
当AI学会"创造"
还记得小时候第一次拿起画笔时的那种兴奋吗?从无到有创造出一幅作品,即使只是简单的线条和色彩。如今,人工智能也在学习这种"创造"的艺术,而生成对抗网络(GAN)正是这场AI创造力革命的核心推动力。
网页版:https://www.genspark.ai/api/page_private?id=ghcpcacs
视频版:https://www.youtube.com/watch?v=EnRvC78KhuA
音频版:https://notebooklm.google.com/notebook/05148826-0974-4de3-9d88-40bbcb2a5d3b/audio
想象一下,在一个充满活力的画室中,有两位艺术家:一位是创作者,不断尝试创造逼真的艺术品;另一位是评论家,试图分辨哪些作品是真实的,哪些是伪造的。随着时间推移,创作者变得越来越擅长"欺骗"评论家,而评论家也变得越来越善于识别真伪。这正是GAN的核心思想——一场创造者和鉴别者之间的智力博弈。
本文将带你深入探索GAN的奇妙世界,从基本结构到高级改进,再到实际代码实现。无论你是AI爱好者、研究人员,还是对生成模型充满好奇的读者,这里都有适合你的内容。让我们一起揭开AI创造力的神秘面纱!
GAN的基本结构:一场精心设计的博弈
生成对抗网络(GAN)由Ian Goodfellow和他的团队在2014年首次提出,这一创新架构包含两个核心组件:生成器(Generator)和判别器(Discriminator)。它们就像一对永恒的对手,在不断的对抗中相互提升。
生成器(Generator):艺术的创造者
生成器的任务是从随机噪声创造出逼真的数据样本。想象一个年轻的艺术家,他从随机的笔触开始,逐渐塑造出一幅精美的作品。
在技术层面,生成器通常是一个深度神经网络,接收随机向量z作为输入(通常是从标准正态分布中采样),然后通过一系列变换将其映射到数据空间。例如,在图像生成任务中,生成器会将随机向量转换为具有正确维度和通道数的图像。
class Generator(nn.Module):
def __init__(self, latent_dim, img_shape):
super(Generator, self).__init__()
self.img_shape = img_shape
# 定义神经网络层
self.model = nn.Sequential(
nn.Linear(latent_dim, 128),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(128, 256),
nn.BatchNorm1d(256, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 512),
nn.BatchNorm1d(512, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), *self.img_shape)
return img
判别器(Discriminator):艺术的鉴赏家
