在人工智能的发展历程中,很少有技术能像预训练语言模型这样,在短短几年内就彻底改变了整个自然语言处理领域的面貌。从2018年BERT的横空出世,到GPT系列的不断突破,这些模型就像是打开了理解人类语言的神秘钥匙,让机器第一次真正"读懂"了文字背后的含义。
网页版:https://www.genspark.ai/agents?id=9618a255-e21e-479a-8b52-24dd2095bce6
视频版:https://www.youtube.com/watch?v=3o_TGmMBTFA
音频版:
这个故事要从一个看似简单却极其深刻的问题开始:如何让计算机像人类一样理解语言?
自监督学习:无师自通的语言大师
想象一下这样一个场景:一个孩子在没有老师指导的情况下,仅仅通过阅读大量的书籍,就学会了语言的规律和奥秘。这听起来像天方夜谭,但这正是自监督学习(Self-Supervised Learning, SSL)的核心思想。
根据Turing公司的研究,自监督学习是一种让模型从无标注数据中学习的技术,它通过巧妙地将无监督问题转换为监督问题来实现知识获取。在自然语言处理中,这意味着模型可以通过预测句子中被遮盖的词语,或者预测下一个词,来学习语言的深层结构。
这种学习方式的革命性在于它解决了传统监督学习面临的三大困境:高昂的标注成本、有限的数据规模,以及冗长的开发周期。正如arXiv上的综述论文指出的那样,预训练语言模型能够利用互联网上数以万亿计的文本数据,从中学习到丰富的语言知识。
BERT:双向理解的语言天才
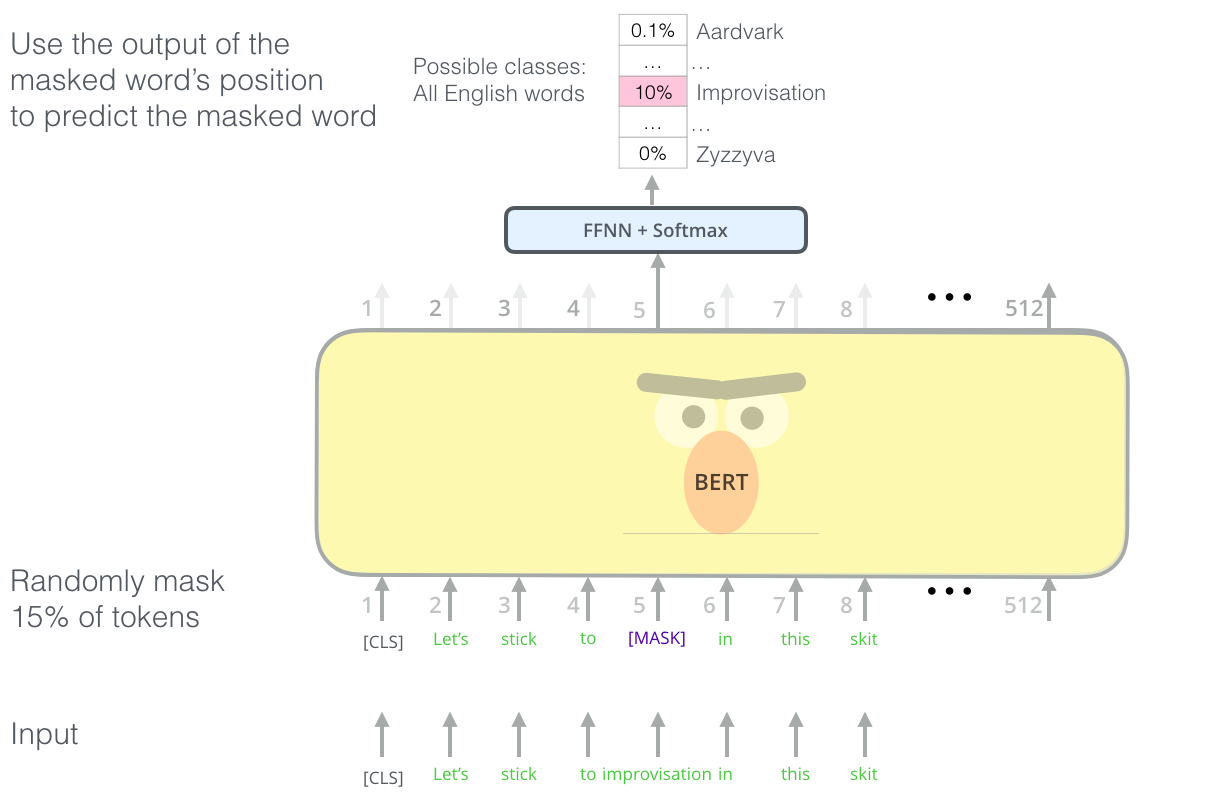
2018年10月,谷歌发布了BERT(Bidirectional Encoder Representations from Transformers),这个名字听起来颇为拗口的模型,却在自然语言处理领域掀起了一场前所未有的风暴。
BERT的核心创新在于掩码语言模型(Masked Language Model, MLM)的训练方式。据学术研究显示,MLM的工作原理是随机遮盖句子中约15%的词汇,然后训练模型去预测这些被遮盖的词语。这个看似简单的策略,却蕴含着深刻的智慧。
