当我第一次踏入数据科学的世界时,有一个问题一直困扰着我:在浩如烟海的数据中,如何找到那些隐藏的"异类"?就像在一个巨大的人群中找到那个与众不同的人一样,这些数据异类往往承载着最有价值的信息——它们可能是金融欺诈的信号,网络攻击的痕迹,或是设备故障的预警。
网页版:https://tmolsntv.gensparkspace.com/
视频版:https://www.youtube.com/watch?v=7bHr_xDiJrw
音频版:https://notebooklm.google.com/notebook/3b89e16d-1d98-44b6-b9be-a36553cbf23b/audio

异常的三种面孔:点、上下文与群体
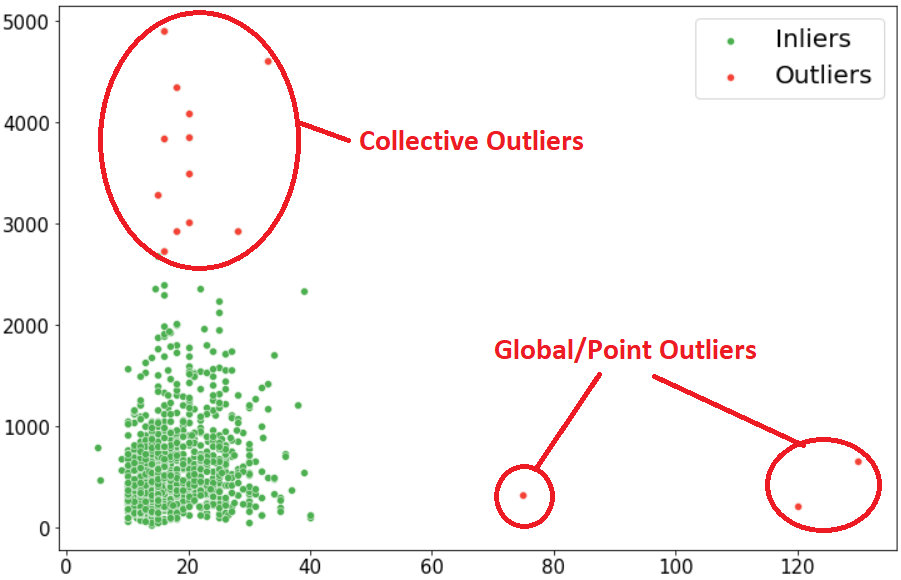
在异常检测的武林中,异常有着三种截然不同的面孔。就像上图所展示的那样,每种异常都有其独特的特征和挑战。
点异常是最直观的一种,就像夜空中最亮的星。想象你在分析银行交易数据时,突然发现有人在凌晨3点转账了100万美元——这种明显偏离常态的单个数据点就是典型的点异常。
上下文异常则需要我们考虑"时间、地点、人物"的背景。比如,一个人在平时消费100元很正常,但如果这个人是一个5岁的孩子,那这笔消费就可能是异常的。同样,某地12月份的高温可能是异常的,但在6月份就很正常。
