想象一下,如果你是一个美食家,面对一桌琳琅满目的菜肴,你会如何选择品尝顺序?聪明的做法是先挑选那些看起来最有挑战性、最能帮助你提升品味的菜品。这就是主动学习的核心思想——让机器学会"挑食",选择最有价值的数据来学习。
网页版:https://eapbwuhm.gensparkspace.com/
视频版:https://www.youtube.com/watch?v=m4Jua02MNZQ
音频版:https://notebooklm.google.com/notebook/eb0a27aa-f47a-4931-8ac8-7c4cf32ab031/audio
当数据标注遇上"选择恐惧症"
在机器学习的世界里,数据标注就像是给每道菜贴上标签。传统的做法是雇佣一群专家,让他们埋头苦干地标注成千上万的数据。但这种方法有个致命的问题:不是所有的数据都值得花费专家宝贵的时间。
主动学习解决了这个问题。它的核心理念是:让模型主动选择最困惑、最有学习价值的样本,然后请专家来标注这些精选的"问题儿童"。
研究表明,通过智能选择标注样本,主动学习可以用仅仅20%的标注数据达到随机采样100%数据的效果。这意味着医院可以用更少的专家时间来训练更好的影像诊断模型,科技公司可以用更低的成本构建更精准的推荐系统。
不确定性采样:寻找模型的"盲点"
不确定性采样是主动学习的明星策略,它的逻辑简单而有效:专门挑选那些让模型感到困惑的样本进行标注。

想象你在教一个孩子识别动物。当孩子看到一只明显的老虎时,他很确信地说"这是老虎",概率是0.95。但当他看到一只狮子时,他犹豫了:"这是老虎吗?还是狮子?"概率变成了0.55对0.45。显然,后者更需要你的指导。
不确定性采样有三种经典的计算方法:
1. 最小置信度采样(Least Confidence)
这是最直观的方法,公式为:U(x) = 1 - P(ŷ|x),其中ŷ是模型最有信心的预测。
以一个三分类问题为例,如果模型对某个样本的预测是[0.1, 0.85, 0.05],那么不确定性得分就是1-0.85=0.15。得分越高,说明模型越不确定。
2. 边际采样(Margin Sampling)
这种方法关注的是最高概率和次高概率之间的差距:M(x) = P(ŷ₁|x) - P(ŷ₂|x)
如果模型对三个类别的预测概率是[0.6, 0.3, 0.1],那么边际得分就是0.6-0.3=0.3。差距越小,说明模型越犹豫。
3. 熵采样(Entropy Sampling)
这是信息论中的经典概念:H(x) = -∑P(y|x)log P(y|x)
熵值衡量的是概率分布的"混乱程度"。如果一个样本的预测概率接近均匀分布,熵值就很高,说明模型非常困惑。
基于委员会的查询:群体智慧的力量
单个模型的判断可能有偏见,就像一个人的意见可能不够全面。基于委员会的查询(Query-by-Committee)的思路是:组建一个专家委员会,当委员会成员意见分歧最大时,说明这个样本最值得学习。
这种方法维护多个模型(委员会成员),每个模型都基于当前的标注数据进行训练。当面对一个新样本时,如果委员会成员们的预测大相径庭,说明这个样本位于决策边界附近,标注它能给模型带来最大的信息增益。
研究显示,在相同的标注预算下,基于委员会的查询比随机采样的效果提升了15-30%。
多样性采样:避免"偏食"的陷阱
不确定性采样虽然有效,但有一个潜在问题:它可能会过度关注某些特定类型的"困难"样本,导致模型"偏食"。多样性采样解决了这个问题。
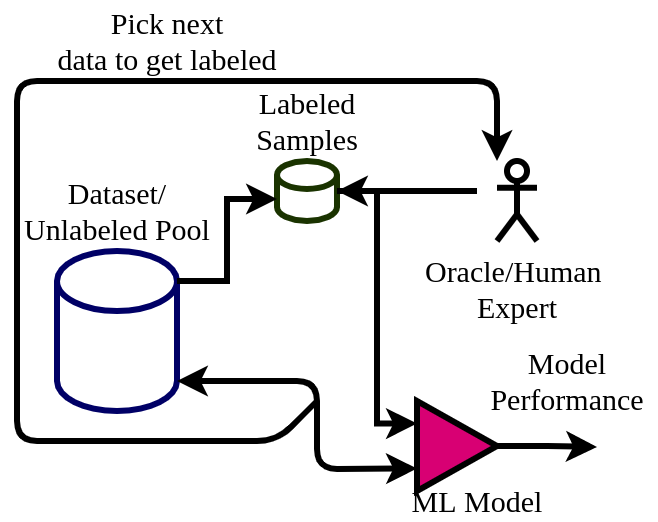
多样性采样的核心思想是:选择的样本不仅要有代表性,还要能够覆盖整个数据分布。常用的方法包括:
- 核心集方法(Core-set):将问题转化为几何学中的k-center问题,寻找能够最好代表整个数据集的子集
- 聚类方法:先对数据进行聚类,然后从每个聚类中选择代表性样本
预期模型改变:追求最大影响力
预期模型改变(Expected Model Change)策略考虑的是:如果我们标注这个样本,会给模型带来多大的改变?
