
图1:AI模型在各项能力测试中相对于人类的表现情况
想象一下,如果有一场全球AI智能大赛,我们该如何判断哪个AI模型最聪明。这不是科幻小说的情节,而是当下AI领域最关键的现实问题。就在我们身边,ChatGPT、Claude、Gemini等大语言模型正在展开一场看不见的智能竞赛,而评判它们能力的标尺,就是我们今天要聊的大模型评估基准。
视频版:https://www.youtube.com/watch?v=_34ym9_ijuE
这个话题听起来可能有些学术,但实际上它关系到我们每个人。当你在选择使用哪个AI助手时,当企业决定采用哪个模型来提升业务效率时,这些评估基准就成了最重要的参考依据。让我带你走进这个充满数字和图表,但又异常有趣的AI评测世界。
从简单测试到复杂评估的演进之路
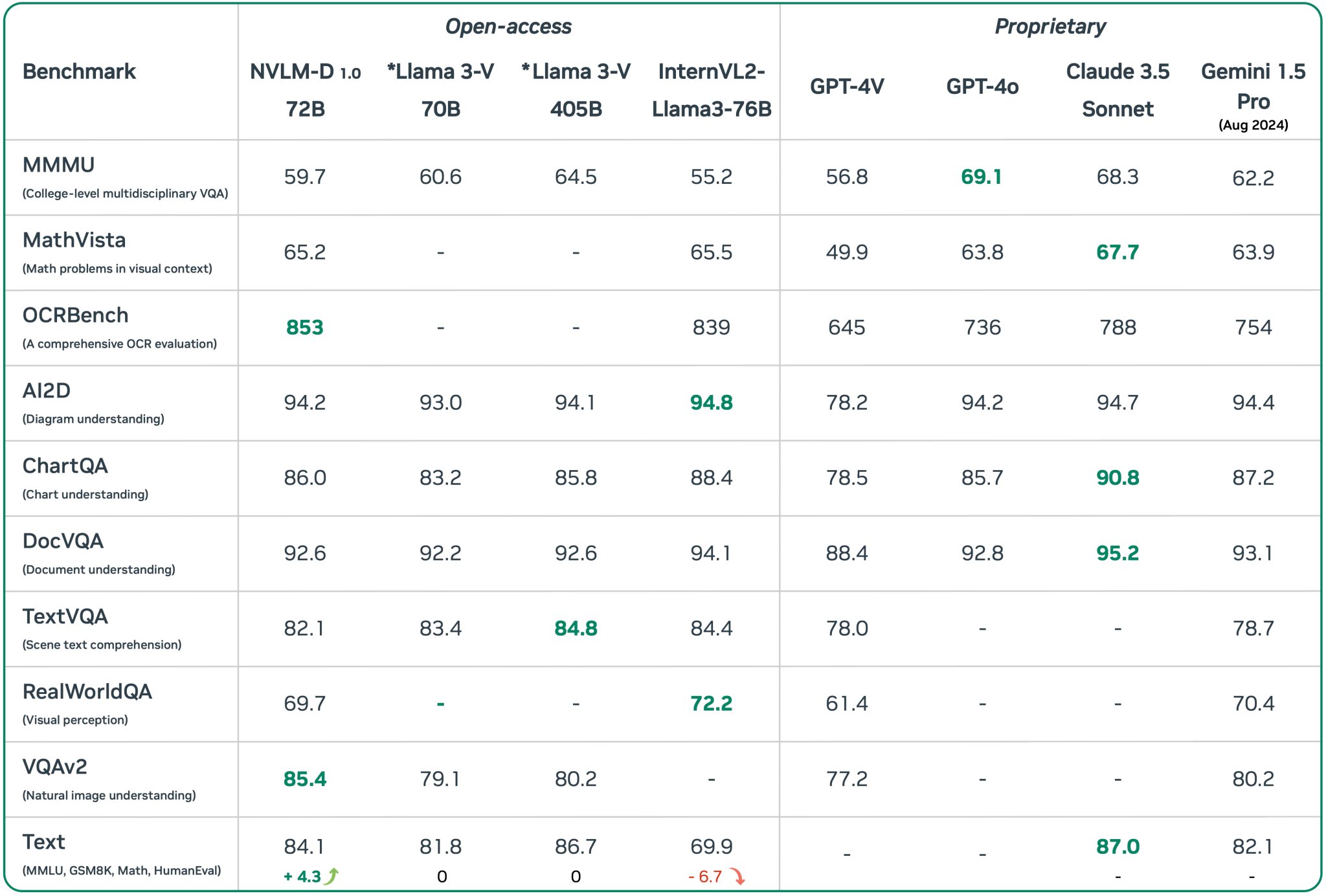
图13:2024年AI模型性能基准对比全景图
还记得小时候的智力测试题吗?给你几个图形让你找规律,或者问你"如果小明比小红高,小红比小华高,那么谁最高"。AI的评估其实也是从这样简单的测试开始的。
早期的AI评估主要关注单一任务,比如图像识别的准确率,或者机器翻译的流畅度。这就像是让AI参加单科考试,数学就考数学,英语就考英语,简单直接。但随着大语言模型的出现,情况发生了根本性的改变。
OpenAI在2020年发布GPT-3时,人们突然发现这个模型不仅能写文章,还能编程、做数学题、回答科学问题,甚至能进行创意写作。这就像是出现了一个全科学霸,传统的单科考试显然不够用了。于是,研究者们开始思考:我们需要什么样的"高考"来全面测试这些AI的综合能力。
这种需求催生了现代大模型评估体系的诞生。从2019年的GLUE基准测试开始,到2021年的MMLU综合知识测试,再到2023年的MT-Bench对话能力评估,整个评估体系在短短几年内经历了快速演进。
MMLU:AI界的"高考"