群体异常是最狡猾的,它们个体看起来都很正常,但作为整体却暴露了问题。就像一个洗钱团伙,每个人的单笔转账都在正常范围内,但整个网络的资金流向却异常明显。
统计学派的经典武器:3-Sigma法则
让我们从最经典的异常检测方法开始——3-Sigma法则。这个方法基于统计学的黄金定律:在正态分布中,99.7%的数据都会落在均值加减三个标准差的范围内。

这种方法简单而有效,就像用一把标尺量出了"正常"的边界。在上图中,我们可以清楚地看到红色阴影区域标示了异常阈值,超出这个范围的数据点就可能是异常的。
我曾经用这个方法帮助一家电商公司识别异常订单。通过分析历史订单金额,我们发现平均订单金额是150元,标准差是50元。按照3-Sigma法则,超过300元或低于0元的订单就需要特别关注。结果证明,大部分高额订单确实存在问题——要么是刷单行为,要么是系统错误。
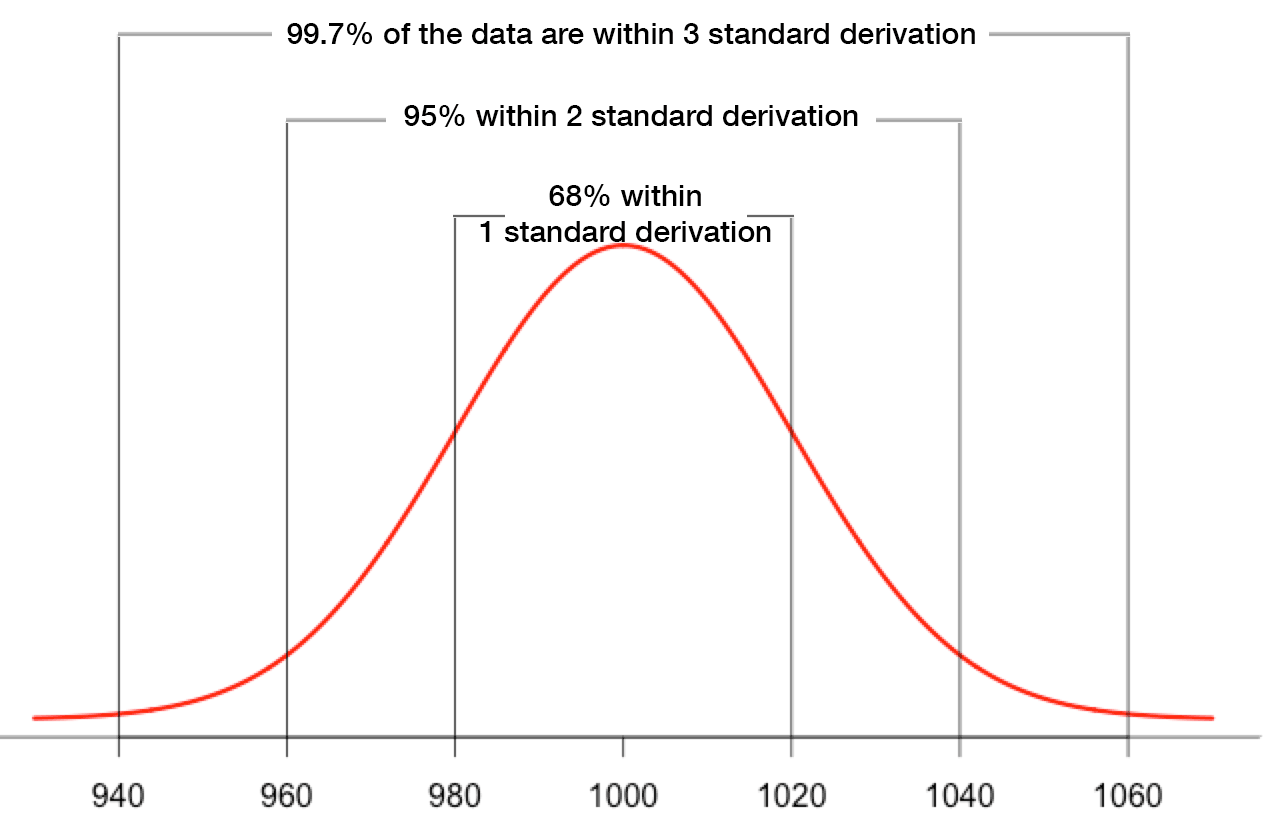
这个经典的正态分布图完美诠释了3-Sigma法则的核心理念。图中清晰地标示了1σ、2σ、3σ的边界,以及对应的概率分布。99.7%的数据都落在3σ范围内,这意味着超出这个范围的数据只有0.3%的概率是正常的。
距离学派的邻里智慧:KNN异常检测
