当我第一次接触机器学习时,总以为模型本身就是全部的魔法。就像一个孩子拿到新玩具一样,急不可耐地想要看到神经网络、随机森林这些酷炫算法的威力。然而,在经历了无数次模型调参失败后,我才真正理解了那句在数据科学界流传甚广的金句:"Garbage in, garbage out"(垃圾进,垃圾出)。
网页版:https://www.genspark.ai/api/page_private?id=nyiqpusx
视频版:https://www.youtube.com/watch?v=lBTje3fSJqo
音频版:https://notebooklm.google.com/notebook/e7dc554b-d1df-4d4b-839d-a80dc6b05fab/audio

这就像是一位大厨想要做出美味佳肴,却忽略了食材的重要性。再精湛的烹饪技艺,如果食材本身就有问题,最终的菜品也难以令人满意。在机器学习的世界里,特征工程就是那位负责精选和处理食材的大厨,而算法模型只是负责烹饪的厨具。
据Built In的研究显示,数据科学家将80%的时间花费在数据预处理和特征工程上,只有20%的时间用于实际的模型构建和调优。这个比例清楚地说明了特征工程在整个机器学习流程中的核心地位。就如同建筑师在设计建筑时,需要花费大量时间在地基和结构设计上,而不仅仅是外观装饰。
特征选择:三剑客的较量
特征选择就像是从一堆宝石中挑选出最珍贵的那些。在机器学习中,我们面临的往往不是特征太少的问题,而是特征太多、太杂乱的困扰。想象一下,如果你要从1000个特征中找出真正有用的50个,该如何下手?
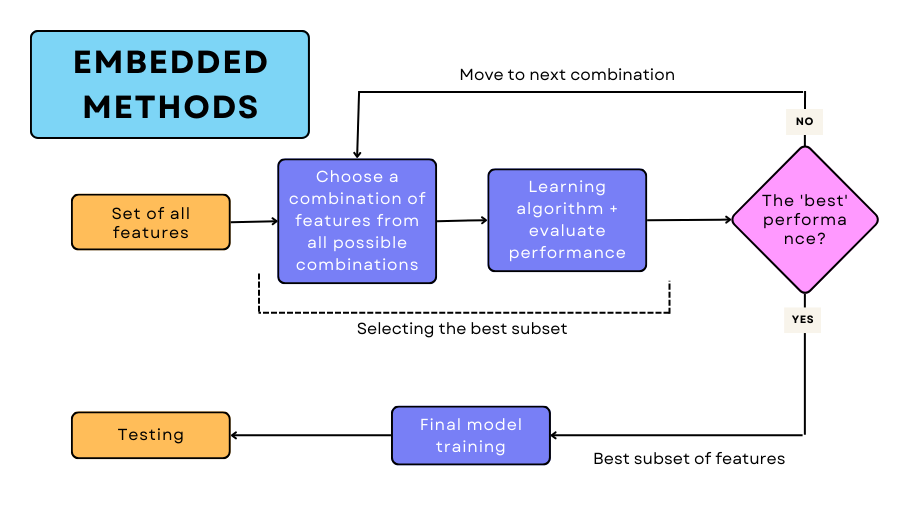
这时候就需要我们的三位特征选择大师出场了:过滤法(Filter)、包裹法(Wrapper)和嵌入法(Embedded)。
过滤法:独立思考的理性派
过滤法就像是一位独立的审计师,它不依赖任何特定的机器学习算法,而是根据特征本身的统计特性来做判断。它会计算每个特征与目标变量之间的相关性、互信息或者卡方统计量,然后根据这些指标来决定保留哪些特征。
根据Medium上的深度分析,过滤法的最大优势在于计算速度快,特别适合处理高维数据。就像一个经验丰富的珠宝鉴定师,能够快速地从一堆原石中挑出有价值的宝石,而不需要经过复杂的加工过程来验证。
包裹法:实战验证的经验派
包裹法则像是一位实践派的教练,它会实际训练模型来评估特征子集的价值。这种方法虽然计算成本较高,但能够考虑特征之间的相互作用,往往能得到更准确的结果。
最典型的包裹法包括前向选择、后向消除和递归特征消除(RFE)。想象你是一支足球队的教练,前向选择就像是逐个试用球员,看哪个组合效果最好;后向消除则是从全队开始,逐个淘汰表现不佳的球员;而递归特征消除就像是不断地重新评估和调整阵容,直到找到最佳配置。
嵌入法:智能平衡的中庸派
嵌入法可以说是前两者的完美融合,它在模型训练过程中同时进行特征选择。像LASSO回归、决策树这样的算法天生就具备特征选择的能力。LASSO通过L1正则化来自动将不重要特征的系数压缩为零,而决策树在分裂节点时会自然地选择最有区分度的特征。
这就像是一位智慧的武术大师,在练功的过程中自然而然地掌握了哪些招式最有效,哪些可以舍弃,实现了"练武"和"选招"的完美统一。
特征构造:创造力的艺术展现
