想象一下,你正在阅读一本引人入胜的小说。当你读到第300页的时候,突然发现自己完全忘记了前面章节的重要线索——这种感觉是不是很糟糕?这正是传统Transformer模型在处理长文本时面临的尴尬处境。
网页版:https://www.genspark.ai/agents?id=26ccdbcf-6a50-4dde-b9d2-c77516afd3d5
视频版:https://www.youtube.com/watch?v=8ySVR8ajQVw

在自然语言处理的世界里,标准Transformer就像一位患有短期记忆障碍的学者。它聪明、高效,能够理解句子间的复杂关系,但有一个致命的弱点:它只能"记住"固定长度的上下文,通常是512个词汇。当文档超过这个长度时,它就不得不把文本切成一段段的"记忆碎片",每次只能看到其中的一小部分。
被束缚的注意力机制
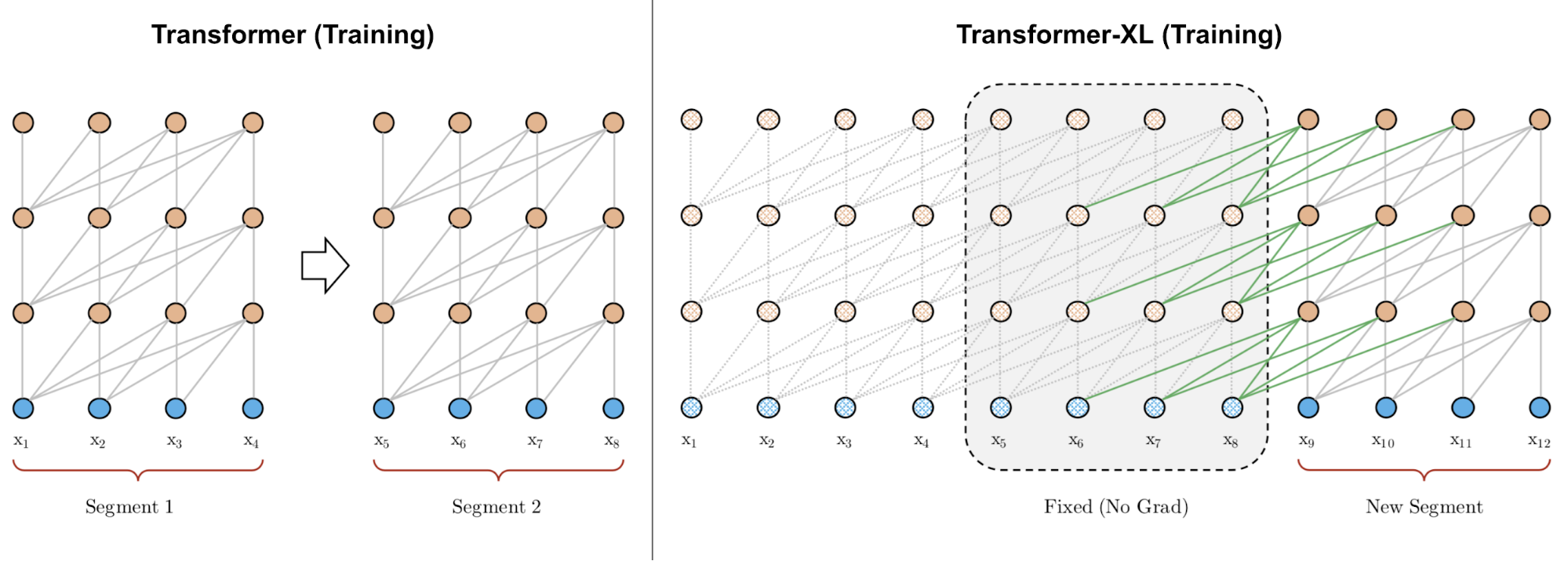
传统Transformer的困境来自于一个看似简单却影响深远的技术限制。在标准的Transformer架构中,自注意力机制的计算复杂度是O(n²),其中n是序列长度。这意味着随着文本长度的增加,计算量会呈平方级增长。更糟糕的是,每个文本段落都被独立处理,就像把一本完整的书撕成碎页,让读者无法理解前后文的逻辑关系。