如果说3-Sigma法则是用一把标尺衡量异常,那么KNN异常检测就像是通过"朋友圈"来判断一个人是否合群。
KNN的核心思想是:如果一个数据点与它的k个最近邻居距离都很远,那么这个点很可能是异常的。这就像在一个聚会上,如果你发现某个人周围10米内都没有其他人,那这个人可能就是"异类"。
在实际应用中,我们计算每个数据点到其第k个最近邻的距离,距离越大,异常程度越高。研究表明,KNN方法在大规模交通数据的异常检测中表现出色,能够有效识别交通流量中的异常模式。
密度学派的局部视角:LOF的智慧
局部异常因子(LOF)是异常检测领域的一颗明珠,它解决了一个重要问题:在不同密度的数据簇中,如何公平地评估异常程度。
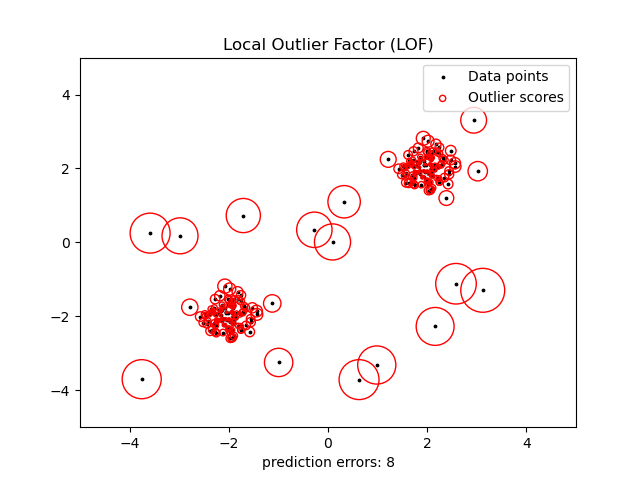
这个由scikit-learn提供的经典可视化完美展示了LOF的工作原理。图中的圆圈大小代表异常程度——圆圈越大,异常程度越高。我们可以看到,即使在不同密度的区域中,LOF都能公平地识别出异常点。
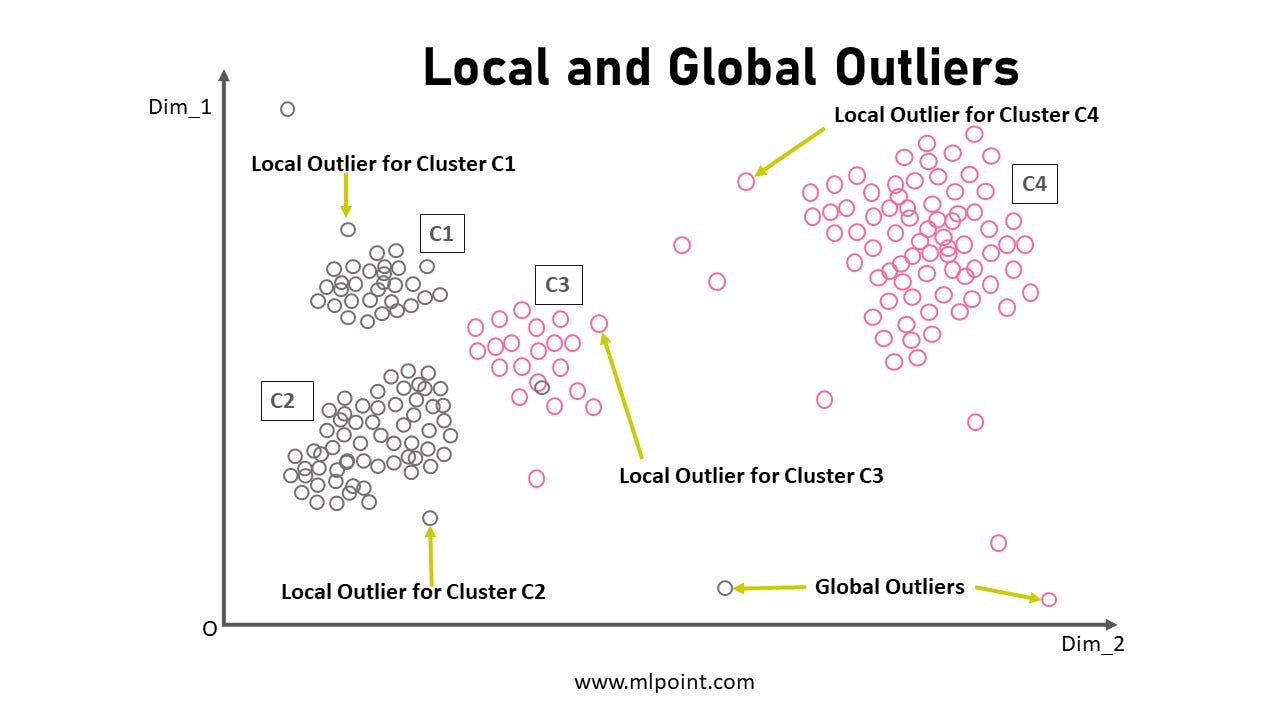
这个更直观的可视化展示了LOF的核心思想:通过比较数据点与其邻居的局部密度来判断异常。就像在不同的社区中,我们需要用不同的标准来判断房子之间的距离是否正常一样。