判别器则扮演着艺术评论家的角色,它试图区分真实数据和生成器创造的"假"数据。这是一个二元分类问题:判别器的输出是一个概率值,表示输入数据是真实的可能性。
class Discriminator(nn.Module):
def __init__(self, img_shape):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
对抗损失函数:博弈的规则
GAN的核心在于其独特的损失函数设计,它定义了生成器和判别器之间的博弈规则。传统GAN使用的是基于交叉熵的损失函数:
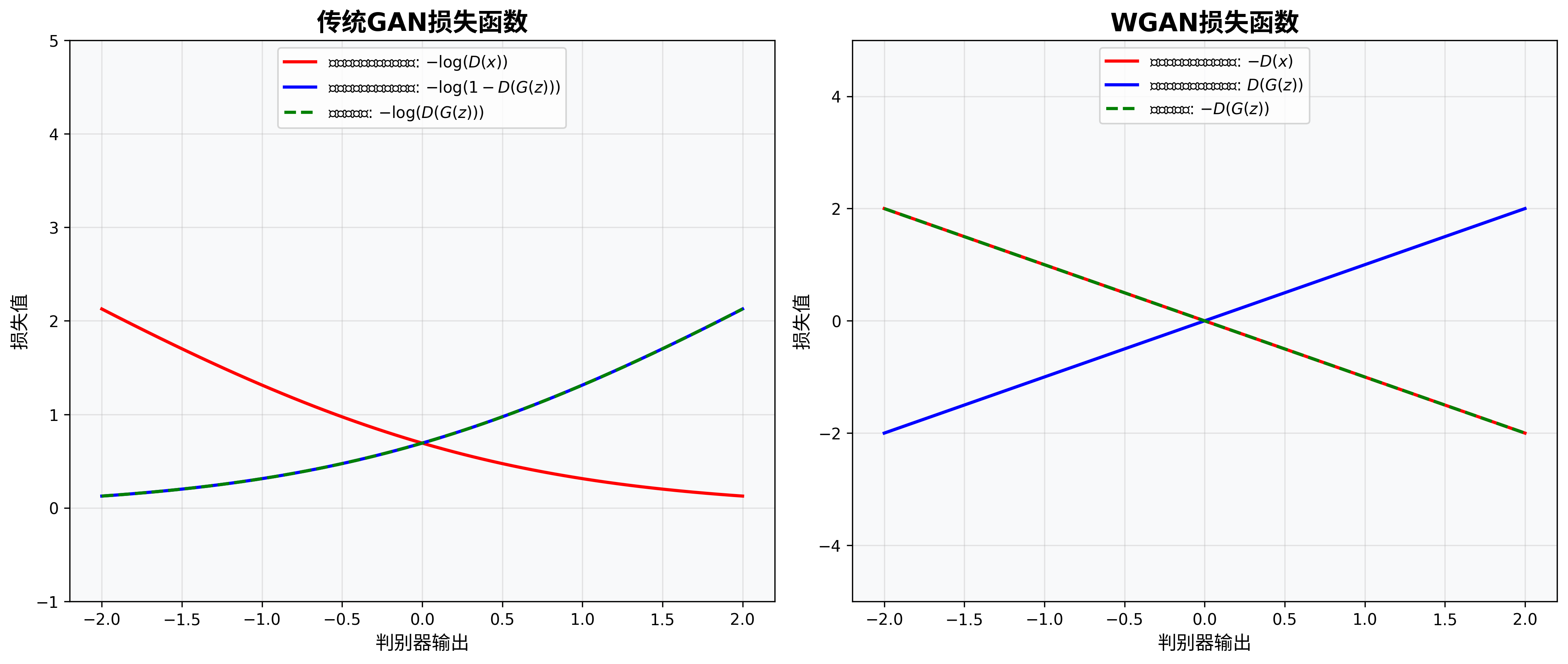
对于判别器来说,目标是最大化正确分类的概率:
- 对真实数据,判别器希望输出接近1
- 对生成数据,判别器希望输出接近0
对于生成器来说,目标是"欺骗"判别器,使其误将生成数据判断为真实数据,即希望判别器对生成数据的输出接近1。
这可以表达为以下的数学形式:
$$\min_G \max_D V(D, G) = \mathbb{E}{x \sim p{data}}[\log D(x)] + \mathbb{E}_{z \sim p_z}[\log(1 – D(G(z)))]$$
这是一个极小极大博弈问题,其中G试图最小化这个目标函数,而D试图最大化它。
训练过程:一场精妙的舞蹈
GAN的训练过程就像一场精心编排的舞蹈,生成器和判别器交替进行优化,不断相互适应和提升:
- 训练判别器:固定生成器参数,训练判别器区分真实样本和生成样本
- 训练生成器:固定判别器参数,训练生成器产生更"逼真"的样本
这种交替训练的过程非常微妙,需要仔细平衡两个网络的能力。如果判别器太强,生成器可能永远无法产生足够好的样本;如果判别器太弱,生成器可能无法得到有用的反馈来改进。
# 训练循环示例
for epoch in range(num_epochs):
for i, (real_imgs, _) in enumerate(dataloader):
# 配置输入
real_imgs = real_imgs.to(device)
batch_size = real_imgs.shape[0]
# 创建标签
valid = torch.ones(batch_size, 1).to(device)
fake = torch.zeros(batch_size, 1).to(device)
# ---------- 训练判别器 ----------
optimizer_D.zero_grad()
# 真实图像的损失
real_loss = adversarial_loss(discriminator(real_imgs), valid)
# 生成图像的损失
z = torch.randn(batch_size, latent_dim).to(device)
gen_imgs = generator(z)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
# 总损失
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