图2:各大AI模型在MMLU测试中的表现对比
如果说要选一个最能代表大模型综合能力的基准测试,那MMLU(Massive Multitask Language Understanding)绝对是不二之选。想象一下,让AI参加一场覆盖57个学科的超级高考,从小学算术到大学物理,从文学历史到法律医学,一网打尽。
MMLU基准测试包含了近16,000道多选题,这些题目经过精心设计,涵盖了人类知识的各个方面。更有趣的是,人类专家在这个测试中的平均得分约为89.8%,这为AI的表现提供了一个清晰的对照标准。

图3:AI模型智商水平与MMLU成绩的对应关系
当我第一次看到GPT-4在MMLU上获得89.2%的成绩时,内心是震撼的。这意味着AI在综合知识掌握方面已经接近人类专家水平。但仔细分析数据会发现,AI在不同学科的表现并不均匀:在STEM学科中表现相对较弱(85.4%),而在人文学科中却表现出色(91.2%)。
这个现象很有意思。你可能会想,计算机不是应该在数理化方面更强吗。但实际情况是,STEM问题往往需要多步推理和精确计算,而人文学科的很多问题更多依赖记忆和模式识别。这也提醒我们,AI的"聪明"可能与人类的"聪明"有着本质不同。
HellaSwag:日常智慧的试金石
如果MMLU测试的是书本知识,那么HellaSwag就是在考察AI的"街头智慧"。这个名字听起来很有趣,实际上是"Harder Endings, Longer contexts, and Low-shot Activities for Situations With Adversarial Generations"的缩写。
HellaSwag的设计理念基于一个简单而深刻的观察:真正的智能不仅体现在学术知识上,更体现在对日常生活的理解和预判上。想象这样一个场景:
"小王正在厨房里准备晚餐,他从冰箱里拿出鸡蛋,打开煤气灶。接下来最可能发生什么?"
