想象一下,你手里有一堆看起来像乱码的数据文件,就像一本用外星文字写成的藏宝图。这些数据里藏着能改变商业决策、预测未来趋势、甚至拯救生命的宝贵信息,但它们却以最混乱的形式呈现在你面前。这时,Pandas就像是一位精通各种语言的翻译大师,能够将这些数据转化为清晰、有序、可以理解的故事。
网页版:https://mzymerxk.gensparkspace.com
视频版:https://www.youtube.com/watch?v=wQeTEeBNu7o
音频版:https://notebooklm.google.com/notebook/a3911079-e983-4b73-9c6c-a9fe2ef4b4ad/audio

初识数据世界的两大守护神
在这个数据的王国里,有两位不可或缺的守护神:Series和DataFrame。它们就像是数据世界的亚当和夏娃,从它们开始,衍生出了整个数据分析的生态系统。
Series,这位单纯的守护者,专注于处理一维数据。想象一下一条直线上排列着的珍珠,每颗珍珠都有自己的位置标记。无论是一家公司连续12个月的销售额,还是一个班级学生的考试成绩,Series都能优雅地将它们组织起来。
import pandas as pd
import numpy as np
# 创建一个简单的Series,就像记录一周的气温
temperatures = pd.Series([22, 25, 28, 26, 24, 23, 21],
index=['Monday', 'Tuesday', 'Wednesday',
'Thursday', 'Friday', 'Saturday', 'Sunday'])
print(temperatures)
DataFrame则是数据王国的女王,她统治着二维表格的世界。如果说Series是一条项链,那么DataFrame就是一整个珠宝盒,里面整齐地摆放着各种不同类型的珠宝。一个电商网站的订单数据、一家医院的病人记录、一所学校的学生档案,都在DataFrame的管辖范围内。
# 创建一个DataFrame,记录学生信息
students_data = {
'name': ['张三', '李四', '王五', '赵六'],
'age': [20, 21, 19, 22],
'grade': [85, 92, 78, 95],
'city': ['北京', '上海', '广州', '深圳']
}
df = pd.DataFrame(students_data)
print(df)
这两位守护神的存在,让原本复杂的数据操作变得如此优雅。就像指挥家挥动指挥棒,瞬间让杂乱的音符变成美妙的交响乐。
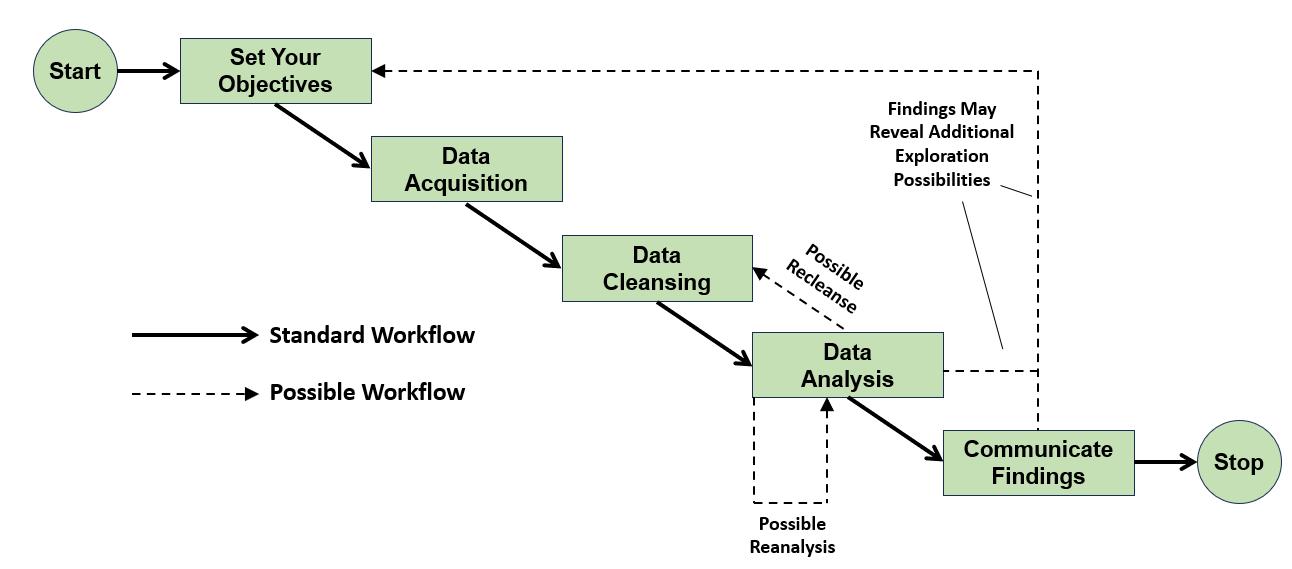
数据的生命之源:读取与写入的艺术
在数据分析的世界里,数据就像是生命之水,而读取和写入就是控制这些水流的闸门。现代社会中,数据以各种形式存在:CSV文件像是最常见的矿泉水瓶,Excel文件像是精装的茶叶罐,而SQL数据库则像是深藏地下的水库。
CSV文件处理就像是最基础的生存技能。想象你在野外探险,遇到一条清澈的小溪,你需要知道如何安全地取水饮用:
# 读取CSV文件,就像从溪流中取水
df = pd.read_csv('sales_data.csv', encoding='utf-8')
# 查看数据的基本信息,就像检验水质
print(df.info())
print(df.head())
# 保存处理后的数据,就像将净化的水储存起来
df.to_csv('cleaned_sales_data.csv', index=False, encoding='utf-8')
Excel文件处理则需要更多的技巧,就像是调制一杯完美的咖啡,需要考虑各种细节:
# 从Excel读取多个工作表,就像同时冲泡多种不同的咖啡豆
excel_file = pd.ExcelFile('company_data.xlsx')
sales_df = pd.read_excel(excel_file, sheet_name='销售数据')
inventory_df = pd.read_excel(excel_file, sheet_name='库存数据')
# 将数据写入Excel的不同工作表
with pd.ExcelWriter('processed_data.xlsx') as writer:
sales_df.to_excel(writer, sheet_name='处理后销售数据', index=False)