# ---------- 训练生成器 ----------
optimizer_G.zero_grad()
# 生成有效图像的损失
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step()
模式崩溃:GAN训练的陷阱
GAN训练面临的一个主要挑战是模式崩溃(Mode Collapse),即生成器只学会产生有限几种样本,而不是捕捉真实数据分布的多样性。
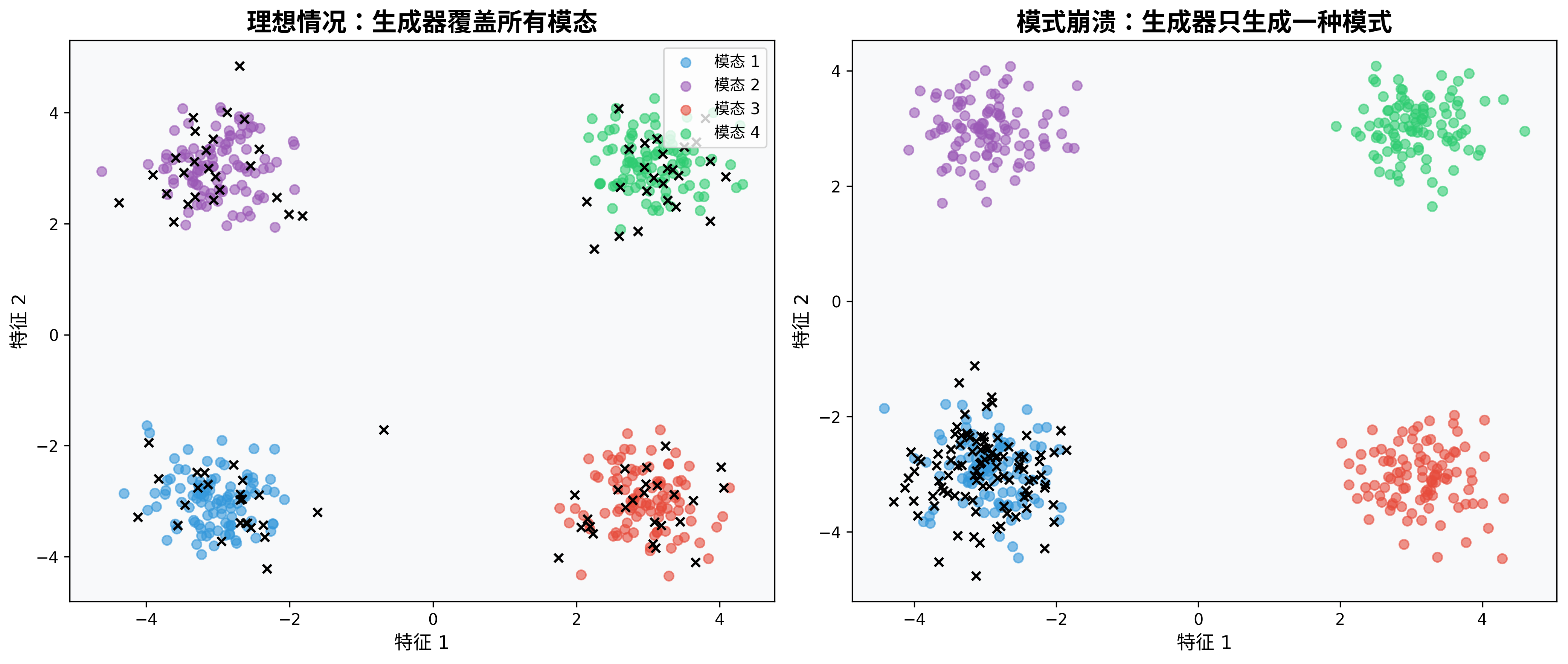
想象一个画家,他发现画一种特定风格的树总能骗过评论家,于是他只画这一种树,完全忽略了森林中其他种类的树木。这就是模式崩溃的形象比喻。
模式崩溃的主要原因包括:
- 生成器找到了判别器的"盲点"
- 优化过程中的局部最优
- 判别器提供的梯度信号不足以指导生成器探索整个数据空间
这一问题促使研究人员开发了更先进的GAN变体,如WGAN和WGAN-GP,以提供更稳定的训练过程。
WGAN:突破传统限制
Wasserstein GAN(WGAN)是对传统GAN的一次重要改进,由Martin Arjovsky等人在2017年提出。WGAN引入了一个全新的损失函数,基于Wasserstein距离(也称为推土机距离)来衡量真实数据分布和生成数据分布之间的差异。
WGAN的核心思想
传统GAN使用JS散度作为分布度量,当两个分布支撑集没有显著重叠时,JS散度无法提供有意义的梯度。相比之下,Wasserstein距离即使在分布完全分离的情况下也能提供有用的梯度信息。
WGAN的损失函数可以表示为:
$$\min_G \max_D \mathbb{E}{x \sim p{data}}[D(x)] – \mathbb{E}_{z \sim p_z}[D(G(z))]$$
其中D不再输出概率值,而是一个实数分数,因此在WGAN中,判别器更准确地称为"评论家"(Critic)。
WGAN的关键改进
WGAN引入了几个关键改进:
- 移除了判别器最后的sigmoid激活函数
- 使用Wasserstein距离替代JS散度
- 通过权重剪裁(weight clipping)来强制评论家满足1-Lipschitz约束
- 不再使用log在损失函数中
这些改变带来了显著的优势:
- 训练更加稳定,不再需要精心平衡生成器和判别器
- 损失函数值与生成样本质量高度相关,可作为有效的进度指标
- 显著减轻了模式崩溃问题
WGAN-GP:进一步完善
尽管WGAN提供了更稳定的训练过程,但权重剪裁方法本身存在一些问题。它可能导致模型容量下降,或者梯度消失/爆炸问题。为了解决这些问题,研究人员提出了WGAN-GP(Wasserstein GAN with Gradient Penalty)。
梯度惩罚:更优雅的约束方式
WGAN-GP用梯度惩罚替代了权重剪裁,通过惩罚评论家在真实数据和生成数据之间的插值点上的梯度范数偏离1的情况,来满足Lipschitz约束。
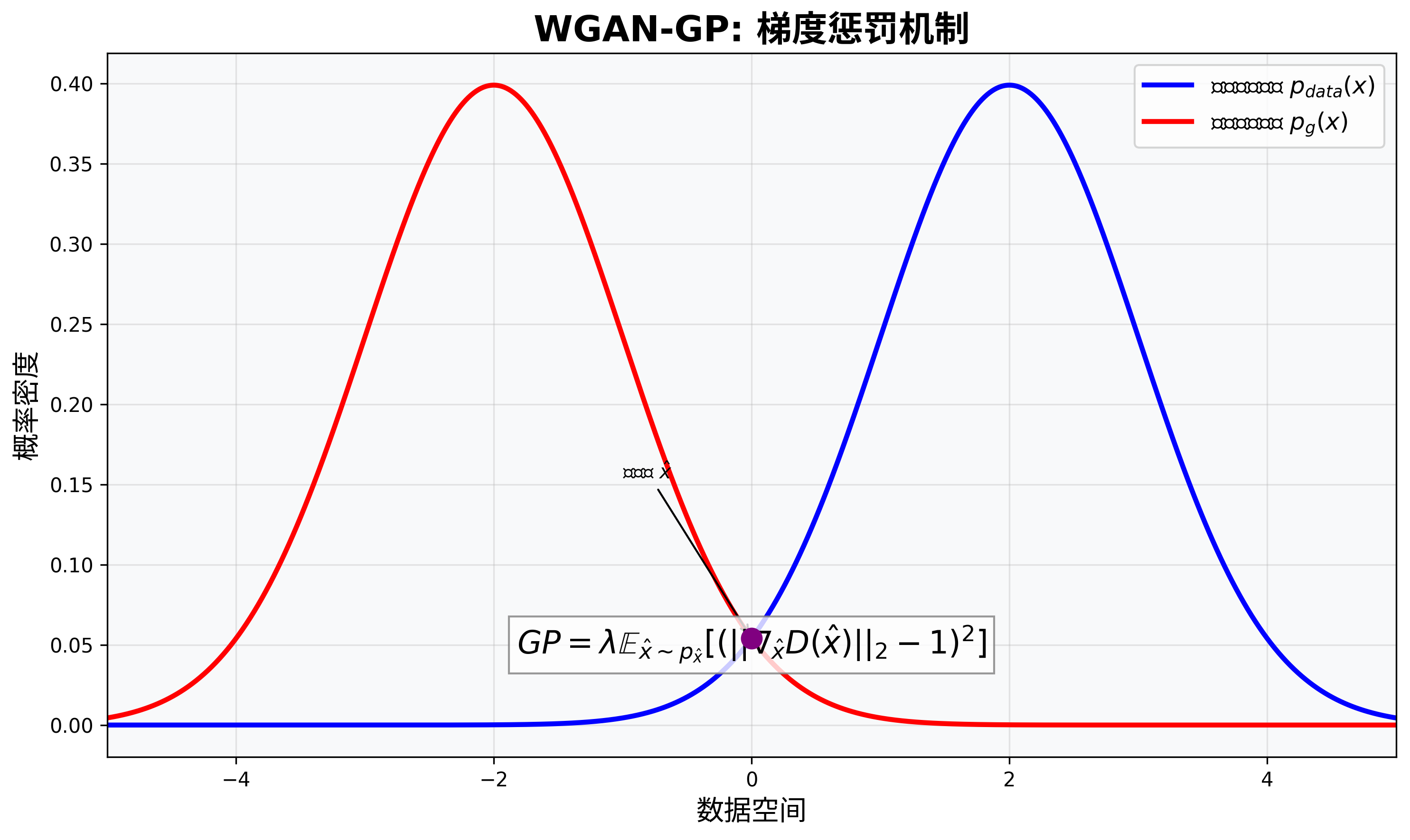
WGAN-GP的损失函数为:
$$\min_G \max_D \mathbb{E}{x \sim p{data}}[D(x)] – \mathbb{E}{z \sim p_z}[D(G(z))] + \lambda\mathbb{E}{\hat{x} \sim p_{\hat{x}}}[(|\nabla_{\hat{x}}D(\hat{x})|_2 – 1)^2]$$
其中,$\hat{x}$是真实样本和生成样本之间的随机插值,$\lambda$是惩罚系数,通常设为10。
WGAN-GP梯度惩罚实现
# WGAN-GP梯度惩罚实现
def compute_gradient_penalty(D, real_samples, fake_samples):
# 随机插值系数
alpha = torch.rand(real_samples.size(0), 1, 1, 1).to(device)
# 在真实和生成样本之间进行插值
interpolates = (alpha * real_samples + ((1 - alpha) * fake_samples)).requires_grad_(True)
# 计算评论家对插值样本的评分
d_interpolates = D(interpolates)
# 创建全1张量
fake = torch.ones(d_interpolates.size()).to(device)
# 计算梯度
gradients = torch.autograd.grad(
outputs=d_interpolates,
inputs=interpolates,
grad_outputs=fake,
create_graph=True,
retain_graph=True,
only_inputs=True,
)[0]
# 计算梯度范数
gradients = gradients.view(gradients.size(0), -1)
gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean()
return gradient_penalty
WGAN-GP的优势
WGAN-GP相对于WGAN的主要优势包括:
- 避免了权重剪裁带来的模型容量限制
- 提供了更平稳的梯度,进一步提升训练稳定性
- 允许使用更强大的网络架构,如ResNet
- 适用于更广泛的应用场景,包括高分辨率图像生成
实战:用PyTorch实现GAN
理论讲解之后,让我们动手实践,使用PyTorch实现一个简单的GAN模型来生成MNIST手写数字。下面是一个完整的实现示例:
传统GAN实现
首先,我们来看传统GAN的完整PyTorch实现代码:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
import numpy as np
# 超参数设置
latent_dim = 100
img_shape = (1, 28, 28)
batch_size = 64
lr = 0.0002
b1 = 0.5
b2 = 0.999
n_epochs = 200
# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载数据