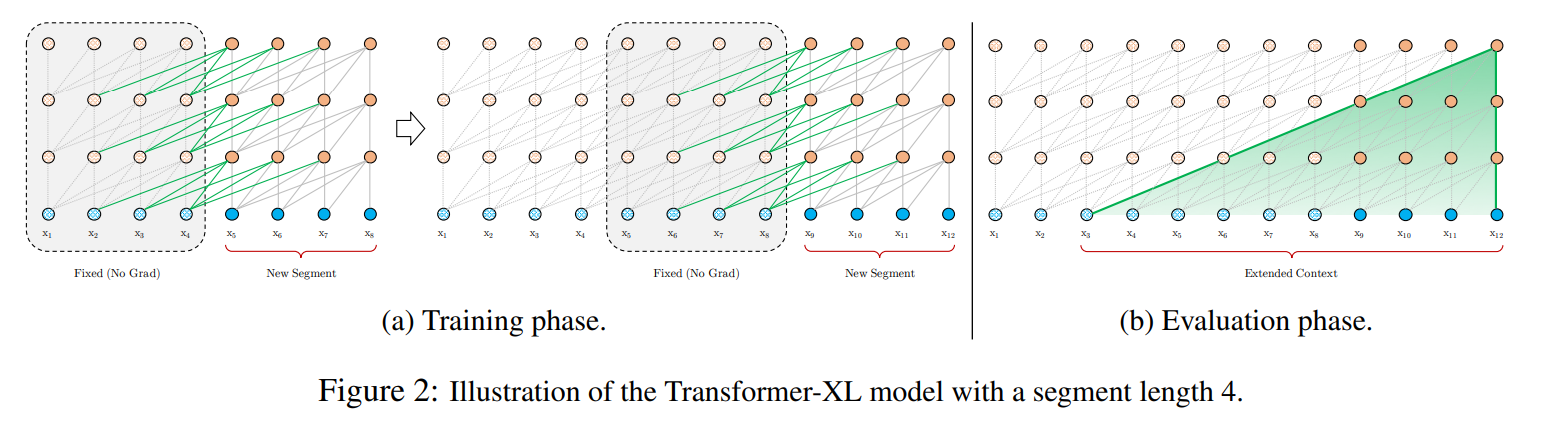
这种设计导致了两个核心问题:首先是上下文碎片化(Context Fragmentation)问题。当一个句子恰好被切断在两个段落的边界时,模型无法理解这个句子的完整含义。其次是有限的依赖建模能力,模型无法捕捉超出固定窗口长度的长距离依赖关系。
Transformer-XL的记忆突破
就在研究者们为这个技术瓶颈苦恼不已时,来自Google Research和CMU的研究团队在2019年提出了Transformer-XL,这个名字中的"XL"代表"eXtra Long",寓意着对超长序列的处理能力。

Transformer-XL的核心创新在于引入了段级循环机制(Segment-Level Recurrence Mechanism)。这就像给那位健忘的学者配备了一本详细的笔记本,让他能够在阅读新章节时随时翻阅之前记录的要点。
具体来说,当模型处理当前文本段时,它会将前一个段落的隐藏状态保存在一个"记忆缓存"中。这些隐藏状态包含了前一段文本的关键信息,可以在处理下一段文本时被重新调用。这样一来,模型的有效上下文长度就从原来的固定长度N扩展到了N×L,其中L是网络的层数。
相对位置编码的巧妙设计
但仅仅引入段级循环还不够。传统的绝对位置编码在这种设计下会产生混乱:想象一下,如果两个文本段都从位置0开始编码,模型如何区分它们的前后顺序?