inventory_df.to_excel(writer, sheet_name='处理后库存数据', index=False)
SQL数据库连接则像是连接到城市的自来水系统,需要正确的管道和权限:
import sqlite3
from sqlalchemy import create_engine
# 建立数据库连接,就像连接到城市供水系统
engine = create_engine('sqlite:///company_database.db')
# 从数据库读取数据
query = '''
SELECT customer_id, product_name, quantity, price, order_date
FROM orders
WHERE order_date >= '2024-01-01'
'''
orders_df = pd.read_sql(query, engine)
# 将处理后的数据写回数据库
orders_df.to_sql('processed_orders', engine, if_exists='replace', index=False)
数据清洗:从混沌到秩序的蜕变
数据清洗就像是一场魔法表演,你需要将一堆看似毫无规律的原始数据,变成整洁、可用的信息。这个过程充满了挑战,但也蕴含着无穷的乐趣。
处理缺失值就像是修复破损的古董。有时你会发现数据中有一些空白的地方,就像古董上的裂痕。你需要决定是填补这些裂痕,还是移除受损的部分:
# 检查缺失值的分布情况,就像检查古董的损坏程度
print(df.isnull().sum())
print(df.isnull().sum() / len(df) * 100) # 计算缺失值百分比
# 不同的填补策略,就像不同的修复技术
# 用均值填补数值型数据
df['age'].fillna(df['age'].mean(), inplace=True)
# 用众数填补分类数据
df['city'].fillna(df['city'].mode()[0], inplace=True)
# 前向填充,适用于时间序列数据
df['stock_price'].fillna(method='ffill', inplace=True)
# 后向填充
df['stock_price'].fillna(method='bfill', inplace=True)
# 删除缺失值过多的行或列
df.dropna(thresh=len(df.columns)*0.7, inplace=True) # 删除缺失值超过30%的行
处理重复值就像是整理衣柜,你需要找出那些完全相同的衣服,然后决定保留哪一件:
# 检查重复值,就像检查衣柜里的重复衣物
print(f"重复行数量: {df.duplicated().sum()}")
# 查看重复的具体行
duplicate_rows = df[df.duplicated()]
print("重复的行:")
print(duplicate_rows)
# 移除重复值,保留第一次出现的记录
df.drop_duplicates(inplace=True)
# 根据特定列判断重复
df.drop_duplicates(subset=['customer_id', 'order_date'], keep='last', inplace=True)
处理异常值就像是在人群中寻找伪装的间谍,需要敏锐的观察力和判断力:
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
# 使用箱线图可视化异常值
plt.figure(figsize=(10, 6))
sns.boxplot(data=df, x='salary')
plt.title('薪资分布箱线图')
plt.show()
# Z-score方法检测异常值
z_scores = np.abs(stats.zscore(df['salary']))
threshold = 3
outliers = df[z_scores > threshold]
print(f"Z-score方法检测到 {len(outliers)} 个异常值")
# IQR方法检测异常值
Q1 = df['salary'].quantile(0.25)
Q3 = df['salary'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# 移除异常值
df_clean = df[(df['salary'] >= lower_bound) & (df['salary'] <= upper_bound)]