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
mnist = torchvision.datasets.MNIST(root="./data", train=True, download=True, transform=transform)
dataloader = DataLoader(mnist, batch_size=batch_size, shuffle=True)
# 生成器
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
# 输入是latent_dim维随机向量
nn.Linear(latent_dim, 128),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(128, 256),
nn.BatchNorm1d(256, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 512),
nn.BatchNorm1d(512, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), *img_shape)
return img
# 判别器
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
# 初始化模型
generator = Generator().to(device)
discriminator = Discriminator().to(device)
# 损失函数和优化器
adversarial_loss = nn.BCELoss()
optimizer_G = optim.Adam(generator.parameters(), lr=lr, betas=(b1, b2))
optimizer_D = optim.Adam(discriminator.parameters(), lr=lr, betas=(b1, b2))
WGAN-GP实现
现在,让我们看看如何实现WGAN-GP版本:
# 超参数设置(与前面相同,增加了一些特定参数)
n_critic = 5 # 每训练一次生成器,训练评论家的次数
lambda_gp = 10 # 梯度惩罚系数
# 评论家 (替代判别器)
class Critic(nn.Module):
def __init__(self):
super(Critic, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1)
# 注意:没有Sigmoid激活函数
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
# WGAN-GP训练循环的关键部分
def wgan_gp_train_step(real_imgs, generator, critic, optimizer_G, optimizer_C):