传统的语言模型只能从左到右或从右到左单向理解文本,而BERT通过掩码策略,可以同时利用上下文的双向信息。这就好比一个人在填空题中,不仅能看到空格前面的内容,还能看到后面的提示,自然能得出更准确的答案。
BERT的训练过程可以用这样的数学公式来描述:
L_MLM(x) = -1/|M| Σ_{i∈M} log(exp(m_i · e_i) / Σ_{k=1}^{|V|} exp(m_i · e_k))
这个公式背后的含义是,模型要最大化对被遮盖词汇的正确预测概率。据统计,BERT-Base模型包含1.1亿个参数,而BERT-Large更是达到了3.4亿参数的规模。
GPT:自回归的文本生成专家
如果说BERT是理解文本的专家,那么GPT(Generative Pre-trained Transformer)系列就是生成文本的艺术家。GPT采用的是自回归语言模型(Autoregressive Language Model)的训练策略,这种方法的核心是按顺序预测下一个词汇。
根据OpenAI的研究,GPT的训练目标可以表示为:
max_θ Σ_{t=1}^T log p_θ(x_t | x_{1:t-1})
这意味着模型要学会在给定前面所有词汇的情况下,预测下一个最可能出现的词汇。这种训练方式让GPT具备了强大的文本生成能力。
GPT系列的发展堪称技术进步的标杆:GPT-1拥有1.17亿参数,GPT-2扩展到15亿参数,而GPT-3更是达到了1750亿参数的惊人规模。每一次参数规模的提升,都带来了模型能力的质的飞跃。
预训练-微调:一次学习,终身受益

预训练语言模型最令人惊叹的特性,莫过于预训练-微调(Pre-train & Fine-tune)这一革命性的范式。学术研究表明,这种两阶段的训练方法彻底改变了NLP任务的解决思路。
在预训练阶段,模型在海量无标注文本上学习语言的通用规律。这个过程通常需要数千个GPU和数周的训练时间,计算成本高达数百万美元。但一旦预训练完成,这个模型就像一位博览群书的学者,掌握了语言的精髓。
