想象一下,你走进一家书店,店主只需要看一眼你的购买记录,就能准确地推荐你可能喜欢的下一本书。这听起来像魔法,但实际上,这正是现代推荐系统每天都在数字世界中执行的任务。从Netflix的电影推荐到Amazon的商品建议,从Spotify的音乐播放列表到抖音的视频流,推荐系统已经悄然成为我们数字生活中最重要的"隐形助手"。
网页版:https://www.genspark.ai/api/page_private?id=fylvsdpp
视频版:https://www.youtube.com/watch?v=_SJEYteqpAo
协同过滤:数字时代的"物以类聚,人以群分"
协同过滤的核心思想简单而优雅:相似的用户会喜欢相似的物品。这就像是数字版的"物以类聚,人以群分"。IBM的研究表明,协同过滤系统使用用户-物品矩阵来映射每个用户对系统中每个物品的行为,然后通过向量空间中的距离度量来计算用户间或物品间的相似性。
用户协同过滤:寻找你的"数字双胞胎"
用户协同过滤的工作原理就像在人群中寻找你的"数字双胞胎"。如Carlos Pinela在Medium上解释的那样,假设你想为朋友Stanley推荐一部电影。如果你发现Stanley和你看过相同的电影,并且评分几乎相同,那么当你喜欢《教父2》而Stanley还没看过时,系统就会合理地推测Stanley也会喜欢这部电影。
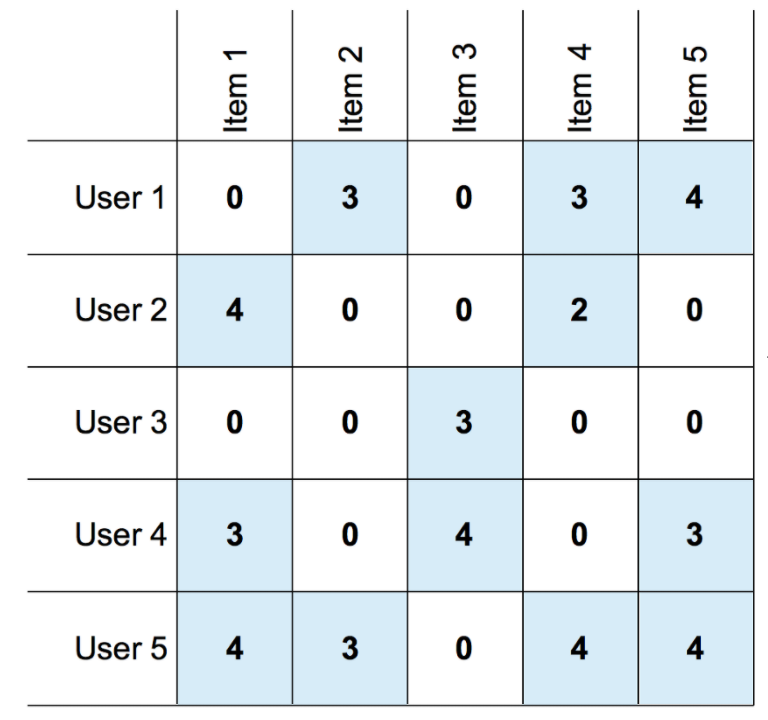
这种方法的数学基础依赖于相似性度量,最常用的包括余弦相似度和皮尔逊相关系数。余弦相似度测量两个向量之间的角度,取值范围在-1到1之间,分数越高表示两个用户越相似。
物品协同过滤:从用户行为中发现物品的"DNA"
与用户协同过滤不同,物品协同过滤关注的是物品之间的相似性。它不是通过物品的内容特征来比较,而是通过用户对这些物品的交互行为来判断相似性。
比如在电影推荐系统中,算法可能会发现用户对《教父》和《疤面煞星》的评分存在很强的相关性。当一个用户给这两部电影都打了高分,但还没有看过《好家伙》时,如果其他有相似评分模式的用户也给《好家伙》打了高分,系统就会向这个用户推荐《好家伙》。
矩阵分解:化繁为简的数学魔法
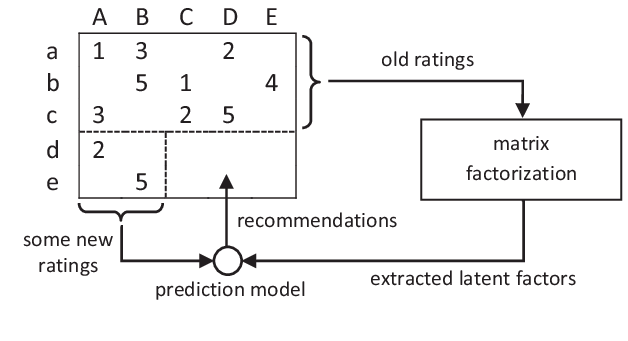
当用户-物品矩阵变得庞大且稀疏时,传统的协同过滤方法就显得力不从心。这时,矩阵分解技术就像是一位神奇的数学魔术师,能够将复杂的用户-物品关系分解为更简洁的低维表示。
奇异值分解(SVD):推荐系统的数学心脏
奇异值分解是矩阵分解家族中最著名的成员。正如Towards Data Science上详细解释的那样,SVD的基本思想是将用户-物品矩阵M分解为三个矩阵的乘积:M = UΣV^T,其中U代表用户的潜在特征,Σ包含特征的重要性权重,V^T代表物品的潜在特征。