LOF的数学原理相对复杂,但其核心思想很直观:如果一个点的局部密度明显低于其邻居的局部密度,那么它就是异常的。根据原始论文,LOF值接近1表示正常,远大于1则表示异常。
孤立森林:优雅的随机隔离艺术
孤立森林(Isolation Forest)是我个人最喜欢的异常检测算法之一,它基于一个简单而深刻的洞察:异常点更容易被孤立。
.webp)
这个来自GeeksforGeeks的图解清晰地展示了孤立森林的工作原理。算法通过随机选择特征和分割值来构建二叉树,异常点通常只需要很少的分割就能被孤立出来。
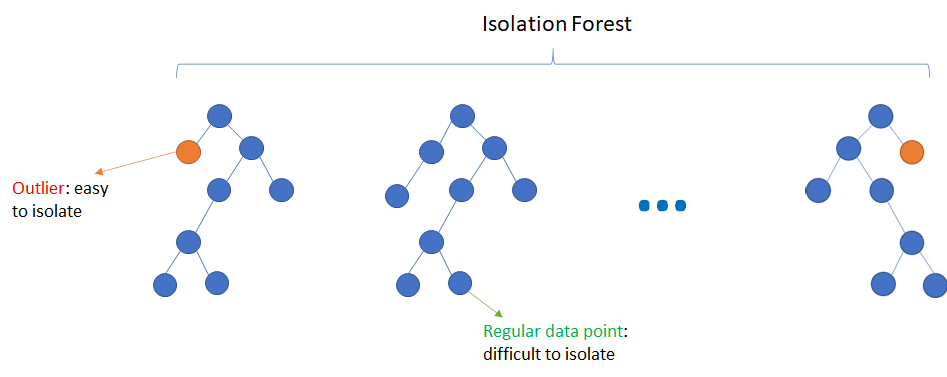
这个更详细的可视化展示了孤立森林的核心概念。左边的正常点需要更多的分割才能被隔离,而右边的异常点只需要很少的分割就能被隔离出来。
我曾经用孤立森林帮助一家制造企业监控生产设备。通过分析设备的温度、压力、振动等多维数据,孤立森林能够在设备故障前几小时就发出预警。最令人印象深刻的是,它甚至发现了一些我们之前从未意识到的异常模式。
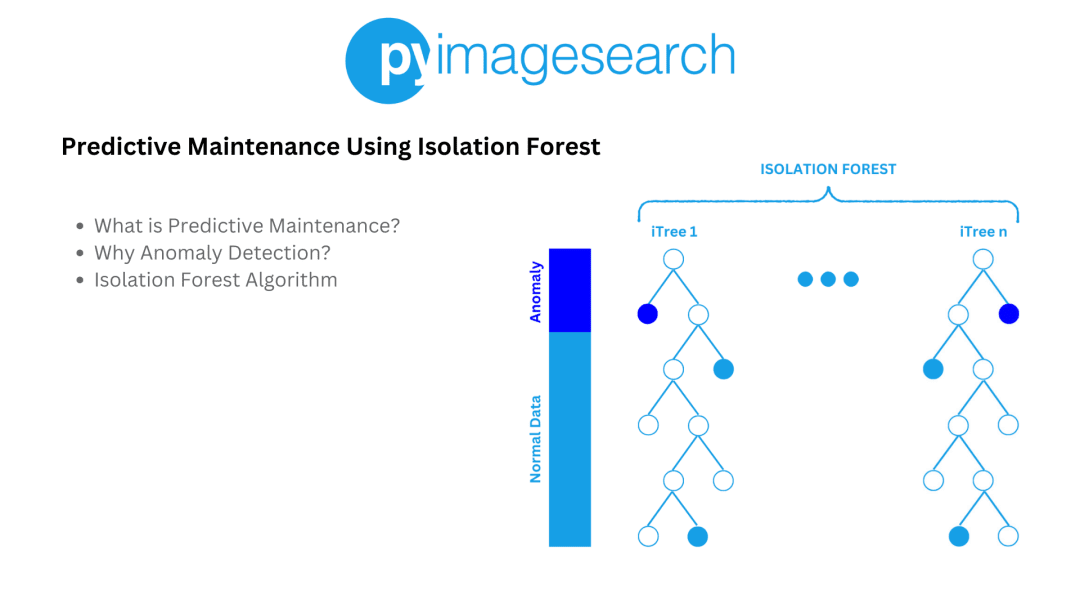
这个来自PyImageSearch的案例展示了孤立森林在预测性维护中的应用,完美诠释了这个算法的实用价值。
深度学习的自编码器:重构的艺术