如果说特征选择是在做减法,那么特征构造就是在做加法,而且是富有创造性的加法。这个过程就像是一位艺术家从原始的颜料中调配出新的色彩,或者像化学家通过反应创造出新的化合物。
多项式特征:捕捉非线性的魅力
线性关系在现实世界中往往是理想化的假设。更多时候,变量之间存在着复杂的非线性关系。多项式特征就是我们捕捉这种非线性关系的法宝。
比如在房价预测中,房屋面积与价格的关系很可能不是简单的线性关系。当面积从100平米增加到200平米时,价格的增幅可能比从50平米增加到100平米时更大。通过构造面积的平方项、立方项,我们就能更好地捕捉这种递增的效应。
根据Scikit-learn的官方文档,多项式特征的构造可以显著提升模型在非线性数据上的表现,但需要注意的是,特征数量会呈指数级增长,因此在高维数据上需要谨慎使用。
交互特征:发现隐藏的化学反应
有时候,单独的特征可能没什么特别,但当它们结合在一起时,就会产生神奇的效果,就像化学反应中的催化剂。
在电商推荐系统中,单独的"用户年龄"和"商品类别"可能都不足以准确预测购买行为,但"年轻用户×电子产品"这个交互特征就能很好地捕捉到年轻人偏爱数码产品的趋势。
在Kaggle竞赛中,很多获胜者都提到了交互特征的重要性。特征工程专家在Medium上分享的经验表明,巧妙构造的交互特征往往是模型性能突破的关键所在。
特征变换:数据的标准化舞蹈
特征变换就像是为不同身高的演员准备统一的舞台,让每个特征都能在同一个尺度上"起舞"。想象一下,如果让一个身高1.5米的人和一个身高2米的人在同一个舞台上表演,没有适当的调整,效果肯定会很奇怪。
归一化与标准化:统一的标尺
归一化(Min-Max Scaling)就像是把所有数据压缩到0到1之间的统一区间,就好比把所有演员都调整到相似的身高范围。而标准化(Z-score Normalization)则是围绕均值和标准差进行调整,更像是根据每个演员的相对表现来调整他们的位置。
根据Analytics Vidhya的深度分析,在距离敏感的算法(如KNN、K-means聚类)中,特征缩放是必不可少的。想象一下,如果用欧几里得距离来衡量相似性,而其中一个特征的数值范围是0-1,另一个是0-10000,那么后者会完全主导距离计算,这显然是不合理的。
编码艺术:类别变量的数字化转换
在机器学习的世界里,算法只认识数字,不认识文字。但现实世界中充满了各种类别信息:性别、城市、产品类型等等。如何将这些"文字"转换成"数字",就是编码的艺术所在。
独热编码:每个类别都有自己的舞台
独热编码(One-Hot Encoding)为每个类别分配一个独立的二进制位。就像给每个演员分配一个专属的聚光灯,当某个演员上台时,只有他的灯亮着,其他都是暗的。
对于"性别"这个特征,我们不会简单地用1代表男性、0代表女性,因为这暗示了男性"大于"女性。相反,我们创建两个新特征:"是否男性"和"是否女性",用[1,0]表示男性,[0,1]表示女性。
标签编码:简单粗暴的排队
标签编码(Label Encoding)则更加直接,就像给队伍中的每个人分配一个号码。这种方法适用于具有自然顺序的类别变量,比如教育程度(小学=1,中学=2,大学=3)。
GeeksforGeeks的比较研究指出,选择编码方法需要考虑特征的性质:对于有序类别变量,标签编码更合适;对于无序类别变量,独热编码是更好的选择。
文本特征提取:将文字变成数字的炼金术