print(f"IQR方法移除了 {len(df) - len(df_clean)} 个异常值")
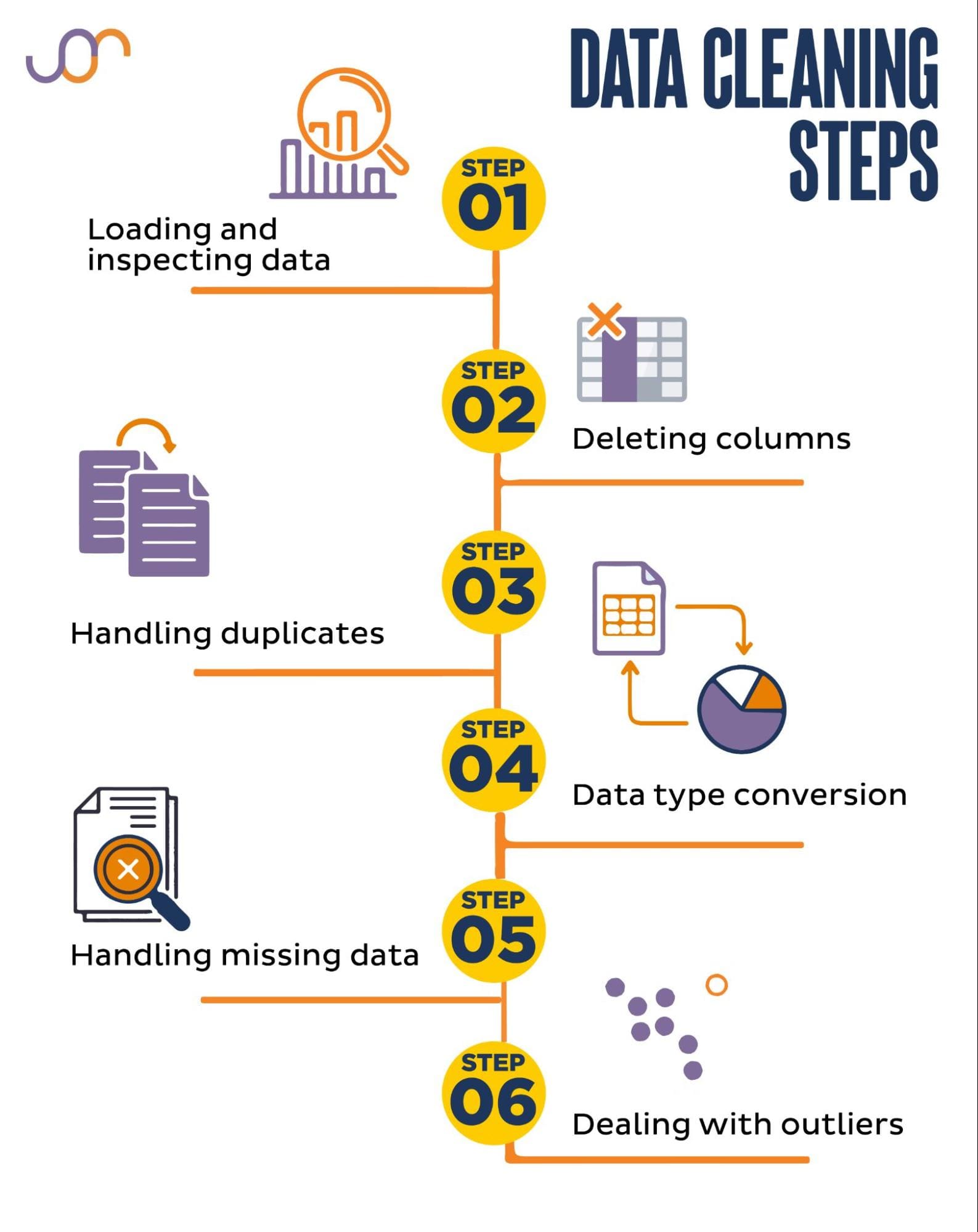
数据转换:化腐朽为神奇的炼金术
数据转换就像是炼金术士的工作,将普通的原材料通过精妙的化学反应,转化为珍贵的黄金。在Pandas的世界里,合并、重塑、分组和聚合就是我们的炼金配方。
数据合并就像是烹饪中的食材搭配,不同的食材组合在一起,能够创造出全新的味道:
# 内连接:只保留两个数据集都有的记录,就像找到共同朋友
customers = pd.DataFrame({
'customer_id': [1, 2, 3, 4],
'name': ['张三', '李四', '王五', '赵六'],
'city': ['北京', '上海', '广州', '深圳']
})
orders = pd.DataFrame({
'order_id': [101, 102, 103, 104],
'customer_id': [1, 2, 1, 5],
'product': ['手机', '电脑', '平板', '耳机'],
'amount': [5000, 8000, 3000, 500]
})
# 内连接
inner_join = pd.merge(customers, orders, on='customer_id', how='inner')
print("内连接结果:")
print(inner_join)
# 左连接:保留所有客户信息,即使没有订单
left_join = pd.merge(customers, orders, on='customer_id', how='left')
print("\n左连接结果:")
print(left_join)
# 外连接:保留所有信息
outer_join = pd.merge(customers, orders, on='customer_id', how='outer')
print("\n外连接结果:")
print(outer_join)
数据重塑就像是变形金刚,能够在不同的形态之间自由转换:
# 创建一个宽格式的数据
wide_data = pd.DataFrame({
'name': ['张三', '李四', '王五'],
'math': [85, 92, 78],
'english': [88, 85, 92],
'science': [90, 88, 85]
})
# 长格式转换:从宽表变成长表
long_data = pd.melt(wide_data,
id_vars=['name'],
value_vars=['math', 'english', 'science'],
var_name='subject',
value_name='score')
print("长格式数据:")
print(long_data)
# 透视表:从长表变成宽表
pivot_data = long_data.pivot(index='name', columns='subject', values='score')
print("\n透视表结果:")
print(pivot_data)
# 数据透视表,类似Excel的数据透视表功能
sales_data = pd.DataFrame({
'date': ['2024-01', '2024-01', '2024-02', '2024-02'],
'region': ['北方', '南方', '北方', '南方'],
'product': ['A', 'B', 'A', 'B'],
'sales': [100, 150, 120, 180]
})
pivot_table = pd.pivot_table(sales_data,
values='sales',
index='date',
columns='region',
aggfunc='sum')
print("\n销售数据透视表:")
print(pivot_table)
分组聚合就像是数据的聚会组织者,将相似的数据聚集在一起,然后进行各种有趣的统计活动:
# 创建销售数据
sales_df = pd.DataFrame({
'salesperson': ['张三', '李四', '张三', '王五', '李四', '张三'],
'region': ['北方', '南方', '北方', '南方', '南方', '北方'],