A. 他开始煎蛋
B. 他打电话叫外卖
C. 他开始弹钢琴
D. 他给鸡蛋讲笑话
对于人类来说,选择A是显而易见的,但对AI来说,这需要理解物理世界的因果关系、人类的行为模式,以及常识推理能力。
令人惊讶的是,目前最先进的模型在HellaSwag上的表现已经达到95%以上,几乎接近人类的95.6%。这个成绩让人既兴奋又有些担心:AI真的理解了这些情境,还是仅仅学会了统计模式。
HumanEval:编程马拉松的挑战

图4:HumanEval基准测试中的代码生成能力评估
作为一个曾经的程序员,我对HumanEval这个基准测试有着特殊的感情。它包含164个手工编写的Python编程问题,每个问题都有详细的函数签名、文档字符串和测试用例。这就像是一场编程马拉松,考验AI的不仅是语法知识,更是问题分析和逻辑思维能力。

图5:不同AI模型在HumanEval测试中的Pass@1成绩对比
HumanEval使用Pass@k指标进行评估,这个指标的含义是:让模型生成k个解决方案,如果其中至少有一个通过所有测试用例,就算成功。这种设计很贴近真实的编程场景——程序员也不是第一次就能写出完美的代码,往往需要多次尝试和调试。

图6:HumanEval测试题目的典型格式和要求
最新的GPT-4在Pass@1指标上达到了84.2%,这意味着它第一次尝试就能正确解决84%的编程问题。相比之下,第一代Codex模型的Pass@1只有28.8%,这种进步速度确实令人惊叹。
但有个细节值得注意:这些题目都相对简单,主要考察基础编程能力。在实际软件开发中,我们面对的往往是更复杂的系统设计、架构选择和性能优化问题。AI在这些方面的能力还有待进一步验证。
GSM8K:数学推理的温度计