自编码器(Autoencoder)是深度学习在异常检测领域的杰作,它的工作原理就像一个神奇的"数据压缩和还原机"。
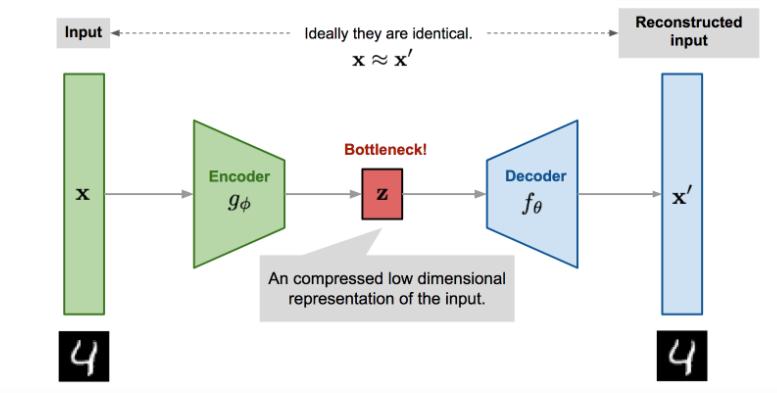
这个经典的自编码器架构图展示了编码器-解码器的结构。数据首先被压缩到低维的"瓶颈"层,然后尝试重构回原始维度。
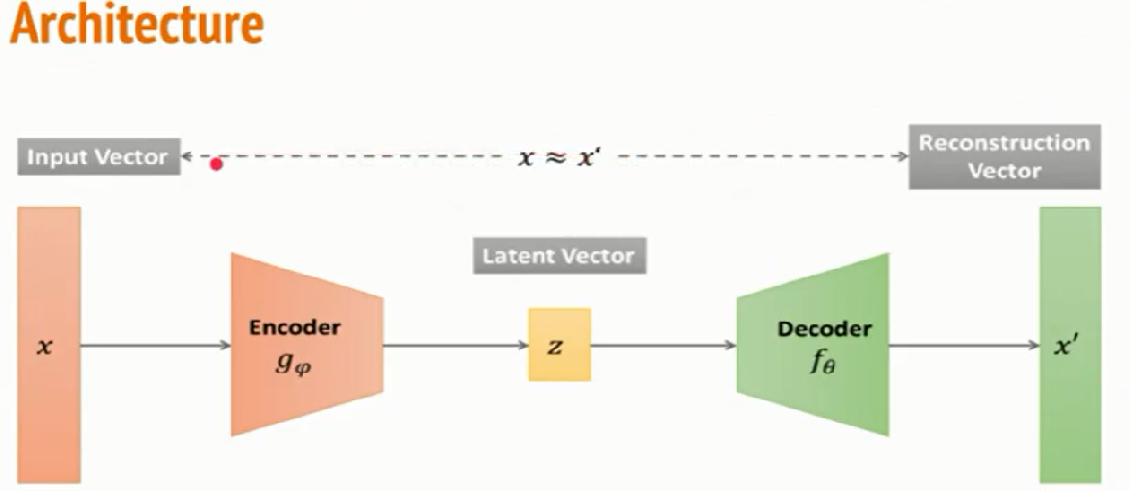
这个更详细的流程图展示了自编码器如何用于异常检测。核心思想是:正常数据能够被很好地重构,而异常数据则会产生较高的重构误差。
自编码器的魅力在于它能够学习数据的复杂表示。我曾经用它来检测制造业中的产品缺陷。通过训练自编码器学习正常产品的图像特征,当出现缺陷产品时,重构误差会明显增加,从而实现异常检测。
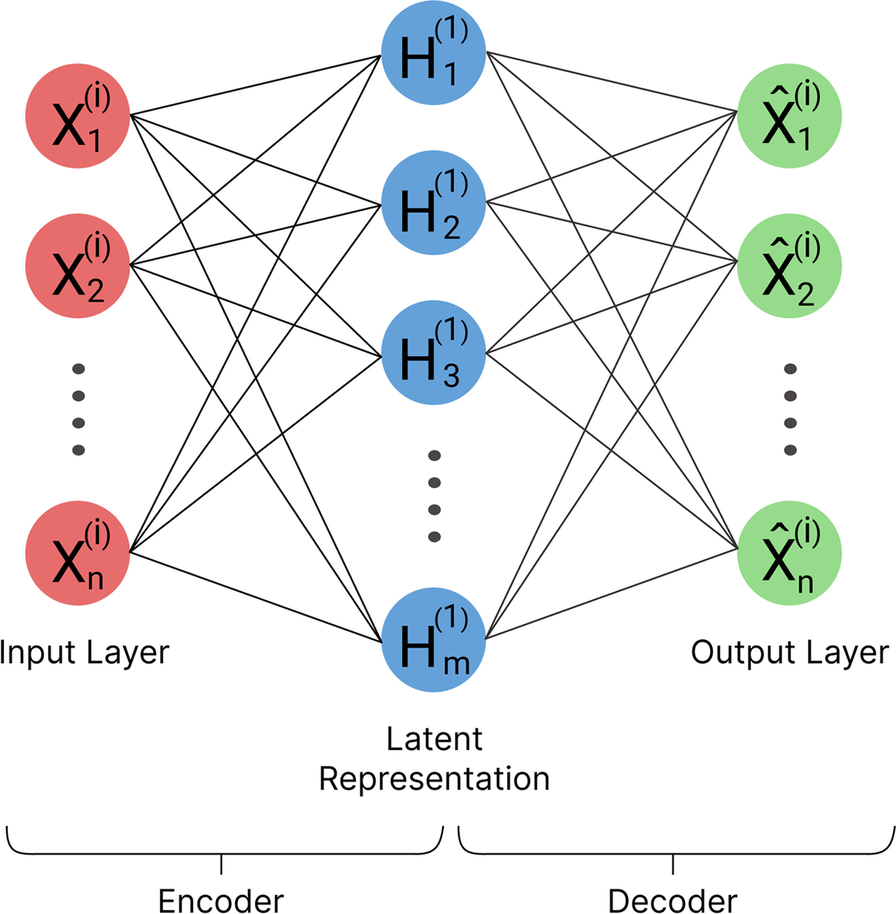
这个来自SpringerOpen的研究展示了自编码器在网络安全异常检测中的应用,通过向量重构误差的概念显著提升了检测性能。
信用卡欺诈检测:异常检测的实战演练
让我们通过一个具体的案例来看看这些技术如何在实战中发挥作用——信用卡欺诈检测。
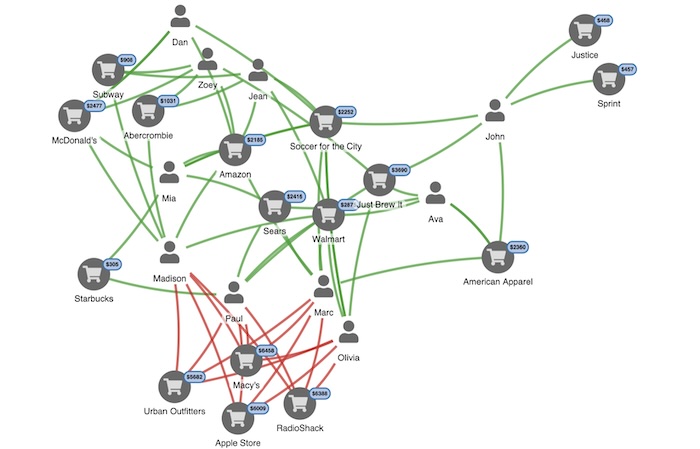