'product': ['A', 'B', 'B', 'A', 'A', 'C'],
'quantity': [10, 15, 8, 12, 20, 5],
'revenue': [1000, 1500, 800, 1200, 2000, 500]
})
# 按销售人员分组,计算总销售额和平均销售额
grouped = sales_df.groupby('salesperson').agg({
'quantity': 'sum',
'revenue': ['sum', 'mean', 'max']
}).round(2)
print("按销售人员分组统计:")
print(grouped)
# 按地区和产品双重分组
multi_group = sales_df.groupby(['region', 'product'])['revenue'].sum()
print("\n按地区和产品分组:")
print(multi_group)
# 使用transform进行组内标准化
sales_df['revenue_zscore'] = sales_df.groupby('region')['revenue'].transform(
lambda x: (x - x.mean()) / x.std()
)
print("\n组内标准化后的数据:")
print(sales_df[['salesperson', 'region', 'revenue', 'revenue_zscore']])
时间序列分析:与时间共舞的艺术
时间序列分析就像是与时间本身对话,通过数据中隐藏的时间密码,我们能够窥探过去、理解现在、预测未来。在金融市场的股票价格波动、电商网站的销售趋势、气象站的温度记录中,时间都是最重要的维度。
# 创建时间索引,就像制作一个精确的时间表
date_range = pd.date_range(start='2024-01-01', end='2024-12-31', freq='D')
print(f"创建了 {len(date_range)} 个日期")
# 模拟股票价格数据
np.random.seed(42)
stock_prices = pd.Series(
100 + np.cumsum(np.random.randn(len(date_range)) * 0.5),
index=date_range,
name='stock_price'
)
# 时间序列的基本操作
print("股票价格统计信息:")
print(stock_prices.describe())
# 重采样:从日数据聚合到月数据
monthly_avg = stock_prices.resample('M').mean()
print("\n月平均价格:")
print(monthly_avg.head())
# 计算移动平均线,就像给数据戴上一副柔光镜
stock_prices_df = pd.DataFrame({'price': stock_prices})
stock_prices_df['ma_7'] = stock_prices_df['price'].rolling(window=7).mean()
stock_prices_df['ma_30'] = stock_prices_df['price'].rolling(window=30).mean()
# 计算价格变化率
stock_prices_df['daily_return'] = stock_prices_df['price'].pct_change()
stock_prices_df['volatility'] = stock_prices_df['daily_return'].rolling(window=30).std()
print("\n股票价格分析结果:")
print(stock_prices_df.head(10))
# 时间序列分解:趋势、季节性、残差
from statsmodels.tsa.seasonal import seasonal_decompose
# 为了演示季节性,创建一个带有季节性模式的时间序列
seasonal_data = (
100 + 0.1 * np.arange(len(date_range)) + # 趋势
10 * np.sin(2 * np.pi * np.arange(len(date_range)) / 365.25) + # 年度季节性
np.random.randn(len(date_range)) * 2 # 噪声
)