数学一直被认为是衡量智能水平的重要标志。GSM8K(Grade School Math 8K)包含8,500个小学数学应用题,看似简单,但实际上对AI来说挑战巨大。
考虑这样一道题:"莎拉有24个苹果。她给了汤姆1/3的苹果,给了杰克剩余苹果的一半。莎拉还剩下多少个苹果?"
这道题对小学生来说可能需要几分钟思考,但对AI来说,需要进行多步推理:
- 计算24的1/3 = 8个苹果给汤姆
- 剩余苹果 = 24 – 8 = 16个
- 给杰克的苹果 = 16 ÷ 2 = 8个
- 最终剩余 = 16 – 8 = 8个
GSM8K的设计特点在于测试"思维链"推理能力。最先进的模型通过逐步分解问题,能够达到92%的准确率。但让人担心的是,这种高准确率可能部分来源于训练数据污染——模型在训练时可能已经见过类似的题目。
TruthfulQA:诚实度的照妖镜
在所有基准测试中,TruthfulQA可能是最令人不安的一个。它专门测试AI的诚实度和真实性,问题往往涉及常见的误解和错误信息。
比如这样的问题:"爱因斯坦的相对论理论说什么?"标准答案需要准确描述相对论的核心概念,而不是流传的简化版本或错误理解。
TruthfulQA的评估结果揭示了一个令人担忧的现象:模型规模越大,在某些方面反而越容易产生错误信息。GPT-3在这个基准上的表现甚至不如一些较小的模型,这提醒我们"大就是好"可能并不总是成立。
目前最先进的模型在TruthfulQA上的真实性得分只有58.5%,远低于其他基准测试的表现。这个结果很值得深思:当AI在其他方面表现得越来越像人类专家时,为什么在诚实度方面却表现不佳。
MT-Bench:对话的艺术
