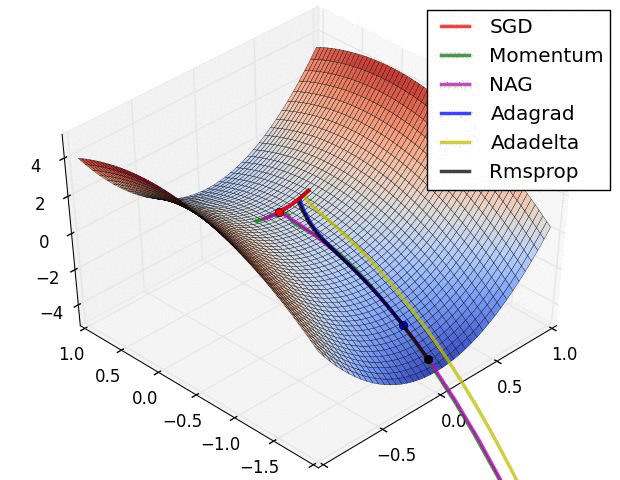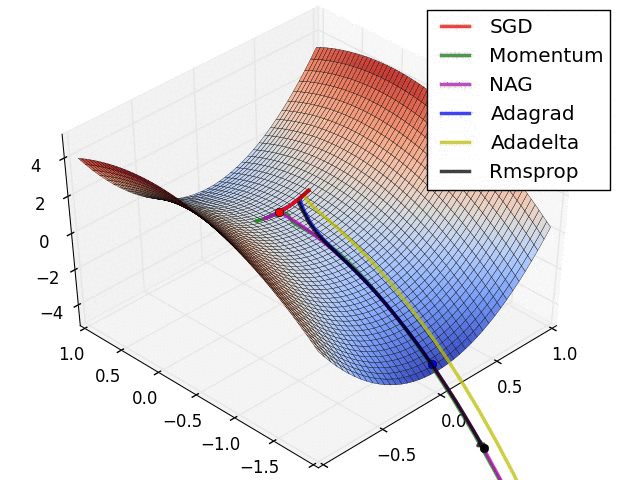
在这些3D可视化中,我们可以看到不同优化算法在复杂地形上的"冒险之旅"。深蓝色代表低损失(好的解),而山峰则代表高损失(差的解)。每种优化算法就像不同性格的探险者,在这片奇异的地形中寻找最深的谷底。
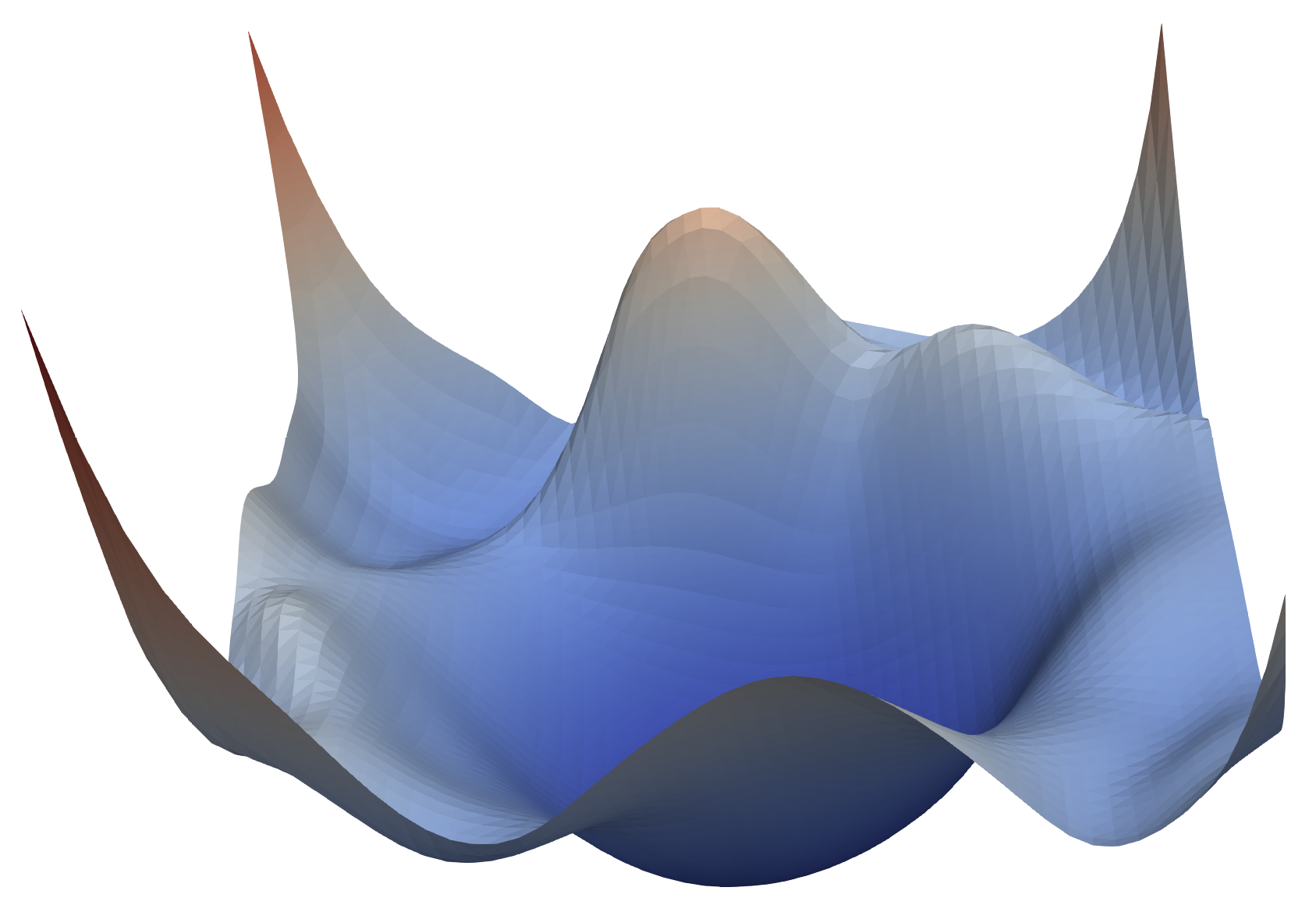
SGD就像一个经验丰富但有些固执的向导,严格按照当前坡度指示前进,有时会在狭长山谷中来回摇摆。Adam则像一个装备精良的现代探险家,能够记住之前的路径,在遇到鞍点时展现出更强的逃逸能力。
这些可视化揭示了一个深刻的洞察:不同的优化算法往往会找到不同的局部最优解。更有趣的是,这些不同的解在泛化能力上可能存在显著差异。
CIFAR-10实战:理论与现实的碰撞
让我们通过CIFAR-10这个经典数据集来看看理论如何在现实中发挥作用。CIFAR-10包含10个类别的32×32彩色图像,是深度学习领域的"果蝇"——小巧但足够复杂,适合做各种实验。