seasonal_series = pd.Series(seasonal_data, index=date_range)
# 进行时间序列分解
decomposition = seasonal_decompose(seasonal_series, model='additive', period=365)
print("\n时间序列分解完成")
print(f"趋势组件方差: {decomposition.trend.var():.2f}")
print(f"季节性组件方差: {decomposition.seasonal.var():.2f}")
print(f"残差组件方差: {decomposition.resid.var():.2f}")
真实项目实战:泰坦尼克号数据分析
让我们通过分析著名的泰坦尼克号数据集,来实际体验Pandas数据处理的完整流程。这个数据集就像是一个装满故事的宝箱,每一行数据都代表着一个真实的生命和他们在那个历史性夜晚的遭遇。

# 加载泰坦尼克号数据集
# 在实际项目中,你可以从 Kaggle 下载这个数据集
# 这里我们创建一个模拟的数据集用于演示
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 创建模拟的泰坦尼克号数据
np.random.seed(42)
n_passengers = 891
titanic_data = {
'PassengerId': range(1, n_passengers + 1),
'Survived': np.random.choice([0, 1], n_passengers, p=[0.62, 0.38]),
'Pclass': np.random.choice([1, 2, 3], n_passengers, p=[0.24, 0.21, 0.55]),
'Name': [f'Passenger_{i}' for i in range(1, n_passengers + 1)],
'Sex': np.random.choice(['male', 'female'], n_passengers, p=[0.65, 0.35]),
'Age': np.random.normal(30, 12, n_passengers),
'SibSp': np.random.poisson(0.5, n_passengers),
'Parch': np.random.poisson(0.4, n_passengers),
'Ticket': [f'Ticket_{i}' for i in range(1, n_passengers + 1)],
'Fare': np.random.exponential(15, n_passengers),
'Cabin': np.random.choice(['A', 'B', 'C', 'D', 'E', 'F', 'G', None],
n_passengers, p=[0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.65]),
'Embarked': np.random.choice(['C', 'Q', 'S'], n_passengers, p=[0.19, 0.09, 0.72])
}
# 处理年龄中的缺失值
age_mask = np.random.choice([True, False], n_passengers, p=[0.8, 0.2])
titanic_data['Age'] = np.where(age_mask, titanic_data['Age'], np.nan)
# 确保年龄为正数
titanic_data['Age'] = np.where(titanic_data['Age'] > 0, titanic_data['Age'], np.nan)
df = pd.DataFrame(titanic_data)
print("=== 泰坦尼克号数据分析项目 ===")
print(f"数据集形状: {df.shape}")
print(f"数据集信息:")
print(df.info())
# 1. 数据探索和清洗
print("\n=== 第一步:数据探索 ===")
print("缺失值统计:")
missing_data = df.isnull().sum()
missing_percent = (missing_data / len(df)) * 100