信用卡欺诈检测是异常检测技术的经典应用场景。在这个领域,我们面临着极度不平衡的数据:在数十万笔正常交易中,可能只有几百笔是欺诈交易。

这个来自GitHub的可视化清晰地展示了信用卡欺诈数据的分布特征。我们可以看到,正常交易和欺诈交易在多个维度上都存在明显的差异。
在这个场景中,每种异常检测技术都有其独特的价值:
- 统计方法能够快速识别金额异常的交易
- KNN能够发现时间和地点异常的交易模式
- LOF能够在不同消费水平的用户群体中公平地识别异常
- 孤立森林能够快速处理大量交易数据
- 自编码器能够学习复杂的交易模式并识别微妙的异常行为
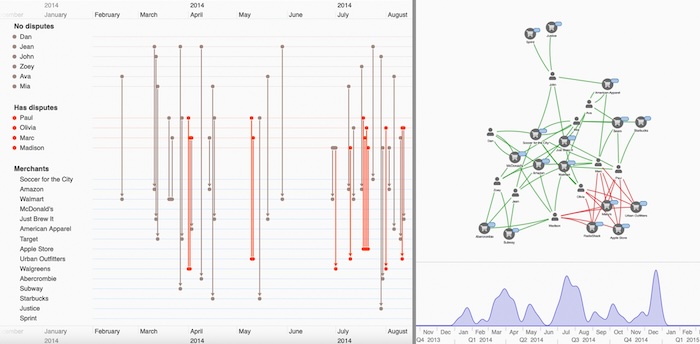
这个网络可视化展示了如何通过关系分析来发现欺诈模式。通过分析账户之间的转账关系,我们能够识别出可疑的资金流向。
评估的艺术:Precision-Recall曲线
在异常检测的世界里,评估模型性能是一门精细的艺术。传统的准确率指标在极度不平衡的数据中会完全失效。
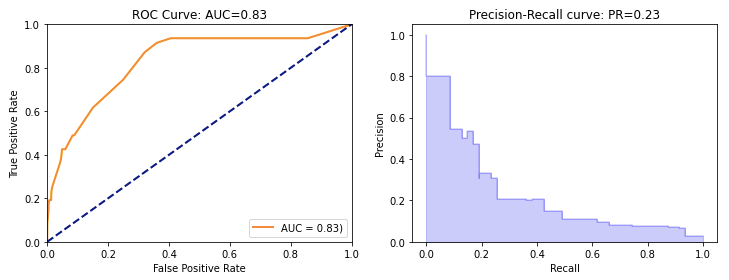
Precision-Recall曲线成为了异常检测中最重要的评估工具。Precision(精确率)回答"我标记的异常中有多少是真的异常",Recall(召回率)回答"所有真正的异常中我找到了多少"。