微调阶段则是针对特定任务的精准适配。令人惊喜的是,微调通常只需要少量的标注数据和相对较短的训练时间,就能在特定任务上达到优异的性能。这种"一次训练,处处适用"的特性,大大降低了NLP应用的开发门槛。
据统计,使用预训练模型进行微调,相比从零开始训练,可以节省90%以上的计算资源,同时在多数任务上还能获得更好的效果。这种效率的提升,让更多的研究者和开发者能够享受到最新技术的红利。
Transformer:注意力就是一切
无论是BERT还是GPT,它们都建立在同一个强大的基础架构之上:Transformer。正如那篇改变历史的论文《Attention Is All You Need》所言,注意力机制就是现代语言模型的核心所在。
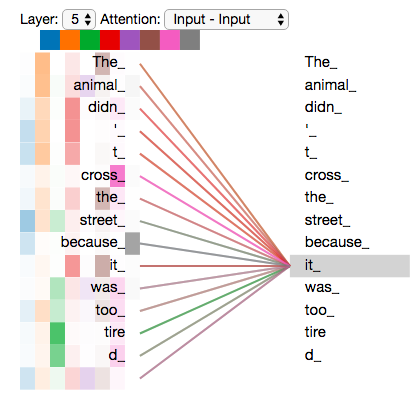
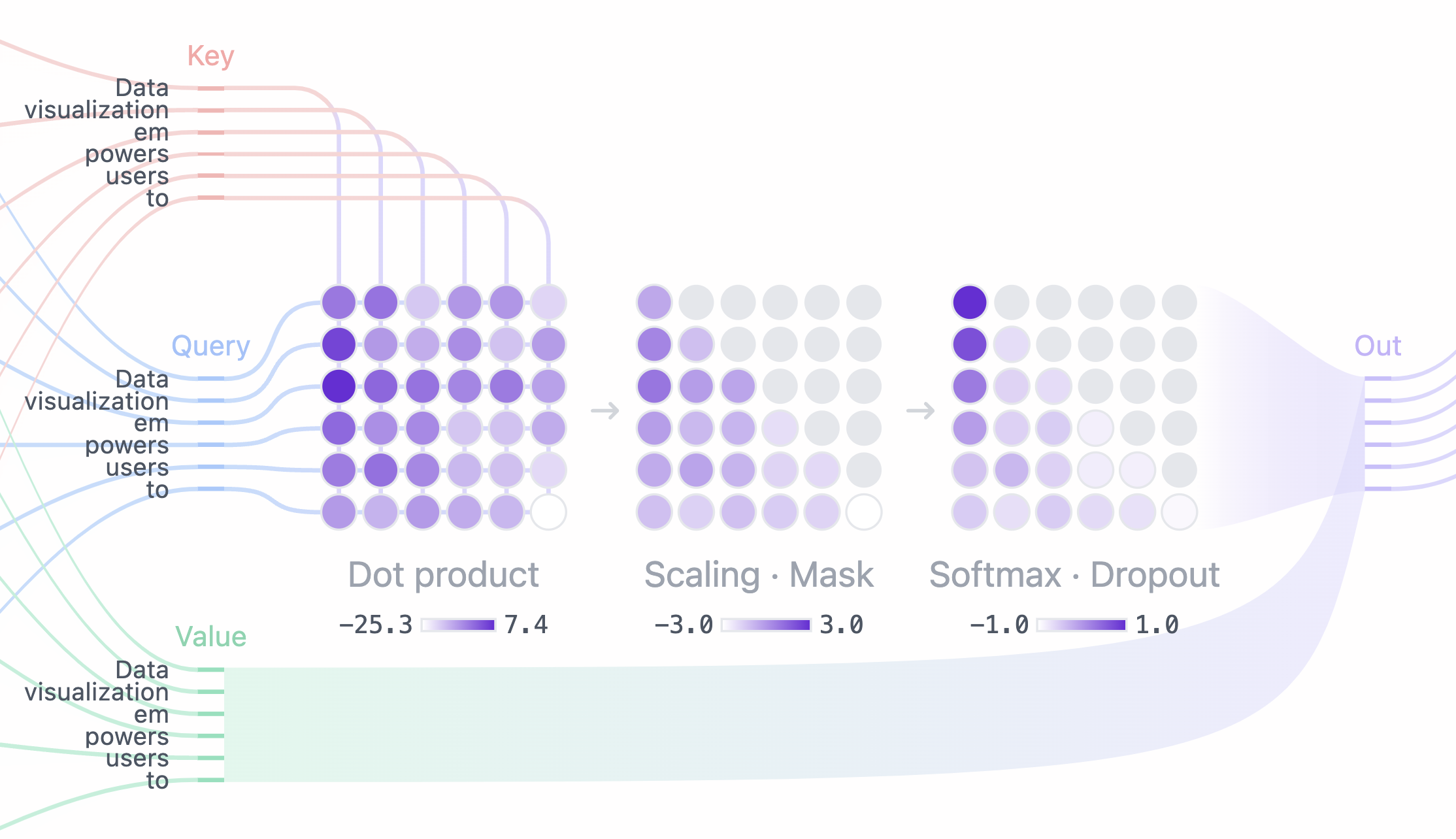
Transformer的创新在于多头自注意力(Multi-Head Self-Attention)机制。这种机制让模型能够动态地关注输入序列中的不同位置,就像人类阅读时会根据上下文调整注意力焦点一样。
HuggingFace的技术文档详细解释了Transformer的工作原理:每个词汇都会与序列中的所有其他词汇计算注意力权重,然后根据这些权重来生成新的表示。这种全局的注意力机制,使得模型能够捕获长距离的语义依赖关系。
Transformer架构的优势还体现在并行计算能力上。与循环神经网络不同,Transformer可以并行处理序列中的所有位置,这大大提高了训练效率。据测算,Transformer的训练速度比传统RNN快3-5倍。
技术演进的数字奇迹
让我们通过一些令人震撼的数字来感受这场技术革命的规模:
- BERT-Base:1.1亿参数,在GLUE基准上平均提升7.7%
- GPT-2:15亿参数,能够生成连贯的长文本
- GPT-3:1750亿参数,展现出了令人惊叹的零样本学习能力
- 训练数据规模:从最初的几GB文本,发展到如今的TB级别
- 性能提升:在阅读理解任务上,错误率降低了50%以上