missing_df = pd.DataFrame({
'缺失数量': missing_data,
'缺失百分比': missing_percent
}).sort_values('缺失数量', ascending=False)
print(missing_df[missing_df['缺失数量'] > 0])
# 2. 数据清洗
print("\n=== 第二步:数据清洗 ===")
# 处理年龄缺失值:用中位数填充
age_median = df['Age'].median()
df['Age'].fillna(age_median, inplace=True)
print(f"用中位数 {age_median:.1f} 填充年龄缺失值")
# 处理Embarked缺失值:用众数填充
embarked_mode = df['Embarked'].mode()[0]
df['Embarked'].fillna(embarked_mode, inplace=True)
print(f"用众数 '{embarked_mode}' 填充登船港口缺失值")
# 删除Cabin列(缺失值太多)
df.drop('Cabin', axis=1, inplace=True)
print("删除了缺失值过多的Cabin列")
# 创建新特征
df['Family_Size'] = df['SibSp'] + df['Parch'] + 1
df['Is_Alone'] = (df['Family_Size'] == 1).astype(int)
df['Age_Group'] = pd.cut(df['Age'], bins=[0, 12, 18, 35, 60, 100],
labels=['Child', 'Teen', 'Adult', 'Middle_Age', 'Senior'])
print("创建了新特征: Family_Size, Is_Alone, Age_Group")
# 3. 数据分析和可视化
print("\n=== 第三步:数据分析 ===")
# 生存率总体统计
survival_rate = df['Survived'].mean()
print(f"总体生存率: {survival_rate:.2%}")
# 按性别分析生存率
gender_survival = df.groupby('Sex')['Survived'].agg(['count', 'mean'])
gender_survival.columns = ['总人数', '生存率']
print("\n按性别分析生存率:")
print(gender_survival)
# 按客舱等级分析生存率
class_survival = df.groupby('Pclass')['Survived'].agg(['count', 'mean'])
class_survival.columns = ['总人数', '生存率']
print("\n按客舱等级分析生存率:")
print(class_survival)
# 按年龄组分析生存率
age_survival = df.groupby('Age_Group')['Survived'].agg(['count', 'mean'])
age_survival.columns = ['总人数', '生存率']
print("\n按年龄组分析生存率:")
print(age_survival)
# 4. 高级分析:交叉表分析
print("\n=== 第四步:交叉分析 ===")
# 性别和客舱等级的交叉分析
cross_analysis = pd.crosstab(df['Sex'], df['Pclass'], df['Survived'], aggfunc='mean')
print("性别和客舱等级的生存率交叉分析:")
print(cross_analysis.round(3))
# 5. 数据聚合和统计
print("\n=== 第五步:统计总结 ===")
# 各种统计指标
summary_stats = df.groupby(['Sex', 'Pclass']).agg({
'Survived': ['count', 'mean'],
'Age': ['mean', 'std'],
'Fare': ['mean', 'median'],
'Family_Size': 'mean'
}).round(2)
print("分组统计总结 (前10行):")
print(summary_stats.head(10))
