2020年,一个看似疯狂的想法在Google的研究实验室里诞生了。一群研究者决定做一件在当时看来"不合理"的事情:把专门处理文本的Transformer架构,直接应用到图像识别任务上。这就像是让一个从小只会读书的学霸,突然去参加绘画比赛一样不可思议。
网页版:https://www.genspark.ai/api/page_private?id=hvmkqjtt
视频版:https://www.youtube.com/watch?v=53hWoirb9g0
然而,正如历史上许多伟大的发现一样,最疯狂的想法往往能带来最出人意料的结果。这个想法最终催生了Vision Transformer (ViT)——一个彻底改变计算机视觉领域游戏规则的架构。
破局而生:从文本到图像的跨界思考
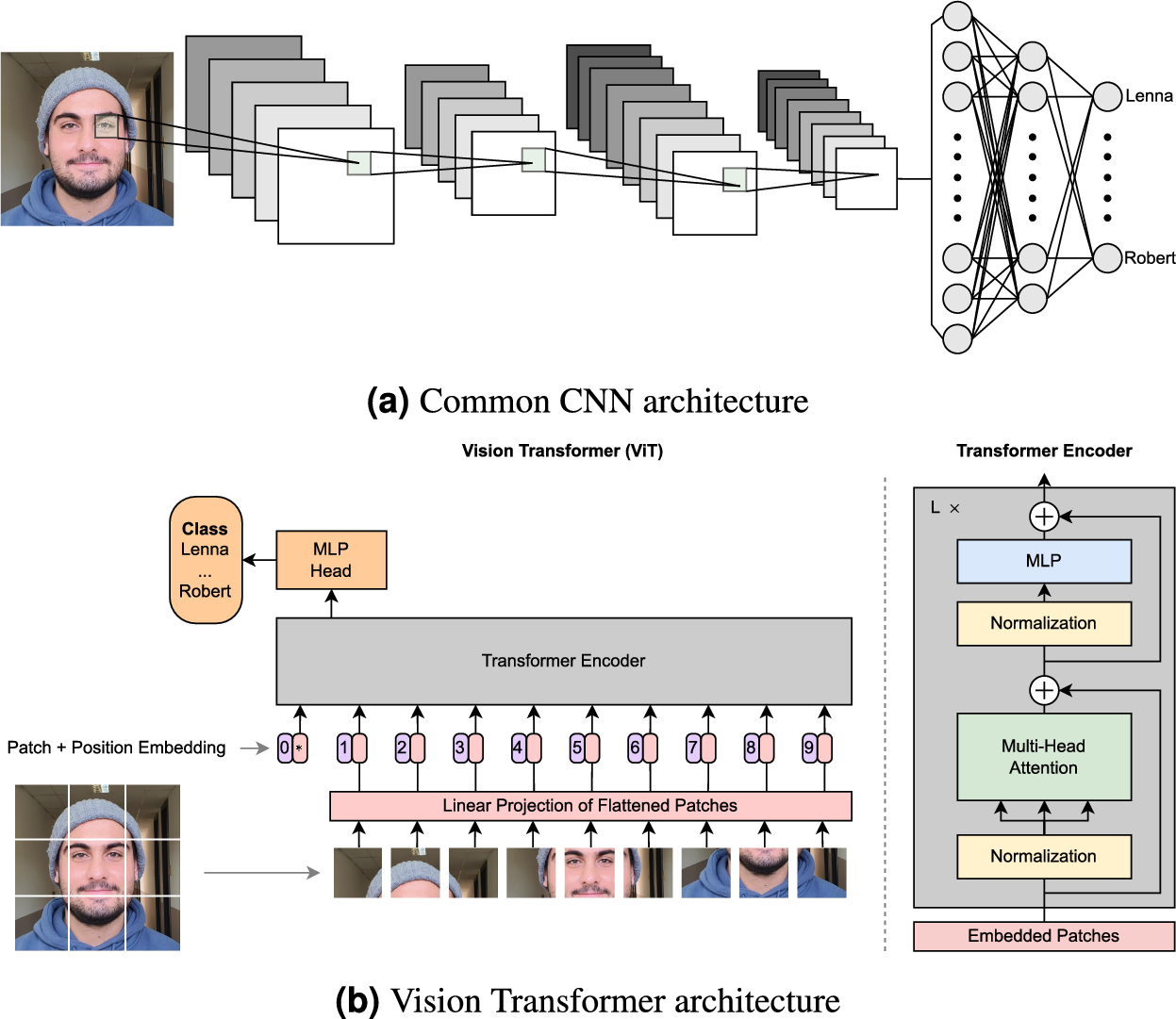
在ViT出现之前,计算机视觉领域几乎被卷积神经网络(CNN)完全统治。CNN就像是一个天生的"近视眼",它只能看到图像的局部区域,需要通过层层叠叠的卷积操作才能逐渐建立对整张图像的理解。
而Transformer在自然语言处理领域的成功,让研究者们开始思考:既然Transformer能够通过注意力机制捕捉文本中词语之间的长距离依赖关系,那么是否也能用来理解图像中像素之间的复杂关联呢?