文本数据就像是一座巨大的图书馆,里面蕴含着丰富的信息,但机器学习算法却无法直接"阅读"这些文字。我们需要一套炼金术,将文字转换成数字,让机器能够理解和处理。
词袋模型:简单粗暴的统计法
词袋模型(Bag of Words)是最直观的文本表示方法,就像是把一篇文章撕碎,然后统计每个词出现的次数。虽然丢失了词语的顺序信息,但却捕获了词频信息。
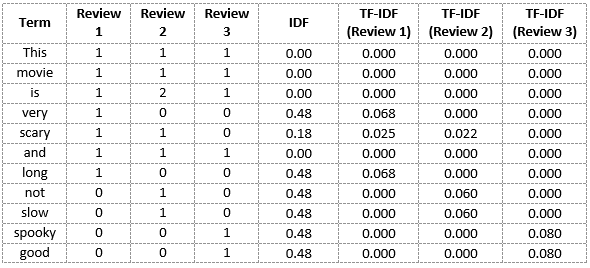
想象三个电影评论:
- 评论1:This movie is very scary and long
- 评论2:This movie is not scary and is slow
- 评论3:This movie is spooky and good
词袋模型会创建一个包含所有独特词汇的词典,然后用向量表示每个评论中各词的出现次数。Analytics Vidhya的详细教程展示了这个过程的具体实现。
TF-IDF:聪明的权重分配师
TF-IDF(Term Frequency-Inverse Document Frequency)就像是一位聪明的权重分配师,它不仅考虑词语在当前文档中的频率,还考虑这个词语在整个语料库中的稀有程度。
如果一个词在某篇文档中频繁出现,但在其他文档中很少出现,那么这个词对于区分这篇文档就很有价值,应该给予更高的权重。反之,如果一个词在所有文档中都频繁出现(比如"的"、"是"、"和"),那么它的区分价值就不高。
TF-IDF的计算公式体现了这种智慧:
- TF(词频)= 某词在文档中出现次数 / 文档总词数
- IDF(逆文档频率)= log(文档总数 / 包含该词的文档数)
- TF-IDF = TF × IDF
这就像是在评估一个人的特殊技能:如果这个技能既是他的强项(在他的技能组合中频繁使用),又是稀缺的(其他人很少具备),那么这个技能就特别有价值。
N-grams:捕捉词语间的亲密关系
虽然词袋模型和TF-IDF都很有用,但它们都忽略了词语之间的顺序关系。这就像是把一句优美的诗歌打散重组,意思可能完全变了。
N-grams技术通过考虑连续的N个词来部分解决这个问题。Medium上的专业分析表明,2-grams(bigrams)和3-grams(trigrams)在很多NLP任务中都能显著提升性能。
比如对于句子"This movie is not good":
- 1-grams: [This, movie, is, not, good]
- 2-grams: [This movie, movie is, is not, not good]
- 3-grams: [This movie is, movie is not, is not good]
通过N-grams,我们能够捕捉到"not good"这样的否定表达,而不会被单独的"good"误导。
缺失值处理:数据的修补艺术
现实世界的数据就像是一幅有些地方被虫蛀的古画,总是存在各种缺失。如何处理这些"空白",需要相当的技巧和智慧。
简单填充:最朴素的修补方法
最直接的方法就是用均值、中位数或众数来填充缺失值。这就像是用相似的颜料来填补画作中的空白区域。对于数值型特征,我们通常用均值或中位数;对于类别型特征,我们用众数。
但这种方法有个明显的缺陷:它假设缺失值与其他观测值来自同一分布,这在现实中往往不成立。