# 6. 链式操作展示Pandas的优雅
print("\n=== 第六步:链式操作演示 ===")
# 一个复杂的链式操作:找出高消费且生存的女性乘客信息
high_fare_survivors = (df
.query("Sex == 'female' and Survived == 1")
.loc[df['Fare'] > df['Fare'].quantile(0.75)]
.groupby('Pclass')
.agg({
'Age': ['mean', 'count'],
'Fare': 'mean'
})
.round(2))
print("高消费生存女性乘客按客舱等级统计:")
print(high_fare_survivors)
# 7. 时间序列模拟(假设我们有按时间记录的获救信息)
print("\n=== 第七步:时间序列分析演示 ===")
# 创建模拟的按小时获救数据
rescue_hours = pd.date_range('1912-04-15 00:00:00', periods=24, freq='H')
survivors_by_hour = np.random.poisson(15, 24) # 每小时获救人数
survivors_by_hour[0:2] = 0 # 前两小时没有获救
survivors_by_hour[2:6] = np.random.poisson(30, 4) # 救援高峰期
rescue_timeline = pd.Series(survivors_by_hour, index=rescue_hours)
print("模拟的每小时获救人数:")
print(rescue_timeline.head(10))
# 计算累计获救人数
rescue_timeline_df = pd.DataFrame({
'hourly_rescued': rescue_timeline,
'cumulative_rescued': rescue_timeline.cumsum(),
'rescue_rate': rescue_timeline.rolling(window=3).mean()
})
print("\n获救情况分析:")
print(rescue_timeline_df.head(10))
print("\n=== 项目分析完成 ===")
print("通过这个项目,我们学会了:")
print("✓ 数据加载和初步探索")
print("✓ 缺失值处理和数据清洗")
print("✓ 特征工程和新变量创建")
print("✓ 分组聚合和统计分析")
print("✓ 交叉表分析和多维度探索")
print("✓ 链式操作的优雅使用")
print("✓ 时间序列数据的基本处理")
实战技巧:链式调用的优雅艺术
在Pandas的世界里,链式调用就像是一首流畅的诗歌,每个方法都是一个韵脚,连贯地表达着数据处理的逻辑。让我们来欣赏一些优雅的链式操作:
# 一个复杂的数据处理流程,用链式调用一气呵成
result = (df
.query("Age >= 18 and Fare > 0") # 筛选成年且有票价记录的乘客
.assign(
Fare_Category=lambda x: pd.cut(x['Fare'],
bins=[0, 10, 30, 100, 1000],
labels=['Low', 'Medium', 'High', 'Luxury']),
Age_Decade=lambda x: (x['Age'] // 10) * 10
) # 创建票价分类和年龄十年组
.groupby(['Sex', 'Pclass', 'Fare_Category'])
.agg({
'Survived': ['count', 'mean'],
'Age': 'mean',
'Family_Size': 'mean'
}) # 多维度分组聚合
.round(2) # 保留两位小数
.reset_index() # 重置索引,转换为普通DataFrame
.query("Survived_count >= 5") # 只保留样本量足够的组
.sort_values('Survived_mean', ascending=False) # 按生存率排序
)
print("优雅的链式操作结果:")
print(result.head())
这种写法不仅代码简洁优雅,而且逻辑清晰,就像是在阅读一个完整的故事,从数据的筛选开始,到特征的创建,再到统计的聚合,最后到结果的整理,一气呵成。