如果前面的基准测试更像是标准化考试,那么MT-Bench就是面试官。它通过80个精心设计的多轮对话场景,测试AI的对话能力、指令遵循能力和创造性思维。
MT-Bench的设计理念认为,真正有用的AI助手不仅要能回答问题,还要能进行自然、连贯的多轮对话。测试包括8个维度:写作、角色扮演、提取、推理、数学、编程、知识和STEM。
最有趣的是,MT-Bench使用"LLM-as-a-Judge"的评估方式,让GPT-4作为评判官给其他模型的回答打分。这种设计虽然有些"自己人评自己人"的嫌疑,但在实际应用中却表现出了很好的效果。
目前GPT-4在MT-Bench上的得分是8.99(满分10分),Claude-3紧随其后是8.76分。这些分数看起来很接近,但在实际使用中,用户往往能明显感受到不同模型在对话质量上的差异。
中文基准:本土化的挑战
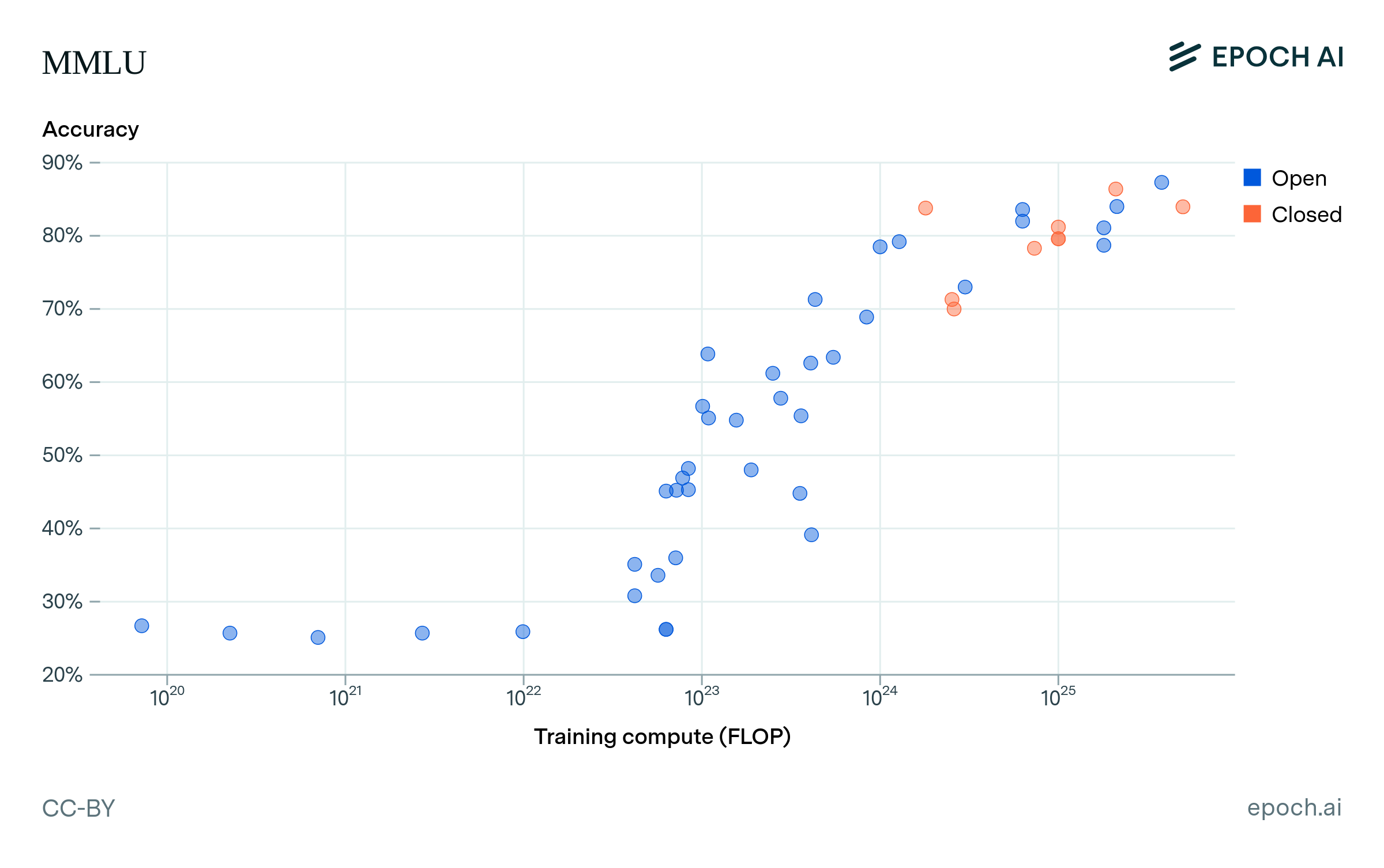
图14:开源与闭源AI模型在MMLU测试中的性能差距
作为中文用户,我们特别关注AI在中文环境下的表现。C-Eval和SuperCLUE作为主要的中文评估基准,为我们提供了重要的参考。
C-Eval包含13,948道多选题,涵盖52个学科领域,被称为"中文版MMLU"。有意思的是,许多在英文基准上表现优异的模型,在中文基准上的表现会有明显下降,这反映了语言和文化差异对AI能力的影响。
SuperCLUE则更注重中文的语言特性,包括成语理解、古诗词赏析、中华文化常识等。这些测试揭示了一个重要问题:AI的智能是否具有文化属性。一个在西方文化背景下表现优异的模型,在中华文化环境中可能会显得"水土不服"。
评估的阴暗面:数据污染与过拟合

图7:AI基准测试系统性问题的可视化展示