batch_size = real_imgs.size(0)
# ---------- 训练评论家 ----------
optimizer_C.zero_grad()
# 生成随机样本
z = torch.randn(batch_size, latent_dim).to(device)
fake_imgs = generator(z)
# 评论家对真实和生成图像的评分
real_validity = critic(real_imgs)
fake_validity = critic(fake_imgs.detach())
# 计算梯度惩罚
gradient_penalty = compute_gradient_penalty(critic, real_imgs.data, fake_imgs.data)
# 评论家损失
c_loss = -torch.mean(real_validity) + torch.mean(fake_validity) + lambda_gp * gradient_penalty
c_loss.backward()
optimizer_C.step()
# ---------- 训练生成器 ----------
optimizer_G.zero_grad()
# 生成新的假图像
fake_imgs = generator(z)
# 评论家对生成图像的评分
fake_validity = critic(fake_imgs)
# 生成器损失
g_loss = -torch.mean(fake_validity)
g_loss.backward()
optimizer_G.step()
return c_loss.item(), g_loss.item(), fake_imgs
GAN变体的比较与应用场景
不同GAN变体各有优缺点,适用于不同的应用场景:
传统GAN
- 优势:实现简单,训练速度较快
- 缺点:训练不稳定,容易出现模式崩溃
- 适用场景:简单的图像生成任务,如低分辨率图像生成
WGAN
- 优势:训练更稳定,损失函数与样本质量相关
- 缺点:权重剪裁可能限制模型容量
- 适用场景:需要稳定训练过程的场景,但对生成质量要求不是特别高
WGAN-GP
- 优势:训练最稳定,生成质量高,适用于复杂模型
- 缺点:计算开销大,训练速度较慢
- 适用场景:高质量图像生成、复杂数据分布学习,如高分辨率图像、风格迁移等
结论:GAN的现在与未来
生成对抗网络自2014年提出以来,已经发展成为生成模型领域最活跃、最有影响力的方向之一。从最初的GAN到WGAN,再到WGAN-GP,研究人员不断改进其架构和训练方法,使其在各种生成任务中取得令人瞩目的成就。
今天,GAN已经广泛应用于图像生成、风格迁移、图像修复、超分辨率重建等多个领域。未来,随着计算能力的提升和算法的进一步改进,我们可以期待GAN在更多领域发挥创造力,可能包括更逼真的视频生成、交互式内容创作等。
学习和理解GAN不仅是掌握一项强大的生成模型技术,更是深入理解人工智能创造力的一次探索之旅。希望本文能帮助你更好地理解GAN的原理和实践,激发你在这个令人兴奋的领域进行进一步探索和创新。