这种分解的威力在于它能够发现隐藏的模式。例如,在音乐推荐中,这些潜在因子可能代表音乐风格(摇滚vs古典)、时代(现代vs复古)或情感色彩(欢快vs忧郁)。用户和歌曲在这些潜在维度上的投影就成为了预测用户偏好的基础。
非负矩阵分解(NMF):保持非负性的优雅分解
NMF在SVD的基础上增加了非负性约束,要求分解得到的矩阵U和V中的所有元素都为非负数。这种约束在某些场景下更有意义,比如在推荐系统中,用户对物品的隐性反馈(如购买次数、播放时长)本身就是非负的。
深度学习:推荐系统的智能革命
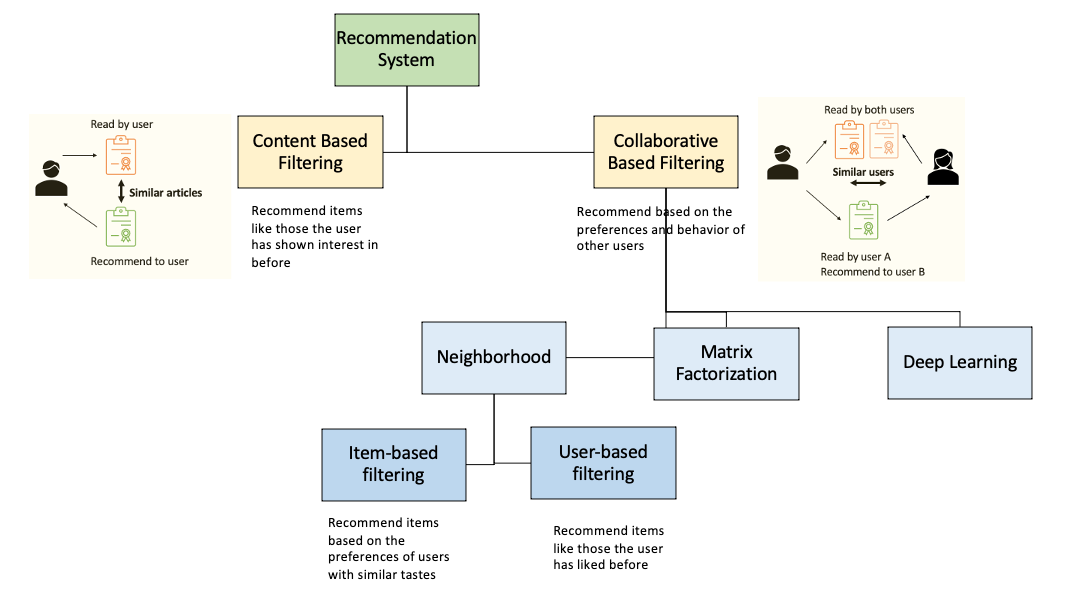
随着深度学习技术的兴起,推荐系统迎来了新的革命。NVIDIA的研究表明,神经网络能够捕捉用户和物品之间更复杂的非线性关系,从而产生更准确的推荐。
嵌入(Embedding):将离散转为连续的艺术
嵌入技术是深度学习推荐系统的核心。它将离散的用户ID和物品ID转换为稠密的向量表示。就像将每个用户和每个物品都分配了一个"数字指纹",这些指纹包含了丰富的语义信息。Google的机器学习文档详细介绍了这种技术如何处理高维稀疏数据。
相似的用户会在嵌入空间中距离较近,相似的物品也是如此。这种表示方式不仅解决了传统协同过滤中的稀疏性问题,还能够捕捉更复杂的用户-物品关系。
多层感知机(MLP):深度特征学习的基石
多层感知机在推荐系统中扮演着特征学习的角色。它能够自动学习用户和物品特征的高阶交互,发现传统方法难以捕捉的复杂模式。一项关于深度学习推荐系统的综述指出,虽然MLP可能不如自编码器、CNN或RNN那样表达力强,但其简单高效的特点使其成为许多实际应用的首选。
自编码器:重构中发现偏好
自编码器在推荐系统中的应用特别有趣。它试图重构用户的评分向量,在这个过程中学习到用户偏好的低维表示。AutoRec模型就是这种思想的典型代表,它将用户的评分向量作为输入,通过编码器压缩到低维空间,再通过解码器重构原始评分。
这种"先压缩再重构"的过程迫使网络学习到最重要的用户偏好特征,从而能够为用户的未评分物品生成预测。
生成对抗网络(GAN):对抗中提升推荐质量
GAN在推荐系统中的应用还相对较新,但已经显示出巨大潜力。生成器试图生成用户可能喜欢的物品,而判别器则试图区分真实偏好和生成偏好。这种对抗训练过程能够产生更加多样化和创新性的推荐。
冷启动问题:推荐系统的"鸡生蛋"难题
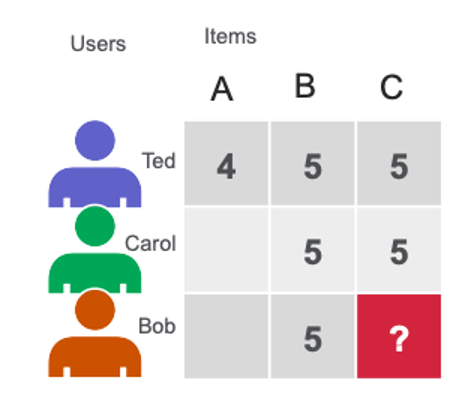
冷启动问题是推荐系统面临的经典挑战。研究表明,当新用户进入系统时,由于缺乏历史交互数据,系统无法准确判断其偏好;同样,新物品也因为缺乏用户反馈而难以被推荐。
解决冷启动问题的策略包括:
- 内容信息利用:利用用户的人口统计信息或物品的内容特征