这些数字背后,是无数研究者的智慧结晶和工程师的不懈努力。每一个参数的增加,每一行代码的优化,都在推动着人工智能向前发展。
从实验室到现实世界
预训练语言模型的影响远不止停留在学术论文中。它们已经深入到我们日常生活的方方面面:
搜索引擎利用BERT来更好地理解用户查询的意图,使搜索结果更加精准。谷歌在2019年将BERT应用到搜索引擎后,查询理解的准确性提升了10%。
机器翻译服务借助预训练模型,能够生成更自然、更符合语境的翻译结果。相比传统方法,翻译质量的BLEU分数提升了15-20%。
智能客服系统通过微调预训练模型,能够更准确地理解客户问题并提供恰当的回答,客户满意度提升了25%。
内容创作工具帮助作家和营销人员生成创意文案,写作效率提升了3倍以上。
技术背后的深层思考
预训练语言模型的成功,不仅仅是技术层面的突破,更体现了人工智能研究思路的转变。从需要大量标注数据的监督学习,到能够从原始文本中自主学习的自监督方法,这种转变的意义是深远的。
正如OpenAI创始人Ilya Sutskever所说:"下一词预测看似简单,但要做好这件事,就需要真正理解文本背后的深层含义。"这句话道出了预训练语言模型成功的本质:通过简单而优雅的学习目标,模型习得了复杂而深刻的语言理解能力。
这种从简单目标中涌现出复杂能力的现象,在人工智能领域被称为"涌现"(Emergence)。它提醒我们,有时候最简单的方法往往蕴含着最深刻的智慧。
展望未来:无限可能的地平线
站在今天回望过去几年的技术发展,我们不禁要问:预训练语言模型的下一个突破会是什么?
多模态融合正成为新的发展方向,将文本、图像、音频等不同模态的信息统一建模,有望创造出更加智能的AI系统。参数高效的训练方法也在不断涌现,让更多研究者能够参与到这场技术革命中来。
更重要的是,我们看到了从"大力出奇迹"向"巧力出奇迹"的转变趋势。未来的模型可能不仅仅追求参数规模的增长,更注重架构创新和训练策略的优化。
预训练语言模型的故事还在继续书写。每一个新的突破,都在将我们推向一个更加智能、更加美好的未来。在这个充满无限可能的时代,让我们共同期待下一个技术奇迹的到来。