Transformer-XL引入了相对位置编码(Relative Positional Encoding)来解决这个问题。与其告诉模型每个词的绝对位置,不如告诉它词与词之间的相对距离。就像在地图上,比起说"我在经度120.5度,纬度30.2度",说"我在你的北边500米"往往更有用。
这种相对位置编码不仅解决了段间位置连贯性的问题,还带来了意外的好处:模型能够更好地泛化到训练时未见过的序列长度。数学上,这种编码方式将注意力计算从:
Attention(Q, K, V) = softmax(QK^T / √d)V
修改为考虑相对位置关系的形式,其中包含了专门的相对位置嵌入项。
令人震撼的性能飞跃
Transformer-XL的实验结果简直可以用"震撼"来形容。在多个基准测试中,它都取得了显著的性能提升:
- 依赖建模能力:比循环神经网络(RNN)长80%,比标准Transformer长450%
- 计算效率:在评估阶段比标准Transformer快1800多倍
- 困惑度指标:在enwiki8数据集上从1.06提升到0.99,首次突破1.0的障壁
- WikiText-103性能:困惑度从20.5大幅改善到18.3
- 处理能力:可处理多达6400个token的序列,相比标准Transformer的512个提升了12.5倍
这些数字背后代表着什么?以文档摘要任务为例,标准Transformer只能"看到"文档的一小部分就要做出摘要,而Transformer-XL则能够纵览整个文档,生成更加连贯和准确的摘要。
从实验室到现实世界
Transformer-XL的创新很快就从学术论文走向了实际应用。在长文档分析领域,法律文书处理系统使用Transformer-XL来理解跨越数十页的合同条款之间的关联关系。在对话系统中,它能够记住更长的对话历史,提供更加连贯和个性化的回应。
在创意写作方面,仅在WikiText-103数据集上训练的Transformer-XL就能生成包含数千个词汇的连贯文章,这在以前是不可想象的。这些生成的文本不仅在局部保持了语法正确性,在全局也展现了令人印象深刻的逻辑一致性。
技术细节的深度解析
从技术实现的角度来看,Transformer-XL的段级循环机制可以用以下数学表达式来描述:
h_τ+1^(n) = Transformer-Layer(h_τ+1^(n-1), [SG(m_τ^(n-1)); h_τ+1^(n-1)])
其中,m_τ^(n-1)表示前一段的记忆缓存,SG表示停止梯度操作,确保梯度不会回传到前一段。这种设计既保证了信息的前向传递,又维持了训练的稳定性。
相对位置编码的核心在于将绝对位置信息替换为相对距离信息。对于位置i和j之间的注意力计算,模型使用R_{i-j}来表示它们的相对位置关系,而不是分别的绝对位置P_i和P_j。
架构创新的深远影响
Transformer-XL的出现不仅仅是一个技术改进,它更代表了一种新的设计思路:如何在保持并行计算优势的同时,融入序列记忆机制。这种思路后来启发了许多其他的长序列处理模型,包括Reformer、Longformer等。
更重要的是,它验证了一个重要的假设:在深度学习中,记忆机制和注意力机制并不是互斥的,而是可以巧妙结合的。这为后续的大语言模型设计提供了重要的启示。
面向未来的思考
随着大语言模型规模的不断扩大,处理超长序列的能力变得越来越重要。想象一下,未来的AI助手需要理解整本教科书、完整的代码库,或者长达数小时的会议记录。Transformer-XL开创的技术路径为实现这些目标提供了重要的基础。
当我们回顾Transformer-XL的技术贡献时,会发现它不仅解决了当时的技术痛点,更重要的是开启了一扇通向"真正理解长文本"的大门。就像那位获得了完美记忆能力的学者,AI模型也终于可以在理解长文本时保持前后连贯的逻辑思维。
在信息爆炸的时代,这样的技术突破显得尤为珍贵。它让机器不再是处理文本片段的工具,而是成为了真正能够理解长篇内容的智能伙伴。