模型预测填充:智能的推理修复
更先进的方法是使用机器学习模型来预测缺失值。我们可以将有缺失值的特征作为目标变量,用其他完整的特征来训练一个预测模型。
根据Nature上发表的研究,基于机器学习的缺失值填充方法在很多情况下都比简单填充有更好的效果,特别是当缺失机制比较复杂时。
这就像是请一位艺术专家来修复古画,他会根据画作的整体风格、色彩搭配和技法特点来推测空白部分应该是什么样子。
自动化特征工程:AI时代的智能助手
手工进行特征工程就像是用手工制作精美的工艺品,虽然精细,但效率有限。随着数据量的爆炸式增长,我们需要更智能的工具来帮助我们。
Featuretools:自动化的魔法工具
Featuretools就像是特征工程界的瑞士军刀,它能够自动生成数千个候选特征。通过深度特征合成(Deep Feature Synthesis)技术,它可以自动发现特征之间的复杂关系。
Kaggle上的自动化特征工程教程展示了Featuretools如何在几分钟内生成上千个特征,其中很多是人工很难想到的巧妙组合。
想象一个电商数据集,包含用户信息、订单信息和商品信息。Featuretools能够自动生成诸如"用户在过去30天内购买的平均商品价格"、"用户最常购买的商品类别"等复杂特征,而这些特征的手工构造可能需要大量的时间和经验。
AutoML的特征工程模块
现代的AutoML平台都内置了自动化特征工程模块。它们不仅能够自动生成特征,还能自动选择最有用的特征组合。这就像是有了一个经验丰富的数据科学团队在后台工作,而你只需要提供原始数据和目标。
特征工程的哲学思考
在我多年的数据科学实践中,我越来越意识到特征工程不仅仅是一项技术活动,更是一种思维方式。它要求我们深入理解业务问题,洞察数据背后的规律,并将这些洞察转化为算法能够理解的语言。
优秀的特征工程师就像是一位出色的翻译家,能够在人类的直觉理解和机器的数学逻辑之间架起桥梁。当我们构造一个新特征时,我们实际上是在告诉算法:"这是一个重要的模式,你应该关注它。"
"Garbage in, garbage out"这句话的深层含义在于:无论算法多么先进,如果输入的特征质量不高,模型的性能就会受限。相反,如果我们能够提供高质量、信息丰富的特征,即使是简单的算法也能达到令人惊喜的效果。
在这个AI日益普及的时代,自动化工具确实能够帮助我们提高效率,但人类的洞察力和创造力仍然是不可替代的。最好的特征往往来自于对业务的深度理解和对数据的敏锐洞察,这正是人类智慧的体现。
特征工程的艺术在于平衡:在自动化与手工制作之间,在复杂性与可解释性之间,在性能提升与计算成本之间。掌握这种平衡,正是成为优秀数据科学家的必经之路。
就像学习任何一门艺术一样,特征工程需要大量的练习和积累。每一个项目都是一次学习的机会,每一次失败都是成长的阶梯。在这个数据驱动的时代,让我们一起在特征工程的道路上不断探索,创造出更多智能的可能。
精美网页已创建完成!
🌐 在线访问: https://gexumxct.gensparkspace.com/
这个网页采用了现代化的Bento Grid设计,融合阿里巴巴官网的主题色彩,包含了特征工程的核心技术要点,并配有精美的交互动效和数据可视化图表。
📱 网页特色:
- 响应式设计,支持多设备访问
- 动态滚动效果,增强用户体验
- 专业图标和配色方案
- 结构化内容展示
- 高清技术图表和可视化