这个对比图清晰地展示了为什么在不平衡数据中PR曲线比ROC曲线更有意义。在异常检测场景中,PR曲线能够更准确地反映模型的真实性能。
在实际应用中,不同的场景对精确率和召回率有不同的要求:
- 医疗诊断:我们宁愿容忍一些误报(低精确率),也要确保不漏掉真正的疾病(高召回率)
- 垃圾邮件检测:我们更希望精确率高一些,避免将重要邮件误判为垃圾邮件
- 金融欺诈检测:需要在两者之间找到平衡,既要抓住欺诈,又要避免过多的误报
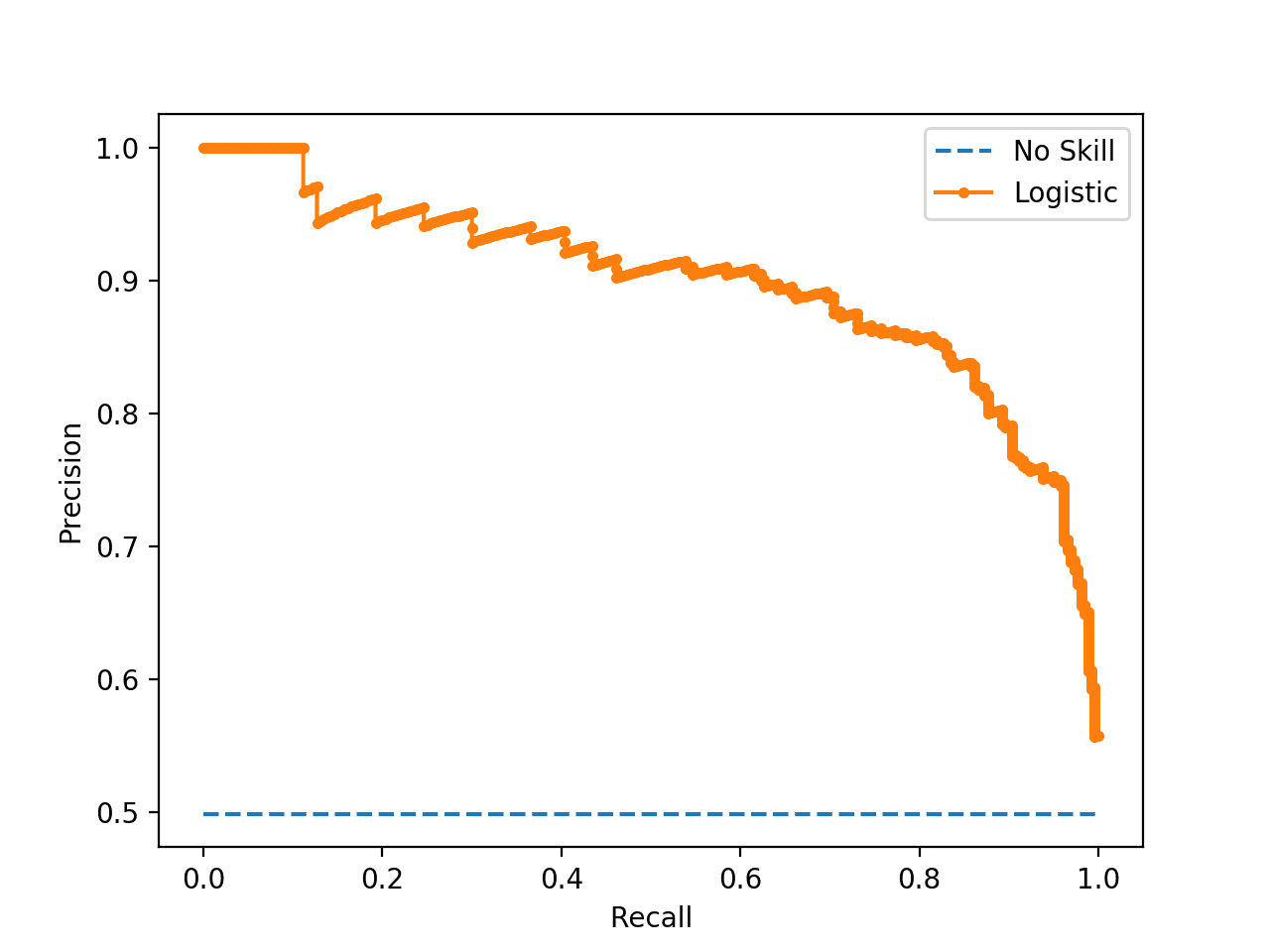
这个来自Machine Learning Mastery的图表展示了如何使用PR曲线来评估模型性能。理想的模型应该在图表的右上角,表示既有高精确率又有高召回率。
技术选择的智慧与未来展望
在异常检测的技术选择上,没有一招鲜吃遍天的神功。每种方法都有其适用的场景和局限性:
统计方法(3-Sigma、箱线图):
- ✅ 简单高效,计算成本低
- ✅ 结果易于解释
- ❌ 假设数据服从特定分布
- ❌ 对复杂模式识别能力有限
距离方法(KNN):
- ✅ 直观易懂,无分布假设
- ✅ 适合多维数据
- ❌ 在高维数据中面临"维度诅咒"
- ❌ 计算复杂度较高
密度方法(LOF):
- ✅ 能处理不同密度的数据簇
- ✅ 局部异常检测能力强