关键的突破在于如何将二维的图像转换为一维的序列。研究者们想出了一个绝妙的解决方案:patch embedding。
Patch Embedding:化整为零的艺术

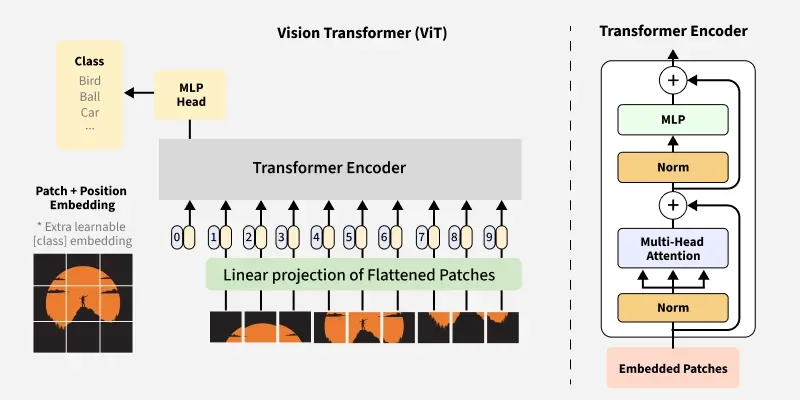
想象一下,你面前有一张1000块的拼图,如果要让一个只会处理一维序列的模型来理解这张拼图,你会怎么做?ViT的答案是:把拼图拆解成一个个小块,然后按顺序排列。
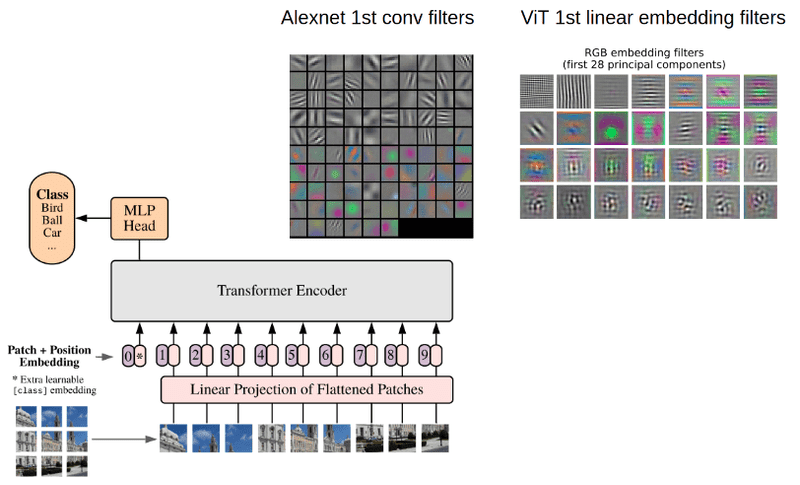
具体来说,ViT将一张224×224像素的图像切割成196个16×16像素的小方块(patches)。每个patch包含768个数值(16×16×3个RGB通道),然后通过一个线性变换将其映射到768维的向量空间。
这个过程就像是给每个拼图块贴上一个独特的"身份证",让原本杂乱无章的像素点变成了有序的数字序列。数据显示,这种patch-based的方法在ImageNet数据集上能够达到87.76%的top-1准确率,超越了当时最先进的CNN模型。
Class Token:整张图像的"代言人"
在所有patch序列的最前面,ViT引入了一个特殊的token——Class Token。这个token起初完全是随机初始化的,不包含任何图像信息,但它的使命却至关重要:成为整张图像的"代言人"。
通过Transformer的多层注意力机制,Class Token学会了如何从其他patch那里"收集情报"。它就像一个资深的情报分析师,能够综合来自图像各个区域的信息,最终做出准确的分类判断。
实验表明,经过训练的Class Token能够有效地聚合全局信息,其分类性能甚至超过了传统的全局平均池化方法。
全局视野:Attention机制的威力