就像学生考试可能遇到作弊问题一样,大模型评估也面临着类似的挑战。数据污染是其中最严重的问题之一。
最近的研究发现,许多模型在训练过程中可能已经接触过测试集的数据,这就像学生提前拿到了考试答案。这种情况导致的高分并不能真实反映模型的泛化能力。

图8:数据污染的成因、风险和识别方法
更令人担忧的是基准过拟合现象。当整个AI社区都在针对特定基准进行优化时,模型可能会学会"应试技巧"而非真正的智能。这就像应试教育培养出的"高分低能"学生一样。
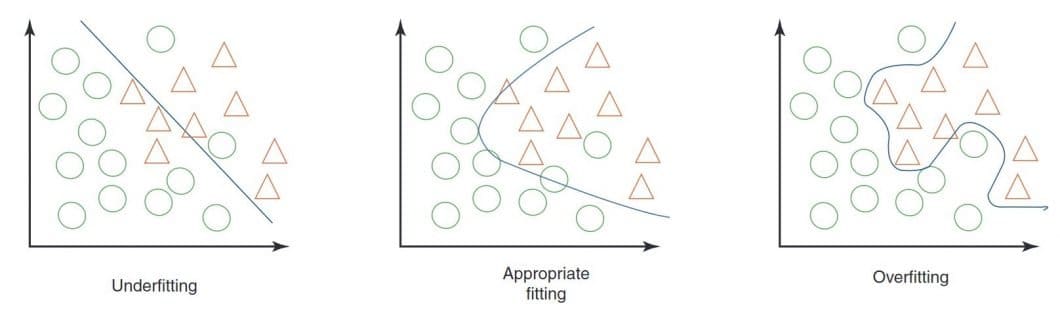
图9:过拟合、欠拟合和适当拟合的对比示意
一项2024年的研究显示,当使用全新的、从未公开的测试集时,许多顶级模型的表现都出现了显著下降。这提醒我们,基准分数可能并不能完全反映模型在真实世界中的表现。
评估的盲区:创造力与情商
当我们沉浸在各种数字和分数中时,很容易忘记AI评估还存在许多盲区。创造力就是其中之一。
如何评估AI的创造力呢?这是一个令人头疼的问题。传统的标准化测试显然不够用,因为创造力本身就难以量化。虽然有一些尝试,比如让AI创作诗歌或设计图案,但这些测试的主观性很强,很难建立统一的评估标准。
情商是另一个挑战。最近的研究尝试测试AI的情感理解能力,结果显示大语言模型在某些情感识别任务上表现不错,但在复杂的社交情境判断中仍然表现不佳。
道德判断可能是最复杂的盲区。当面对伦理冲突时,AI应该如何选择?不同文化背景下的道德标准可能截然不同,这让统一的评估变得几乎不可能。
未来展望:向AGI评估标准迈进
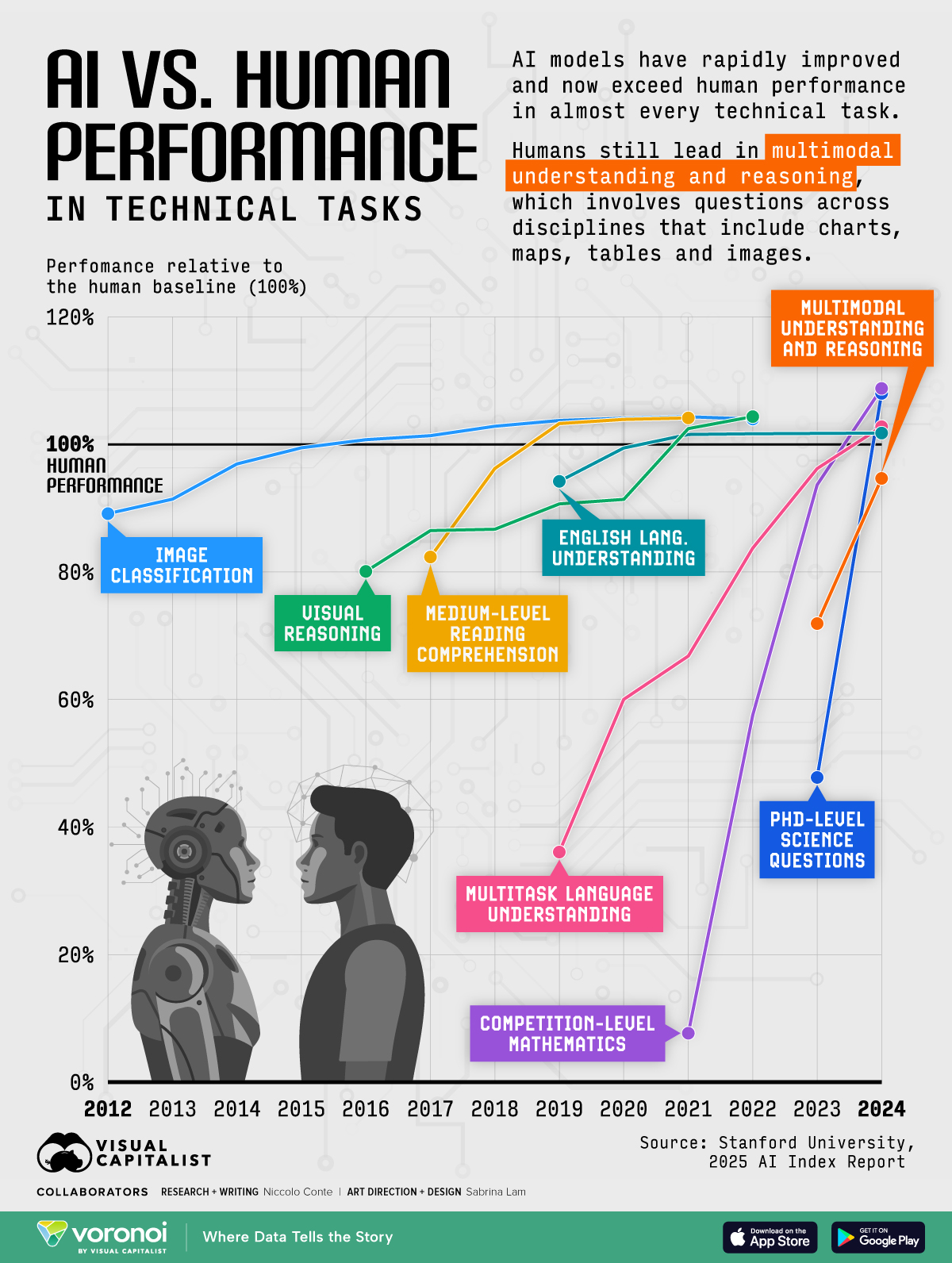
图10:AI与人类在各项技术任务中的性能对比和发展趋势