- ❌ 参数选择影响大
- ❌ 需要领域知识和经验
孤立森林:
- ✅ 大规模、高维数据表现优异
- ✅ 训练速度快,线性时间复杂度
- ❌ 对复杂异常模式敏感度有限
- ❌ 随机性可能影响稳定性
自编码器:
- ✅ 能学习复杂的数据表示
- ✅ 在图像、文本等复杂数据上效果突出
- ❌ 需要大量训练数据和计算资源
- ❌ 模型可解释性较差
在实际应用中,最佳策略往往是构建一个多层次的异常检测系统:先用统计方法进行快速筛选,再用机器学习方法进行精细分析,最后用深度学习方法处理复杂场景。
未来的发展趋势包括:
-
实时检测能力提升:随着边缘计算和5G技术的发展,异常检测系统将能更快响应异常事件
-
可解释性增强:新的研究正在探索如何让深度学习模型更加透明和可解释
-
多模态数据融合:如何有效融合文本、图像、时间序列等不同类型的数据
-
自适应学习:模型能够随着数据分布的变化自动调整检测策略
异常检测技术就像数据世界里的守护者,它们默默守护着我们的数字生活。从防范金融欺诈到保护网络安全,从监控工业设备到诊断医疗疾病,这些技术正在改变着我们的世界。
在这个数据驱动的时代,掌握异常检测技术不仅是技术人员的必备技能,也是我们理解和改善世界的重要工具。每一个异常数据点背后,都可能隐藏着一个重要的故事——而我们,就是这些故事的发现者和讲述者。