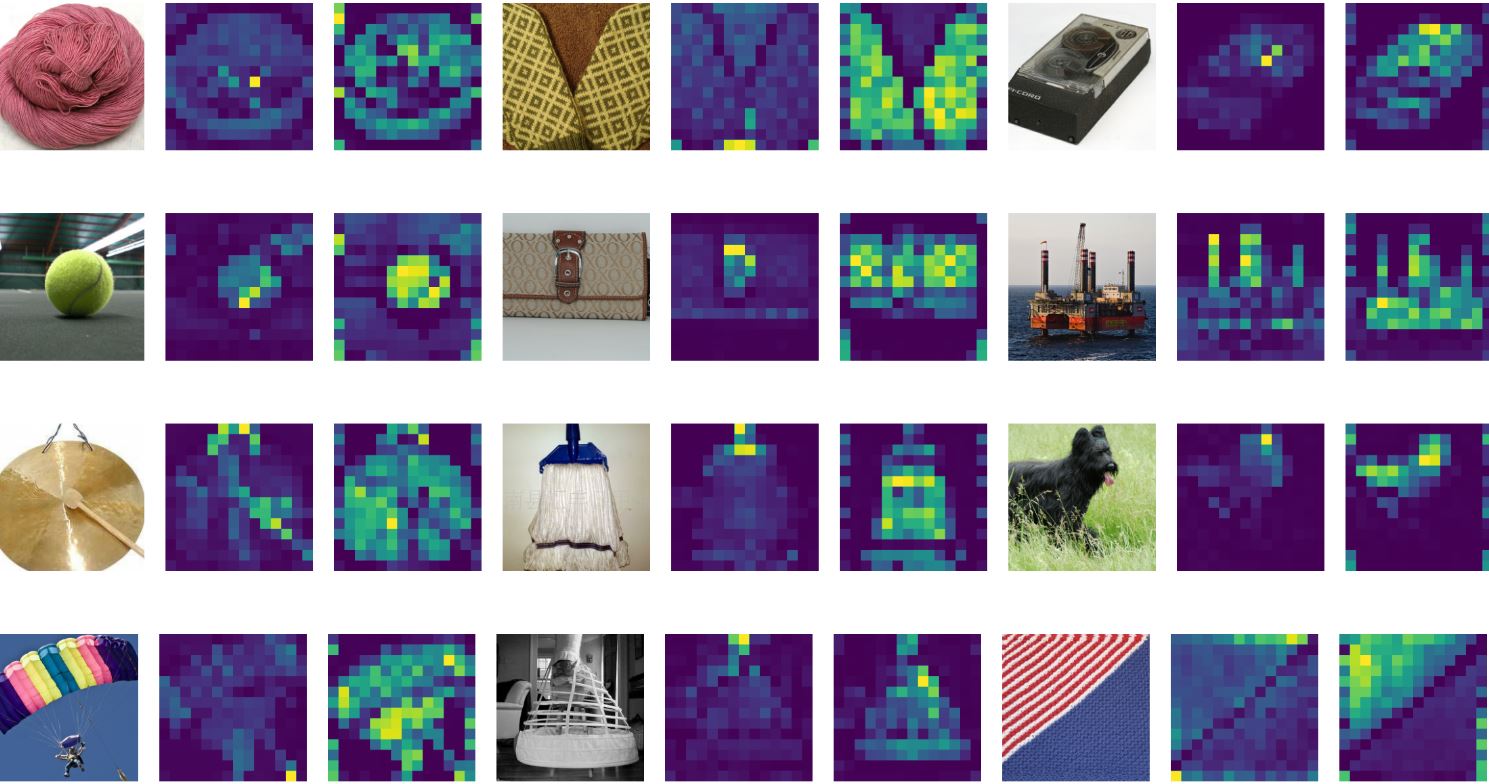
ViT最大的优势在于其全局注意力机制。与CNN需要通过多层感受野扩展才能建立长距离依赖不同,ViT从第一层开始就能让每个patch直接"看到"图像中的任何其他patch。
这种能力在处理需要全局理解的任务时表现尤为突出。比如在识别一只猫的时候,ViT可以同时关注猫的眼睛、耳朵和尾巴,即使它们在图像中相距很远。注意力权重的可视化显示,ViT确实学会了关注对象的关键部位,而不仅仅是局部特征。
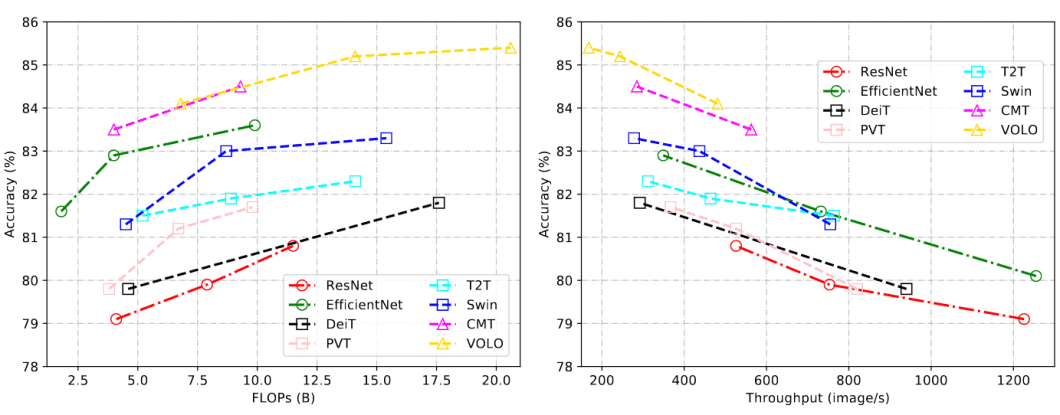
性能对比:新旧交替的见证
当我们将ViT与传统CNN进行详细对比时,结果展现出了复杂而有趣的模式:
数据规模的影响:在小规模数据集(如CIFAR-10)上,CNN往往表现更好,准确率可达95%以上,而ViT只能达到85%左右。但随着数据规模增加到ImageNet-21K这样的大规模数据集,ViT开始展现优势,准确率提升到87.76%,超越了同期的CNN模型。
计算效率对比:
- 训练阶段:ViT需要更多的GPU时间,但具有更好的并行化特性
- 推理阶段:ViT的推理速度与ResNet相当,在批量处理时甚至更快
- 参数量:ViT-Base有86M参数,而ResNet-50只有25M参数
Swin Transformer:站在巨人肩膀上的创新
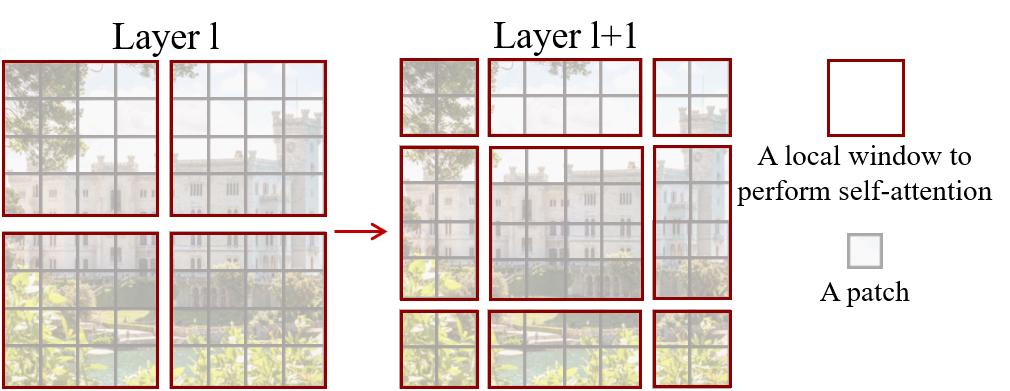
就在ViT声名鹊起之时,微软亚洲研究院的研究者们提出了一个更加精妙的改进方案:Swin Transformer。
Swin Transformer的核心创新在于层次化架构和滑动窗口注意力:

层次化设计:Swin Transformer采用类似CNN的层次化结构,能够生成多尺度的特征图。这使得它在目标检测和语义分割等密集预测任务上表现优异。