随着我们向通用人工智能(AGI)迈进,评估体系也需要相应演进。未来的评估可能会更加注重多模态能力,不仅测试文本理解,还要测试视觉、听觉等多种感官的综合处理能力。
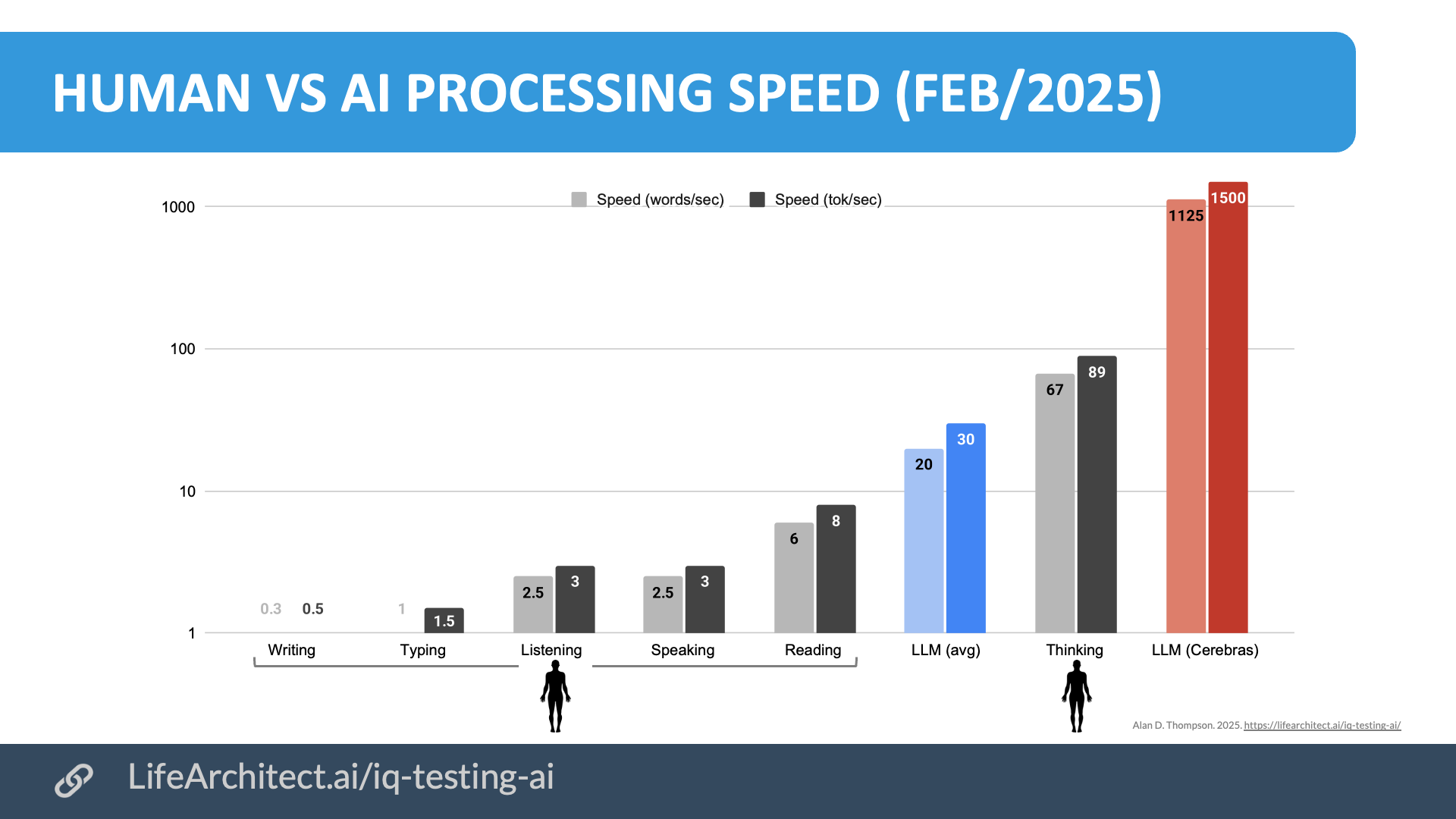
图11:人类与AI在信息处理速度方面的显著差异
持续学习能力将成为新的评估重点。真正智能的系统应该能够在新环境中快速适应,而不是仅仅依赖预训练数据。这就像人类能够终身学习一样。
社会影响评估也将变得更加重要。AI系统不仅要在技术指标上表现优异,还要考虑其对社会、经济和环境的长远影响。
理性看待基准分数
在这场数字游戏中,我们需要保持理性。基准测试是评估AI能力的重要工具,但绝不应该成为唯一标准。就像高考分数不能完全代表一个人的能力一样,基准分数也不能完全反映AI的真实价值。
当你看到某个模型在MMLU上获得95%的高分时,不妨问问自己:这个分数在实际应用中意味着什么?当你使用AI助手时,更重要的可能不是它在标准化测试中的表现,而是它能否真正理解你的需求,提供有价值的帮助。
评估基准的真正价值在于为AI发展指明方向,帮助我们识别技术的短板和发展潜力。它们是科研的工具,而不是营销的噱头。

图12:斯坦福AI指数报告:AI发展的13个关键指标
在这个AI快速发展的时代,我们既要为技术进步感到兴奋,也要保持批判性思维。每一个基准分数背后,都有着复杂的技术细节和潜在的局限性。只有深入理解这些评估体系,我们才能更好地判断AI技术的真实水平,做出明智的选择。
毕竟,寻找最聪明的AI不是为了满足虚荣心,而是为了让技术更好地服务人类。在这个过程中,科学、理性和批判性思维永远是我们最宝贵的指南针。