- 流行度推荐:为新用户推荐热门物品
- 主动学习:通过问卷调查等方式快速收集用户偏好信息
- 迁移学习:从相关领域转移知识来帮助新用户或新物品的推荐
多样性与探索:推荐系统的平衡艺术
优秀的推荐系统不仅要准确,还要具有多样性。用户需要在熟悉的内容和新奇发现之间找到平衡。这就像一个好的朋友,既会推荐你肯定喜欢的东西,也会偶尔建议你尝试一些新鲜事物。
多样性策略包括:
- 随机性注入:在推荐列表中加入随机元素
- 类别平衡:确保推荐物品涵盖多个类别
- 时间多样性:考虑用户在不同时间的不同需求
- 惊喜度优化:推荐用户意想不到但可能喜欢的物品
评估指标:衡量推荐质量的标尺
推荐系统的性能评估需要多维度的指标。Shaped的研究详细介绍了几个关键指标:
精确率和召回率:经典的二元评估
精确率(Precision)衡量推荐物品中用户真正喜欢的比例,召回率(Recall)衡量用户喜欢的物品中被成功推荐的比例。这两个指标反映了推荐系统的基本准确性。
归一化折损累积增益(NDCG):考虑排序的智能指标
NDCG不仅考虑推荐的准确性,还考虑排序的质量。它给予排名靠前的正确推荐更高的权重,这符合用户更关注推荐列表顶部物品的行为习惯。
平均精确率(MAP):综合考虑排序和精确度
MAP结合了精确率和排序位置的考量,为每个查询计算精确率,然后取平均值。它特别适合评估搜索和推荐系统的整体性能。
实现之路:从理论到代码的跨越
对于想要实践推荐系统的开发者,PyTorch和TensorFlow都提供了丰富的工具。神经协同过滤(Neural Collaborative Filtering, NCF)是一个很好的入门选择,它结合了矩阵分解和深度学习的优势。
实现的基本步骤包括:
- 数据预处理:构建用户-物品交互矩阵
- 模型构建:设计嵌入层和神经网络结构
- 损失函数设计:选择合适的优化目标
- 训练和验证:使用交叉验证评估模型性能
- 推荐生成:为目标用户生成个性化推荐
未来展望:推荐系统的智能演进
推荐系统正在向更加智能化的方向发展。强化学习开始被应用于推荐系统,将推荐过程建模为序贯决策问题。这种方法能够考虑用户的长期满意度,而不仅仅是短期点击率。
多模态推荐系统也在兴起,它们能够同时处理文本、图像、音频等多种类型的数据,为用户提供更加丰富和准确的推荐体验。
知识图谱的融入为推荐系统带来了更强的解释性和推理能力。通过理解实体之间的关系,推荐系统能够提供更有说服力的推荐理由。
推荐系统从简单的协同过滤发展到今天的深度学习驱动,经历了一场真正的智能革命。它不再只是一个冰冷的算法,而是一个能够理解用户需求、学习用户偏好、甚至预测用户未来兴趣的智能伙伴。在这个信息过载的时代,推荐系统正在成为连接用户与内容的重要桥梁,帮助我们在茫茫数据海洋中找到真正有价值的珍珠。