滑动窗口机制:通过将注意力计算限制在局部窗口内,Swin将计算复杂度从O(n²)降低到O(n)。实验显示,在COCO目标检测任务上,Swin Transformer达到了58.7 box AP的成绩,超越了同期的CNN检测器。
实践指南:从理论到应用
使用Hugging Face Transformers库,我们可以轻松地部署和微调ViT模型:
from transformers import pipeline
import torch
# 创建图像分类管道
classifier = pipeline(
task="image-classification",
model="google/vit-base-patch16-224",
torch_dtype=torch.float16,
device=0
)
# 对图像进行分类
results = classifier("path/to/your/image.jpg")
print(f"预测类别: {results[0]['label']}")
print(f"置信度: {results[0]['score']:.4f}")
微调建议:
- 使用更高分辨率的图像(384×384)进行微调,通常能提升1-2%的准确率
- 数据增强技术如Mixup和CutMix对ViT特别有效
- 使用较小的学习率(1e-4到5e-5)进行微调
真实世界的应用案例
医学图像分析:在糖尿病视网膜病变检测任务中,ViT达到了96.8%的准确率,超越了传统CNN方法。这是因为糖尿病视网膜病变的征象往往分布在整个视网膜上,需要全局的理解能力。
自动驾驶:Tesla在其FSD系统中采用了基于Transformer的视觉模型,能够同时处理来自8个摄像头的信息,实现真正的全景理解。