在CIFAR-10的实验中,我们看到了一个有趣的现象:在训练的前50个epoch中,Adam通常会取得领先优势,学习曲线像火箭一样快速上升。这让很多初学者误以为Adam就是万能药。
然而,当训练继续到150个epoch时,情况发生了戏剧性的逆转。SGD+Momentum开始展现出它的"后劲",不仅在训练精度上追平了Adam,在测试精度上甚至实现了反超。这就像龟兔赛跑的现代版本——快不一定意味着好。
CNN与Transformer:两个世界的解释挑战
当我们将目光转向更复杂的模型架构时,可解释性面临着全新的挑战。卷积神经网络(CNN)就像一个有序的工厂流水线,每一层都有相对明确的功能分工,从边缘检测到纹理识别,再到物体部件检测,层次分明,容易理解。

但Transformer模型的情况就复杂得多了。注意力机制就像一个复杂的社交网络,每个token都在与其他所有token"交流",信息在多个头之间并行流动,再通过残差连接和层归一化进行融合。这种复杂的交互模式让传统的解释方法显得力不从心。
近年来,研究者们开发了专门针对Transformer的解释技术。注意力可视化虽然直观,但往往只能提供表面信息。更深层的解释需要结合梯度信息、层间激活模式等多种信号。
实践中的智慧选择
在实际项目中,选择合适的解释方法和优化策略就像配置一台精密的机器,每个部件都需要精心调校。
对于需要严格可解释性的场景——比如医疗诊断或金融风控——LIME和SHAP提供的详细解释就像法庭上的证据,每一个预测都需要有充分的理由支撑。这时候,解释的质量比模型的性能更重要。

而在追求模型性能的竞赛或研究场景中,优化算法的选择往往决定了项目的成败。大规模数据集通常更适合SGD+Momentum,因为它的内存需求更低,且在充分训练后往往能获得更好的泛化性能。
对于小规模数据集或需要快速验证想法的原型开发,Adam族算法的快速收敛特性则更有价值。这就像选择交通工具一样:长途旅行选火车,短途通勤选地铁。
未来的无限可能
深度学习的可解释性和优化技术就像两条奔涌的河流,正在汇聚成更强大的洪流。在可解释性方面,因果推理与机器学习的结合正在开辟全新的研究领域。我们不再满足于知道"什么特征是重要的",而是追求理解"为什么这些特征重要"以及"如果改变这些特征会发生什么"。
在优化算法领域,新的研究正在探索如何结合不同算法的优势。AdaBelief试图修正Adam中的偏差问题,SAM(Sharpness-Aware Minimization)则直接优化损失地形的平坦性。这些创新就像给传统汽车安装了更智能的导航系统。
元学习(Meta-Learning)的兴起更是为优化算法带来了革命性的思路。与其为所有任务设计一个通用的优化算法,不如让算法学会根据具体任务自动调整策略。这种"学会学习"的能力可能会彻底改变我们对模型训练的理解。
想象一下,未来的AI系统不仅能够解决问题,还能解释自己的解决过程,甚至能够反思和改进自己的学习方法。这样的系统将真正成为人类的智能伙伴,而不再是神秘的黑盒。
从LIME和SHAP开启的可解释性研究,到SGD与Adam族算法的优化竞赛,每一项技术进步都在推动我们向更透明、更高效的AI系统迈进。在这个激动人心的旅程中,我们既是见证者,也是参与者,共同书写着人工智能发展的新篇章。