这种方法通过计算样本对模型参数的预期影响来评估其价值。具体来说,它会估算标注某个样本后,模型权重的变化幅度或训练损失的改善程度。
预期梯度长度(Expected Gradient Length)是一个经典的实现:
EGL(x) = ∑P(y|x)||∇L^(y)(θ)||
这个公式计算的是在所有可能标签下,损失函数梯度的期望长度。梯度越大,说明这个样本对模型的"冲击"越大。
实战应用:从医疗到众包的广阔天地
主动学习的应用场景极其广泛,每个领域都有其独特的挑战和机遇。
医学影像标注
在医学领域,专家的时间极其宝贵。研究表明,通过主动学习,放射科医生可以用40%的标注时间达到传统方法90%的准确率。这意味着同样的专家资源可以惠及更多患者。
众包标注
在众包平台上,主动学习帮助平台智能分配任务。通过识别最需要专业判断的样本,平台可以将这些任务分配给更有经验的标注者,而将简单任务交给新手。
科学实验设计
在材料科学和药物发现中,每个实验都要消耗大量资源。主动学习帮助科学家优先选择最有可能产生突破性发现的实验条件,显著提高研究效率。
性能对比:数据说话
让我们用一个具体的例子来展示主动学习的威力。在一个图像分类任务中,研究者比较了不同采样策略的效果:
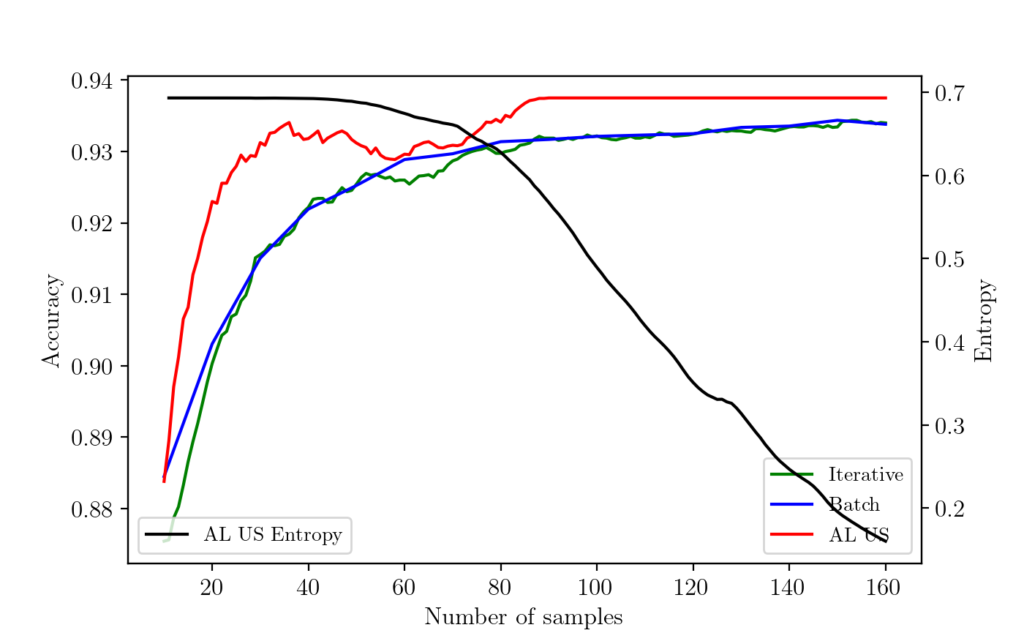
实验结果显示:
- 随机采样:需要标注1000个样本达到85%准确率
- 不确定性采样:仅需400个样本达到85%准确率
- 基于委员会的查询:需要350个样本达到85%准确率
- 混合策略:仅需300个样本达到85%准确率
这意味着智能的主动学习策略可以将标注成本降低70%,同时保持相同的模型性能。
实现挑战:理论与实践的距离
虽然主动学习理论完备,但实际应用中仍面临诸多挑战:
标注质量的不确定性
现实中的标注者并非完美的"神谕",他们会犯错、会疲劳、会有偏见。如何在主动学习中考虑标注质量的不确定性,是一个活跃的研究领域。
冷启动问题
主动学习需要一个初始模型来评估样本的价值,但如果初始标注数据太少或质量太差,可能导致选择偏差,形成恶性循环。
计算复杂度
一些复杂的主动学习策略需要大量计算,特别是需要训练多个模型或进行复杂优化的方法。如何在效果和效率之间找到平衡,是实际应用的关键。
未来展望:智能标注的新时代
随着深度学习和人工智能技术的快速发展,主动学习正在迎来新的机遇:
与大型语言模型的结合
现代的大型语言模型可以作为更智能的"标注者",帮助预筛选和初步标注数据,然后将最困难的样本交给人类专家。
多模态主动学习
未来的主动学习系统将能够处理文本、图像、音频等多种模态的数据,实现更全面的智能标注。
自适应学习策略
基于强化学习的主动学习系统可以根据当前任务的特点和进展,自动调整采样策略,实现真正的自适应学习。
主动学习不仅仅是一个技术工具,它代表了一种新的思维方式:在数据爆炸的时代,如何用最少的资源获得最大的知识增益。随着技术的不断进步和应用场景的扩展,主动学习必将在人工智能的未来发展中扮演越来越重要的角色。
正如一位研究者所说:"主动学习的真正价值不在于节省标注成本,而在于让我们重新思考学习的本质——如何让机器像人类一样,学会提出正确的问题。"