内容审核:各大社交媒体平台使用ViT进行图像内容审核,其全局理解能力使得它能够更好地识别上下文相关的不当内容。
挑战与未来展望
尽管ViT取得了巨大成功,但仍面临一些挑战:
数据饥渴症:ViT需要大量数据才能达到最佳性能。研究显示,在少于1万张图像的数据集上,ViT的性能明显不如CNN。
计算资源需求:训练一个大规模ViT模型需要数百个GPU天的计算资源,这对许多研究机构来说都是不小的负担。
解释性问题:虽然可以可视化注意力权重,但理解ViT的决策过程仍然比CNN更困难。
然而,新的技术正在不断涌现:
- 数据效率改进:DeiT(Data-efficient ViT)通过知识蒸馏将所需数据量减少了80%
- 轻量化设计:MobileViT、EfficientViT等模型在保持性能的同时大幅减少了参数量
- 自监督学习:MAE(Masked Autoencoder)等方法让ViT能够从无标签数据中学习
结语:新时代的序幕

Vision Transformer的出现不仅仅是一个新模型的诞生,更代表着计算机视觉领域思维方式的根本转变。它证明了Transformer架构的通用性,也为我们提供了一个全新的视角来理解视觉感知。
从最初的质疑到现在的广泛接受,ViT走过了一条充满挑战但又激动人心的道路。今天,当我们使用智能手机的拍照识别功能,当我们在电商网站搜索相似商品,当医生使用AI辅助诊断时,都可能有ViT的身影在默默发挥作用。
这个故事告诉我们,在科学研究中,最大胆的跨界尝试往往能带来最意想不到的突破。Vision Transformer不仅改变了计算机视觉,更启发我们在人工智能的道路上保持开放的心态,勇于探索未知的可能性。
正如这个领域的快速发展所展示的那样,今天的"不可能"很可能就是明天的"理所当然"。而Vision Transformer,正是这种无限可能性的完美诠释。